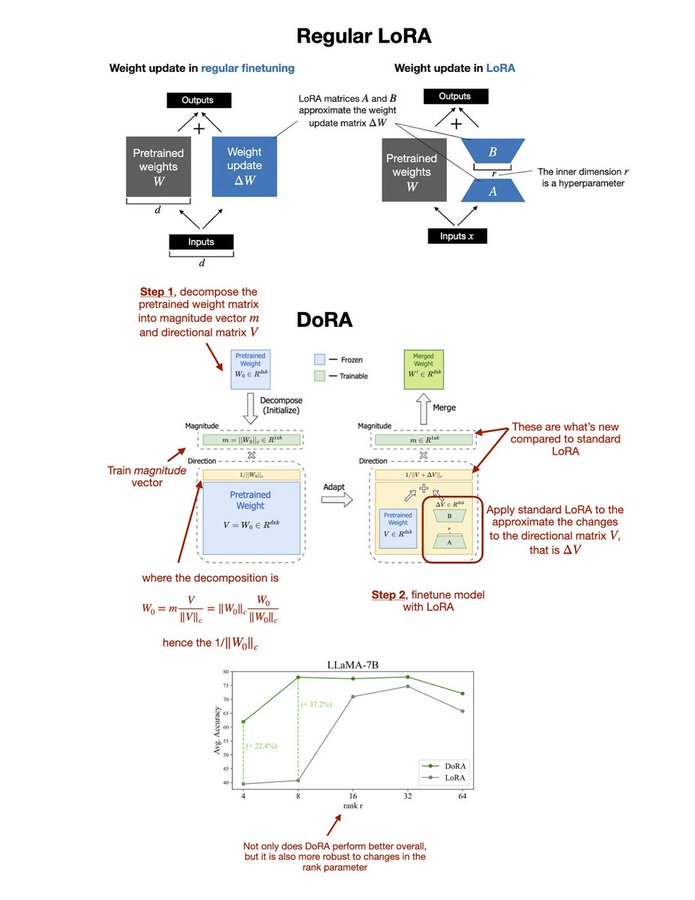
岭回归,也称为Tikhonov正则化,是一种专门用于处理多重共线性问题的回归分析技术。多重共线性是指模型中的自变量高度相关,这种高度的相关性会导致普通最小二乘法(OLS)估计的回归系数变得非常不稳定,甚至无法解释。岭回归通过引入一个非常小的、称为正则化参数的偏差,来改善估计的稳定性和减少方差,虽然这会以略微增加偏差为代价。
岭回归的数学原理
岭回归的目标是最小化以下代价函数:
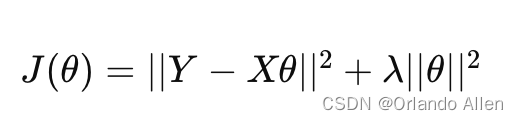
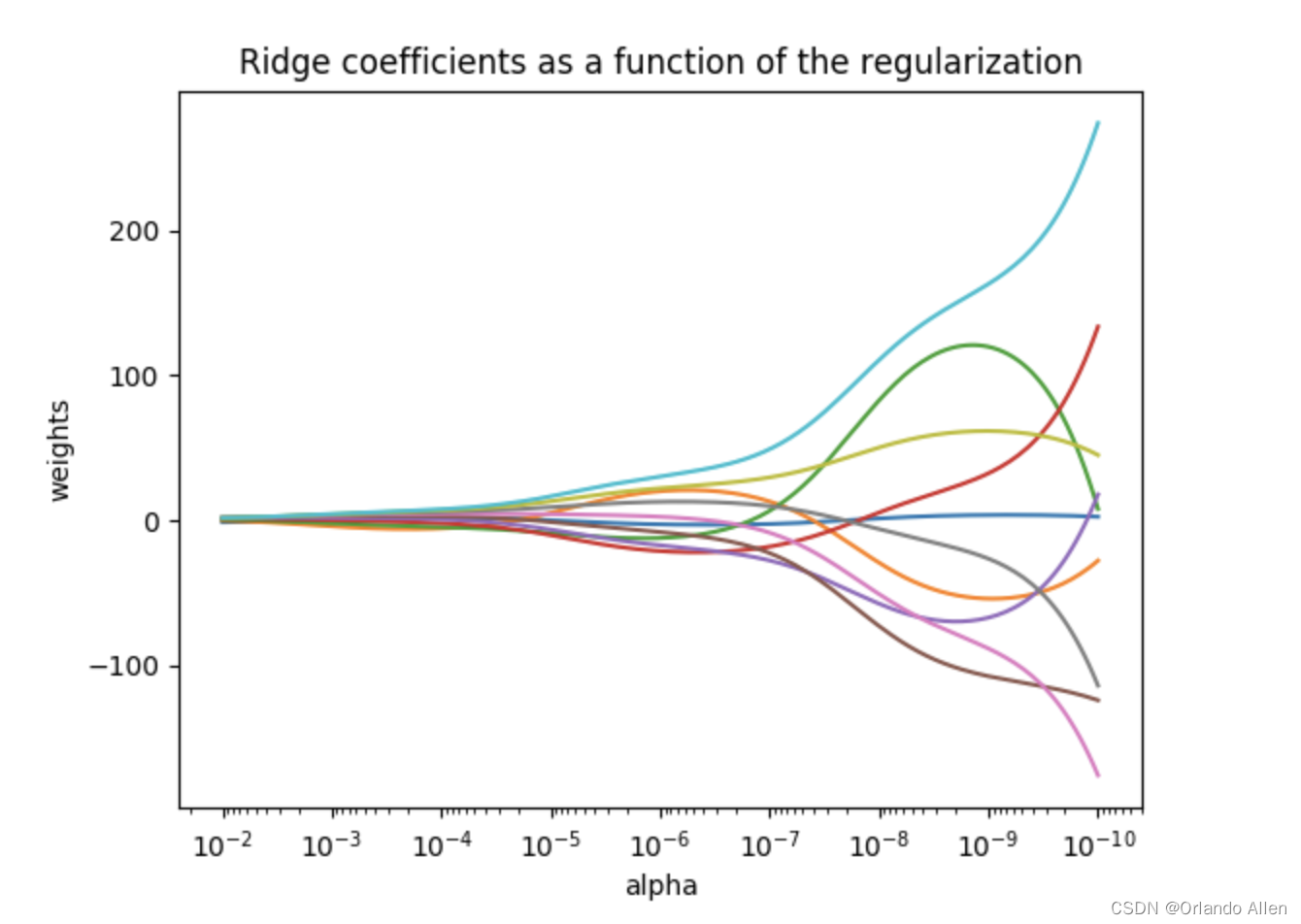
其中,Y是响应变量,X是设计矩阵,θ是回归系数,λ是正则化强度参数。第一项是残差平方和(RSS),衡量了模型拟合数据的程度;第二项是对系数的大小施加惩罚,防止它们变得过大,从而控制模型的复杂度。正则化参数λ的选择至关重要,它决定了对回归系数的惩罚强度,λ越大,惩罚越重,回归系数将越趋于零,这有助于防止过拟合。
参数选择:交叉验证
选择合适的λ值是实施岭回归时的关键步骤。这通常通过交叉验证来完成,如k折交叉验证是一种常用方法。通过交叉验证,我们可以评估不同λ值下模型的预测性能,选择一个能够使预测误差最小化的λ值。
岭回归的应用
岭回归广泛应用于包含大量预测变量的情况,其中一些变量可能与输出高度相关。这些场景包括:
- 金融领域:在资产定价和风险管理模型中,岭回归可以帮助处理各种宏观经济因素和股票价格之间可能存在的多重共线性问题。
- 生物统计学:在基因表达数据分析中,由于成千上万的基因可能对某些疾病有微小的影响,使用岭回归可以帮助识别出那些对疾病有显著影响的基因。
- 工程领域:在信号处理和多参数系统控制问题中,岭回归用于处理高度相关的输入变量,以提高系统模型的预测准确性。
代码示例
让我们通过一个简单的例子来演示如何在Python中使用岭回归。假设我们有一组数据,包含多个自变量(特征)和一个因变量(目标),我们将使用sklearn库中的Ridge类来构建岭回归模型。
示例:使用岭回归预测房价
假设我们的目标是根据房屋的各种特征(如面积、卧室数量、年龄等)来预测其价格。为了简单起见,这里使用一个虚构的小型数据集进行演示。
步骤 1:导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
步骤 2:创建数据集
np.random.seed(0)
X = np.random.rand(100, 3) # 假设有100个样本和3个特征
y = X @ np.array([3, 5, 2]) + np.random.randn(100) # 生成目标变量
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
步骤 3:训练岭回归模型
我们将尝试不同的正则化强度(λ值)并选择最佳的一个。
# 设置岭回归模型
ridge_model = Ridge(alpha=1.0) # 这里的 alpha 参数对应于上文的 λ
ridge_model.fit(X_train, y_train)
# 预测测试集
y_pred = ridge_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
步骤 4:评估模型性能
评估模型性能是通过比较测试集上的实际值和预测值来完成的。在这个例子中,我们使用了均方误差(MSE)作为性能指标。
步骤 5:调整正则化参数
为了找到最优的正则化参数(λ值),可以尝试多个不同的值并使用交叉验证来评估每个模型的性能。
alphas = np.logspace(-4, 4, 9) # 创建不同的alpha(λ)值
mse_list = []
for alpha in alphas:
ridge_model = Ridge(alpha=alpha)
ridge_model.fit(X_train, y_train)
y_pred = ridge_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
mse_list.append(mse)
# 绘制MSE随alpha变化的图
plt.semilogx(alphas, mse_list)
plt.xlabel('Alpha')
plt.ylabel('Mean Squared Error')
plt.title('MSE vs. Alpha')
plt.show()
通过这个例子,我们可以看到不同的正则化强度如何影响模型的预测性能。选择一个合适的λ值可以显著提高模型的泛化能力。这个过程称为岭回归的正则化路径分析,是选择最佳正则化参数的有效方法。
结论
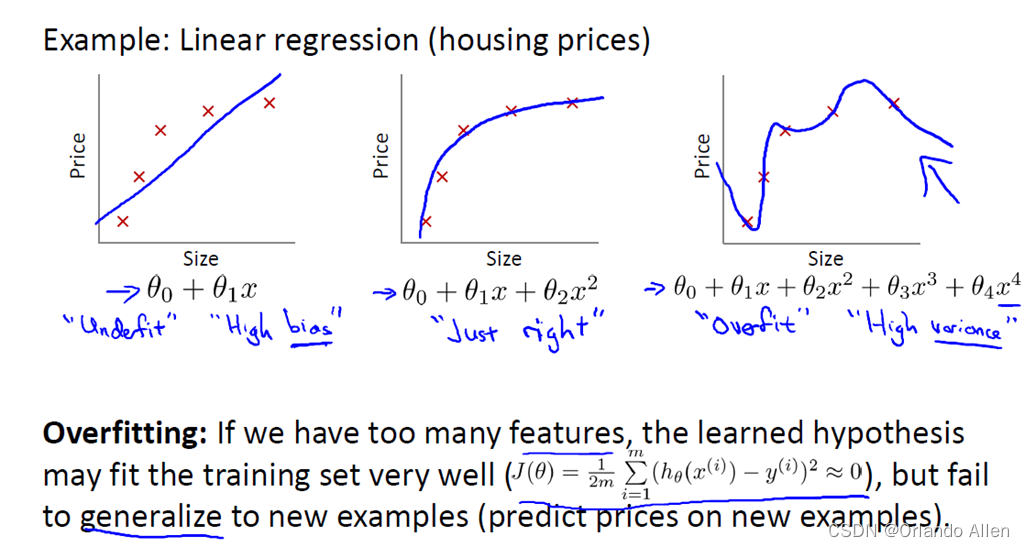
岭回归通过引入L2正则化来解决多重共线性问题,提高了模型的泛化能力。通过选择合适的正则化参数,岭回归不仅能够减少模型的过拟合风险,还能在存在高度相关自变量的情况下提供稳定的解。因此,它是现代数据分析中一个极其有用的工具,特别是在面对复杂数据集时。






















![[计算机网络]---Http协议](https://img-blog.csdnimg.cn/f55a07090b3541518429c3017449bf1b.png)