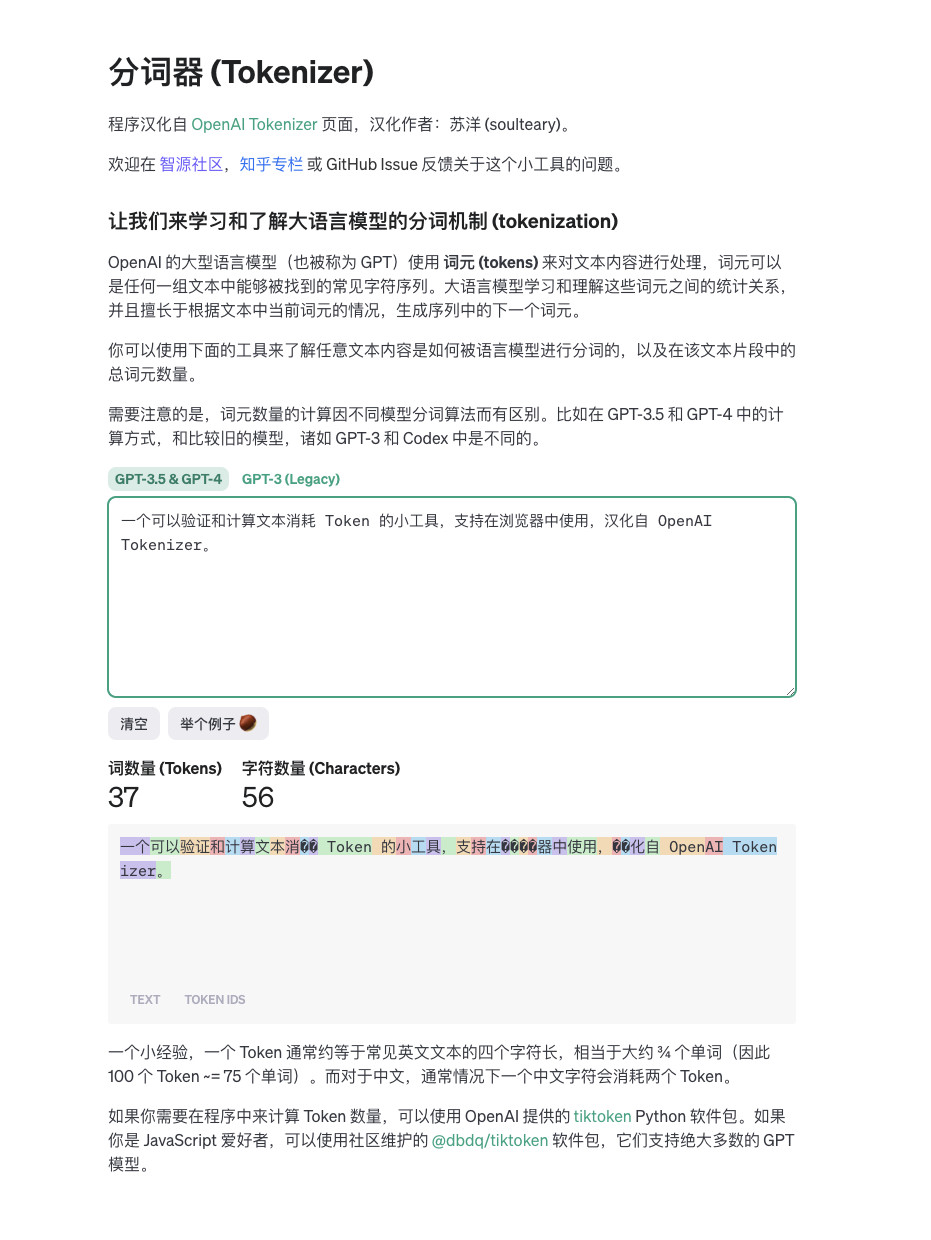
Byte-Pair Encoding(BPE) 如何构建词典?
Byte-Pair Encoding(BPE)是一种常用的无监督分词方法,用于将文本分解为子词或字符级别的单位。BPE的词典构建过程如下:
初始化词典:将每个字符视为一个初始的词。例如,对于输入文本"hello world",初始词典可以包含{'h', 'e', 'l', 'o', 'w', 'r', 'd'}。
统计词频:对于每个词,统计其在文本中的频率。例如,在"hello world"中,'h'出现1次,'e'出现1次,'l'出现3次,'o'出现2次,'w'出现1次,'r'出现1次,'d'出现1次。
合并频率最高的词对:在每次迭代中,选择频率最高的词对进行合并。合并的方式是将两个词连接起来,并用一个特殊的符号(如"_")分隔。例如,在初始词典中,选择频率最高的词对"l"和"l",将它们合并为"ll",更新词典为{'h', 'e', 'll', 'o', 'w', 'r', 'd'}。
更新词频:更新合并后的词频。对于合并的词,统计其在文本中的频率。例如,在"hello world"中,'h'出现1次,'e'出现1次,'ll'出现3次,'o'出现2次,'w'出现1次,'r'出现1次,'d'出现1次。
重复步骤3和4:重复步骤3和4,直到达到预设的词典大小或者满足其他停止条件。每次迭代都会合并频率最高的词对,并更新词频。
最终得到的词典即为BPE的词典。通过BPE算法,可以将文本分解为多个子词,其中一些子词可能是常见的词汇,而其他子词则是根据输入文本的特点生成的。这种方式可以更好地处理未登录词和稀有词,并提高模型对复杂词汇和短语的处理能力。
WordPiece 与 BPE 异同点是什么?
WordPiece和BPE(Byte-Pair Encoding)都是常用的无监督分词方法,它们有一些相似之处,但也存在一些差异。
分词目标:WordPiece和BPE都旨在将文本分解为子词或字符级别的单位,以便更好地处理未登录词和稀有词,提高模型对复杂词汇和短语的处理能力。
无监督学习:WordPiece和BPE都是无监督学习方法,不需要依赖外部的标注数据,而是通过分析输入文本自动构建词典。
拆分策略:WordPiece采用贪婪的自顶向下的拆分策略,将词汇表中的词分解为更小的子词。它使用最大似然估计来确定最佳的分割点,并通过词频来更新词典。BPE则采用自底向上的拆分策略,通过合并频率最高的词对来构建词典。它使用词频来选择合并的词对,并通过更新词频来更新词典。
分割粒度:WordPiece通常将词分解为更小的子词,例如将"running"分解为"run"和"##ning"。这些子词通常以"##"前缀表示它们是一个词的一部分。BPE则将词分解为更小的子词或字符级别的单位。它不使用特殊的前缀或后缀来表示子词。
处理未登录词:WordPiece和BPE在处理未登录词时有所不同。WordPiece通常将未登录词分解为更小的子词,以便模型可以更好地处理它们。而BPE则将未登录词作为单独的词处理,不进行进一步的拆分。
总体而言,WordPiece和BPE都是有效的分词方法,选择使用哪种方法取决于具体的任务需求和语料特点。
简单介绍一下 SentencePiece 思路?
SentencePiece是一种基于BPE算法的分词工具,旨在将文本分解为子词或字符级别的单位。与传统的BPE算法不同,SentencePiece引入了一种更灵活的训练方式,可以根据不同任务和语料库的需求进行自定义。SentencePiece的思路如下:
初始化词典:将每个字符视为一个初始的词。例如,对于输入文本"hello world",初始词典可以包含{'h', 'e', 'l', 'o', 'w', 'r', 'd'}。
统计词频:对于每个词,统计其在文本中的频率。例如,在"hello world"中,'h'出现1次,'e'出现1次,'l'出现3次,'o'出现2次,'w'出现1次,'r'出现1次,'d'出现1次。
合并频率最高的词对:在每次迭代中,选择频率最高的词对进行合并。合并的方式是将两个词连接起来,并用一个特殊的符号(如"_")分隔。例如,在初始词典中,选择频率最高的词对"l"和"l",将它们合并为"ll",更新词典为{'h', 'e', 'll', 'o', 'w', 'r', 'd'}。
更新词频:更新合并后的词频。对于合并的词,统计其在文本中的频率。例如,在"hello world"中,'h'出现1次,'e'出现1次,'ll'出现3次,'o'出现2次,'w'出现1次,'r'出现1次,'d'出现1次。
重复步骤3和4:重复步骤3和4,直到达到预设的词典大小或者满足其他停止条件。每次迭代都会合并频率最高的词对,并更新词频。
训练模型:根据得到的词典,训练一个分词模型。模型可以根据需求选择将文本分解为子词或字符级别的单位。
通过SentencePiece,可以根据不同任务和语料库的需求,自定义分词模型。它可以更好地处理未登录词和稀有词,提高模型对复杂词汇和短语的处理能力。同时,SentencePiece还支持多种语言和编码方式,可以广泛应用于自然语言处理任务中。
不同大模型 LLMs 的分词方式
大模型语言模型(Large Language Models,LLMs)通常采用不同的分词方式,这些方式可以根据任务和语料库的不同进行调整。以下是一些常见的大模型LLMs的分词方式的举例:
基于规则的分词:这种分词方式使用预定义的规则和模式来切分文本。例如,可以使用空格、标点符号或特定的字符来确定词语的边界。这种方法简单直接,但对于复杂的语言和文本结构可能不够准确。
基于统计的分词:这种分词方式使用统计模型来确定词语的边界。通常会使用大量的标注数据来训练模型,并根据词语的频率和上下文来进行切分。这种方法相对准确,但对于未见过的词语或特定领域的术语可能不够准确。
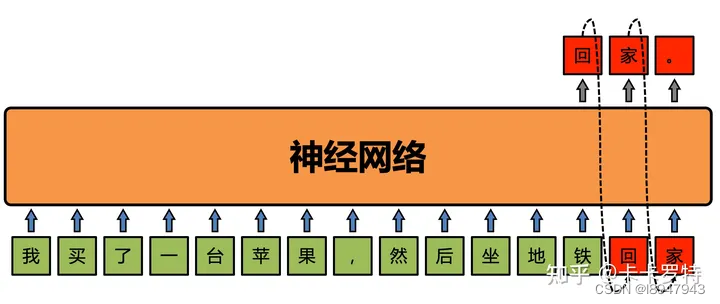
基于深度学习的分词:这种分词方式使用深度学习模型,如循环神经网络(RNN)或Transformer模型,来进行分词。这些模型可以学习文本的上下文信息,并根据语义和语法规则来进行切分。这种方法可以处理复杂的语言结构和未见过的词语,但需要大量的训练数据和计算资源。
基于预训练模型的分词:最近的研究表明,使用预训练的语言模型,如BERT、GPT等,可以在分词任务上取得很好的效果。这些模型在大规模的文本数据上进行预训练,并能够学习到丰富的语言表示。在具体的分词任务中,可以通过在预训练模型上进行微调来进行分词。这种方法具有较高的准确性和泛化能力。
基于词典的分词:这是最常见的分词方式之一,使用一个预先构建好的词典来将文本分解为单词。例如,BERT模型使用WordPiece分词器,将文本分解为词片段(subword units),并在词典中查找匹配的词片段。
基于字符的分词:这种方式将文本分解为单个字符或者字符级别的单位。例如,GPT模型使用字节对编码(Byte Pair Encoding,BPE)算法,将文本分解为字符或字符片段。
基于音节的分词:对于一些语言,特别是拼音文字系统,基于音节的分词方式更为常见。这种方式将文本分解为音节或音节级别的单位。例如,对于中文,可以使用基于音节的分词器将文本分解为音节。
基于规则的分词:有些语言具有明确的分词规则,可以根据这些规则将文本分解为单词。例如,日语中的分词可以基于汉字辞书或者语法规则进行。
基于统计的分词:这种方式使用统计模型来判断文本中的分词边界。例如,隐马尔可夫模型(Hidden Markov Model,HMM)可以通过训练来预测最可能的分词边界。
需要注意的是,不同的大模型LLMs可能在分词方式上有所差异,具体的实现和效果可能因模型的结构、训练数据和任务设置而有所不同。甚至在同一个模型中,可以根据任务和语料库的需求进行调整。这些分词方式的选择会对模型的性能和效果产生影响,因此需要根据具体情况进行选择和调整。