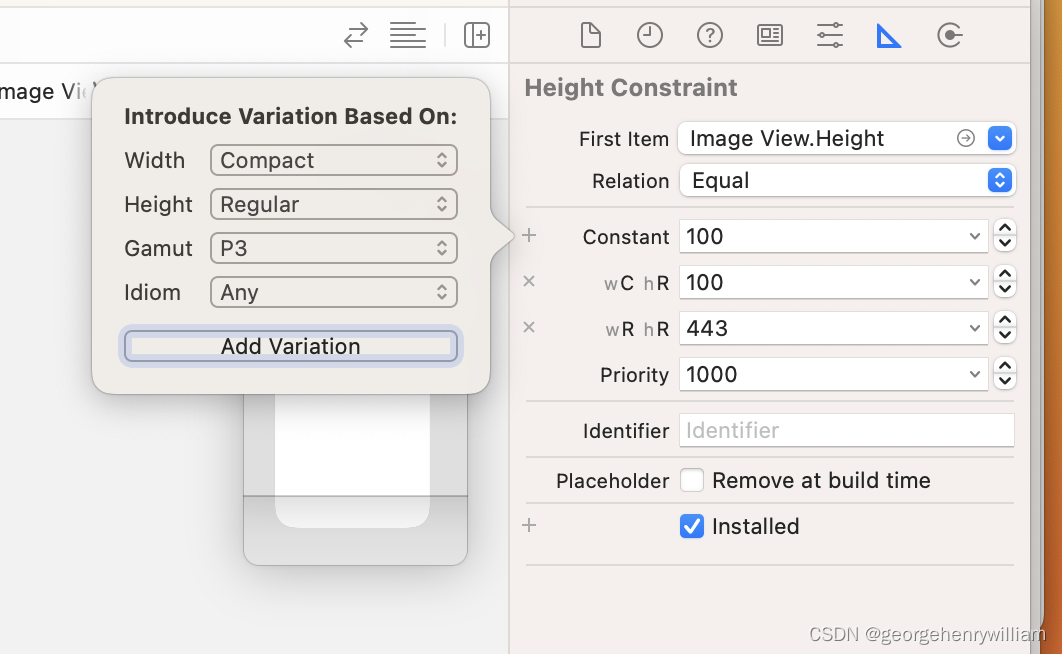
XGBoost 主要结合了大量的回归树和一个小的学习率。在这种情况下,早期添加的树是重要的,而晚期添加的树是不重要的。
Vinayak 和 Gilad-Bachrach 提出了一种将深度神经网络社区的 dropout 技术应用于梯度提升树的新方法,并在某些情况下报告了更好的结果。
以下是新的树增强器 dart 的说明。
原始论文
Rashmi Korlakai Vinayak, Ran Gilad-Bachrach。“DART: Dropouts meet Multiple Additive Regression Trees.” [arXiv]。
特性
- 通过删除树来解决过拟合问题。
- 可以阻止不重要的普通树(以纠正普通错误)
由于训练中引入的随机性,可以期待以下一些差异:
由于随机丢弃dropout会阻止使用预测缓冲区,因此训练可能比
gbtree慢由于随机性,早停Early-stop可能不稳定
工作原理
在第 m m m训练轮次中,假设 k k k棵树被选中丢弃。
令 D = ∑ i ∈ K F i D = \sum_{i \in \mathbf{K}} F_i D=∑i∈KFi为被丢弃树的叶节点分数, F m = η F ~ m F_m = \eta \tilde{F}_m Fm=ηF~m为新树的叶节点分数。
目标函数如下:
O b j = ∑ j = 1 n L ( y j , y ^ j m − 1 − D j + F ~ m ) Ω ( F ~ m ) . \mathrm{Obj} = \sum_{j=1}^n L \left( y_j, \hat{y}_j^{m-1} - D_j + \tilde{F}_m \right)\Omega \left( \tilde{F}_m \right). Obj=j=1∑nL(yj,y^jm−1−Dj+F~m)Ω(F~m).
- D D D和 F m F_m Fm是超调,因此使用缩放因子
y ^ j m = ∑ i ∉ K F i + a ( ∑ i ∈ K F i + b F m ) . \hat{y}_j^m = \sum_{i \not\in \mathbf{K}} F_i + a \left( \sum_{i \in \mathbf{K}} F_i + b F_m \right) . y^jm=i∈K∑Fi+a(i∈K∑Fi+bFm).
参数
Booster dart 继承自 gbtree booster,因此支持 gbtree 的所有参数,比如 eta、gamma、max_depth 等。
以下是额外的参数:
sample_type:采样算法的类型。uniform:(默认)以均匀方式选择要删除的树。weighted:以权重比例选择要删除的树。
normalize_type:规范化算法的类型。tree:(默认)新树的权重与每个被删除的树相同。
a ( ∑ i ∈ K F i + 1 k F m ) = a ( ∑ i ∈ K F i + η k F ~ m ) ∼ a ( 1 + η k ) D = a k + η k D = D , a = k k + η \begin{split}a \left( \sum_{i \in \mathbf{K}} F_i + \frac{1}{k} F_m \right) &= a \left( \sum_{i \in \mathbf{K}} F_i + \frac{\eta}{k} \tilde{F}_m \right) \\ &\sim a \left( 1 + \frac{\eta}{k} \right) D \\ &= a \frac{k + \eta}{k} D = D , \\ &\quad a = \frac{k}{k + \eta}\end{split} a(i∈K∑Fi+k1Fm)=a(i∈K∑Fi+kηF~m)∼a(1+kη)D=akk+ηD=D,a=k+ηk
forest:新树的权重等于被删除的树的权重之和(森林)。
a ( ∑ i ∈ K F i + F m ) = a ( ∑ i ∈ K F i + η F ~ m ) ∼ a ( 1 + η ) D = a ( 1 + η ) D = D , a = 1 1 + η . \begin{split}a \left( \sum_{i \in \mathbf{K}} F_i + F_m \right) &= a \left( \sum_{i \in \mathbf{K}} F_i + \eta \tilde{F}_m \right) \\ &\sim a \left( 1 + \eta \right) D \\ &= a (1 + \eta) D = D , \\ &\quad a = \frac{1}{1 + \eta} .\end{split} a(i∈K∑Fi+Fm)=a(i∈K∑Fi+ηF~m)∼a(1+η)D=a(1+η)D=D,a=1+η1.
dropout_rate: 丢弃率。
- 范围:[0.0, 1.0]
skip_dropout: 跳过丢弃的概率。
- 如果跳过了dropout,新树将以与 gbtree 相同的方式添加。
- 范围:[0.0, 1.0]
示例
import xgboost as xgb
# read in data
dtrain = xgb.DMatrix('./xgboost/demo/data/agaricus.txt.train?format=libsvm')
dtest = xgb.DMatrix('./xgboost/demo/data/agaricus.txt.test?format=libsvm')
# specify parameters via map
param = {
'booster': 'dart',
'max_depth': 5, 'learning_rate': 0.1,
'objective': 'binary:logistic',
'sample_type': 'uniform',
'normalize_type': 'tree',
'rate_drop': 0.1,
'skip_drop': 0.5}
num_round = 50
bst = xgb.train(param, dtrain, num_round)
preds = bst.predict(dtest)