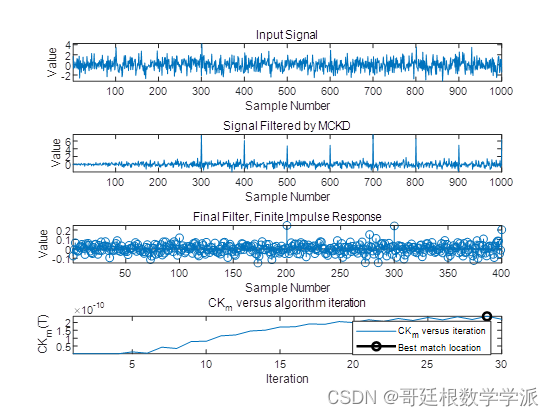
实现原理
导入一篇txt文档,使用jieba库对文档中的文字进行分词,计算各个词汇出现的频率,使用wordcloud库按照词汇频率的大小生成词云。
注意,不是使用wordcloud.generate(),这个方法没有按照词汇频率的方式实现词云
停用词
在讲区别之前,来看看停用词是什么。下面是不调用停用词的词云,观感很差对吧。

实现方式区别
【基于文本生成词云】:txt文章->调用wordcloud.generate(),内部调用停用词->保存图片
这种方法观感很差

【基于频率生成词云】:txt文章->分词->去空格空行->自己手动去除停用词->计算频率生成字典->调用wordcloud.generate_from_frequencies()->保存图
这种方法是理想方法

注意!wordcloud.generate()的参数是字符串,wordcloud.generate_from_frequencies()的参数是字典
你们会注意到,【基于频率生成词云】操作会麻烦一些,需要手动去除停用词。笨方法,但是有用。
看源码,对于stopword的操作,如果调用WordCloud()进行对象的创建,这个创建过程是没有办法处理字典元素的,很蠢
stopwords = set([i.lower() for i in self.stopwords])
if self.collocations:
word_counts = unigrams_and_bigrams(words, stopwords, self.normalize_plurals, self.collocation_threshold)
else:
words = [word for word in words if word.lower() not in stopwords]
word_counts, _ = process_tokens(words, self.normalize_plurals)
介绍库
Jieba库
jieba库是一个方便实用的中文文本分词工具,被广泛应用于中文文本处理和自然语言处理的各个领域。支持三种分词模式:精确模式、全模式和搜索引擎模式。本文使用全模式。
如果想对jieba库的分词模式有更深入的了解,可以看这篇:jieba分词有哪些模式?
Wordcloud库
wordcloud是一个用于生成词云图的Python库。词云图是一种可视化方式,通过将文本中的单词按照频率和重要性进行布局,形成一个类似云朵的图形,其中频率高的单词通常显示得更大、更突出。
代码+解释
导入相关库
from os import path
import jieba
from collections import Counter
from wordcloud import WordCloud, ImageColorGenerator
import numpy as np
from PIL import Image
from os import path: 导入os模块中的path子模块。path模块提供了与文件路径相关的功能,例如文件路径的拼接、判断路径是否存在等。
import jieba: 导入jieba模块。jieba是一个中文分词库,用于将中文文本分割成单词或词语。
from collections import Counter: 从collections模块中导入Counter类。Counter是一个用于计数的工具类,可以用于统计元素出现的次数。
from wordcloud import WordCloud, ImageColorGenerator: 从wordcloud模块中导入WordCloud和ImageColorGenerator类。WordCloud是一个用于生成词云的工具,ImageColorGenerator用于生成基于图像颜色的词云。
import numpy as np: 导入numpy模块,并将其命名为np。numpy是一个用于进行科学计算的库,提供了高效的数组操作和数值计算功能。
from PIL import Image: 从PIL模块中导入Image类。PIL是Python Imaging Library的缩写,提供了图像处理的功能,Image类用于表示和操作图像。
路径设置
# 获取路径
d = path.dirname(__file__)
这行代码用于获取当前脚本文件的目录路径,并将其赋值给变量d。
# 下面四个自行变换
TXT_path = path.join(d, 'doc//浪潮之巅.txt') # 文本
MASK_path = path.join(d, 'pic//雾雨魔理沙.png') # 图片
STOPWORDS_path = path.join(d, r'doc//stopwords_cn.txt') # 停用词
FONT_path = path.join(d, 'font//msyh.ttf') # 字体
USERDICT_path = path.join(d, 'doc//自定义词组.txt')
这些行代码定义了几个文件的路径,包括文本文件路径TXT_path、图片文件路径MASK_path、停用词文件路径STOPWORDS_path、字体文件路径FONT_path和自定义词典文件路径USERDICT_path。这些文件路径可以根据实际情况进行修改。
# 找到txt文件
text = open(TXT_path, encoding='UTF-8').read()
这行代码打开指定路径的文本文件,并将文件内容读取到变量text中。
# 找到mask文件
mask = np.array(Image.open(MASK_path))这行代码打开指定路径的图片文件,并将其转换为numpy数组,存储在变量mask中。这个图片将用作词云的形状。
# 导入自定义词典
jieba.load_userdict(USERDICT_path)这行代码导入自定义词典,以便中文分词时使用。自定义词典包含一些用户指定的词语,可以影响分词结果。
准备工作
# 提取背景颜色
bg_color = ImageColorGenerator(mask, default_color=None)这行代码根据图片的颜色生成背景颜色生成器,用于词云的颜色设置。
# 若是中文文本,则先进行分词操作
# cut_all是分词模式,True是全模式,False是精准模式,默认False
wordTemp = jieba.lcut(text, cut_all=True)这行代码使用jieba对文本进行分词操作,将分词结果存储在变量wordTemp中。cut_all=True表示使用全模式,即将文本中的所有可能成词的部分都进行切分。
words = []
# 设定停用词表
stopword = [line.strip() for line in open(STOPWORDS_path, 'r', encoding='UTF-8').readlines()]
# 载入词
for w in wordTemp:
if w not in stopword:
words.append(w)这部分代码对分词结果进行处理,首先定义一个空列表words。然后从停用词表中加载停用词,停用词表文件的路径由STOPWORDS_path指定。接下来,对每个分词结果进行检查,如果它不在停用词表中,就将其添加到words列表中。
# 去除空格
words = [item.strip() for item in words if item.strip() != '']这行代码对words列表中的每个词去除首尾的空格。
# 去停用词之后的词频统计结果
frequency = dict(Counter(words))这行代码使用Counter类对去除停用词之后的词列表进行词频统计,结果存储在字典frequency中。
生成词云
wc = WordCloud(background_color="white", # 设置背景颜色
max_words=500, # 词云显示的最大词数
mask=mask, # 设置背景图片
font_path=FONT_path, 这行代码创建了一个`WordCloud`对象`wc`,用于生成词云图。其中的
# 词频生成词云
wc.generate_from_frequencies(frequency)
# 文本生成词云
# wc.generate(text)background_color:词云的背景颜色,这里设置为白色。
max_words:词云显示的最大词数,这里设置为500。
mask:词云的背景图片,使用之前读取的图片数组mask。
font_path:词云中使用的字体文件路径,由变量FONT_path指定。
这部分代码用于生成词云。根据词频统计结果frequency生成词云图,方法是调用generate_from_frequencies函数。另外,也可以根据文本生成词云,将注释的一行取消注释即可。
WordCloud参数详解看这里:词云-WordCloud参数详解
wc.to_file('output.png')这行代码将生成的词云图保存为名为output.png的文件。
综上所述,这段代码的功能是读取指定的文本文件并进行中文分词,然后根据分词结果生成词云图,并将生成的词云图保存为文件。
文章转载自:这可就有点麻烦了