开始使用完全分片数据并行(FSDP)
原文:
pytorch.org/tutorials/intermediate/FSDP_tutorial.html译者:飞龙
作者:Hamid Shojanazeri,Yanli Zhao,Shen Li
注意
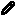 在github上查看并编辑本教程。
在github上查看并编辑本教程。
在大规模训练 AI 模型是一项具有挑战性的任务,需要大量的计算能力和资源。同时,处理这些非常大模型的训练也伴随着相当大的工程复杂性。PyTorch FSDP,在 PyTorch 1.11 中发布,使这变得更容易。
在本教程中,我们展示了如何使用FSDP APIs,用于简单的 MNIST 模型,可以扩展到其他更大的模型,比如HuggingFace BERT 模型,GPT 3 模型高达 1T 参数。示例 DDP MNIST 代码是从这里借鉴的。
FSDP 是如何工作的
在DistributedDataParallel(DDP)训练中,每个进程/工作器拥有模型的副本并处理一批数据,最后使用全局归约来汇总不同工作器上的梯度。在 DDP 中,模型权重和优化器状态在所有工作器之间复制。FSDP 是一种数据并行 ism,它在 DDP 等级之间分片模型参数、优化器状态和梯度。
使用 FSDP 进行训练时,GPU 内存占用比在所有工作节点上使用 DDP 进行训练时要小。这使得一些非常大的模型的训练变得可行,因为可以容纳更大的模型或批量大小在设备上。但这也会增加通信量。通过内部优化,如重叠通信和计算,可以减少通信开销。

FSDP 工作流程
在高层次上,FSDP 的工作方式如下:
在构造函数中
- 分片模型参数和每个等级只保留自己的分片
在前向路径
运行 all_gather 来收集所有等级的所有碎片,以恢复此 FSDP 单元中的完整参数。
进行前向计算
丢弃刚收集的参数分片
在反向路径中
运行 all_gather 来收集所有等级的所有碎片,以恢复此 FSDP 单元中的完整参数。
运行反向计算
运行 reduce_scatter 来同步梯度
丢弃参数。
将 FSDP 的分片视为将 DDP 梯度全局归约分解为归约散射和全局聚集的一种方式。具体来说,在反向传播过程中,FSDP 减少并散射梯度,确保每个秩具有梯度的一个片段。然后在优化器步骤中更新相应的参数片段。最后,在随后的前向传播过程中,它执行全局聚集操作来收集和组合更新的参数片段。

FSDP Allreduce
如何使用 FSDP
在这里,我们使用一个玩具模型来对 MNIST 数据集进行训练,以演示目的。这些 API 和逻辑也可以应用于训练更大的模型。
设置
1.1 安装 PyTorch 和 Torchvision
pip3 install --pre torch torchvision torchaudio -f https://download.pytorch.org/whl/nightly/cu113/torch_nightly.html
我们将以下代码片段添加到一个名为“FSDP_mnist.py”的 Python 脚本中。
1.2 导入必要的包
注意
本教程适用于 PyTorch 版本 1.12 及更高版本。如果您使用的是早期版本,请将所有的 size_based_auto_wrap_policy 实例替换为 default_auto_wrap_policy。
# Based on: https://github.com/pytorch/examples/blob/master/mnist/main.py
import os
import argparse
import functools
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.fully_sharded_data_parallel import (
CPUOffload,
BackwardPrefetch,
)
from torch.distributed.fsdp.wrap import (
size_based_auto_wrap_policy,
enable_wrap,
wrap,
)
1.3 分布式训练设置。正如我们提到的,FSDP 是一种数据并行 ism,它需要一个分布式训练环境,因此我们在这里使用两个辅助函数来初始化分布式训练的进程并进行清理。
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
2.1 定义我们的手写数字分类的玩具模型。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
2.2 定义一个训练函数。
def train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=None):
model.train()
ddp_loss = torch.zeros(2).to(rank)
if sampler:
sampler.set_epoch(epoch)
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(rank), target.to(rank)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target, reduction='sum')
loss.backward()
optimizer.step()
ddp_loss[0] += loss.item()
ddp_loss[1] += len(data)
dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM)
if rank == 0:
print('Train Epoch: {} \tLoss: {:.6f}'.format(epoch, ddp_loss[0] / ddp_loss[1]))
2.3 定义一个验证函数
def test(model, rank, world_size, test_loader):
model.eval()
correct = 0
ddp_loss = torch.zeros(3).to(rank)
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(rank), target.to(rank)
output = model(data)
ddp_loss[0] += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
ddp_loss[1] += pred.eq(target.view_as(pred)).sum().item()
ddp_loss[2] += len(data)
dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM)
if rank == 0:
test_loss = ddp_loss[0] / ddp_loss[2]
print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, int(ddp_loss[1]), int(ddp_loss[2]),
100. * ddp_loss[1] / ddp_loss[2]))
2.4 定义一个分布式训练函数,将模型包装在 FSDP 中
注意:为了保存 FSDP 模型,我们需要在每个排名上调用 state_dict,然后在排名 0 上保存整体状态。
def fsdp_main(rank, world_size, args):
setup(rank, world_size)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
sampler1 = DistributedSampler(dataset1, rank=rank, num_replicas=world_size, shuffle=True)
sampler2 = DistributedSampler(dataset2, rank=rank, num_replicas=world_size)
train_kwargs = {
'batch_size': args.batch_size, 'sampler': sampler1}
test_kwargs = {
'batch_size': args.test_batch_size, 'sampler': sampler2}
cuda_kwargs = {
'num_workers': 2,
'pin_memory': True,
'shuffle': False}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
my_auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=100
)
torch.cuda.set_device(rank)
init_start_event = torch.cuda.Event(enable_timing=True)
init_end_event = torch.cuda.Event(enable_timing=True)
model = Net().to(rank)
model = FSDP(model)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
init_start_event.record()
for epoch in range(1, args.epochs + 1):
train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=sampler1)
test(model, rank, world_size, test_loader)
scheduler.step()
init_end_event.record()
if rank == 0:
print(f"CUDA event elapsed time: {
init_start_event.elapsed_time(init_end_event) / 1000}sec")
print(f"{
model}")
if args.save_model:
# use a barrier to make sure training is done on all ranks
dist.barrier()
states = model.state_dict()
if rank == 0:
torch.save(states, "mnist_cnn.pt")
cleanup()
2.5 最后,解析参数并设置主函数
if __name__ == '__main__':
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
torch.manual_seed(args.seed)
WORLD_SIZE = torch.cuda.device_count()
mp.spawn(fsdp_main,
args=(WORLD_SIZE, args),
nprocs=WORLD_SIZE,
join=True)
我们已记录了 CUDA 事件来测量 FSDP 模型特定部分的时间。CUDA 事件时间为 110.85 秒。
python FSDP_mnist.py
CUDA event elapsed time on training loop 40.67462890625sec
使用 FSDP 包装模型后,模型将如下所示,我们可以看到模型已经被包装在一个 FSDP 单元中。或者,我们将考虑接下来添加 fsdp_auto_wrap_policy,并讨论其中的区别。
FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(dropout1): Dropout(p=0.25, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
(fc1): Linear(in_features=9216, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
)
)
以下是在 g4dn.12.xlarge AWS EC2 实例上使用 4 个 GPU 进行 FSDP MNIST 训练时从 PyTorch Profiler 捕获的峰值内存使用情况。

FSDP 峰值内存使用量
在 FSDP 中应用fsdp_auto_wrap_policy,否则,FSDP 将把整个模型放在一个 FSDP 单元中,这将降低计算效率和内存效率。它的工作方式是,假设您的模型包含 100 个线性层。如果您对模型进行 FSDP 处理,那么只会有一个包含整个模型的 FSDP 单元。在这种情况下,allgather 将收集所有 100 个线性层的完整参数,因此不会为参数分片节省 CUDA 内存。此外,对于所有 100 个线性层,只有一个阻塞的 allgather 调用,层之间不会有通信和计算重叠。
为了避免这种情况,您可以传入一个 fsdp_auto_wrap_policy,当满足指定条件(例如大小限制)时,将封装当前的 FSDP 单元并自动启动一个新的。这样,您将拥有多个 FSDP 单元,每次只需要一个 FSDP 单元收集完整参数。例如,假设您有 5 个 FSDP 单元,每个包含 20 个线性层。然后,在前向传播中,第一个 FSDP 单元将收集前 20 个线性层的参数,进行计算,丢弃参数,然后继续下一个 20 个线性层。因此,在任何时候,每个 rank 只会实现 20 个线性层的参数/梯度,而不是 100 个。
为了在 2.4 中这样做,我们定义了 auto_wrap_policy 并将其传递给 FSDP 包装器,在以下示例中,my_auto_wrap_policy 定义了如果该层中的参数数量大于 100,则该层可以被 FSDP 包装或分片。如果该层中的参数数量小于 100,则它将与其他小层一起被 FSDP 包装。找到一个最佳的自动包装策略是具有挑战性的,PyTorch 将在将来为此配置添加自动调整功能。没有自动调整工具,最好通过实验使用不同的自动包装策略来分析您的工作流程,并找到最佳策略。
my_auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=20000
)
torch.cuda.set_device(rank)
model = Net().to(rank)
model = FSDP(model,
fsdp_auto_wrap_policy=my_auto_wrap_policy)
应用 fsdp_auto_wrap_policy,模型将如下:
FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(dropout1): Dropout(p=0.25, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
(fc1): FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Linear(in_features=9216, out_features=128, bias=True)
)
)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
)
python FSDP_mnist.py
CUDA event elapsed time on training loop 41.89130859375sec
以下是在 g4dn.12.xlarge AWS EC2 实例上使用 4 个 GPU 进行 MNIST 训练时,从 PyTorch Profiler 捕获的 FSDP 自动包装策略的峰值内存使用情况。可以观察到,与未应用自动包装策略的 FSDP 相比,每个设备上的峰值内存使用量较小,从约 75 MB 降至 66 MB。

使用 Auto_wrap 策略的 FSDP 峰值内存使用量
CPU 卸载:如果模型非常庞大,即使使用 FSDP 也无法适应 GPU,那么 CPU 卸载可能会有所帮助。
目前,仅支持参数和梯度的 CPU 卸载。可以通过传入 cpu_offload=CPUOffload(offload_params=True)来启用。
请注意,目前这将隐式地启用梯度卸载到 CPU,以便参数和梯度在同一设备上与优化器一起工作。此 API 可能会发生变化。默认值为 None,在这种情况下将不会进行卸载。
使用这个功能可能会显著减慢训练速度,因为频繁地从主机复制张量到设备,但它可以帮助提高内存效率并训练更大规模的模型。
在 2.4 版本中,我们只是将其添加到 FSDP 包装器中。
model = FSDP(model,
fsdp_auto_wrap_policy=my_auto_wrap_policy,
cpu_offload=CPUOffload(offload_params=True))
将其与 DDP 进行比较,如果在 2.4 中我们只是正常地将模型包装在 DPP 中,并保存更改在“DDP_mnist.py”中。
model = Net().to(rank)
model = DDP(model)
python DDP_mnist.py
CUDA event elapsed time on training loop 39.77766015625sec
以下是在 g4dn.12.xlarge AWS EC2 实例上使用 4 个 GPU 进行 DDP MNIST 训练时从 PyTorch 分析器中捕获的峰值内存使用情况。
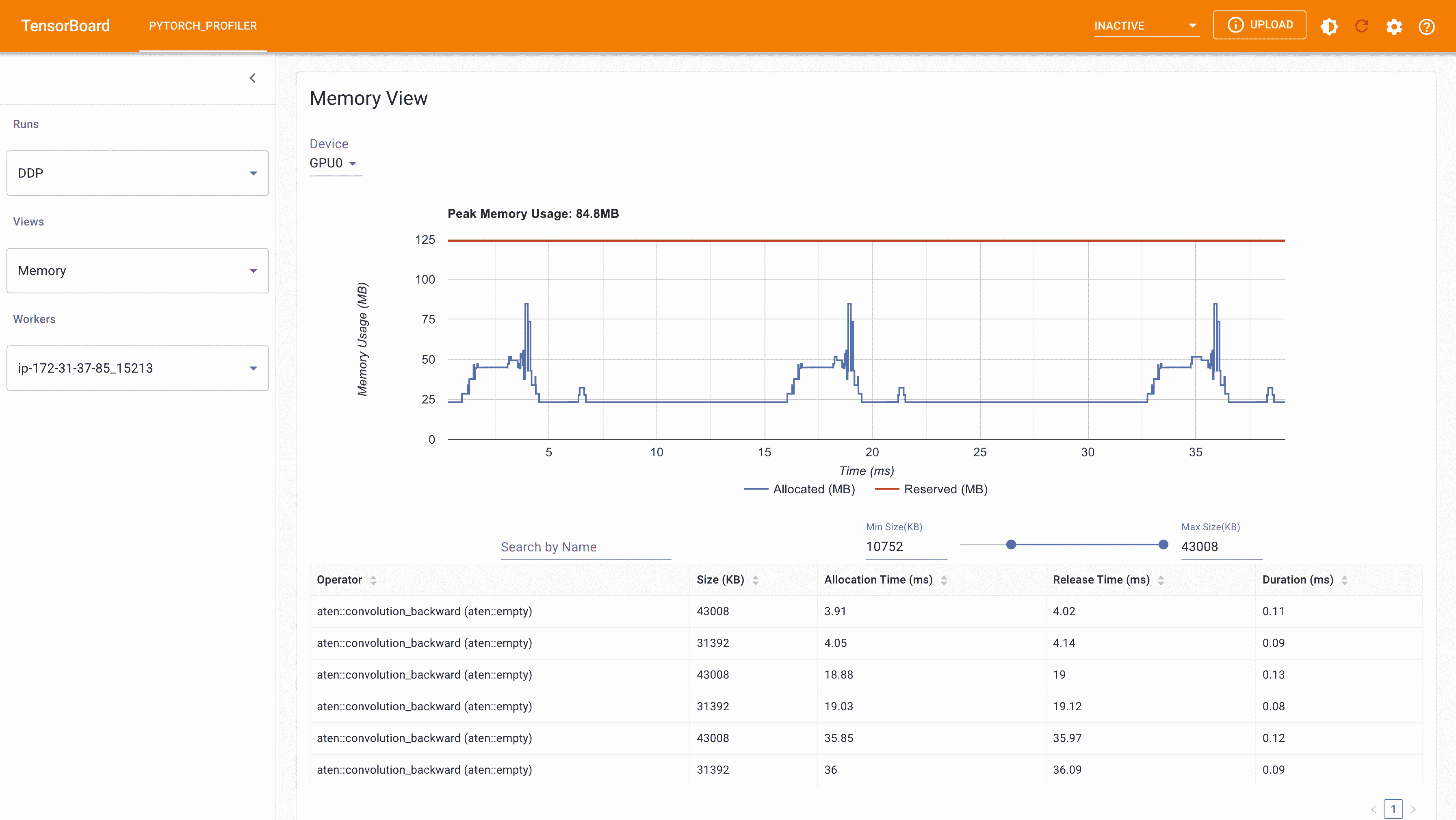
DDP 使用 Auto_wrap 策略的峰值内存使用量
考虑到我们在这里定义的玩具示例和微小的 MNIST 模型,我们可以观察到 DDP 和 FSDP 的峰值内存使用之间的差异。在 DDP 中,每个进程持有模型的副本,因此内存占用量较高,而与 DDP 排名相比,FSDP 将模型参数、优化器状态和梯度进行分片。使用 auto_wrap 策略的 FSDP 的峰值内存使用量最低,其次是 FSDP 和 DDP。
此外,从时间上看,考虑到小模型并在单台机器上运行训练,FSDP 在有或没有自动包装策略的情况下几乎与 DDP 一样快。这个例子并不代表大多数真实应用程序,有关 DDP 和 FSDP 的详细分析和比较,请参考这篇博客文章。
使用完全分片数据并行(FSDP)进行高级模型训练。
原文:
pytorch.org/tutorials/intermediate/FSDP_adavnced_tutorial.html译者:飞龙
作者:Hamid Shojanazeri,Less Wright,Rohan Varma,Yanli Zhao
本教程介绍了 PyTorch 1.12 版本中 Fully Sharded Data Parallel(FSDP)的更高级特性。要熟悉 FSDP,请参考FSDP 入门教程。
在本教程中,我们使用 FSDP 对 HuggingFace(HF)的 T5 模型进行微调,作为文本摘要的工作示例。
这个例子使用了 Wikihow,为了简单起见,我们将展示在一个单节点上进行训练,使用带有 8 个 A100 GPU 的 P4dn 实例。我们很快将在多节点集群上发布一篇关于大规模 FSDP 训练的博客文章,请关注 PyTorch 的官方媒体渠道。
FSDP 是一个已经准备好的软件包,专注于易用性、性能和长期支持。FSDP 的主要优势之一是减少每个 GPU 上的内存占用。这使得可以使用更低的总内存训练更大的模型,同时利用计算和通信的重叠来高效训练模型。这种减少的内存压力可以用来训练更大的模型或增加批量大小,潜在地帮助提高整体训练吞吐量。您可以在这里阅读更多关于 PyTorch FSDP 的信息。
本教程中的 FSDP 功能
Transformer 自动包装策略
混合精度
在设备上初始化 FSDP 模型
分片策略
向后预取
通过流式传输保存模型检查点到 CPU
FSDP 工作原理回顾
在高层次上,FDSP 的工作方式如下:
在构造函数中
- 分片模型参数,每个等级只保留自己的分片
在前向传播中
运行 all_gather 以收集所有排名的所有碎片,以恢复此 FSDP 单元的完整参数 运行前向计算
丢弃刚刚收集的非所有者参数分片以释放内存
在反向传递中
运行 all_gather 以收集所有等级的所有碎片,以恢复此 FSDP 单元中的完整参数 运行向后计算
丢弃非所有者参数以释放内存。
运行 reduce_scatter 以同步梯度。
微调 HF T5
HF T5 预训练模型有四种不同大小可供选择,从参数为 6000 万的小型模型到参数为 110 亿的 XXL 模型。在本教程中,我们演示了使用 WikiHow 数据集对 T5 3B 进行微调,以用于文本摘要。本教程的主要重点是突出 FSDP 中可用的不同功能,这些功能有助于训练超过 3B 参数的大规模模型。此外,我们还介绍了基于 Transformer 的模型的特定功能。本教程的代码可在Pytorch 示例中找到。
设置
1.1 安装 PyTorch 最新版本
我们将安装 PyTorch 的 nightlies 版本,因为一些功能,比如激活检查点,在 nightlies 版本中可用,并将在 1.12 版本之后的下一个 PyTorch 发布中添加。
pip3 install --pre torch torchvision torchaudio -f https://download.pytorch.org/whl/nightly/cu113/torch_nightly.html
1.2 数据集设置
请创建一个名为 data 的文件夹,从wikihowAll.csv和wikihowSep.cs下载 WikiHow 数据集,并将它们放在 data 文件夹中。我们将使用来自summarization_dataset的 wikihow 数据集。
接下来,我们将以下代码片段添加到一个名为“T5_training.py”的 Python 脚本中。
注意
本教程的完整源代码可在PyTorch 示例中找到。
1.3 导入必要的包:
import os
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from transformers import AutoTokenizer, GPT2TokenizerFast
from transformers import T5Tokenizer, T5ForConditionalGeneration
import functools
from torch.optim.lr_scheduler import StepLR
import torch.nn.functional as F
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
from transformers.models.t5.modeling_t5 import T5Block
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import (
checkpoint_wrapper,
CheckpointImpl,
apply_activation_checkpointing_wrapper)
from torch.distributed.fsdp import (
FullyShardedDataParallel as FSDP,
MixedPrecision,
BackwardPrefetch,
ShardingStrategy,
FullStateDictConfig,
StateDictType,
)
from torch.distributed.fsdp.wrap import (
transformer_auto_wrap_policy,
enable_wrap,
wrap,
)
from functools import partial
from torch.utils.data import DataLoader
from pathlib import Path
from summarization_dataset import *
from transformers.models.t5.modeling_t5 import T5Block
from typing import Type
import time
import tqdm
from datetime import datetime
1.4 分布式训练设置。在这里,我们使用两个辅助函数来初始化分布式训练的进程,然后在训练完成后进行清理。在本教程中,我们将使用 torch elastic,使用torchrun,它会自动设置工作进程的 RANK 和 WORLD_SIZE。
def setup():
# initialize the process group
dist.init_process_group("nccl")
def cleanup():
dist.destroy_process_group()
2.1 设置 HuggingFace T5 模型:
def setup_model(model_name):
model = T5ForConditionalGeneration.from_pretrained(model_name)
tokenizer = T5Tokenizer.from_pretrained(model_name)
return model, tokenizer
我们还在这里添加了一些用于日期和格式化内存指标的辅助函数。
def get_date_of_run():
"""create date and time for file save uniqueness
example: 2022-05-07-08:31:12_PM'
"""
date_of_run = datetime.now().strftime("%Y-%m-%d-%I:%M:%S_%p")
print(f"--> current date and time of run = {
date_of_run}")
return date_of_run
def format_metrics_to_gb(item):
"""quick function to format numbers to gigabyte and round to 4 digit precision"""
metric_num = item / g_gigabyte
metric_num = round(metric_num, ndigits=4)
return metric_num
2.2 定义一个训练函数:
def train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=None):
model.train()
local_rank = int(os.environ['LOCAL_RANK'])
fsdp_loss = torch.zeros(2).to(local_rank)
if sampler:
sampler.set_epoch(epoch)
if rank==0:
inner_pbar = tqdm.tqdm(
range(len(train_loader)), colour="blue", desc="r0 Training Epoch"
)
for batch in train_loader:
for key in batch.keys():
batch[key] = batch[key].to(local_rank)
optimizer.zero_grad()
output = model(input_ids=batch["source_ids"],attention_mask=batch["source_mask"],labels=batch["target_ids"] )
loss = output["loss"]
loss.backward()
optimizer.step()
fsdp_loss[0] += loss.item()
fsdp_loss[1] += len(batch)
if rank==0:
inner_pbar.update(1)
dist.all_reduce(fsdp_loss, op=dist.ReduceOp.SUM)
train_accuracy = fsdp_loss[0] / fsdp_loss[1]
if rank == 0:
inner_pbar.close()
print(
f"Train Epoch: \t{
epoch}, Loss: \t{
train_accuracy:.4f}"
)
return train_accuracy
2.3 定义一个验证函数:
def validation(model, rank, world_size, val_loader):
model.eval()
correct = 0
local_rank = int(os.environ['LOCAL_RANK'])
fsdp_loss = torch.zeros(3).to(local_rank)
if rank == 0:
inner_pbar = tqdm.tqdm(
range(len(val_loader)), colour="green", desc="Validation Epoch"
)
with torch.no_grad():
for batch in val_loader:
for key in batch.keys():
batch[key] = batch[key].to(local_rank)
output = model(input_ids=batch["source_ids"],attention_mask=batch["source_mask"],labels=batch["target_ids"])
fsdp_loss[0] += output["loss"].item() # sum up batch loss
fsdp_loss[1] += len(batch)
if rank==0:
inner_pbar.update(1)
dist.all_reduce(fsdp_loss, op=dist.ReduceOp.SUM)
val_loss = fsdp_loss[0] / fsdp_loss[1]
if rank == 0:
inner_pbar.close()
print(f"Validation Loss: {
val_loss:.4f}")
return val_loss
定义一个包装模型在 FSDP 中的分布式训练函数。
def fsdp_main(args):
model, tokenizer = setup_model("t5-base")
local_rank = int(os.environ['LOCAL_RANK'])
rank = int(os.environ['RANK'])
world_size = int(os.environ['WORLD_SIZE'])
dataset = load_dataset('wikihow', 'all', data_dir='data/')
print(dataset.keys())
print("Size of train dataset: ", dataset['train'].shape)
print("Size of Validation dataset: ", dataset['validation'].shape)
#wikihow(tokenizer, type_path, num_samples, input_length, output_length, print_text=False)
train_dataset = wikihow(tokenizer, 'train', 1500, 512, 150, False)
val_dataset = wikihow(tokenizer, 'validation', 300, 512, 150, False)
sampler1 = DistributedSampler(train_dataset, rank=rank, num_replicas=world_size, shuffle=True)
sampler2 = DistributedSampler(val_dataset, rank=rank, num_replicas=world_size)
setup()
train_kwargs = {
'batch_size': args.batch_size, 'sampler': sampler1}
test_kwargs = {
'batch_size': args.test_batch_size, 'sampler': sampler2}
cuda_kwargs = {
'num_workers': 2,
'pin_memory': True,
'shuffle': False}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
train_loader = torch.utils.data.DataLoader(train_dataset,**train_kwargs)
val_loader = torch.utils.data.DataLoader(val_dataset, **test_kwargs)
t5_auto_wrap_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
T5Block,
},
)
sharding_strategy: ShardingStrategy = ShardingStrategy.SHARD_GRAD_OP #for Zero2 and FULL_SHARD for Zero3
torch.cuda.set_device(local_rank)
#init_start_event = torch.cuda.Event(enable_timing=True)
#init_end_event = torch.cuda.Event(enable_timing=True)
#init_start_event.record()
bf16_ready = (
torch.version.cuda
and torch.cuda.is_bf16_supported()
and LooseVersion(torch.version.cuda) >= "11.0"
and dist.is_nccl_available()
and nccl.version() >= (2, 10)
)
if bf16_ready:
mp_policy = bfSixteen
else:
mp_policy = None # defaults to fp32
# model is on CPU before input to FSDP
model = FSDP(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=mp_policy,
#sharding_strategy=sharding_strategy,
device_id=torch.cuda.current_device())
optimizer = optim.AdamW(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
best_val_loss = float("inf")
curr_val_loss = float("inf")
file_save_name = "T5-model-"
if rank == 0:
time_of_run = get_date_of_run()
dur = []
train_acc_tracking = []
val_acc_tracking = []
training_start_time = time.time()
if rank == 0 and args.track_memory:
mem_alloc_tracker = []
mem_reserved_tracker = []
for epoch in range(1, args.epochs + 1):
t0 = time.time()
train_accuracy = train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=sampler1)
if args.run_validation:
curr_val_loss = validation(model, rank, world_size, val_loader)
scheduler.step()
if rank == 0:
print(f"--> epoch {
epoch} completed...entering save and stats zone")
dur.append(time.time() - t0)
train_acc_tracking.append(train_accuracy.item())
if args.run_validation:
val_acc_tracking.append(curr_val_loss.item())
if args.track_memory:
mem_alloc_tracker.append(
format_metrics_to_gb(torch.cuda.memory_allocated())
)
mem_reserved_tracker.append(
format_metrics_to_gb(torch.cuda.memory_reserved())
)
print(f"completed save and stats zone...")
if args.save_model and curr_val_loss < best_val_loss:
# save
if rank == 0:
print(f"--> entering save model state")
save_policy = FullStateDictConfig(offload_to_cpu=True, rank0_only=True)
with FSDP.state_dict_type(
model, StateDictType.FULL_STATE_DICT, save_policy
):
cpu_state = model.state_dict()
#print(f"saving process: rank {rank} done w state_dict")
if rank == 0:
print(f"--> saving model ...")
currEpoch = (
"-" + str(epoch) + "-" + str(round(curr_val_loss.item(), 4)) + ".pt"
)
print(f"--> attempting to save model prefix {
currEpoch}")
save_name = file_save_name + "-" + time_of_run + "-" + currEpoch
print(f"--> saving as model name {
save_name}")
torch.save(cpu_state, save_name)
if curr_val_loss < best_val_loss:
best_val_loss = curr_val_loss
if rank==0:
print(f"-->>>> New Val Loss Record: {
best_val_loss}")
dist.barrier()
cleanup()
2.5 解析参数并设置主函数:
if __name__ == '__main__':
# Training settings
parser = argparse.ArgumentParser(description='PyTorch T5 FSDP Example')
parser.add_argument('--batch-size', type=int, default=4, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=4, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=2, metavar='N',
help='number of epochs to train (default: 3)')
parser.add_argument('--lr', type=float, default=.002, metavar='LR',
help='learning rate (default: .002)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--track_memory', action='store_false', default=True,
help='track the gpu memory')
parser.add_argument('--run_validation', action='store_false', default=True,
help='running the validation')
parser.add_argument('--save-model', action='store_false', default=True,
help='For Saving the current Model')
args = parser.parse_args()
torch.manual_seed(args.seed)
fsdp_main(args)
使用 torchrun 运行训练:
torchrun --nnodes 1 --nproc_per_node 4 T5_training.py
转换器包装策略
正如在上一个教程中讨论的,auto_wrap_policy 是 FSDP 功能之一,它使得自动对给定模型进行分片并将模型、优化器和梯度分片放入不同的 FSDP 单元变得容易。
对于一些架构,比如 Transformer 编码器-解码器,模型的一些部分,比如嵌入表,被编码器和解码器共享。在这种情况下,我们需要将嵌入表放在外部 FSDP 单元中,以便从编码器和解码器中访问。此外,通过为 transformer 注册层类,分片计划可以变得更加通信高效。在 PyTorch 1.12 中,FSDP 添加了这种支持,现在我们有了一个用于 transformers 的包装策略。
可以按照以下方式创建,其中 T5Block 代表 T5 变压器层类(包含 MHSA 和 FFN)。
t5_auto_wrap_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
T5Block,
},
)
torch.cuda.set_device(local_rank)
model = FSDP(model,
fsdp_auto_wrap_policy=t5_auto_wrap_policy)
要查看包装的模型,您可以轻松打印模型并直观地检查分片和 FSDP 单元。
混合精度
FSDP 支持灵活的混合精度训练,允许使用任意降低精度类型(如 fp16 或 bfloat16)。目前,BFloat16 仅在安培 GPU 上可用,因此在使用之前需要确认是否有本机支持。例如,在 V100 上,仍然可以运行 BFloat16,但由于它是非本机运行,可能会导致显著的减速。
要检查是否原生支持 BFloat16,您可以使用以下方法:
bf16_ready = (
torch.version.cuda
and torch.cuda.is_bf16_supported()
and LooseVersion(torch.version.cuda) >= "11.0"
and dist.is_nccl_available()
and nccl.version() >= (2, 10)
)
在 FSDP 中混合精度的一个优点是为参数、梯度和缓冲区提供不同精度级别的细粒度控制。
fpSixteen = MixedPrecision(
param_dtype=torch.float16,
# Gradient communication precision.
reduce_dtype=torch.float16,
# Buffer precision.
buffer_dtype=torch.float16,
)
bfSixteen = MixedPrecision(
param_dtype=torch.bfloat16,
# Gradient communication precision.
reduce_dtype=torch.bfloat16,
# Buffer precision.
buffer_dtype=torch.bfloat16,
)
fp32_policy = MixedPrecision(
param_dtype=torch.float32,
# Gradient communication precision.
reduce_dtype=torch.float32,
# Buffer precision.
buffer_dtype=torch.float32,
)
请注意,如果某种类型(参数、减少、缓冲区)未指定,则它们将不会被转换。
这种灵活性使用户可以进行精细的控制,比如只将梯度通信设置为以降低精度进行,而所有参数/缓冲计算则以全精度进行。在节点内通信是主要瓶颈且参数/缓冲必须以全精度进行以避免精度问题的情况下,这种方法可能非常有用。可以使用以下策略来实现:
grad_bf16 = MixedPrecision(reduce_dtype=torch.bfloat16)
在 2.4 版本中,我们只需将相关的混合精度策略添加到 FSDP 包装器中:
model = FSDP(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=bfSixteen)
在我们的实验中,我们观察到使用 BFloat16 进行训练可以加快速度达到 4 倍,并且在一些实验中可以减少大约 30%的内存,这可以用于增加批量大小。
在设备上初始化 FSDP 模型
在 1.12 版本中,FSDP 支持一个 device_id 参数,旨在初始化设备上的输入 CPU 模块。当整个模型无法适应单个 GPU,但适应主机的 CPU 内存时,这将非常有用。当指定 device_id 时,FSDP 将根据每个 FSDP 单元将模型移动到指定的设备上,避免 GPU 内存不足问题,同时初始化速度比基于 CPU 的初始化快数倍。
torch.cuda.set_device(local_rank)
model = FSDP(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=bfSixteen,
device_id=torch.cuda.current_device())
分片策略
默认情况下,FSDP 分片策略被设置为完全分片模型参数,梯度和优化器状态在所有等级之间分片(也称为 Zero3 分片)。如果您希望使用 Zero2 分片策略,仅对优化器状态和梯度进行分片,FSDP 支持通过将分片策略传递给 FSDP 初始化来实现此功能,如下所示:“ShardingStrategy.SHARD_GRAD_OP”,而不是“ShardingStrategy.FULL_SHARD”。
torch.cuda.set_device(local_rank)
model = FSDP(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=bfSixteen,
device_id=torch.cuda.current_device(),
sharding_strategy=ShardingStrategy.SHARD_GRAD_OP # ZERO2)
这将减少 FSDP 中的通信开销,在这种情况下,在前向传播和反向传播后保持完整的参数。
在反向传播过程中,这样做可以节省一次全局聚合操作,从而减少通信量,但会增加内存占用。请注意,完整的模型参数会在反向传播结束时被释放,全局聚合操作将在下一次前向传播中进行。
向后预取
后向预取设置控制了何时应请求下一个 FSDP 单元的参数。通过将其设置为 BACKWARD_PRE,下一个 FSDP 单元的参数可以在当前单元的计算开始之前开始请求并到达。这会重叠所有收集通信和梯度计算,可以增加训练速度,但会略微增加内存消耗。可以在 2.4 版本中的 FSDP 包装器中利用它。
torch.cuda.set_device(local_rank)
model = FSDP(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=bfSixteen,
device_id=torch.cuda.current_device(),
backward_prefetch = BackwardPrefetch.BACKWARD_PRE)
backward_prefetch 有两种模式,BACKWARD_PRE 和 BACKWARD_POST。BACKWARD_POST 意味着直到当前 FSDP 单元处理完成之前,不会请求下一个 FSDP 单元的参数,从而最大限度地减少内存开销。在某些情况下,使用 BACKWARD_PRE 可以将模型训练速度提高 2-10%,对于更大的模型,速度提高更为显著。
模型检查点保存,通过流式传输到 Rank0 CPU。
使用 FULL_STATE_DICT 保存模型检查点,该保存方式与本地模型相同,PyTorch 1.12 提供了一些实用工具来支持保存更大的模型。
首先,可以指定一个 FullStateDictConfig,允许仅在 rank 0 上填充 state_dict 并转移到 CPU。
在使用这种配置时,FSDP 将会收集模型参数,逐个将其转移到 CPU 上,仅在 rank 0 上进行。当 state_dict 最终保存时,它只会在 rank 0 上填充,并包含 CPU 张量。这避免了对于大于单个 GPU 内存的模型可能出现的 OOM,并允许用户对模型进行检查点,其大小大致等于用户机器上可用的 CPU RAM。
这个功能可以按照以下方式运行:
save_policy = FullStateDictConfig(offload_to_cpu=True, rank0_only=True)
with FSDP.state_dict_type(
model, StateDictType.FULL_STATE_DICT, save_policy
):
cpu_state = model.state_dict()
if rank == 0:
save_name = file_save_name + "-" + time_of_run + "-" + currEpoch
torch.save(cpu_state, save_name)
摘要
在本教程中,我们介绍了 Pytorch 1.12 中可用的许多 FSDP 的新功能,并以 HF T5 作为运行示例。特别是对于变压器模型,使用适当的包装策略,以及混合精度和向后预取应该可以加快您的训练速度。此外,诸如在设备上初始化模型和通过流式传输到 CPU 保存检查点等功能应该有助于避免处理大型模型时的 OOM 错误。
我们正在积极努力为下一个版本的 FSDP 添加新功能。如果您有反馈、功能请求、问题或在使用 FSDP 时遇到问题,请随时通过在PyTorch Github 存储库中打开问题与我们联系。
使用 Cpp 扩展自定义流程组后端
原文:
pytorch.org/tutorials/intermediate/process_group_cpp_extension_tutorial.html译者:飞龙
作者:Howard Huang https://github.com/H-Huang,Feng Tian,Shen Li,Min Si
注意
 在 github 上查看并编辑本教程。
在 github 上查看并编辑本教程。
先决条件:
PyTorch 分布式概述
本教程演示了如何实现一个自定义的Backend并将其插入PyTorch 分布式包,使用cpp 扩展。当您需要为硬件定制专门的软件堆栈,或者想要尝试新的集体通信算法时,这将非常有帮助。
基础知识
PyTorch 集体通信支持多种广泛采用的分布式训练功能,包括DistributedDataParallel,ZeroRedundancyOptimizer,FullyShardedDataParallel。为了使相同的集体通信 API 能够与不同的通信后端一起工作,分布式包将集体通信操作抽象为Backend类。不同的后端可以作为Backend的子类使用首选的第三方库来实现。PyTorch 分布式带有三个默认后端,ProcessGroupNCCL,ProcessGroupGloo和ProcessGroupMPI。然而,除了这三个后端之外,还有其他通信库(例如UCC,OneCCL),不同类型的硬件(例如TPU,Trainum)和新兴的通信算法(例如Herring,Reduction Server)。因此,分布式包提供了扩展 API 来允许定制集体通信后端。
以下 4 个步骤展示了如何在 Python 应用程序代码中实现一个虚拟的Backend后端并使用它。请注意,本教程侧重于演示扩展 API,而不是开发一个功能完善的通信后端。因此,dummy后端只涵盖了 API 的一个子集(all_reduce和all_gather),并且只是将张量的值设置为 0。
步骤 1:实现Backend的子类
第一步是实现一个Backend子类,覆盖目标集体通信 API,并运行自定义通信算法。扩展还需要实现一个Work子类,作为通信结果的 future,并允许在应用代码中异步执行。如果扩展使用第三方库,可以在BackendDummy子类中包含头文件并调用库 API。下面的两个代码片段展示了dummy.h和dummy.cpp的实现。请查看dummy collectives存储库以获取完整的实现。
// file name: dummy.hpp
#include <torch/python.h>
#include <torch/csrc/distributed/c10d/Backend.hpp>
#include <torch/csrc/distributed/c10d/Work.hpp>
#include <torch/csrc/distributed/c10d/Store.hpp>
#include <torch/csrc/distributed/c10d/Types.hpp>
#include <torch/csrc/distributed/c10d/Utils.hpp>
#include <pybind11/chrono.h>
namespace c10d {
class BackendDummy : public Backend {
public:
BackendDummy(int rank, int size);
c10::intrusive_ptr<Work> allgather(
std::vector<std::vector<at::Tensor>>& outputTensors,
std::vector<at::Tensor>& inputTensors,
const AllgatherOptions& opts = AllgatherOptions()) override;
c10::intrusive_ptr<Work> allreduce(
std::vector<at::Tensor>& tensors,
const AllreduceOptions& opts = AllreduceOptions()) override;
// The collective communication APIs without a custom implementation
// will error out if invoked by application code.
};
class WorkDummy : public Work {
public:
WorkDummy(
OpType opType,
c10::intrusive_ptr<c10::ivalue::Future> future) // future of the output
: Work(
-1, // rank, only used by recvAnySource, irrelevant in this demo
opType),
future_(std::move(future)) {
}
bool isCompleted() override;
bool isSuccess() const override;
bool wait(std::chrono::milliseconds timeout = kUnsetTimeout) override;
virtual c10::intrusive_ptr<c10::ivalue::Future> getFuture() override;
private:
c10::intrusive_ptr<c10::ivalue::Future> future_;
};
} // namespace c10d
// file name: dummy.cpp
#include "dummy.hpp"
namespace c10d {
// This is a dummy allgather that sets all output tensors to zero
// Modify the implementation to conduct real communication asynchronously
c10::intrusive_ptr<Work> BackendDummy::allgather(
std::vector<std::vector<at::Tensor>>& outputTensors,
std::vector<at::Tensor>& inputTensors,
const AllgatherOptions& /* unused */) {
for (auto& outputTensorVec : outputTensors) {
for (auto& outputTensor : outputTensorVec) {
outputTensor.zero_();
}
}
auto future = c10::make_intrusive<c10::ivalue::Future>(
c10::ListType::create(c10::ListType::create(c10::TensorType::get())));
future->markCompleted(c10::IValue(outputTensors));
return c10::make_intrusive<WorkDummy>(OpType::ALLGATHER, std::move(future));
}
// This is a dummy allreduce that sets all output tensors to zero
// Modify the implementation to conduct real communication asynchronously
c10::intrusive_ptr<Work> BackendDummy::allreduce(
std::vector<at::Tensor>& tensors,
const AllreduceOptions& opts) {
for (auto& tensor : tensors) {
tensor.zero_();
}
auto future = c10::make_intrusive<c10::ivalue::Future>(
c10::ListType::create(c10::TensorType::get()));
future->markCompleted(c10::IValue(tensors));
return c10::make_intrusive<WorkDummy>(OpType::ALLGATHER, std::move(future));
}
} // namespace c10d
步骤 2:暴露扩展 Python API
后端构造函数是从 Python 端调用的,因此扩展还需要向 Python 公开构造函数 API。这可以通过添加以下方法来实现。在这个例子中,store和timeout被BackendDummy实例化方法忽略,因为在这个虚拟实现中没有使用它们。然而,真实世界的扩展应该考虑使用store来执行会合并支持timeout参数。
// file name: dummy.hpp
class BackendDummy : public Backend {
...
<Step 1 code>
...
static c10::intrusive_ptr<Backend> createBackendDummy(
const c10::intrusive_ptr<::c10d::Store>& store,
int rank,
int size,
const std::chrono::duration<float>& timeout);
static void BackendDummyConstructor() __attribute__((constructor)) {
py::object module = py::module::import("torch.distributed");
py::object register_backend =
module.attr("Backend").attr("register_backend");
// torch.distributed.Backend.register_backend will add `dummy` as a
// new valid backend.
register_backend("dummy", py::cpp_function(createBackendDummy));
}
}
// file name: dummy.cpp
c10::intrusive_ptr<Backend> BackendDummy::createBackendDummy(
const c10::intrusive_ptr<::c10d::Store>& /* unused */,
int rank,
int size,
const std::chrono::duration<float>& /* unused */) {
return c10::make_intrusive<BackendDummy>(rank, size);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("createBackendDummy", &BackendDummy::createBackendDummy);
}
步骤 3:构建自定义扩展
现在,扩展源代码文件已经准备好。我们可以使用cpp extensions来构建它。为此,创建一个setup.py文件,准备路径和命令。然后调用python setup.py develop来安装扩展。
如果扩展依赖于第三方库,您还可以在 cpp 扩展 API 中指定libraries_dirs和libraries。请参考torch ucc项目作为一个真实的例子。
# file name: setup.py
import os
import sys
import torch
from setuptools import setup
from torch.utils import cpp_extension
sources = ["src/dummy.cpp"]
include_dirs = [f"{
os.path.dirname(os.path.abspath(__file__))}/include/"]
if torch.cuda.is_available():
module = cpp_extension.CUDAExtension(
name = "dummy_collectives",
sources = sources,
include_dirs = include_dirs,
)
else:
module = cpp_extension.CppExtension(
name = "dummy_collectives",
sources = sources,
include_dirs = include_dirs,
)
setup(
name = "Dummy-Collectives",
version = "0.0.1",
ext_modules = [module],
cmdclass={
'build_ext': cpp_extension.BuildExtension}
)
步骤 4:在应用程序中使用扩展。
安装完成后,您可以在调用init_process_group时方便地使用dummy后端,就像它是一个内置后端一样。
我们可以根据后端来指定调度,方法是改变init_process_group的backend参数。我们可以通过将后端参数指定为cpu:gloo,cuda:dummy,将 CPU 张量的集体分发到gloo后端,将 CUDA 张量的集体分发到dummy后端。
要将所有张量发送到dummy后端,我们可以简单地将dummy指定为后端参数。
import os
import torch
# importing dummy_collectives makes torch.distributed recognize `dummy`
# as a valid backend.
import dummy_collectives
import torch.distributed as dist
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
# Alternatively:
# dist.init_process_group("dummy", rank=0, world_size=1)
dist.init_process_group("cpu:gloo,cuda:dummy", rank=0, world_size=1)
# this goes through gloo
x = torch.ones(6)
dist.all_reduce(x)
print(f"cpu allreduce: {
x}")
# this goes through dummy
if torch.cuda.is_available():
y = x.cuda()
dist.all_reduce(y)
print(f"cuda allreduce: {
y}")
try:
dist.broadcast(y, 0)
except RuntimeError:
print("got RuntimeError when calling broadcast")
使用分布式 RPC 框架入门
原文:
pytorch.org/tutorials/intermediate/rpc_tutorial.html译者:飞龙
作者:Shen Li
注意
 在github中查看和编辑本教程。
在github中查看和编辑本教程。
先决条件:
PyTorch 分布式概述
本教程使用两个简单示例演示如何使用torch.distributed.rpc包构建分布式训练,该包最初作为 PyTorch v1.4 中的实验性功能引入。这两个示例的源代码可以在PyTorch 示例中找到。
之前的教程,使用分布式数据并行开始和使用 PyTorch 编写分布式应用程序,描述了分布式数据并行,支持一种特定的训练范式,其中模型在多个进程中复制,并且每个进程处理输入数据的一个部分。有时,您可能会遇到需要不同训练范式的情况。例如:
在强化学习中,从环境中获取训练数据可能相对昂贵,而模型本身可能非常小。在这种情况下,可能有用的是并行运行多个观察者并共享单个代理。在这种情况下,代理在本地处理训练,但应用程序仍需要库来在观察者和训练者之间发送和接收数据。
您的模型可能太大,无法适应单台机器上的 GPU,因此需要一个库来将模型分割到多台机器上。或者您可能正在实现一个参数服务器训练框架,其中模型参数和训练器位于不同的机器上。
torch.distributed.rpc包可以帮助处理上述情况。在情况 1 中,RPC和RRef允许从一个工作进程发送数据到另一个工作进程,同时轻松引用远程数据对象。在情况 2 中,分布式自动求导和分布式优化器使得执行反向传播和优化器步骤就像是本地训练一样。在接下来的两个部分中,我们将使用一个强化学习示例和一个语言模型示例演示torch.distributed.rpc的 API。请注意,本教程的目标不是构建最准确或高效的模型来解决给定问题,而是展示如何使用torch.distributed.rpc包构建分布式训练应用程序。
使用 RPC 和 RRef 进行分布式强化学习
本部分描述了使用 RPC 构建玩具分布式强化学习模型的步骤,以解决来自OpenAI Gym的 CartPole-v1 问题。策略代码大部分是从现有的单线程示例中借用的,如下所示。我们将跳过“策略”设计的细节,重点放在 RPC 的用法上。
import torch.nn as nn
import torch.nn.functional as F
class Policy(nn.Module):
def __init__(self):
super(Policy, self).__init__()
self.affine1 = nn.Linear(4, 128)
self.dropout = nn.Dropout(p=0.6)
self.affine2 = nn.Linear(128, 2)
def forward(self, x):
x = self.affine1(x)
x = self.dropout(x)
x = F.relu(x)
action_scores = self.affine2(x)
return F.softmax(action_scores, dim=1)
我们准备展示观察者。在这个例子中,每个观察者都创建自己的环境,并等待代理的命令来运行一个剧集。在每个剧集中,一个观察者最多循环n_steps次迭代,在每次迭代中,它使用 RPC 将其环境状态传递给代理,并获得一个动作。然后将该动作应用于其环境,并从环境中获得奖励和下一个状态。之后,观察者使用另一个 RPC 向代理报告奖励。再次请注意,这显然不是最有效的观察者实现。例如,一个简单的优化可以是将当前状态和上一个奖励打包在一个 RPC 中,以减少通信开销。然而,目标是演示 RPC API 而不是构建 CartPole 的最佳求解器。因此,在这个例子中,让我们保持逻辑简单,将这两个步骤明确表示。
import argparse
import gym
import torch.distributed.rpc as rpc
parser = argparse.ArgumentParser(
description="RPC Reinforcement Learning Example",
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
)
parser.add_argument('--world_size', default=2, type=int, metavar='W',
help='number of workers')
parser.add_argument('--log_interval', type=int, default=10, metavar='N',
help='interval between training status logs')
parser.add_argument('--gamma', type=float, default=0.99, metavar='G',
help='how much to value future rewards')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed for reproducibility')
args = parser.parse_args()
class Observer:
def __init__(self):
self.id = rpc.get_worker_info().id
self.env = gym.make('CartPole-v1')
self.env.seed(args.seed)
def run_episode(self, agent_rref):
state, ep_reward = self.env.reset(), 0
for _ in range(10000):
# send the state to the agent to get an action
action = agent_rref.rpc_sync().select_action(self.id, state)
# apply the action to the environment, and get the reward
state, reward, done, _ = self.env.step(action)
# report the reward to the agent for training purpose
agent_rref.rpc_sync().report_reward(self.id, reward)
# finishes after the number of self.env._max_episode_steps
if done:
break
代理的代码稍微复杂一些,我们将其分解为多个部分。在这个例子中,代理既充当训练者又充当主控,它向多个分布式观察者发送命令来运行剧集,并在本地记录所有动作和奖励,这些将在每个剧集后的训练阶段中使用。下面的代码显示了Agent构造函数,其中大多数行都在初始化各种组件。最后的循环在其他工作进程上远程初始化观察者,并在本地保存这些观察者的RRefs。代理将在稍后使用这些观察者的RRefs来发送命令。应用程序不需要担心RRefs的生命周期。每个RRef的所有者维护一个引用计数映射来跟踪其生命周期,并保证只要有任何RRef的活动用户,远程数据对象就不会被删除。有关详细信息,请参阅RRef设计文档。
import gym
import numpy as np
import torch
import torch.distributed.rpc as rpc
import torch.optim as optim
from torch.distributed.rpc import RRef, rpc_async, remote
from torch.distributions import Categorical
class Agent:
def __init__(self, world_size):
self.ob_rrefs = []
self.agent_rref = RRef(self)
self.rewards = {
}
self.saved_log_probs = {
}
self.policy = Policy()
self.optimizer = optim.Adam(self.policy.parameters(), lr=1e-2)
self.eps = np.finfo(np.float32).eps.item()
self.running_reward = 0
self.reward_threshold = gym.make('CartPole-v1').spec.reward_threshold
for ob_rank in range(1, world_size):
ob_info = rpc.get_worker_info(OBSERVER_NAME.format(ob_rank))
self.ob_rrefs.append(remote(ob_info, Observer))
self.rewards[ob_info.id] = []
self.saved_log_probs[ob_info.id] = []
接下来,代理向观察者公开两个 API,用于选择动作和报告奖励。这些函数仅在代理上本地运行,但将通过 RPC 由观察者触发。
class Agent:
...
def select_action(self, ob_id, state):
state = torch.from_numpy(state).float().unsqueeze(0)
probs = self.policy(state)
m = Categorical(probs)
action = m.sample()
self.saved_log_probs[ob_id].append(m.log_prob(action))
return action.item()
def report_reward(self, ob_id, reward):
self.rewards[ob_id].append(reward)
让我们在代理上添加一个run_episode函数,告诉所有观察者执行一个剧集。在这个函数中,首先创建一个列表来收集异步 RPC 的 futures,然后循环遍历所有观察者的RRefs来进行异步 RPC。在这些 RPC 中,代理还将自身的RRef传递给观察者,以便观察者也可以在代理上调用函数。如上所示,每个观察者将向代理发起 RPC,这些是嵌套的 RPC。每个剧集结束后,saved_log_probs和rewards将包含记录的动作概率和奖励。
class Agent:
...
def run_episode(self):
futs = []
for ob_rref in self.ob_rrefs:
# make async RPC to kick off an episode on all observers
futs.append(
rpc_async(
ob_rref.owner(),
ob_rref.rpc_sync().run_episode,
args=(self.agent_rref,)
)
)
# wait until all obervers have finished this episode
for fut in futs:
fut.wait()
最后,在一个剧集结束后,代理需要训练模型,这在下面的finish_episode函数中实现。这个函数中没有 RPC,它主要是从单线程的示例中借用的。因此,我们跳过描述其内容。
class Agent:
...
def finish_episode(self):
# joins probs and rewards from different observers into lists
R, probs, rewards = 0, [], []
for ob_id in self.rewards:
probs.extend(self.saved_log_probs[ob_id])
rewards.extend(self.rewards[ob_id])
# use the minimum observer reward to calculate the running reward
min_reward = min([sum(self.rewards[ob_id]) for ob_id in self.rewards])
self.running_reward = 0.05 * min_reward + (1 - 0.05) * self.running_reward
# clear saved probs and rewards
for ob_id in self.rewards:
self.rewards[ob_id] = []
self.saved_log_probs[ob_id] = []
policy_loss, returns = [], []
for r in rewards[::-1]:
R = r + args.gamma * R
returns.insert(0, R)
returns = torch.tensor(returns)
returns = (returns - returns.mean()) / (returns.std() + self.eps)
for log_prob, R in zip(probs, returns):
policy_loss.append(-log_prob * R)
self.optimizer.zero_grad()
policy_loss = torch.cat(policy_loss).sum()
policy_loss.backward()
self.optimizer.step()
return min_reward
有了Policy、Observer和Agent类,我们准备启动多个进程执行分布式训练。在这个例子中,所有进程都运行相同的run_worker函数,并使用排名来区分它们的角色。排名 0 始终是代理,所有其他排名都是观察者。代理通过反复调用run_episode和finish_episode来充当主控,直到运行奖励超过环境指定的奖励阈值。所有观察者都 passively 等待代理的命令。代码由rpc.init_rpc和rpc.shutdown包装,分别初始化和终止 RPC 实例。更多细节请参阅API 页面。
import os
from itertools import count
import torch.multiprocessing as mp
AGENT_NAME = "agent"
OBSERVER_NAME="obs{}"
def run_worker(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
if rank == 0:
# rank0 is the agent
rpc.init_rpc(AGENT_NAME, rank=rank, world_size=world_size)
agent = Agent(world_size)
print(f"This will run until reward threshold of {
agent.reward_threshold}"
" is reached. Ctrl+C to exit.")
for i_episode in count(1):
agent.run_episode()
last_reward = agent.finish_episode()
if i_episode % args.log_interval == 0:
print(f"Episode {
i_episode}\tLast reward: {
last_reward:.2f}\tAverage reward: "
f"{
agent.running_reward:.2f}")
if agent.running_reward > agent.reward_threshold:
print(f"Solved! Running reward is now {
agent.running_reward}!")
break
else:
# other ranks are the observer
rpc.init_rpc(OBSERVER_NAME.format(rank), rank=rank, world_size=world_size)
# observers passively waiting for instructions from the agent
# block until all rpcs finish, and shutdown the RPC instance
rpc.shutdown()
mp.spawn(
run_worker,
args=(args.world_size, ),
nprocs=args.world_size,
join=True
)
以下是在 world_size=2 时进行训练时的一些示例输出。
This will run until reward threshold of 475.0 is reached. Ctrl+C to exit.
Episode 10 Last reward: 26.00 Average reward: 10.01
Episode 20 Last reward: 16.00 Average reward: 11.27
Episode 30 Last reward: 49.00 Average reward: 18.62
Episode 40 Last reward: 45.00 Average reward: 26.09
Episode 50 Last reward: 44.00 Average reward: 30.03
Episode 60 Last reward: 111.00 Average reward: 42.23
Episode 70 Last reward: 131.00 Average reward: 70.11
Episode 80 Last reward: 87.00 Average reward: 76.51
Episode 90 Last reward: 86.00 Average reward: 95.93
Episode 100 Last reward: 13.00 Average reward: 123.93
Episode 110 Last reward: 33.00 Average reward: 91.39
Episode 120 Last reward: 73.00 Average reward: 76.38
Episode 130 Last reward: 137.00 Average reward: 88.08
Episode 140 Last reward: 89.00 Average reward: 104.96
Episode 150 Last reward: 97.00 Average reward: 98.74
Episode 160 Last reward: 150.00 Average reward: 100.87
Episode 170 Last reward: 126.00 Average reward: 104.38
Episode 180 Last reward: 500.00 Average reward: 213.74
Episode 190 Last reward: 322.00 Average reward: 300.22
Episode 200 Last reward: 165.00 Average reward: 272.71
Episode 210 Last reward: 168.00 Average reward: 233.11
Episode 220 Last reward: 184.00 Average reward: 195.02
Episode 230 Last reward: 284.00 Average reward: 208.32
Episode 240 Last reward: 395.00 Average reward: 247.37
Episode 250 Last reward: 500.00 Average reward: 335.42
Episode 260 Last reward: 500.00 Average reward: 386.30
Episode 270 Last reward: 500.00 Average reward: 405.29
Episode 280 Last reward: 500.00 Average reward: 443.29
Episode 290 Last reward: 500.00 Average reward: 464.65
Solved! Running reward is now 475.3163778435275!
在这个例子中,我们展示了如何使用 RPC 作为通信工具在工作器之间传递数据,以及如何使用 RRef 引用远程对象。当然,您可以直接在ProcessGroup send和recv API 之上构建整个结构,或者使用其他通信/RPC 库。然而,通过使用 torch.distributed.rpc,您可以获得本地支持,并在幕后持续优化性能。
接下来,我们将展示如何结合 RPC 和 RRef 与分布式自动求导和分布式优化器来执行分布式模型并行训练。
使用分布式自动求导和分布式优化器的分布式 RNN
在本节中,我们使用一个 RNN 模型来展示如何使用 RPC API 构建分布式模型并行训练。示例 RNN 模型非常小,可以轻松适应单个 GPU,但我们仍将其层分布到两个不同的工作器上以演示这个想法。开发人员可以应用类似的技术将更大的模型分布到多个设备和机器上。
RNN 模型设计借鉴了 PyTorch 示例 仓库中的单词语言模型,其中包含三个主要组件,一个嵌入表,一个LSTM层和一个解码器。下面的代码将嵌入表和解码器包装成子模块,以便它们的构造函数可以传递给 RPC API。在EmbeddingTable子模块中,我们故意将Embedding层放在 GPU 上以涵盖使用情况。在 v1.4 中,RPC 始终在目标工作器上创建 CPU 张量参数或返回值。如果函数接受 GPU 张量,则需要显式将其移动到适当的设备上。
class EmbeddingTable(nn.Module):
r"""
Encoding layers of the RNNModel
"""
def __init__(self, ntoken, ninp, dropout):
super(EmbeddingTable, self).__init__()
self.drop = nn.Dropout(dropout)
self.encoder = nn.Embedding(ntoken, ninp).cuda()
self.encoder.weight.data.uniform_(-0.1, 0.1)
def forward(self, input):
return self.drop(self.encoder(input.cuda()).cpu()
class Decoder(nn.Module):
def __init__(self, ntoken, nhid, dropout):
super(Decoder, self).__init__()
self.drop = nn.Dropout(dropout)
self.decoder = nn.Linear(nhid, ntoken)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-0.1, 0.1)
def forward(self, output):
return self.decoder(self.drop(output))
通过上述子模块,我们现在可以使用 RPC 将它们组合在一起创建一个 RNN 模型。在下面的代码中,ps代表参数服务器,它承载嵌入表和解码器的参数。构造函数使用remote API 在参数服务器上创建一个EmbeddingTable对象和一个Decoder对象,并在本地创建LSTM子模块。在前向传播过程中,训练器使用EmbeddingTable的RRef来找到远程子模块,并通过 RPC 将输入数据传递给EmbeddingTable并获取查找结果。然后,它通过本地的LSTM层运行嵌入,最后使用另一个 RPC 将输出发送到Decoder子模块。通常,为了实现分布式模型并行训练,开发人员可以将模型划分为子模块,调用 RPC 远程创建子模块实例,并在必要时使用RRef来找到它们。正如您在下面的代码中所看到的,它看起来非常类似于单机模型并行训练。主要区别是用 RPC 函数替换Tensor.to(device)。
class RNNModel(nn.Module):
def __init__(self, ps, ntoken, ninp, nhid, nlayers, dropout=0.5):
super(RNNModel, self).__init__()
# setup embedding table remotely
self.emb_table_rref = rpc.remote(ps, EmbeddingTable, args=(ntoken, ninp, dropout))
# setup LSTM locally
self.rnn = nn.LSTM(ninp, nhid, nlayers, dropout=dropout)
# setup decoder remotely
self.decoder_rref = rpc.remote(ps, Decoder, args=(ntoken, nhid, dropout))
def forward(self, input, hidden):
# pass input to the remote embedding table and fetch emb tensor back
emb = _remote_method(EmbeddingTable.forward, self.emb_table_rref, input)
output, hidden = self.rnn(emb, hidden)
# pass output to the rremote decoder and get the decoded output back
decoded = _remote_method(Decoder.forward, self.decoder_rref, output)
return decoded, hidden
在介绍分布式优化器之前,让我们添加一个辅助函数来生成模型参数的 RRef 列表,这将被分布式优化器使用。在本地训练中,应用程序可以调用Module.parameters()来获取所有参数张量的引用,并将其传递给本地优化器进行后续更新。然而,在分布式训练场景中,相同的 API 不起作用,因为一些参数存在于远程机器上。因此,分布式优化器不是接受参数Tensors列表,而是接受RRefs列表,每个模型参数都有一个RRef,用于本地和远程模型参数。辅助函数非常简单,只需调用Module.parameters()并在每个参数上创建一个本地RRef。
def _parameter_rrefs(module):
param_rrefs = []
for param in module.parameters():
param_rrefs.append(RRef(param))
return param_rrefs
然后,由于RNNModel包含三个子模块,我们需要三次调用_parameter_rrefs,并将其包装到另一个辅助函数中。
class RNNModel(nn.Module):
...
def parameter_rrefs(self):
remote_params = []
# get RRefs of embedding table
remote_params.extend(_remote_method(_parameter_rrefs, self.emb_table_rref))
# create RRefs for local parameters
remote_params.extend(_parameter_rrefs(self.rnn))
# get RRefs of decoder
remote_params.extend(_remote_method(_parameter_rrefs, self.decoder_rref))
return remote_params
现在,我们准备实现训练循环。在初始化模型参数后,我们创建RNNModel和DistributedOptimizer。分布式优化器将获取参数RRefs列表,找到所有不同的所有者工作节点,并使用给定参数(即,在本例中为lr=0.05)在每个所有者工作节点上创建给定的本地优化器(即SGD,您也可以使用其他本地优化器)。
在训练循环中,首先创建一个分布式自动求导上下文,这将帮助分布式自动求导引擎找到梯度和涉及的 RPC 发送/接收函数。分布式自动求导引擎的设计细节可以在其设计说明中找到。然后,启动前向传播,就像是一个本地模型,然后运行分布式反向传播。对于分布式反向传播,您只需要指定一个根列表,在本例中,它是损失Tensor。分布式自动求导引擎将自动遍历分布式图并正确写入梯度。接下来,在分布式优化器上运行step函数,这将联系到所有涉及的本地优化器来更新模型参数。与本地训练相比,一个小的区别是您不需要运行zero_grad(),因为每个自动求导上下文都有专用空间来存储梯度,并且由于我们每次迭代创建一个上下文,来自不同迭代的梯度不会累积到相同的Tensors集合中。
def run_trainer():
batch = 5
ntoken = 10
ninp = 2
nhid = 3
nindices = 3
nlayers = 4
hidden = (
torch.randn(nlayers, nindices, nhid),
torch.randn(nlayers, nindices, nhid)
)
model = rnn.RNNModel('ps', ntoken, ninp, nhid, nlayers)
# setup distributed optimizer
opt = DistributedOptimizer(
optim.SGD,
model.parameter_rrefs(),
lr=0.05,
)
criterion = torch.nn.CrossEntropyLoss()
def get_next_batch():
for _ in range(5):
data = torch.LongTensor(batch, nindices) % ntoken
target = torch.LongTensor(batch, ntoken) % nindices
yield data, target
# train for 10 iterations
for epoch in range(10):
for data, target in get_next_batch():
# create distributed autograd context
with dist_autograd.context() as context_id:
hidden[0].detach_()
hidden[1].detach_()
output, hidden = model(data, hidden)
loss = criterion(output, target)
# run distributed backward pass
dist_autograd.backward(context_id, [loss])
# run distributed optimizer
opt.step(context_id)
# not necessary to zero grads since they are
# accumulated into the distributed autograd context
# which is reset every iteration.
print("Training epoch {}".format(epoch))
最后,让我们添加一些粘合代码来启动参数服务器和训练器进程。
def run_worker(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
if rank == 1:
rpc.init_rpc("trainer", rank=rank, world_size=world_size)
_run_trainer()
else:
rpc.init_rpc("ps", rank=rank, world_size=world_size)
# parameter server do nothing
pass
# block until all rpcs finish
rpc.shutdown()
if __name__=="__main__":
world_size = 2
mp.spawn(run_worker, args=(world_size, ), nprocs=world_size, join=True)
使用分布式 RPC 框架实现参数服务器
原文:
pytorch.org/tutorials/intermediate/rpc_param_server_tutorial.html译者:飞龙
作者:Rohan Varma
注意
 在github中查看并编辑本教程。
在github中查看并编辑本教程。
先决条件:
PyTorch 分布式概述
本教程演示了使用 PyTorch 的分布式 RPC 框架实现参数服务器的简单示例。参数服务器框架是一种范式,其中一组服务器存储参数,例如大型嵌入表,几个训练器查询参数服务器以检索最新的参数。这些训练器可以在本地运行训练循环,并偶尔与参数服务器同步以获取最新的参数。要了解更多关于参数服务器方法的信息,请查看这篇论文。
使用分布式 RPC 框架,我们将构建一个示例,其中多个训练器使用 RPC 与同一参数服务器通信,并使用RRef来访问远程参数服务器实例上的状态。每个训练器将通过在多个节点之间的自动求导图上进行分布式反向传递的拼接来启动其专用的反向传递。
注意:本教程涵盖了分布式 RPC 框架的使用,该框架对于将模型分割到多台机器上或实现参数服务器训练策略非常有用,其中网络训练器获取托管在不同机器上的参数。如果您想要在多个 GPU 上复制模型,请参阅分布式数据并行教程。还有另一个RPC 教程,涵盖了强化学习和 RNN 用例。
让我们从熟悉的开始:导入所需的模块并定义一个简单的 ConvNet,该网络将在 MNIST 数据集上进行训练。下面的网络主要采用自pytorch/examples repo中定义的网络。
import argparse
import os
import time
from threading import Lock
import torch
import torch.distributed.autograd as dist_autograd
import torch.distributed.rpc as rpc
import torch.multiprocessing as mp
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.distributed.optim import DistributedOptimizer
from torchvision import datasets, transforms
# --------- MNIST Network to train, from pytorch/examples -----
class Net(nn.Module):
def __init__(self, num_gpus=0):
super(Net, self).__init__()
print(f"Using {
num_gpus} GPUs to train")
self.num_gpus = num_gpus
device = torch.device(
"cuda:0" if torch.cuda.is_available() and self.num_gpus > 0 else "cpu")
print(f"Putting first 2 convs on {
str(device)}")
# Put conv layers on the first cuda device, or CPU if no cuda device
self.conv1 = nn.Conv2d(1, 32, 3, 1).to(device)
self.conv2 = nn.Conv2d(32, 64, 3, 1).to(device)
# Put rest of the network on the 2nd cuda device, if there is one
if "cuda" in str(device) and num_gpus > 1:
device = torch.device("cuda:1")
print(f"Putting rest of layers on {
str(device)}")
self.dropout1 = nn.Dropout2d(0.25).to(device)
self.dropout2 = nn.Dropout2d(0.5).to(device)
self.fc1 = nn.Linear(9216, 128).to(device)
self.fc2 = nn.Linear(128, 10).to(device)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
# Move tensor to next device if necessary
next_device = next(self.fc1.parameters()).device
x = x.to(next_device)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
接下来,让我们定义一些有用的辅助函数,这些函数将对我们脚本的其余部分很有用。以下使用rpc_sync和RRef来定义一个函数,该函数在远程节点上调用给定对象的方法。在下面,我们对远程对象的句柄由rref参数给出,并在拥有节点上运行它:rref.owner()。在调用节点上,我们通过使用rpc_sync同步运行此命令,这意味着我们将阻塞直到收到响应。
# --------- Helper Methods --------------------
# On the local node, call a method with first arg as the value held by the
# RRef. Other args are passed in as arguments to the function called.
# Useful for calling instance methods. method could be any matching function, including
# class methods.
def call_method(method, rref, *args, **kwargs):
return method(rref.local_value(), *args, **kwargs)
# Given an RRef, return the result of calling the passed in method on the value
# held by the RRef. This call is done on the remote node that owns
# the RRef and passes along the given argument.
# Example: If the value held by the RRef is of type Foo, then
# remote_method(Foo.bar, rref, arg1, arg2) is equivalent to calling
# <foo_instance>.bar(arg1, arg2) on the remote node and getting the result
# back.
def remote_method(method, rref, *args, **kwargs):
args = [method, rref] + list(args)
return rpc.rpc_sync(rref.owner(), call_method, args=args, kwargs=kwargs)
现在,我们准备定义我们的参数服务器。我们将子类化nn.Module并保存一个句柄到我们上面定义的网络。我们还将保存一个输入设备,这将是在调用模型之前将输入传输到的设备。
# --------- Parameter Server --------------------
class ParameterServer(nn.Module):
def __init__(self, num_gpus=0):
super().__init__()
model = Net(num_gpus=num_gpus)
self.model = model
self.input_device = torch.device(
"cuda:0" if torch.cuda.is_available() and num_gpus > 0 else "cpu")
接下来,我们将定义我们的前向传递。请注意,无论模型输出的设备如何,我们都将输出移动到 CPU,因为分布式 RPC 框架目前仅支持通过 RPC 发送 CPU 张量。由于调用方/被调用方可能存在不同设备(CPU/GPU),我们故意禁用了通过 RPC 发送 CUDA 张量,但可能会在未来版本中支持。
class ParameterServer(nn.Module):
...
def forward(self, inp):
inp = inp.to(self.input_device)
out = self.model(inp)
# This output is forwarded over RPC, which as of 1.5.0 only accepts CPU tensors.
# Tensors must be moved in and out of GPU memory due to this.
out = out.to("cpu")
return out
接下来,我们将定义一些对训练和验证有用的杂项函数。首先,get_dist_gradients将接收一个分布式自动求导上下文 ID,并调用dist_autograd.get_gradients API 来检索分布式自动求导计算的梯度。更多信息可以在分布式自动求导文档中找到。请注意,我们还会遍历结果字典,并将每个张量转换为 CPU 张量,因为目前框架只支持通过 RPC 发送张量。接下来,get_param_rrefs将遍历我们的模型参数,并将它们包装为一个(本地)RRef。这个方法将被训练节点通过 RPC 调用,并返回要优化的参数列表。这是Distributed Optimizer的输入要求,它要求所有必须优化的参数作为RRef列表。
# Use dist autograd to retrieve gradients accumulated for this model.
# Primarily used for verification.
def get_dist_gradients(self, cid):
grads = dist_autograd.get_gradients(cid)
# This output is forwarded over RPC, which as of 1.5.0 only accepts CPU tensors.
# Tensors must be moved in and out of GPU memory due to this.
cpu_grads = {
}
for k, v in grads.items():
k_cpu, v_cpu = k.to("cpu"), v.to("cpu")
cpu_grads[k_cpu] = v_cpu
return cpu_grads
# Wrap local parameters in a RRef. Needed for building the
# DistributedOptimizer which optimizes paramters remotely.
def get_param_rrefs(self):
param_rrefs = [rpc.RRef(param) for param in self.model.parameters()]
return param_rrefs
最后,我们将创建方法来初始化我们的参数服务器。请注意,在所有进程中只会有一个参数服务器实例,并且所有训练器将与同一个参数服务器通信并更新相同的存储模型。如run_parameter_server中所示,服务器本身不会采取任何独立的行动;它会等待来自训练器(尚未定义)的请求,并通过运行请求的函数来响应它们。
# The global parameter server instance.
param_server = None
# A lock to ensure we only have one parameter server.
global_lock = Lock()
def get_parameter_server(num_gpus=0):
"""
Returns a singleton parameter server to all trainer processes
"""
global param_server
# Ensure that we get only one handle to the ParameterServer.
with global_lock:
if not param_server:
# construct it once
param_server = ParameterServer(num_gpus=num_gpus)
return param_server
def run_parameter_server(rank, world_size):
# The parameter server just acts as a host for the model and responds to
# requests from trainers.
# rpc.shutdown() will wait for all workers to complete by default, which
# in this case means that the parameter server will wait for all trainers
# to complete, and then exit.
print("PS master initializing RPC")
rpc.init_rpc(name="parameter_server", rank=rank, world_size=world_size)
print("RPC initialized! Running parameter server...")
rpc.shutdown()
print("RPC shutdown on parameter server.")
请注意,上面的rpc.shutdown()不会立即关闭参数服务器。相反,它将等待所有工作节点(在这种情况下是训练器)也调用rpc.shutdown()。这样我们就可以保证在所有训练器(尚未定义)完成训练过程之前,参数服务器不会下线。
接下来,我们将定义我们的TrainerNet类。这也将是nn.Module的子类,我们的__init__方法将使用rpc.remote API 来获取一个 RRef,或者远程引用,到我们的参数服务器。请注意,这里我们不会将参数服务器复制到我们的本地进程,相反,我们可以将self.param_server_rref看作是指向在单独进程中运行的参数服务器的分布式共享指针。
# --------- Trainers --------------------
# nn.Module corresponding to the network trained by this trainer. The
# forward() method simply invokes the network on the given parameter
# server.
class TrainerNet(nn.Module):
def __init__(self, num_gpus=0):
super().__init__()
self.num_gpus = num_gpus
self.param_server_rref = rpc.remote(
"parameter_server", get_parameter_server, args=(num_gpus,))
接下来,我们将定义一个名为get_global_param_rrefs的方法。为了激发对这个方法的需求,值得阅读DistributedOptimizer上的文档,特别是 API 签名。优化器必须传递一个要优化的远程参数的RRef列表,所以这里我们获取必要的RRef。由于给定的TrainerNet与唯一的远程工作节点ParameterServer进行交互,我们只需在ParameterServer上调用remote_method。我们使用在ParameterServer类中定义的get_param_rrefs方法。这个方法将返回一个需要被优化的参数的RRef列表。请注意,在这种情况下,我们的TrainerNet不定义自己的参数;如果定义了,我们还需要将每个参数包装成一个RRef,并将其包含在输入到DistributedOptimizer中。
class TrainerNet(nn.Module):
...
def get_global_param_rrefs(self):
remote_params = remote_method(
ParameterServer.get_param_rrefs,
self.param_server_rref)
return remote_params
现在,我们准备定义我们的forward方法,它将调用(同步)RPC 来运行在ParameterServer上定义的网络的前向传播。请注意,我们传入self.param_server_rref,这是对我们的ParameterServer的远程句柄,到我们的 RPC 调用中。这个调用将发送一个 RPC 到我们的ParameterServer正在运行的节点上,调用forward传播,并返回对应于模型输出的Tensor。
class TrainerNet(nn.Module):
...
def forward(self, x):
model_output = remote_method(
ParameterServer.forward, self.param_server_rref, x)
return model_output
我们的训练器已经完全定义好了,现在是时候编写我们的神经网络训练循环,该循环将创建我们的网络和优化器,运行一些输入通过网络并计算损失。训练循环看起来很像本地训练程序的循环,但由于我们的网络分布在多台机器上,所以有一些修改。
在下面,我们初始化我们的TrainerNet并构建一个DistributedOptimizer。请注意,如上所述,我们必须传入所有全局(参与分布式训练的所有节点)参数,我们希望进行优化。此外,我们传入要使用的本地优化器,本例中为 SGD。请注意,我们可以像创建本地优化器一样配置底层优化算法 - 所有optimizer.SGD的参数都将被正确转发。例如,我们传入一个自定义学习率,该学习率将用作所有本地优化器的学习率。
def run_training_loop(rank, num_gpus, train_loader, test_loader):
# Runs the typical nueral network forward + backward + optimizer step, but
# in a distributed fashion.
net = TrainerNet(num_gpus=num_gpus)
# Build DistributedOptimizer.
param_rrefs = net.get_global_param_rrefs()
opt = DistributedOptimizer(optim.SGD, param_rrefs, lr=0.03)
接下来,我们定义我们的主要训练循环。我们循环遍历 PyTorch 的DataLoader提供的可迭代对象。在编写典型的前向/后向/优化器循环之前,我们首先将逻辑包装在Distributed Autograd context中。请注意,这是为了记录模型前向传递中调用的 RPC,以便构建一个适当的图,其中包括在后向传递中参与的所有分布式工作节点。分布式自动求导上下文返回一个context_id,用作累积和优化与特定迭代对应的梯度的标识符。
与调用典型的loss.backward()不同,后者会在本地工作节点上启动后向传递,我们调用dist_autograd.backward()并传入我们的context_id以及loss,这是我们希望从根开始进行后向传递的位置。此外,我们将这个context_id传递给我们的优化器调用,这是必要的,以便能够查找由此特定后向传递计算的相应梯度跨所有节点。
def run_training_loop(rank, num_gpus, train_loader, test_loader):
...
for i, (data, target) in enumerate(train_loader):
with dist_autograd.context() as cid:
model_output = net(data)
target = target.to(model_output.device)
loss = F.nll_loss(model_output, target)
if i % 5 == 0:
print(f"Rank {
rank} training batch {
i} loss {
loss.item()}")
dist_autograd.backward(cid, [loss])
# Ensure that dist autograd ran successfully and gradients were
# returned.
assert remote_method(
ParameterServer.get_dist_gradients,
net.param_server_rref,
cid) != {
}
opt.step(cid)
print("Training complete!")
print("Getting accuracy....")
get_accuracy(test_loader, net)
接下来,我们简单地计算模型在训练完成后的准确率,就像传统的本地模型一样。但是,请注意,我们在上面传递给此函数的net是TrainerNet的一个实例,因此前向传递以透明方式调用 RPC。
def get_accuracy(test_loader, model):
model.eval()
correct_sum = 0
# Use GPU to evaluate if possible
device = torch.device("cuda:0" if model.num_gpus > 0
and torch.cuda.is_available() else "cpu")
with torch.no_grad():
for i, (data, target) in enumerate(test_loader):
out = model(data, -1)
pred = out.argmax(dim=1, keepdim=True)
pred, target = pred.to(device), target.to(device)
correct = pred.eq(target.view_as(pred)).sum().item()
correct_sum += correct
print(f"Accuracy {
correct_sum / len(test_loader.dataset)}")
接下来,类似于我们为ParameterServer定义run_parameter_server作为主循环的方式,负责初始化 RPC,让我们为训练器定义一个类似的循环。不同之处在于我们的训练器必须运行我们上面定义的训练循环:
# Main loop for trainers.
def run_worker(rank, world_size, num_gpus, train_loader, test_loader):
print(f"Worker rank {
rank} initializing RPC")
rpc.init_rpc(
name=f"trainer_{
rank}",
rank=rank,
world_size=world_size)
print(f"Worker {
rank} done initializing RPC")
run_training_loop(rank, num_gpus, train_loader, test_loader)
rpc.shutdown()
请注意,类似于run_parameter_server,rpc.shutdown()默认情况下会等待所有工作节点,包括训练器和参数服务器,调用rpc.shutdown()后,该节点才会退出。这确保节点被优雅地终止,而不会在另一个节点期望其在线时离线。
我们现在已经完成了训练器和参数服务器特定的代码,剩下的就是添加代码来启动训练器和参数服务器。首先,我们必须接收适用于我们参数服务器和训练器的各种参数。world_size对应于将参与训练的节点的总数,是所有训练器和参数服务器的总和。我们还必须为每个单独的进程传入一个唯一的rank,从 0(我们将在其中运行单个参数服务器)到world_size - 1。master_addr和master_port是可以用来识别 0 级进程运行位置的参数,并将被各个节点用于发现彼此。为了在本地测试此示例,只需将localhost和相同的master_port传递给所有生成的实例。请注意,出于演示目的,此示例仅支持 0-2 个 GPU,尽管该模式可以扩展以利用更多的 GPU。
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description="Parameter-Server RPC based training")
parser.add_argument(
"--world_size",
type=int,
default=4,
help="""Total number of participating processes. Should be the sum of
master node and all training nodes.""")
parser.add_argument(
"rank",
type=int,
default=None,
help="Global rank of this process. Pass in 0 for master.")
parser.add_argument(
"num_gpus",
type=int,
default=0,
help="""Number of GPUs to use for training, Currently supports between 0
and 2 GPUs. Note that this argument will be passed to the parameter servers.""")
parser.add_argument(
"--master_addr",
type=str,
default="localhost",
help="""Address of master, will default to localhost if not provided.
Master must be able to accept network traffic on the address + port.""")
parser.add_argument(
"--master_port",
type=str,
default="29500",
help="""Port that master is listening on, will default to 29500 if not
provided. Master must be able to accept network traffic on the host and port.""")
args = parser.parse_args()
assert args.rank is not None, "must provide rank argument."
assert args.num_gpus <= 3, f"Only 0-2 GPUs currently supported (got {
args.num_gpus})."
os.environ['MASTER_ADDR'] = args.master_addr
os.environ["MASTER_PORT"] = args.master_port
现在,我们将根据我们的命令行参数创建相应于参数服务器或训练器的进程。如果我们传入的等级为 0,则将创建一个ParameterServer,否则将创建一个TrainerNet。请注意,我们使用torch.multiprocessing启动一个子进程,对应于我们要执行的函数,并在主线程中使用p.join()等待该进程的完成。在初始化我们的训练器时,我们还使用 PyTorch 的dataloaders来指定 MNIST 数据集上的训练和测试数据加载器。
processes = []
world_size = args.world_size
if args.rank == 0:
p = mp.Process(target=run_parameter_server, args=(0, world_size))
p.start()
processes.append(p)
else:
# Get data to train on
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=32, shuffle=True,)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(
'../data',
train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=32,
shuffle=True,
)
# start training worker on this node
p = mp.Process(
target=run_worker,
args=(
args.rank,
world_size, args.num_gpus,
train_loader,
test_loader))
p.start()
processes.append(p)
for p in processes:
p.join()
要在本地运行示例,请在单独的终端窗口中为服务器和每个要生成的工作节点运行以下命令:python rpc_parameter_server.py --world_size=WORLD_SIZE --rank=RANK。例如,对于世界大小为 2 的主节点,命令将是python rpc_parameter_server.py --world_size=2 --rank=0。然后可以在单独的窗口中使用命令python rpc_parameter_server.py --world_size=2 --rank=1启动训练器,这将开始使用一个服务器和一个训练器进行训练。请注意,本教程假定训练使用 0 到 2 个 GPU 进行,可以通过将--num_gpus=N传递到训练脚本中进行配置。
您可以通过命令行参数--master_addr=ADDRESS和--master_port=PORT传入地址和端口,以指示主工作节点正在侦听的地址和端口,例如,用于测试训练器和主节点在不同机器上运行的功能。