目录
linux中的普通文件的刷新策略是全缓冲,显示器上的刷新策略是行刷新
前言知识点
文件=内容+属性
文件分为打开的文件和没打开的文件
是谁在打开文件? 进程和文件的关系
没有打开的文件特别多,文件是怎么进行分类的?
打开的文件非常多,是怎么快速的进行增删查改(定位文件)?
文件是否也像进程一样在操作系统中是一个结构体。
C语言的规定:字符串必须以“\0”结束,但是在文件中,不需要写\0,文件可以使用任何语言。
文件写入的路径:在/proc目录中有当前工作目录的软连接,可以通过chdir来更改工作目录
文件的底层,一定会封装系统调用。程序不能跳过文件直接访问硬件设备,所以库函数的实现底层本质是调用系统提供的使用硬件设备的调用接口
位图:通过位图,可以设置标志位的方式来判断文件打开的模式。位图是由01组成的序列。
在创建文件时候可以使用umask()函数在子进程中临时修改umask值
不同的语言,调用不同的函数,其本质就是对于系统调用的组合,就比如文件操作函数,调用的都是linux中提供的c语言文件操作函数
文件操作 文件访问
函数 参数
头文件<stdio,h>
fopen():用于打开文件并返回一个指向文件的指针。它有两个参数,第一个是文件名(路径),第二个是打开模式。例如:FILE* fp = fopen("filename.txt", "r");fclose():用于关闭文件。fgetc()和getc():用于从文件中读取一个字符。它们接受一个指向文件的指针作为参数,并返回读取的字符。例如:char c = fgetc(fp);fgets():用于从文件中读取一行文本。它接受一个指向字符数组的指针(用于存储读取的文本),以及一个表示最大字符数的整数参数。例如:char line[256]; fgets(line, sizeof(line), fp);fputc()和putc():用于将一个字符写入文件。它们接受一个字符和一个指向文件的指针作为参数。例如:fputc('A', fp);fputs():用于将一个字符串写入文件。它接受一个字符串和一个指向文件的指针作为参数。例如:fputs("Hello", fp);fprintf():用于将格式化的数据写入文件。它类似于printf(),但是它接受一个指向文件的指针作为第一个参数。例如:fprintf(fp, "The value is %d\n", value);fscanf():用于从文件中读取格式化的数据。它类似于scanf(),但是它接受一个指向文件的指针作为第一个参数。例如:fscanf(fp, "%d", &value);fwrite: 用于将数据写入文件。它可以将一个已知大小的缓冲区的数据写入文件。size_t fwrite(const void *ptr, size_t size, size_t count, FILE *stream);fread:用于从文件中读取数据。它可以读取一个已知大小的缓冲区的数据 from file。size_t fread(void *ptr, size_t size, size_t count, FILE *stream);feof():用于检查文件是否已到达文件尾。它接受一个指向文件的指针作为参数,并返回一个非零值(true),如果文件已经达到文件尾部。例如:if (feof(fp)) { // 文件读取完毕 }ferror():用于检查文件操作是否发生了错误。它接受一个指向文件的指针作为参数,并返回一个非零值(true),如果发生了错误。例如:if (ferror(fp)) { // 文件操作错误 }fseek():用于在文件中定位到指定的位置。它接受一个指向文件的指针、偏移量和参考位置作为参数,并将文件指针定位到指定位置。例如:fseek(fp, 0, SEEK_SET);将文件指针设置为文件开头。ftell():用于获取文件指针的当前位置。它接受一个指向文件的指针,并返回当前文件指针的位置。例如:long position = ftell(fp);rewind():用于将文件指针重置到文件的开头。它接受一个指向文件的指针作为参数,并将文件指针设置为文件开头。例如:rewind(fp);feof()和ferror():在前面已经提到过,用于检查文件是否已到达文件尾或是否发生了错误。rename():用于更改文件名。它接受原始文件名和目标文件名作为参数,并将文件名更改为目标文件名。例如:rename("oldfile.txt", "newfile.txt");remove():用于删除文件。它接受一个文件名作为参数,并删除该文件。例如:remove("filename.txt");
linux系统的文件调用接口
open():
int open(const char *pathname, int flags),它用于打开一个文件并返回一个文件描述符。int open(const char *pathname, int flags,mode_t mode)参数
pathname是要打开的文件名,参数flags是打开文件时需要的标志,例如 O_TRUNC(截断),O_WRONLY(只写) ,O_RDONLY(只读)或 O_CREAT(创建),第三个可选的参数是如果修改文件的权限:文件0666,目录0777close():
int close(int fd),它用于关闭一个已打开的文件描述符参数 fd 是要关闭的文件描述符。
read():
ssize_t read(int fd, void *buf, size_t count),它用于从文件中读取数据。参数
fd是打开的文件描述符,参数buf是用于存储读数据的缓冲区,参数count是读取的数据量。write():
ssize_t write(int fd, const void *buf, size_t count),它用于向文件中写入数据。参数
fd是打开的文件描述符,参数buf是要写入的数据缓冲区,参数count是写入的数据量大小。creat():
int creat(const char *pathname, mode_t mode);用于创建新文件.pathname是要创建的文件的名称,mode是创建文件时设置的权限。 在使用creat函数时,如果指定的文件名不存在,它将创建一个新的文件,并返回一个文件描述符来进行相应的操作。如果文件名已经存在,它将截断(清空)现有文件,并返回一个文件描述符。dup2():
int dup2(int oldfd, int newfd);用于将oldfd所指向的文件描述符复制到newfd所指向的文件描述符位置上。oldfd一般是打开文件的描述符fd, newfd一般是标准流0 1 2。lseek():
off_t lseek(int fd, off_t offset, int whence),它用于改变文件指针的位置。参数
fd是打开的文件描述符,参数offset是要移动的偏移量,参数whence是移动的方向。stat():
int stat(const char *pathname, struct stat *buf),它用于获取文件状态信息。参数
name是要查询的文件名,参数buf是用于存储文件状态信息的结构体指针。unlink():
int unlink(const char *pathname),它用于删除指定文件参数
pathname是要删除的文件名。rename():
int rename(const char *oldpathname, const char *newpathname),它用于重命名文件。
参数 oldpathname 是要重命名的文件名,参数 newpathname 是新的文件名。
fcntl():
int fcntl(int fd, int cmd, ...),它用于控制文件描述符的行为。
参数 fd 是打开的文件描述符,参数 cmd 是控制命令,例如 F_GETFL(获取文件描述符)或 F_SETFL(设置文件描述符标志),参数 ... 是其他参数。
flock():
int flock(int fd, int operation),它用于文件锁机制。参数
fd是打开的文件描述符,operation是锁操作,例如 L_UNLCK(解锁)或 L_LOCK(加锁)。
头文件
open() - 头文件
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h>
close() - 头文件
<unistd.h>read() - 头文件
<unistd.h>write() - 头文件
<unistd.h>crate() - 头文件
<unistd.h>dup2() - 头文件
<unistd.h>lseek() - 头文件
<unistd.h>stat() - 头文件
<sys/stat.h>和<unistd.h>unlink() - 头文件
<unistd.h>rename() - 头文件
<stdio.h>fcntl() - 头文件
<fcntl.h>flock() - 头文件
<sys/file.h>或<fcntl.h>
文件打开模式
只读模式(r):以只读方式打开文件,该文件必须存在。
只写模式(w):以只写方式打开文件,如果文件存在则覆盖原文件内容,不存在则创建新文件。
追加模式(a):以追加方式打开文件,数据会被写入文件的末尾而不会覆盖原文件内容。
读写模式(r+):以读写方式打开文件,与只读模式不同的是该文件可以被重定位;与只写模式不同的是数据可以同时被读取和写入。
读写模式(w+):以读写方式打开文件,如果文件存在则覆盖原文件内容,如果文件不存在则创建新文件。
附加读写模式(a+):以附加读写方式打开文件,数据会被写入文件的末尾,同时支持读取和写入。
只读二进制模式(rb):以只读方式打开二进制文件,该文件必须存在。
只写二进制模式(wb):以只写方式打开二进制文件,如果文件存在则覆盖原文件内容,不存在则创建新文件。
追加二进制模式(ab):以追加方式打开二进制文件,数据会被写入文件的末尾而不会覆盖原文件内容。
读写二进制模式(rb+):以读写方式打开二进制文件,与只读模式不同的是该文件可以被重定位;与只写模式不同的是数据可以同时被读取和写入。
读写二进制模式(wb+):以读写方式打开二进制文件,如果文件存在则覆盖原文件内容,如果文件不存在则创建新文件。
附加读写二进制模式(ab+):以附加读写方式打开二进制文件,数据会被写入文件的末尾,同时支持读取和写入。
这些模式可以组合使用。
open函数重点介绍
函数原型
#include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> int open(const char *path, int flags); int open(const char *path, int flags, mode_t mode);
参数说明
path: 要打开的文件的路径。flags: 打开文件的标志。这是一个或运算的标志集合,常用的标志有:O_RDONLY: 只读模式O_WRONLY: 只写模式O_RDWR: 读写模式O_APPEND: 追加模式O_TRUNC: 如果文件已存在,则截断文件到0长度O_AT: 如果文件不存在,则创建文件O_EXCL: 与O_CREAT一起使用时,如果文件已存在,则返回错误O_NOCTTY: 不要将文件设置为终端O_NONBLOCK: 非阻塞模式O_NDELAY: 相当于O_NONBLOCK,用于阻塞模式的文件描述符
mode: 文件创建时的模式。这是一个八进制数,用于设置文件权限等。如果flags中没有设置O_CREAT,则mode参数无效。
返回值
如果open()成功打开文件,它将返回一个非负的文件描述符。如果出错,则返回-1。
示例
#include <stdio.h>
#include <unistd.h>
int main() {
int fd;
char *filename = "example.txt";
// 以只写模式打开文件,如果不存在则创建
fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, 0644);
//File* fp =fopen(filename,"w");的系统调用就是上边这个
if (fd == -1) {
perror("open");
return 1;
}
// 写入文件内容
const char * = "Hello, world!\n";
write(fd, text, strlen(text));
// 关闭文件
close(fd);
return 0;
}
注意事项
使用
open()函数时,应该总是检查返回值,以确定是否成功打开文件。可以在调用open()函数后使用perror()函数来打印错误信息。文件描述符需要使用
close()函数来关闭。文件权限模式
mode可以使用umask来设置默认的权限掩码,从而改变创建文件的默认权限。在liunx中c语言中打开文件的操作本质都是调用这个接口
文件访问的本质
文件描述符fd
文件描述符(File Descriptor)是操作系统中对文件或输入/输出设备进行操作的一种抽象概念。在Unix、Linux等操作系统中,每个打开的文件都会被操作系统分配一个唯一的文件描述符,用于标识这个文件在进程中的访问。
文件描述符是一个非负整数,通常被用作索引,将打开的文件与进程实际使用的文件数据结构(如文件结构体)进行关联。操作系统提供了一系列的系统调用函数(如open()、read()、write()、close()等)来通过文件描述符进行文件的操作。
常见的文件描述符如下:
0:标准输入
1:标准输出
2:标准错误输出
除了上述的标准输入、输出和错误输出,其他文件描述符通常是通过系统调用函数(如open())打开文件时返回的。每个进程都会有一张文件描述符表,其中记录了与进程相关的打开文件的信息,包括文件描述符、文件的打开模式、读写位置等。
先描述在组织
文件描述符表
在进程的结构体PCB(struct task_struct)中会有与其相关的(文件描述符表指针)struct files_struct *files;
在 struct files_struct 这个结构体中有一个数组struct file *fd_array[] 。这个数组叫做文件描述符表(File Descriptor Table),文件描述符表中的每个条目(entry)是一个指向文件表(File Table)中的文件表项(File Table Entry)的指针struct file*
当进程打开一个文件时候,就会在表中找一个空位放一个文件结构体指针,指向文件对应的结构体中的项目。
文件表是操作系统内核维护的一个数据结构,存放所有打开的文件信息。每个文件表项对应一个具体的文件,并包含了有关该文件的元数据、读写指针位置、权限信息等。
所以open函数的返回值的整数 ,就是打开文件对应的下标,可以通过查看这个返回值查看,发现是从3开始的。012去哪里了??
这里的012,就是对应(c语言)的stdin,stdout,stderror但是这不是c语言的特性,而是操作系统的特性
实验:
write(1,"hello\n",strlen("hello\n"));
write(2,"hello\n",strlen("hello\n"));
char buffer[1024];
ssize_t s = read(0,buffer,sizeof(buffer));
if(s<0) return 1;
buffer[s] ='\0';
printf("echo : %s",buffer);
文件结构体 FCB
FCB(File Control Block)指的是文件控制块,是一种在文件系统中用于管理文件的数据结构,可以看作是文件结构体的一种实现方式。
文件结构体包含了与文件相关的各种信息,如文件名、文件大小、文件创建时间、访问时间、修改时间等。
文件结构体通常包含以下字段:
struct_file_name:文件名,包括文件路径和文件名。struct_file_size:文件大小,以字节为单位。struct_file_time:文件的访问时间、修改时间和创建时间等信息。struct_file_type:文件的类型,如普通文件、目录、链接文件等。权限信息、元数据、文件的内核缓冲区信息。
struct_file_data:文件的数据部分,包含了文件的实际内容。struct file* next:指向其他文件表项,使用双链表等数据结构组织打开文件的管理
除了文件结构体之外,操作系统通常还提供了其他相关结构体和数据类型,用于处理文件系统中的其他方面,如目录结构、文件锁、文件系统元数据等。
思考:引用计数
//如果close(1);printf就不能输出信息了,可以用fprintf(2,"asd");向错误流输出信息
每个程序都有自己的文件描述符表
输出流与错误流都标示着屏幕文件,这里就有一个引用计数,关闭流的操作就是将这个计数count--,然后将自己的文件描述符表中的对应指针置为空,如果count为0了,就会回收struct file文件。
实验
1.读写文件的例子
#include <stdio.h>
void readWriteFile(const char* inputFile, const char* outputFile) {
// 打开输入文件用于读取
FILE* fpIn = fopen(inputFile, "r");
if (fpIn == NULL) {
printf("无法打开输入文件\n");
return;
}
// 打开输出文件用于写入
FILE* fpOut = fopen(outputFile, "w");
if (fpOut == NULL) {
printf("无法打开输出文件\n");
fclose(fpIn);
return;
}
char buffer[1024];
// 从输入文件读取内容,并写入到输出文件
while (fgets(buffer, sizeof(buffer), fpIn) != NULL) {
fputs(buffer, fpOut);
}
// 关闭文件
fclose(fpIn);
fclose(fpOut);
printf("文件读取和写入完成\n");
}
int main() {
const char* inputFile = "input.txt"; // 输入文件名
const char* outputFile = "output.txt"; // 输出文件名
// 读取文件并将内容写入另一个文件
readWriteFile(inputFile, outputFile);
return 0;
}
在这个示例中,readWriteFile 函数打开一个输入文件和一个输出文件,然后使用 fgets 从输入文件中读取内容,并使用 fputs 将内容写入输出文件。
在 main 函数中,输入文件名和输出文件名被硬编码为 input.txt 和 output.txt。您可以根据需要修改这些文件名。
编译并运行此代码将从输入文件中读取内容,并将内容写入输出文件。如果输入文件存在且可以成功打开,并且输出文件可写入,则会打印文件读取和写入完成的消息。
请确保在运行代码之前,存在名为 input.txt 的输入文件。
2.open,read,write,close
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
int main() {
int fd;
// 打开文件
fd = open("log.txt", O_RDONLY,0666);
fd = open("log.txt", O_WRONLY|O_CREAT|O_TRUNC,0666);
//fd = open(".txt", O_RDONLY|O_CREAT|O_TRUNC,0666);
//文件不存在自动创建文件,子码为0666,如果存在就追加写
if (fd == -1) {
perror("open :");
return 1;
}
//写入
//
printf("fd: %d\n", fd);
const char* message = "hello linux\n";
write(fd,message ,strlen(message));
// 读取文件内容
char buffer[1024];
ssize_t n;
while ((n = read(fd, buffer, sizeof(buffer))) > 0) {
buffer[n] = '\0'; // 添加字符串结束符
printf("%s", buffer);
}
// 关闭文件
close(fd);
return 0;
}
使用 open 函数打开名为 log.txt 的文件,并将其内容读取到一个循环缓冲区中。我们使用 read 函数从文件中读取数据,每次读取一个缓冲区(大小为 1024 字节),并将读取到的内容打印到控制台上。
使用了 O_RDONLY 标志,表示只读取文件内容。如果文件不存在,则该函数将返回 -1,并设置 errno 变量来表示错误。
当读取文件内容时,我们使用 read 函数从文件中读取数据并将其写入缓冲区。如果读取的数据量小于请求的大小,则 read 函数将返回实际读取的数据量。如果到达文件末尾或发生错误,则 read 函数将返回 。
注意:
在WRONLY模式下,文件是被覆盖写的但是不会清除原本的文件内容
重定向(管道在信号)
介绍
在《需要了解的前言知识中》
实验
1.文件描述符的分配规则
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
int main() {
//关闭了0文件描述符
close(0);
int fd;
// 打开文件
fd = open("log.txt", O_WRONLY|O_CREAT|O_TRUNC,0666);
if (fd == -1) {
perror("open :");
return 1;
}
printf("fd: %d\n", fd);
const char* message = "hello linux\n";
int i=5;
while(i--)
write(fd,message ,strlen(message));
// 关闭文件
close(fd);
return 0;
}
[root@MYCAT Filetest]# ./mytest fd: 0 [root@MYCAT Filetest]# cat log.txt hello linux hello linux hello linux hello linux hello linux
思考:
新打开的文件描述符为0,说明设置文件描述符时候是线性遍历文件描述符表,将最小的空间作为将打开文件的描述符
2.输出重定向的实现
向1号描述符输入字符
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
int main() {
//close(1);
int fd;
fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd == -1) {
perror("open :");
return 1;
}
printf("fd: %d\n", fd);
const char* message = "hello linux\n";
int i = 5;
while (i--)
write(1, message, strlen(message));
//向屏幕输出
close(fd);
return 0;
}
[root@MYCAT Filetest]# ./mytest fd: 3 hello linux hello linux hello linux hello linux hello linux [root@MYCAT Filetest]# cat log.txt
关闭一号文件
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <string.h>
int main() {
close(1);
int fd;
fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd == -1) {
perror("open :");
return 1;
}
printf("fd: %d\n", fd);
const char* message = "hello linux\n";
int i = 5;
while (i--)
write(1, message, strlen(message));
//向屏幕输出
close(fd);
return 0;
}
[root@MYCAT Filetest]# ./mytest [root@MYCAT Filetest]# cat log.txt hello linux hello linux hello linux hello linux hello linux
思考:
原本在屏幕上打印的内容,出现在了文件中,这就是输出重定向!
关闭了输出流,由于1号为空指针,在打开文件时候本来指向的是显示器文件,后边改到了文件中。然而,printf函数并不知道,他的任务就是向1号文件输出字符,所以呈现了上边的结果
3.输入重定向的实现
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd;
close(0);
fd = open("input.txt", O_RDONLY);
if (fd == -1) {
perror("open :");
return 1;
}
//if (dup2(fd, 0) == -1) {
// perror("dup2 :");
// return 1;
//}
//也可以这种
int num1, num2;
scanf("%d %d", &num1, &num2);
int sum = num1 + num2;
printf("Sum: %d\n", sum);
close(fd);
return 0;
}
输出:
[root@MYCAT Filetest]# cat input.txt 100 50 [root@MYCAT Filetest]# ./mytest Sum: 150
重定向的实现步骤
在具体实现重定向时,操作系统会进行以下步骤:
打开目标文件:操作系统根据重定向符号(如
>或>>)指定的文件路径,使用系统调用(如open()函数)打开目标文件。这将创建一个新的文件描述符,表示目标文件。复制文件描述符:操作系统使用系统调用
dup2()来复制目标文件的文件描述符到特定的文件描述符值,等于要重定向的默认文件描述符。例如,要将标准输出(文件描述符为1)重定向到目标文件,可以执行dup2(dest_fd, 1)。关闭原有文件描述符(可选):根据需要,操作系统可能会使用系统调用(如
close()函数)关闭原有的文件描述符。执行程序输出:当程序将数据写入标准输出时,实际上是将数据写入到被重定向的文件描述符指向的目标文件中。
需要注意的是,重定向是在启动程序之前进行的,因此程序本身并不知道它的输出被重定向到其他位置。这也意味着重定向操作是由命令提示符或脚本配置的,而不是由程序自身处理的。
基本原理
重定向是指将程序的输入或输出从默认的标准输入/输出流(通常是键盘和屏幕)切换到其他设备或文件的过程。
在Unix/Linux系统中,每个进程默认都有三个标准的文件描述符:
标准输入(文件描述符0):输入数据从该文件描述符读取,默认为键盘输入。
标准输出(文件描述符1):输出数据写入该文件描述符,默认为屏幕。
标准错误输出(文件描述符2):用于输出错误消息,默认也为屏幕。(引用计数)
与C语言的stdout,stdin,stderror类似但绝不相等
重定向的基本原理是通过操作系统提供的文件描述符进行实现
在启动程序时,在进程的创建和初始化过程中,操作系统会为进程打开指定的输入和输出文件,并将相应的文件描述符分配给它们。当程序执行过程中使用标准输入/输出操作时,实际上是在使用与文件描述符相关联的文件。
在程序执行时,操作系统根据重定向符号对文件描述符进行重定向操作,将标准输出的输出目标修改为指定的文件。这样,程序的输出将被写入到文件而不是显示在屏幕上。
重定向是在程序执行之前进行的,因此程序本身并不需要知道它的输入或输出被重定向了。这样,可以更灵活地控制程序的输入和输出,实现数据的流动和存储与显示的分离。
实现函数:
dup2()
dup2()函数是一个用于复制文件描述符的系统调用函数,它可以将一个文件描述符复制到另一个文件描述符上。
函数原型
#include <unistd.h> int dup2(int oldfd, int newfd);
参数说明
oldfd:要被复制的源文件描述符。newfd:要复制到的目标文件描述符。
返回值
成功时,返回新的文件描述符(
newfd)。失败时,返回-1,并设置
errno来指示错误原因。
函数功能
检查要复制的源文件描述符
oldfd是否有效。如果无效,即该文件描述符没有打开,则dup2()函数返回-1。检查源文件描述符
oldfd和目标文件描述符newfd是否相同。如果相同,则dup2()函数直接返回目标文件描述符,不进行进一步操作。如果目标文件描述符
newfd已经打开,则先将其关闭。执行文件描述符的复制操作,将源文件描述符
oldfd复制到目标文件描述符newfd所在的位置,这意味着对新的文件描述符进行的任何操作都将影响源文件描述符。最终oldfd 与 newfd 都变成 oldfd 了,dup2函数将源文件描述(
oldfd)的文件结构体指针复制到目标文件描述符(newfd)所在的位置,从而实现文件描述符的复制和覆盖需要注意的是,
dup2()函数不会保留源文件描述符的属性(如权限和所有权),因此复制的文件描述符将具有与源文件描述符相同的权限和所有权。
示例
标准输出重定向到一个文件中:
追加重定向
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
int fd;
fd = open("output.txt", O_WRONLY | O_CREAT | O_APPEND, 0644);//追加重定向
// 将标准输出重定向到文件
dup2(fd, 1);
printf("Hello, world!\n");
printf("This will be written to the file.\n");
close(fd);
return 0;
}
就算把文件描述符提前关闭了也能使用
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
int fd;
fd = open("output.txt", O_WRONLY | O_CREAT | O_APPEND, 0644);//追加重定向
// 将标准输出重定向到文件
dup2(fd, 1);
close(fd);
printf("Hello, world!\n");
printf("This will be written to the file.\n");
return 0;
}
思考:
虽然关闭了文件流,但是printf调用的是1号文件,这时候1号文件已经被覆盖了,这里是引用计数在起作用
输出:
[root@MYCAT Filetest]# ./mytest [root@MYCAT Filetest]# ./mytest [root@MYCAT Filetest]# cat output.txt Hello, world! This will be written to the file. Hello, world! This will be written to the file.
标准输入重定向到一个文件中:
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd;
fd = open("input.txt", O_RDONLY);
if (fd == -1) {
perror("open :");
return 1;
}
if (dup2(fd, 0) == -1) {
perror("dup2 :");
return 1;
}
int num1, num2;
scanf(" %d %d", &num1, &num2);
int sum = num1 + num2;
printf("Sum: %d\n", sum);
close(fd);
return 0;
}
输出:
[root@MYCAT Filetest]# cat input.txt 100 60 [root@MYCAT Filetest]# ./mytest Sum: 160
fcntl()<了解>
fcntl() 函数是一个在 Unix-like 操作系统中使用的系统调用,它提供了对文件描述符的低级控制。fcntl() 函数可以用来设置或获取文件描述符的标志,例如非阻塞模式、记录锁定等,也可以用来控制文件的状态。
函数原型如下:
#include <fcntl.h> int fcntl(int fd, int cmd, ...);
参数说明:
fd:文件描述符,它是通过open()create()等函数返回的。cmd:命令字,指示fcntl()执行什么样的操作。常见的命令字包括:F_GETLK:获取文件描述符上的记录锁定信息。F_SETLK:设置文件描述符上的记录锁定。F_SETFL:设置文件描述符的标志,如 O_NONBLOCK(非阻塞模式)。F_GETFL:获取文件描述符的当前标志。
...:根据cmd的不同,可能需要提供其他参数。例如,在使用F_SETLK时,需要提供要锁定的记录的偏移量和长度。
返回值:
成功时,返回
0或者根据cmd返回其他相关信息。失败时,返回
-1,并设置errno来指示错误原因。
fcntl() 函数在文件操作中非常重要,特别是在需要进行并发控制和同步时,如使用记录锁定来防止多个进程同时写入同一文件的同一行。此外,fcntl() 函数也用于设置文件的标志,例如将文件设置为非阻塞模式,以便于进行异步I/O操作。
模拟实现dup2()
注意:还可以更完美
#include <unistd.h>
#include <fcntl.h>
int my_dup2(int oldfd, int newfd) {
// 检查要复制的文件描述符是否合法
if (fcntl(oldfd, F_GETFD) == -1) {
return -1;
}
// 如果旧的和新的文件描述符相同,直接返回
if (oldfd == newfd) {
return oldfd;
}
// 关闭新的文件描述符(如果已经打开)
if (fcntl(newfd, F_GETFD) != -1) {
close(newfd);
}
// 复制旧的文件描述符
int result = fcntl(oldfd, F_DUPFD, newfd);
// 检查复制是否成功
if (result == -1) {
return -1;
}
return result;
}
上述代码中的my_dup2()函数模拟了dup2()函数的行为,使用了fcntl()函数进行文件描述符的操作。它具有以下功能:
检查源文件描述符
oldfd的有效性,如果无效则返回-1。检查源文件描述符
oldfd和目标文件描述符newfd是否相等,如果相等则直接返回旧的文件描述符。如果目标文件描述符
newfd已经打开,先将其关闭。使用
fcntl()函数和F_DUPFD参数将源文件描述符复制到目标文件描述符。返回复制后的新文件描述符。
输入输出缓冲区
介绍
区分C和内核buffer
输入缓冲区用于暂时存储从输入设备(如键盘、鼠标)获取的数据,供进程读取。输出缓冲区用于临时存储进程要写入输出设备(如屏幕、打印机)的数据,然后再由操作系统将缓冲区中的数据发送给设备。
缓冲区的存在可以平滑输入和输出之间的速度差异。当输入设备的速度快于进程处理数据的速度时,输入缓冲区能够缓冲输入数据,避免数据的丢失。类似地,当进程的输出速度快于设备的处理速度时,输出缓冲区能够暂存数据,避免频繁的数据发送,提高效率。
在C语言中,标准I/O库提供了输入输出缓冲区的支持。数据将首先存储在(用户缓冲区)中,根据标准I/O库的策略进行处理和刷新。默认情况下是行缓冲的,即在遇到换行符\n时进行缓冲区的刷新。可以使用setvbuf()函数来设置缓冲模式。
系统内核会维护一些内部的缓冲区,用于处理底层的输入输出操作,提高整个系统的性能。内核缓冲区通常由操作系统自行管理,对应于底层的设备驱动程序。
缓冲区的刷新策略
缓冲区刷新策略是指控制缓冲区数据何时被写入到目标存储或传输媒介的规则
行缓冲(Line Buffering): 行缓冲是最常见的缓冲区刷新策略之一,它会在缓冲区满时或遇到换行符(如
\n)时将数据刷新到目标媒介。这种策略适合于文本输出,因为它可以确保每行数据都被及时输出,从而保持文本的清晰可读。全缓冲(Full Buffering): 全缓冲策略会在缓冲区满时才进行刷新。这种策略可以提高效率,因为它允许缓冲区积累更多的数据,直到缓冲区大小达到上限才进行刷新。这对于大批量的数据传输尤其有用。
直接刷新(Direct Buffering): 直接刷新策略是指数据一旦被写入缓冲区,就立即刷新到目标媒介。这种策略通常用于需要实时数据传输的场景,如实时通信和视频流处理。
混合刷新(Mixed Buffering): 混合刷新策略结合了行缓冲和全缓冲的特点。它可以根据数据的性质和需求,同时使用行缓冲和全缓冲。例如,文本数据可能会使用行缓冲,而二进制数据可能会使用全缓冲。
操作系统控制(Operating System Controlled): 在某些系统中,操作系统会根据系统整体的性能和资源状况来决定何时刷新缓冲区。这种策略通常用于避免系统过载,确保数据传输的平稳和高效。
应用程序控制(Application Controlled): 应用程序可能会实现自己的缓冲区管理策略,根据应用程序的需求和逻辑来控制缓冲区的刷新。这允许应用程序更灵活地处理数据刷新,以满足特定的性能要求。
linux中的普通文件的刷新策略是全缓冲,显示器上的刷新策略是行刷新
用户缓冲区
为什么
用户缓冲区(User Buffer)
性能优化:用户缓冲区可以提高输入输出性能。相比于相比于直接在系统缓冲区进行操作,用户缓冲区允许应用程序更好地控制数据的传输。应用程序可以根据需要调整缓冲区大小,以及设置特定的刷新策略。这有助于优化特定应用场景的性能。
数据安全性:用户缓冲区可以提高数据安全性。应用程序可以将数据先写入用户缓冲区,然后由系统缓冲区将数据传递给底层设备。这种方式可以在一定程度上避免应用程序直接操作底层设备,从而降低潜在的安全风险。
编程便利性:用户缓冲区提供了更方便的编程接口。通过使用C标准库(如stdio.h)提供的函数,开发人员可以轻松地在用户缓冲区中进行输入输出操作,而无需关心底层实现细节。这有助于提高编程效率和可读性。
错误处理:用户缓冲区允许应用程序更好地处理错误。在输入输出过程中,如果发生错误(如设备不可用、内存不足等),应用程序可以在用户缓冲区中检测到这些错误,并采取相应的措施。而在直接操作系统缓冲区的情况下,错误处理可能更加困难。
C语言中的FILE 操作系统中的文件表项
在C语言中,以一个FILE结构体维护文件。包含:
文件描述符(
int _fileno):用于标识文件的描述符,它是一个整数值。文件流指针(
_IO_FILE *_filp):指向标准I/O库内部的文件流结构体。该结构体包含了许多与文件I/O相关的成员变量,其中包括缓冲区的相关成员变量。缓冲区基址指针(
unsigned char *_base):表示缓冲区的起始地址。当前位置指针(
unsigned char *_ptr):表示当前缓冲区的读写位置。缓冲区剩余的可用字节数(
int _cnt):表示当前缓冲区中剩余的可用字节数。缓冲区类型(
unsigned short _flag):用于标识缓冲区类型的位字段,如是否为缓冲输入或输出、是否有错误等。
C标准库提供了一些函数(如setbuf()和setvbuf())来手动控制FILE结构体中的缓冲区设置。
好像和PCB中的文件表项类似?不是的
在操作系统的进程控制块(PCB)中,通常会存在一个文件描述符表(File Descriptor Table),用于管理进程打开的文件。文件描述符表中的每个条目(entry)是一个指向文件表(File Table)中的文件表项(File Table Entry)的指针。
文件表存放的项目是所有被打开的文件结构体指针。
FILE结构体(在C标准库中定义):FILE结构体是一种用于表示文件的抽象数据类型,用于对文件进行流式I/O操作。它包含了一些与文件I/O操作相关的成员变量,如文件描述符、缓冲区指针、读写位置指针、错误标志等。FILE结构体是C标准库为了方便用户进行文件I/O操作而定义的一个抽象数据结构。文件表项(File Table Entry):文件表项是操作系统内核中维护的一个数据结构,用于记录进程打开的文件信息。它通常包含了文件的元数据、读写指针位置、权限信息等,并提供给操作系统进行文件管理和控制。文件表项是操作系统内核级别的数据结构,只在内核空间中存在,用于内核处理文件操作请求,与具体的编程语言无关。
两者是怎么关联的
他们代表两种不同的文件结构体:
用户空间的文件结构体(如C语言中的
FILE结构体)内核空间的文件结构体:内核空间中用于管理文件的结构体。
用户空间中的FILE结构体和内核中的文件表项之间的联系是通过文件描述符(File Descriptor)建立的。当用户空间的程序打开一个文件时,内核会为该文件分配一个文件描述符,用户空间的FILE结构体会保存这个文件描述符。用户空间的程序通过对FILE结构体的操作,实际上是在对文件描述符所对应的文件表项进行操作。
当用户程序调用文件操作相关的函数时,例如fread()、fwrite()等,库函数内部会通过系统调用将操作请求传递给内核。内核根据文件描述符找到对应的文件表项,然后在内核空间中操作文件,并更新文件表项中的相关状态和数据。结果再通过系统调用返回到用户空间中的FILE结构体,供用户程序继续使用和处理。
两者的缓冲区是怎么关联的
操作系统内核会负责管理底层的文件系统和其他硬件资源。
当用户空间中的程序使用标准库中的文件操作函数(如fread()或fwrite())时,这些函数会将请求发送给操作系统内核。内核会根据请求的类型和参数执行相应的操作(系统接口),例如读取或写入文件数据。
在内核空间中,文件系统通常会维护一个缓冲区池(Buffer Pool),用于缓存文件数据。当内核接收到文件操作请求时,它会从缓冲区池中分配一个合适的缓冲区,并将请求的数据写入该缓冲区。
具体来说,当用户空间中的程序调用fwrite()函数将数据写入文件时,内核会首先检查缓冲区池中是否有可用的空闲缓冲区。如果有,内核就会使用这个缓冲区来存放应用程序写入的数据。这样,数据就先被缓存在内存中的缓冲区里,而不是直接写入磁盘。
如果缓冲区池中没有空闲的缓冲区,这意味着所有缓冲区都已经被占用,这时候内核有几种处理方式:
等待缓冲区释放:内核可以等待,直到有缓冲区变得空闲。这可能会导致应用程序的写入操作暂时阻塞。
刷新缓冲区:如果缓冲区里的数据已经准备好写入磁盘,内核可以选择刷新(flush)缓冲区,将数据写入磁盘。这可能会牺牲一些性能,因为写入磁盘通常比内存操作慢
分配新的缓冲区:在某些情况下,内核可能会选择分配一个新的缓冲区,即使缓冲区池已满。这通常发生在系统配置的缓冲区大小不足以满足所有应用程序的需求时。
在大多数现代操作系统中,缓冲区管理是由内核自动进行的,应用程序通常不需要担心缓冲区是否可用或数据是否已经写入磁盘。当应用程序调用文件关闭操作(如fclose())时,或者在一定时间后(取决于操作系统的具体实现),内核会自动将缓冲区中的数据写入磁盘,以确保数据持久化。这种机制可以提高系统的性能和效率,因为读取和写入操作通常比直接访问磁盘更快。
理解语言层(用户层)和内核层
C语言与Linux系统的buffer
在C语言中,在标准库(stdio.h)中提供了输入输出函数(如fgets()、fputs()、fprintf()、fscanf()等)来进行输入输出操作。这些函数操作的是由标准库实现的缓冲区,称为标准I/O缓冲区。当使用标准库函数读取或写入数据时,数据首先存储在缓冲区中,然后根据标准库的策略进行处理、刷新或写入实际设备。
Linux中的缓冲区是指操作系统内核维护的输入输出缓冲区。内核提供了I/O缓冲区来处理文件和设备的读写操作。当应用程序调用系统调用函数(如read()、write())进行输入和输出时,数据将首先存储在内核缓冲区中,然后根据操作系统的策略进行处理、刷新或写入实际设备。
标准I/O库位于用户层,提供了更高级的输入输出操作接口,而Linux内核处于操作系统底层,处理底层的输入输出操作。C语言的输入输出操作实际上是调用操作系统的接口来实现的。
实验:
1.显示器文件的刷新方式是行刷新
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
const char* fstr = "I am fwrite!\n";
const char* str = "I am write!\n";
printf("I am printf\n");
fprintf(stdout,"I am fprintf\n");
fwrite(fstr, strlen(fstr), 1, stdout);
write(1,str,strlen(str));
return 0;
}
输出:
[root@MYCAT Filetest]# ./mytest I am printf I am fprintf I am fwrite! I am write!
对照实验:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
const char* fstr = "I am fwrite!";
const char* str = "I am write!";
printf("I am printf");
fprintf(stdout,"I am fprintf");
fwrite(fstr, strlen(fstr), 1, stdout);
write(1,str,strlen(str));
close(1);//关闭了标准输出流
return 0;
}
输出:
[root@MYCAT Filetest]# ./mytest I am write![root@MYCAT Filetest]#
解释:write是系统接口,直接在屏幕上输出,然而C函数是行缓冲,进行到close直接关闭了流,就不能输出信息了。
2.普通文件的刷新方式是全缓冲
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
const char* fstr = "I am fwrite!\n";
const char* str = "I am write!\n";
printf("I am printf\n");
fprintf(stdout,"I am fprintf\n");
fwrite(fstr, strlen(fstr), 1, stdout);
write(1,str,strlen(str));
fork();
return 0;
}
两种输出:
[root@MYCAT Filetest]# ./mytest I am printf I am fprintf I am fwrite! I am write! [root@MYCAT Filetest]# ./mytest > output.txt [root@MYCAT Filetest]# cat output.txt I am write! I am printf I am fprintf I am fwrite! I am printf I am fprintf I am fwrite!
现象:
输出到屏幕上时:正常顺序。
重定向到文件中的内容,首先先出现的是
I am write!, 接下来C语言的函数每个都打印了两次。
解释:
(第一个输出)*C函数是行缓冲,每次\n都会调用系统接口写入缓存池,显示器也是行缓冲,每次\n刷新缓存池写入文件
(第二个输出)
一种解释:
首先,linux普通文件是全缓冲的方式写入的,所以C函数输出的内容首先放到了缓存池中。
接着fork会创建一个与父进程几乎一模一样的子进程,但是子进程会复制父进程的地址空间(几乎相同的上下文)。同时缓存池中的数据也会复制,这时候结束程序刷新缓存池,就会写入两次。可以用wait函数查看这里的父子进程写入的过程
另一种解释:
在重定向到文件时候,C语言与操作系统都认识到了这是一个普通文件,他们更换了自己的刷新策略,全部都是全缓冲。
fork会创建一个与父进程几乎一模一样的子进程,子进程会复制父进程的地址空间(几乎相同的上下文)。同时用户缓存区中的数据也会复制,这时候结束程序父子进程都会写入缓存池,同时由于程序终止,系统调用函数刷新缓存池写入文件。
思考:
关闭流,原本输入系统缓冲区的内容被呈现,然而C语言函数的缓冲区没有显示,所以C语言函数与系统的缓冲区是不同的,C语言有自己的策略(行缓冲)决定什么时候将自己的缓冲区(用户缓冲区)内容刷新系统缓冲区。
拓展:之前说的exit 与 _exit 接口,exit函数会刷新自己的用户缓冲区, _exit是系统调用,它看不到C函数的缓冲区,因此会直接退出当前进程。exit()就像是 fflush(stdout) 这是一个C接口 接着调用 _exit()这是系统接口
fflush(stdout)在底层一定调用的是write接口,把stdout写到系统缓冲区中
模拟实现C语言的文件系统
Mystdio.h
//#pragma once
#ifndef __MYSTDIO_H__
#define __MYSTDIO_H__
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SIZE 1024
typedef enum {
FLUSH_LINE=1,FLUSH_ALL=2,FLUSH_NOW=4,
}WAY;
// 定义文件结构体
typedef struct {
int fd;
//char* filename;
char inbuffer[SIZE];
int in_pos;
char outbuffer[SIZE];
int out_pos;
WAY way;//缓冲刷新方式
} _FILE;
// 打开文件
_FILE* Fopen(const char* filename, const char* mode);
// 写入文件
int Fwrite(_FILE* file, const char* buffer, int size);
// 读取文件
int Fread(_FILE* file, char* buffer, int size);
// 关闭文件
void Close(_FILE* file);
//刷新缓冲区
void Fflush(_FILE* file);
#endif // !__MYSTDIO_H__
Mystdio.c
#include"Mystdio.h"
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<stdlib.h>
#include<unistd.h>
#include<assert.h>
#define FILE_MODE 0666
// 打开文件
_FILE* Fopen(const char* filename, const char* flags) {
assert(filename); // 检查文件名不为空
assert(flags); // 检查标志不为空
int f = 0;
if (strcmp(flags, "w") == 0) f = (O_CREAT | O_WRONLY | O_TRUNC);
else if (strcmp(flags, "a") == 0) f = (O_CREAT | O_WRONLY | O_APPEND);
else if (strcmp(flags, "r") == 0) f = (O_RDONLY);
else return NULL;
int fd = open(filename, f, FILE_MODE);
if (fd == -1) return NULL;
_FILE* file = (_FILE*)malloc(sizeof(_FILE));
if (file == NULL) {
perror("malloc failed");
return NULL;
}
file->fd = fd;
file->way = FLUSH_LINE;
file->out_pos = 0;
return file;
}
int Fread(_FILE* file, char* buffer, int size) {
assert(file); // 检查文件指针不为空
assert(buffer); // 检查缓冲区不为空
int count = read(file->fd, buffer, size);
if (count == -1) {
perror("read failed");
}
return count;
}
// 写入文件
int Fwrite(_FILE* file, const char* buffer, int size) {
// 检查缓冲区是否足够大,防止写入的缓冲区不足的情况
if (size > (SIZE - file->out_pos)) {
Fflush(file); // 如果缓冲区不足,则先刷新缓冲区
}
memcpy(&file->outbuffer[file->out_pos], buffer, size); // 将数据写入缓冲区
file->out_pos += size;
if (file->way & FLUSH_NOW) {
Fflush(file); // 根据标志刷新缓冲区
}
else if (file->way & FLUSH_LINE) {
if (file->outbuffer[file->out_pos - 1] == '\n') {
Fflush(file);
}
}
else if (file->way == FLUSH_ALL) {
if (file->out_pos >= SIZE) {
Fflush(file);
}
}
return 1;
}
void Fflush(_FILE* file) {
assert(file); // 检查文件指针不为空
if (file->out_pos > 0) {
write(file->fd, file->outbuffer, file->out_pos); // 将缓冲区的内容写入文件
file->out_pos = 0;
}
}
// 关闭文件
void Close(_FILE* file) {
assert(file); // 检查文件指针不为空
Fflush(file); // 刷新缓冲区
close(file->fd); // 关闭文件描述符
free(file); // 释放文件结构体的内存
}
main.c
int main() {
_FILE* file = Fopen("myfile.txt", "w");
if (file == NULL) {
printf("Failed to open file\n");
return 1;
}
const char* s = "hello linux\n";
int cnt = 10;
while (cnt--) {
Fwrite(file, s, strlen(s)); // 使用strlen获取字符串长度而不是sizeof获取指针大小
}
Close(file);
return 0;
}
输出:
[root@MYCAT Filetest]# gcc test_mystdio_main.c test_mystdio.c -o test_mystdio.exe [root@MYCAT Filetest]# ./test_mystdio.exe [root@MYCAT Filetest]# cat myfile.txt hello linux hello linux hello linux hello linux hello linux hello linux hello linux hello linux hello linux hello linux
注意:
C语言中不能有默认参数。
文件系统
介绍
文件系统(File System)是一种数据结构,用于存储和管理文件和目录。文件系统为每个文件提供了一个唯一的地址,并允许用户和应用程序对文件进行访问、存储和共享。文件系统还负责维护文件和目录的元数据(如文件名、大小、创建日期、权限等),以及管理磁盘空间的使用。
分类
本地文件系统和网络文件系统。本地文件系统是存储在计算机本地硬盘上的文件系统,而网络文件系统允许在网络上访问和文件。常见的本地文件系统有NTFS、FAT、EXT4等,常见的网络文件系统有NFS、SMB/CIFS、HTTP等。
特点
文件和目录结构:文件系统通过文件和目录的组织方式来管理数据。文件是存储在磁盘上的具体数据单元,而目录则是用于组织和管理文件的容器。文件和目录之间的关系形成了文件系统的树形结构,允许用户使用层次化的方式组织和访问文件。
文件命名和路径:文件系统为每个文件分配一个唯一的名称,以便于识别和访问。文件名称遵循一定的命名规则和限制,如长度、字符集等。同时,文件系统使用路径来描述文件或目录的位置,路径可以是绝对路径(从根目录开始)或相对路径(相对于当前目录)。
文件访问和权限:文件系统通过访问控制列表(ACL)或访问权限来管理文件的访问。权限定义了允许用户或用户组执行的特定操作,如读取、写入、执行等。文件系统根据用户和权限来决定哪些文件可以被访问或修改。
文件的存储和分配:文件系统负责将文件存储在物理介质(如硬盘)上,并分配磁盘空间以存储文件的内容。文件系统需要管理磁盘上的空闲空间,并决定如何分配和组织文件的存储,以提高空间利用率和访问效率。
文件系统的日志和一致性:一些现代文件系统使用日志(Journaling)技术来记录文件系统操作的顺序和更改,以提供数据的一致性和恢复能力。日志记录允许在意外断电或系统故障发生时,文件系统可以更容易地恢复到之前的一致状态。
文件系统类型:存在多种不同的文件系统类型,其中每种文件系统具有不同的设计和特点。常见的文件系统包括NTFS、FAT32、ext4、APFS、HFS+等。每种文件系统都有其自己的优势和限制,适用于不同的操作系统和用途。
文件系统的性能和优化:文件系统的性能是指数据读取和写入的速度,以及文件的访问效率。文件系统的性能可以通过多种技术和优化策略来提高,如缓存、预读取、延迟写入等。
文件系统的一致性和恢复:文件系统需要维护数据的一致性和完整性,以确保文件和目录的元数据和内容不会丢失或损坏。为了实现这一点,文件系统需要使用各种一致性机制,如事务、日志和校验和。此外,文件系统还需要支持数据的恢复和故障恢复,以便在发生意外或系统故障时能够地恢复正常运行。
文件系统的可靠性和容错:文件系统需要保证数据的可靠性和容错,以防止数据丢失或损坏。这可以通过使用冗余存储、备份校验来实现。冗余存储允许文件系统在磁盘上存储多个副本,以防止单个磁盘的故障。备份允许文件系统将数据复制到另一个位置,以便在发生问题时可以恢复数据。校验和允许文件系统检测和修复数据中的错误,以保证数据的完整性。
文件系统的可扩展性和兼容性:文件系统需要支持可扩展性和兼容性,以适应不同的应用需求和硬件平台。为了实现这一点,文件系统需要支持跨平台兼容性、大文件支持、加密和压缩等特性。
结构
文件系统具有物理结构和逻辑结构两个层面。
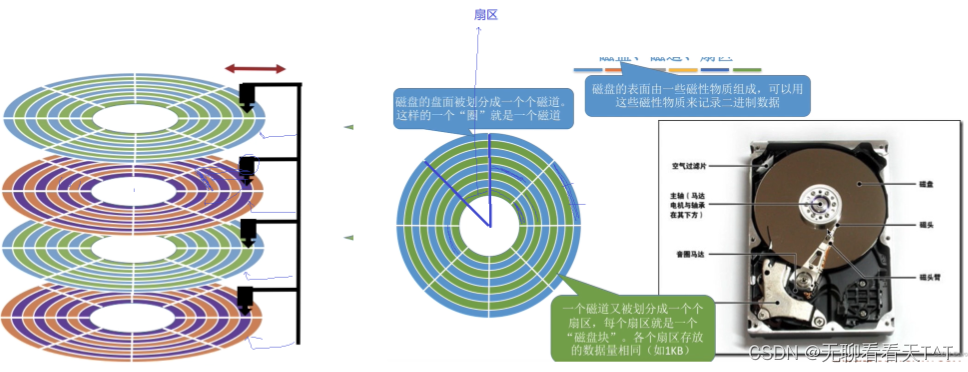
物理结构: 文件系统的物理结构是指文件系统在物理介质(如硬盘)上的组织方式。物理结构定义了数据在磁盘或其他存储设备上的存储方式和排列方式。主要的物理结构包括:(前言知识有所介绍)
磁盘块(Disk Block):磁盘被划分为固定大小的块,例如磁盘块大小通常为4KB、8KB或更大。文件和目录通常以一个或多个磁盘块的形式存储在磁盘上。
盘片和磁头(Platters and Heads):磁盘通常由多个盘片组成,每个盘片有两个表面,每个表面有一个磁头。磁头通过在盘片上读写数据,以及控制盘片的旋转和位置来实现数据的访问。
磁道和扇区(Tracks and Sectors):磁盘表面被划分为一个个圆形的磁道(Tracks),每个磁道被分为若干个固定大小的扇区(Sectors)。文件和目录的数据以扇区为单位存储在磁盘上。
逻辑结构: 文件系统的逻辑结构是指通过文件和目录的组织方式来管理数据。逻辑结构定义了文件和目录之间的关系、数据的访问方式、权限控制等。主要的逻辑结构元素包括:
文件(File):文件是计算机中存储数据的基本单位,可以是文本文件、图像文件、音频文件等各种形式。文件通常有唯一的文件名,可以包含数据、属性和元数据等信息。
目录(Directory):目录用于组织和管理文件,它是一个包含文件和子目录的容器。目录具有唯一的目录名,并可以包含文件和子目录的引用。
路径(Path):路径是指定文件或目录在文件系统中位置的方法。它可以是绝对路径(从根目录开始的完整路径)或相对路径(相对于当前工作目录的路径)。
文件属性和权限:文件系统为每个文件和目录定义了一组属性,如文件大小、创建时间、修改时间等。同时,文件系统还定义了权限机制,以控制文件和目录的访问权限。
文件系统的物理结构和逻辑结构相互关联,物理结构决定了数据存储的方式,而逻辑结构定义了数据的组织和访问方式。通过物理结构和逻辑结构的组合,文件系统可以提供高效、安全和可靠的数据存储和访问。
EXT4文件系统
图解
ext2
分区(文件系统) 磁盘
| ----------------|------------------|-----------------|
/ | \
|Boot Block| Block group 0 |---|---|---| -|---|---|---||Block group n |
/ | \
|Super Block | Group Descriptor Table | Block Bitmap | |inode Bitmap| inode Table | Data blocks (1----n)..|
另一种
分区(文件系统) 磁盘 | ----------------|------------------|-----------------| / | \ |Boot Block| Super Block |--|Block group 0 |---|---|---|---|---|---||Block group n | / | \ | Group Descriptor table| Block Bitmap | inode Bitmap|. ...| inode Table | Data blocks (1----n)..|
分区(磁盘分多份)
磁盘空间很大,所以要分区管理,就相当于电脑的C盘D盘
分区的优势:
数据组织和管理:通过分区,可以将磁盘空间划分为逻辑部分,使得存储的数据更有结构性和组织性。不同分区可以用于存储不同类型的数据,便于管理和维护。
磁盘性能优化:将磁盘分为多个分区可以提高磁盘的性能和数据访问速度。例如,可以将操作系统和常用程序放在一个分区中,将用户数据放在另一个分区中,避免数据混杂导致的碎片化和访问冲突。
数据安全和恢复:分区的一个重要作用是隔离不同类型的数据,从而降低数据损失的风险。如果某个分区发生故障或数据丢失,其他分区的数据仍然可以保持完整,便于快速恢复和修复。
多操作系统支持:通过分区管理,可以在同一磁盘上安装多个操作系统,并将每个操作系统安装在不同的分区中。这样可以实现多重启动和灵活的操作系统选择。
可以打开磁盘管理查看分区信息
Boot Block
Boot Block,也称为引导块,是文件系统中的一个特殊块,它位于文件系统的最前面,通常占据第一个块。Boot Block的主要作用是在文件系统被挂载时,提供文件系统的基本信息,以便操作系统能够识别和挂载文件系统。
Boot Block中通常包含以下信息:
文件系统的魔数(Magic Number):用于标识文件类型。例如,EXT4文件系统的魔数
文件系统版本号:用于标识文件系统的版本。
文件系统类型:用于标识文件系统的类型,如EXT4、FAT等。
块大小和数量:提供文件系统块的大小和数量信息,以便操作系统能够正确地读取和写入数据。
其他相关信息:根据不同的文件系统,Boot Block可能还包含其他相关信息,如文件的分配表、目录结构等。
Boot Block的布局和实现通常由文件系统的内核实现负责,它是文件系统内核的一个重要组成部分,对于文件系统的稳定性和性能至关重要。当操作系统启动时,它通常会读取Boot Block中的信息,并根据这些信息进行文件的挂载和访问。
Super Block
Super Block(超级块)存储了文件系统的全局元数据。Super Block包含了有关文件系统的基本信息,如文件系统类型、文件系统大小、块大小、inode大小、文件系统状态、挂载次数等。
Super Block通常位于磁盘上的固定位置,并在文件系统被挂载时被读取。super block对于每个文件系统都是唯一的,并且通常存储在文件系统的第一块或第一个inode中。(其他分组可能有Super Block 的备份)
Super Block可以包括以下内容:
文件系统的类型:指示文件系统的类型,如ext4、NTFS、FAT32等。
文件系统的大小:表示整个文件系统的总容量。
块大小:指示文件系统中块(block)的大小,通常是4KB、8KB等。
inode大小:指示文件系统中inode的大小。
文件系统状态:表示文件系统的状态,如已挂载、已卸载、损坏等。
挂载次数:记录文件系统被挂载的次数,用于检测文件系统的一致性。
块位图和inode位图的位置:表示位图(bitmap)存储在磁盘上的位置,用于记录数据块和inode的使用情况。
磁盘中的其他元数据:可能包括根目录的inode号、文件系统的创建时间、最后挂载时间等。
Super Block充当了文件系统的关键指引,操作系统通过读取Super Block中的信息,来获得对文件系统的基本描述,并进行适当的文件系统操作和管理
魔数
文件系统的魔数(Magic Number)是一个用来标识文件系统类型的特殊数字或序列,它通常位于文件系统的引导块(Boot Block)或超级块(Super Block)中。用于告知操作系统如何读取和解释文件系统中的数据结构。
不同的文件系统有不同的魔数,这些魔数被设计为难以误判的特定数值,以区分不同的文件系统类型。例如:
EXT4文件系统的魔数是0xEF53(十六进制)。
FAT12/16/32文件系统的魔数分别是0xFF11(FAT12)、0xFF11(FAT16)和0xFF1A(FAT32)。
NTFS文件系统的魔数是0x5346(十六进制),即"NTFS"节序。
当操作系统启动时,它会检查磁盘分区的魔数,以确定该分区使用的文件系统类型,并据此加载相应的文件系统驱动程序。魔数是文件系统和处理磁盘数据的关键。
在文件系统的设计中,魔数是一个重要的概念,它确保了文件系统的兼容性和可识别性。
数据块组(分区分多份)
在EXT4文件系统中,文件系统被分为多个block group。
组的分类:
根据数据块组中的数据类型和存储方式的不同:
普通数据块组:存储文件数据的块组。
目录块组:包含目录信息的块组,用于存储目录的名称和对应的inode或数据块地址。
索引节点块组:包含索引节点信息的块组,用于存储文件的元数据信息。
特殊块组:如FAT块组,用于存储文件系统的文件分配表。
组存放的信息:
可能有Super Block的拷贝;
数据:数据块组中存储了文件的具体内容。
校验信息:为了确保数据块中的数据在传输和存储过程中不会发生错误,文件系统可能使用校验信息来检测和修复数据块中的错误。
目录信息:对于文件系统支持的目录系统,目录信息包含关于文件或目录的元数据信息,如名称、权限、位置等。
索引节点信息:在一些文件系统中,如EXT3/4,每个数据块组都关联一个索引节点(inode),inode包含有关文件或目录的元数据信息,如文件大小、创建时间、修改时间等。
块BLOCK
文件系统通过使用文件控制块(FCB)或索引节点(inode)等数据结构来描述和存储文件的元数据(metadata),包括文件的名称、大小、权限、创建时间、修改时间等信息。这些元数据存储在分区中的某个位置,以指向具体文件数据的指针。
在组中有一些块:
Super Block:为了防止出现系统分区出错文件系统崩溃,在一些分区中可能会有超级块的拷贝,并且会维护这个块使所有的超级块一致。
Group Descriptor Table:它包含了关于该block group,如该组中数据块的数量、inode的数量、块位图和inode位图的地址等。group descriptor table是所有group descriptor(组描述符)的集合,它描述了文件系统中所有block group的布局
Group Descriptor Table记录了每个分组的重要信息,例如:
分组的起始块号
数据块和inode的数量
指向数据块位图和inode位图的指针。
指向该组inode表的指针。
块和inode之间的映射关系
分组中未分配块和inode的数量
分组中文件和目录的数量
通过Group Descriptor Table,文件系统可以快速找到和查询每个分组的相关信息,从而更有效地管理磁盘空间和分配资源。组描述符表的位置通常是在文件系统的根目录所在的块或者是在文件系统的第一个数据块中。这是因为这些位置是文件系统启动和初始化时最先被加载和访问的部分。在这里存放组描述符表可以确保文件系统在启动时能够快速访问到关键的元数据信息。
Block Bitmap:block bitmap是用于跟踪block group中每个数据块的使用情况的一个位图。它是一个一维数组,每个元素对应一个数据块,如果该元素为0,则对应的数据块未被使用;如果为1,则表示已被使用。
Inode Bitmap:inode bitmap与block bitmap类似,但它用于跟踪block group中的每个inode的使用情况。它一维数组,每个元素对应一个inode,值为0表示inode未被使用,值为1表示已被使用。
Inode Table:inode table是存储文件系统中所有inode的元数据的数组。每个inode包含文件或目录的元数据,如文件大小、创建时间、修改时间、权限、链接数、文件数据块的地址等。inode table中的每个条目都指向一个inode,inode number用于唯一标识每个文件或目录。
Data Block:块(block)是存储实际文件数据的基本单元,块的大小通常为4KB、8KB等。每个块都被分配一个唯一的地址来标识其在磁盘上的位置。文件系统通过维护文件数据块的地址和顺序,将文件的内容链接到一起,实现对文件的读写访问。
这些数据结构共同工作,以确保文件系统的数据正确地存储和检索,以及有效地使用磁盘空间。它们是文件系统内核实现的重要组成部分,对于文件系统的稳定性和性能至关重要。
Inode号与块号的分配
统一的inode号分配:
假设100万个inode号,每个分组都有一部分inode号。例如有5个分组(0-20万第一个分组,......),那么假设访问第23万个inode。那么会在第二个组中的Inode Bitmap中直接看第3万个标志位就可知道这个inode号的状态。同时在Inode table中可以找到对应的inode结构体。
独立的块号分配:
块号的分配与inode号是独立的,每个组(block group)有自己独立的块号范围。在Block Bitmap中,可以以位图的方式表示每个数据块的分配状态,以快速查看哪些数据块已分配和未分配。
Inode FCB
介绍
inode(索引节点)是文件系统中的一种数据结构,用于存储和管理文件的元数据(metadata)。它记录了关于文件的各种属性和指向文件数据块的指针,而实际的文件数据则存储在数据块中。
每个文件在文件系统中都有一个唯一的inode,它由一个整数表示,称为inode号。inode号用于标识和访问特定的文件。这些inode被组织成inode表(inode table)的结构,每个inode在表中占据固定大小的空间。(一般是128字节)
在inode表中,每个inode都对应一个唯一的inode号码(inode number),用于标识和访问特定的文件。查看inode标号可以通过 ls -i 查看。
inode通常包含以下信息:
inode标号:在inode bitmap中映射,指示inode号的使用情况。
文件类型:指示文件是普通文件、目录、符号链接等。
文件权限:包括读、写、执行权限。
文件所有者和所属群组:指明文件的所有者和所属群组。
文件大小:指示文件占用的存储空间大小。
创建时间和最后修改时间:记录文件的创建时间和最后一次修改时间。
链接计数:表示有多少个目录项链接到这个inode,即硬链接的数量。
指向文件/目录数据块的指针:指示文件数据(目录数据)在磁盘上的位置。
通过inode,文件系统可以快速定位和访问文件的元数据和数据。当访问文件时,操作系统根据文件的路径解析到文件对应的inode,然后使用inode中的信息来找到文件的数据块,从而读取或修改文件的内容和属性。
struct inode{
int inode;//inode标号
文件类型
文件权限
链接计数(引用计数)
拥有者 所属群组
ACM时间
int* block_table;
//指向指示文件/目录数据块的数组
};
#define NUM 15
int blocks[NUM];
inode没有存储文件的名字,文件名字在哪里?
在inode中确实没有直接存储文件名字。inode主要用于存储文件的元数据信息,如文件大小、创建时间、修改时间、权限等,以及指向文件数据块的指针。
文件名字与inode是通过目录项(directory entry)进行关联的。目录项是一个数据结构,包含了文件名和与之相关联的inode号码的映射关系。文件系统通过目录结构中的目录项来查找并定位文件的inode,然后使用inode中的指针来访问文件数据。
当我们访问文件时,操作系统会将目标文件的路径解析为目录树中相应的目录项,并使用目录项中存储的inode号码来检索文件的inode。然后,操作系统使用inode中的指针来读取或修改文件的数据块。
所以,文件名字存储在目录项中,而非inode中。目录项将文件名与inode关联起来,从而在文件系统中建立了文件名到对应inode的映射关系。
重点介绍一下blocks:
在示例中,我们设置了大小为15,数组中存放的是数据块的块号。每一个数据块的大小是4k,所以较大的文件是多个数据块整合的。
这个数组存放数据有特殊的规则。blocks数组中存放的是文件数据块的块号,提供了一种索引数据块的机制。具体规则如下:
直接索引(Direct Indexing):数组中下标为0到10的元素直接存储了文件内容所在的数据块的块号。这意味着文件的前11个数据块可以通过这些直接索引找到和访问。
间接索引(Single Indirect Indexing):数组中下标为11和12的元素存储了其他数据块块号的指针。这些数据块中存储的是更多数据块的块号,它们间接指向存储文件内容的数据块。
双重间接索引(Double Indirect Indexing):数组中下标为13和14的元素存储了其他数据块块号的指针。这些数据块中存储的是更多数据块的块号,而这些块中的数据又间接指向存储文件内容的数据块。
按照上边的规则(假设一个整形4个字节)可以最大存储的文件大小为:4k=4096B
为8,396,844k 约等于 8G 大小。
目录文件的数据块和inode
目录数据块存储着什么信息?
目录数据块存储着目录中的文件和子目录的信息。这些信息包括文件名、对应的inode号码以及其他与文件相关的元数据(如文件大小、所有者、权限等)。目录数据块中的记录有序地保存了目录中的文件和子目录的信息。
为什么同一个目录下不能有同名文件?
同一个目录下不能有同名文件的原因是为了确保文件系统中的唯一性和标识性。每个文件在文件系统中都有一个唯一的文件名,而文件名与文件的inode(索引节点)相关联(类似key-value关系)。如果同一个目录下存在同名文件,文件系统无法准确地识别和引用特定的文件,会导致混淆和冲突。
目录下没有w权限,我们无法创建文件,也无法删除里边的文件。可以在目录的子目录(如果有w权限)下创建文件。
目录下没有写权限(w权限),表示对目录没有创建、修改或重命名文件的权限。因此无法创建文件或删除目录中的文件。而在具有写权限的子目录下创建文件是因为子目录的写权限允许对该子目录进行创建、修改和删除操作。
目录下没有r权限,我们无法查看文件,却可以删除里边的文件。(如果知道文件名字的话)
目录下没有x权限,我们无法进入这个目录,却可以在目录外删除里边的文件。
目录下没有执行权限(x权限),表示无法进入该目录,无法使用该目录的路径来访问其中的文件或子目录。然而,删除目录仅涉及父目录中对该目录的操作,而不是对目录中的文件或子目录进行直接操作。因此即使没有执行权限,仍然可以删除目录中的文件。
所有情况下,我们都可以直接删除这个目录,不管他有什么权限。和普通文件是相同的。
FCB和inode
FCB(File Control Block)可以看作是文件结构体的一种实现方式。
文件结构体和inode结构体有着不同的用途和结构。
文件结构体通常用于描述文件的属性、内容和其他相关信息。文件结构体是一个抽象的数据结构,它可以包含各种字段,如文件名、文件大小、文件创建日期、文件权限等。文件结构体通常在文件系统中作为文件的元数据存储,用于提供对文件的操作和管理。
inode结构体则是一个更底层的结构,用于存储关于文件系统中的每个文件或目录的信息。inode结构体包含了文件的元数据(如文件大小、创建日期、权限等),还包含了关于文件的一些额外信息,如文件的访问和修改历史记录、文件的数据块地址等。这些信息对于文件系统的管理和优化非常重要,因为它们可以帮助系统更好地跟踪文件的修改和访问历史,从而提高文件系统的性能和稳定性。
FCB中可能包含了inode的指针
定位文件的过程
在文件系统中,定位文件通常涉及以下几个步骤:
路径解析:用户或应用程序提供的文件路径首先被解析为一系列目录项的序列,先递归找到根目录。每个目录项指向一个目录,并包含该目录的inode号。
查找inode:目录项的序列递归返回目录文件的inode。这是通过遍历目录项来实现的,直到找到最后一个目录项,它指向了目标文件的inode。
使用inode号:一旦找到了文件的inode号,操作系统就可以直接访问该inode,以获取文件的其他元数据(如文件大小、权限、修改时间等)以及指向文件数据块的指针。
访问数据块:文件的数据实际上存储在数据块中,这些数据块通过inode中的指针来访问。操作系统根据inode中的信息来定位文件的数据,并进行读取或写入操作。
整个过程是由文件系统的目录项和inode管理机制共同支持的,确保了文件可以被快速和准确地定位和访问。这种机制在各种操作系统和文件系统中都是基本且核心的特性。
删除文件的过程
定位文件
通过inode号在Inode Bitmap中查看标志位是否为1,然后在这个数组中查看块号。
在Block Bitmap中将文件占用的块全部置为0;
把Inode Bitmap 中的标志位置为0;
文件信息和它的inode都没有被删除,这是文件恢复的原理
文件的导入与写回(重点理解)
读取普通文件 修改文件内容的过程
文件通过inode等结构在磁盘中组织,要打开一个文件,首先要找到文件的inode。这是定位文件的过程。
然后将文件页放入物理内存中(如果文件过大,会先读取一部分,设置页表中的状态位),这个缓冲区可以是进程的堆空间、栈空间或其他已分配的内存区域。
这个缓冲区是用户缓冲区。
同时在系统内核中把inode的一些信息(物理地址的数组,权限信息、修改时间、文件大小等)(不是直接加载整个inode),Group Descriptor table(查看分组的使用率等),inode位图,block位图放入内存缓冲区。
接着生成页表,在页表中生成页帧(物理内存)与页框(磁盘)的映射关系(单位是4kb)页大小,权限等等信息。每一个页表项都有自己的属性和状态位。
创建文件时候,会在inode位图中找可用位置,在缓冲区中创建inode。同时在block位图中找可用位置,置状态位为使用,同时在内存中建立新的页页帧,然后生成页表,在页表中建立新的虚拟内存与物理内存的映射关系,设置页表项的属性。
修改文件内容时候,会首先检查页表项的权限位,然后开始修改,如果发生了页溢出,会在block位图中找合适的位置,置状态位为使用。在页表中建立新的虚拟内存与物理内存的映射关系,设置页表项的状态位,比如设置有效位,脏页位。正常修改会修改页表项的状态位。
修改文件属性的时候,会在加载到缓冲区的inode中修改。同时会将页表项中的权限位全部修改。(不会设置脏页位)
可能会根据系统的写回策略,将脏页提前写回,并且修改脏页位。
关闭文件或者进程终止时候,会根据映射关系和状态位(脏页位)将磁盘中的页进行覆盖。完成后。会将修改的inode,inode位图,block位图,组描述符表进行更新。
最后将缓存擦除或者丢弃(置为失效)。
总结:
定位文件的inode,读取文件的元数据和数据块位图到内存缓冲区。
创建或修改页表,建立虚拟地址到物理地址的映射关系。
读取或修改文件内容时,根据页表中的映射关系访问相应的物理内存。
如果发生页溢出或新增内容,需要在inode位图和block位图中分配新的块,并更新页表和相应的状态位。
在修改文件属性时,直接在内存中修改inode的相应字段。
关闭文件或终止进程时,根据需要更新磁盘中的数据块,并更新inode、inode位图、block位图等相关信息。
注意:
我们没有谈论文件操作时他的目录文件的操作,这是一个复杂的内容,是一个递归的过程。
进程不关心文件是否刷新到磁盘,每一个文件都有自己的文件页的缓冲区(可能加载了文件的一部分到内存中,但是进程通通不关心)。
写回(write-back)策略
常见的写回策略包括延迟写入和异步写入
延迟写入(Delayed Write):延迟写入策略是将文件修改的数据暂时存储在内存中的缓冲区中,而不是立即将数据写回磁盘。当缓冲区达到一定大小或发生特定事件时,才将缓冲区中的数据一次性写回到磁盘。这种策略可以提高写入性能,减少频繁的磁盘写操作。
异步写入(Asynchronous Write):异步写入策略是指在文件或数据修改后,将数据写入内存缓冲区,并立即通知调用方(如应用程序或用户),表示写入操作已成功完成。而实际的写入磁盘操作则由操作系统负责在适当的时机进行。这种策略可以提高磁盘写入效率和整体系统的响应性能。
创建文件的过程
创建文件的过程涉及到多个步骤,包括文件的分配、元数据的创建和维护等。以下是一个简化的描述文件创建过程的步骤:
分配inode:当创建一个新的文件时,文件系统首先需要为一个文件分配一个inode。这通常涉及到在Group Descriptor table 查看分组的使用率 在inode表中找到一个未被使用的inode号。如果inode表已满,文件系统可能需要扩展inode表或回收已删除文件的inode。
设置inode元数据:一旦分配了inode,文件系统将在inode结构中设置各种元数据字段,如文件大小、权限、链接计数、创建时间、修改时间、访问时间、所有者、所属群组等。
分配数据块:如果文件有数据需要存储,文件系统将为文件分配数据块。这可能涉及到在数据块位图中找到空闲的数据块,并将它们标记为已使用。如果数据块位图已满,文件系统可能需要扩展数据块位图或回收不再使用的数据块。
写入数据:将文件的数据写入分配的数据块中。文件系统会将数据从用户空间复制到内核空间,然后写入磁盘上的数据块。
更新inode和数据块位图:一旦数据被写入数据块,文件系统将更新inode结构中的数据块指针,以便指向新分配的数据块。同时,文件系统还会更新数据块位图,以反映新的数据块使用情况。
文件系统同步:在文件创建过程中,文件系统可能会执行同步操作,以确保所有的改动都写入磁盘。这可以防止数据丢失,在系统崩溃时保护文件的完整性。
返回控制权:完成文件创建后,文件系统将返回控制权给创建文件的系统调用,此时文件系统已经为文件分配了必要的资源,设置了相应的元数据。
修改文件属性的过程
修改文件属性的过程涉及文件系统的元数据操作。
打开文件:首先需要打开要修改属性的文件。这通常通过文件系统提供的系统调用来实现,例如
open()函数。获取文件的inode:通过文件系统中的目录结构,找到文件对应的inode。这可以通过遍历目录,根据文件名找到文件的inode。
修改inode的属性:获取到文件的inode后,可以通过系统调用或API将具体的属性值写入到inode结构中。常见的文件属性包括文件权限、所有者、组、修改时间等。
更新文件系统:将修改的inode信息持久化到磁盘。这通常需要利用文件系统的写入机制,在指定的位置更新inode的内容。
关闭文件:在完成属性修改后,关闭文件以释放资源。通常使用
close()函数来关闭文件。
文件系统的初始化(了解)
以下是文件系统初始化的一些基本步骤:
创建超级块:超级块是文件系统的元数据之一,它包含了文件系统的全局信息,如文件系统类型、大小、块大小、inode大小、挂载时间等。初始化过程中会创建并填充超级块。
创建组描述符表:文件系统通常会被划分为多个组(block group),每个组包含一定数量的数据块和inode。组描述符表用于管理和描述每个组的信息,如数据块和inode的数量、未使用块和inode的数量等。
初始化数据块位图和inode位图:位图结构用于跟踪文件系统中数据块和inode的分配情况。在初始化过程中,会创建并初始化这些位图,标记所有块和inode为未使用。
创建inode表:inode表是存储文件系统中所有inode的元数据的数组。每个inode包含有关文件或目录的元数据信息,如文件大小、权限、链接计数、所有者、群组等。初始化过程中会创建inode表,并分配初始的inode号。
分配数据块:文件系统需要为文件分配数据块来存储实际的数据。在初始化过程中,会根据文件的大小和块的大小分配数据块,并更新数据块位图和inode中的指针。
设置文件系统标志:初始化过程中还会设置文件系统的标志,如是否为只读、是否支持压缩等。
7 挂载文件系统:一旦文件系统的初始化完成,它就可以被挂载到文件系统树中,供操作系统使用。
文件系统的初始化通常在操作系统启动时或者在文件系统被首次挂载时进行。
软硬链接
硬链接
在Linux中,硬链接(hard link)和软链接(symbolic link,又称符号链接)是两种不同类型的链接,它们都可以用来创建文件系统中的链接。
硬链接(hard)是指在同一文件系统中的两个或多个文件共享相同的inode和数据块。硬链接的特点是:
硬链接共享原文件的所有权、权限和时间戳。
硬链接和原具有相同的文件名和路径。
硬链接和原文件之间共享inode和数据块,因此对其中一个文件进行的修改会反映在另一个文件中。
硬链接只能链接同一文件系统中的文件。
注意点:
不能给目录文件创建硬链接,为什么?
在 Linux 中,不能直接为目录文件创建硬链接,主要原因是:
安全问题:如果可以对目录文件创建硬链接,那么可以创建多个指向同一目录的硬,这样就可以绕过文件系统的访问控制机制,使得用户可以访问该目录下的所有文件,包括那些原本不应该被访问的文件。
无限循环:如果可以对目录文件创建硬链接,那么可以创建一个指向该目录的硬链接,然后将该链接放回该目录中,这样就会导致无限循环。因为硬链接指向的文件必须存在于该目录中,而该目录本身又指向了该文件,因此会出现死循环。
目录遍历:如果可以对目录文件创建硬链接,那么可以创建多个指向同一目录的硬链接,然后将它们放在不同的目录中。这样就可以绕过文件系统的访问控制机制,使得用户可以访问该目录下的所有文件,包括那些原本不应该被访问的文件。
因此,出于安全考虑,Linux 不支持对目录文件创建硬链接。但是,可以使用符号链接(Symbolic Link)来链接目录,这种链接类似于 Windows 中的快捷方式,它只是指向目标目录的一个文本指针,而不是一个实际的文件或目录。
软连接(符号链接)
软链接(symbolic link,又称符号链接)是指一个特殊的文件,它包含一个指针或引用,指向另一个文件或目录。软链接的特点是:
软链接和原文件不共享所有权、权限和时间戳。
软链接和原文件具有不同的文件名和路径。
软链接指向另一个文件或目录,可以是同一系统中的文件或跨文件系统中的文件。
软链接可以用来创建目录链接(directory symbolic link)。
软链接可以用来链接文件和目录。
软链接可以用来更改链接目标的文件名或路径。
符号链接的数据块
软链接文件(符号链接)本身并不存储目标文件的数据,它只包含指向目标文件的路径或文件名的字符串。
当你使用软链接文件访问目标文件时,系统将会解析软链接文件,并根据其中保存的路径或文件名找到真正的目标文件。因此,软链接文件存储的是一个路径或文件名的字符串,它表示了链接到目标文件的位置。
需要注意的是,软链接文件和目标文件是两个不同的实体,它们具有不同的inode和数据块。软链接只是一个指向目标文件的引用,并不实际包含目标文件的数据。因此,软链接文件的大小通常很小,只占用一些磁盘空间用于存储路径或文件名字符串。
符号链接为什么不直接存储inode?
软连接(symbolic link)之所以存储的是路径字符串而不是直接存储目标文件的inode号码,主要是出于以下几个原因:
文件系统独立性:软连接的一个关键特性是它可以跨越不同的文件系统。如果软链接直接存储目标文件的inode号码,那么它将只限于在相同的文件系统中工作。因为不同的文件系统可能使用不同的inode号码分配机制,直接存储inode号码会导致软链接在不同文件系统之间不可移植。
灵活性和可移动性:软连接的路径字符串允许目标文件在不改变软链接的情况下被移动。如果软链接直接指向inode,那么当目标文件被移动到新的位置时,软链接将无法自动更新到新的路径,除非文件系统实现特殊的机制来跟踪inode到路径的映射。
安全性:通过存储路径字符串,软链接不直接暴露目标文件的位置信息。这提供了一定程度的安全性,因为即使某个用户有权限读取软链接,他们也无法直接访问目标文件的数据块,除非他们具有访问目标文件的权限。
简单性:存储路径字符串比存储inode号码简单,因为文件系统的实现不需要关心inode号码的具体分配和映射。路径字符串是操作系统提供的标准方式来引用文件,因此使用路径字符串作为软链接的内容可以简化文件系统的实现。
兼容性:软链接的路径字符串格式兼容性强,可以在不同的操作系统和文件系统之间通用。大多数操作系统都支持路径字符串作为文件引用的标准格式。
可读性:路径字符串对用户来说是可读的,用户可以轻松地看到软链接指向的是哪个文件。而inode号码对用户来说是不直观的,且不同的文件系统可能会有不同的inode号码范围和分配策略。
命令
ln命令的基本语法如下:
ln [选项] 源文件 目标文件
其中,常见的选项包括:
-i:交互式操作,询问是否覆盖已存在的文件。-s:创建符号链接(符号链接)-f:强制创建链接,不提示是否覆盖已存在的文件。-b:创建硬链接(硬链接)。-c:创建副本(硬链接)。
例如:
ln -b linkfile originalfile ln -s linkfile originalfile
请注意,硬链接和符号链接的区别在于它们如何引用源文件。硬链接共享源文件的inode和数据块,而符号链接仅包含指向源文件的引用。
实验:
ll命令查看硬链接数(引用计数)
touch file.txt ln -s file.txt soft-link ln -b file.txt hard-link ll -rw-rw-r-- 2 lzh lzh 0 Feb 4 18:55 file.txt -rw-rw-r-- 2 lzh lzh 0 Feb 4 18:55 hard-link lrwxrwxrwx 1 lzh lzh 8 Feb 4 18:55 soft-link -> file.txt ll -i //查看inode号 34559945 -rw-rw-r-- 2 lzh lzh 0 Feb 4 19:03 file.txt 34559945 -rw-rw-r-- 2 lzh lzh 0 Feb 4 19:03 hard-link 34559946 lrwxrwxrwx 1 lzh lzh 8 Feb 4 19:03 soft-link -> file.txt (引用计数) rm hard-link ll -rw-rw-r-- 1 lzh lzh 0 Feb 4 18:55 file.txt lrwxrwxrwx 1 lzh lzh 8 Feb 4 18:55 soft-link -> file.txt
理解引用计数
[lzh@MYCAT Link]$ mkdir dir [lzh@MYCAT Link]$ cd dir/ [lzh@MYCAT dir]$ ll -ia total 0 53489959 drwxrwxr-x 2 lzh lzh 6 Feb 4 19:21 . 33808904 drwxrwxr-x 3 lzh lzh 67 Feb 4 19:21 .. [lzh@MYCAT dir]$ cd - /home/lzh/tmp/Link [lzh@MYCAT Link]$ ll -ai total 0 33808904 drwxrwxr-x 3 lzh lzh 67 Feb 4 19:21 . 33832651 drwxrwxr-x 7 lzh lzh 89 Feb 4 18:54 .. 53489959 drwxrwxr-x 2 lzh lzh 6 Feb 4 19:21 dir [lzh@MYCAT Link]$ mkdir dir/dir1 [lzh@MYCAT Link]$ ll -ai total 0 33808904 drwxrwxr-x 3 lzh lzh 67 Feb 4 19:21 . 33832651 drwxrwxr-x 7 lzh lzh 89 Feb 4 18:54 .. 53489959 drwxrwxr-x 3 lzh lzh 18 Feb 4 19:26 dir
注意:
.目录是所在目录的硬链接..目录是上级目录的硬链接
拓展:
目录数据块中存储的数据结构
字典树
字典树(Trie)是一种用于存储字符串键的树形数据结构,其中每个节点代表一个字符。Trie特别适合于处理字符串匹配和自动完成搜索等应用,因为它可以提供高效的查找、插入和删除操作。
在Trie中,节点之间的关系表示字符的映射关系。例如,考虑以下Trie结构,它用于存储单词“apple”和“append”:
root
/
a
\
p
\
p
/ \
e l
/ /
n e
/
d
在这个Trie中,根节点代表空字符串,每个分支代表一个字符。例如,从根节点到“a”分支表示字符'a',从根节点到“ap”分支表示字符串“ap”。节点上可以附加额外的信息,例如,表示单词结束的标记。
Trie的优势在于它提供了非常高的查询效率。查找一个字符串的时间复杂度与字符串的长度成线性关系,而与Trie中存储的单词数量无关。这是因为在Trie中,只有在字符匹配的情况下才会向下遍历树,从而避免了在传统的哈希表中可能出现的冲突和大量的无效查找。
此外,Trie还可以方便地进行前缀匹配和自动完成搜索。例如,要找到所有以“ap”开头的单词,只需要从根节点沿着“a”和“p”分支向下遍历即可。
尽管Trie在查询效率上有优势,但它也有一些缺点。首先,Trie的结构比哈希表更加复杂,因此在插入和删除操作上可能不如哈希表高效。其次,Trie需要额外的空间来存储节点和连接,特别是在存储大量短单词的情况下,这可能导致Trie比哈希表占用更多的内存。
在文件系统的目录数据块中,Trie不是常用的数据结构。文件系统的目录通常使用多级索引结构(如多级目录树)来存储和管理文件和目录的路径名。这种结构通过将目录名分解为多个组件,并在每一级目录中使用索引来快速定位文件或目录。
多级索引结构(如多级目录树)
多级索引结构是一种用于组织和管理大型文件系统中的数据的数据结构。它是一种层次化的结构,其中索引层级不仅便于查找和访问数据,还可以有效地减少索引的空间占用。
在多级索引结构中,文件系统的索引分为多个层级。最底层是数据块,存储实际的文件数据。上一级是数据块的索引节点,它记录了数据块的位置和其他相关信息。再上一级是索引节点的索引节点,依此类推,直到最高级别的顶层索引节点。
利用多级索引结构,文件系统可以支持大量的数据块和文件。通过顶层索引节点,可以快速找到对应文件的数据块索引。然后通过索引节点的索引节点链依次递进,最终找到具体的数据块。
索引表可以使用多种方式实现,如平衡树(如B树、B+树)、哈希表、线性表等等。其中,平衡树是一种经常被用于实现索引节点的数据结构,它可以提供较快的查找和插入操作。
多级索引结构的优点是可以减少索引的大小,因为通过多个层级的指针引用,可以实现对大量数据块的索引。此外,它还提供了灵活性,可以生成不同层数的索引结构来适应不同大小的文件系统。
然而,多级索引结构也存在一些缺点。例如,由于需要多次访问索引节点,会增加磁盘I/O的次数,影响文件系统的性能。为了克服这个问题,一种常见的优化方法是将一部分索引节点缓存在内存中(denty缓存),以提高访问速度。
denty缓存
递归从根目录查找文件的过程是不是效率低下呢?
是的。所以在linux中有一种技术叫 dentry缓存,在Linux中,系统会对常用的目录路径和文件进行缓存(称为“dentry缓存”),所以在一次完整的文件查找过程中,可能会涉及多次的缓存访问,从而导致效率降低。
当我们在系统中搜索文件时,通常不是从根目录开始,而是从一个已打开的文件描述符(fd)或者一个特定的目录开始。然后,我们使用一个递归函数遍历目录树来查找文件。在这个过程中,如果系统能够使用dentry缓存,它会在搜索过程中存储路径和inode的映射关系,从而提高效率。
dentry缓存介绍(了解)
dentry缓存是Linux文件系统中的一种缓存机制,用于加速对文件和目录的查找操作。dentry(directory entry)是Linux内核中的目录条目,它存储了目录中的文件名和与之相关联的inode引用。dentry缓存则用于存储最近被访问的dentry对象,以便在以后的访问中重用这些对象,从而提高文件系统的性能和效率。
简单来说,dentry缓存的作用是将最经常访问的目录项(文件名和对应的inode号码)保存在缓存中,以减少重复的磁盘I/O操作,提高文件查找的速度。
dentry缓存的特点和工作原理如下:
LRU机制:dentry缓存使用最近最少使用(LRU)的替换策略来管理缓存中的对象,保留最常使用的dentry对象。(在计组中介绍)
引用计数:每个dentry对象都有一个引用计数,记录该dentry对象被目录中的文件或子目录多少次引用。当引用计数达到0时,该dentry对象将被释放。
效率提升:使用dentry缓存可以减少对底层存储介质的访问,从而提高文件查找的效率。系统可以通过在dentry缓存中查找目标dentry对象,而不是每次都从磁盘上的目录中重新加载目录项。
缓存失效:当底层文件系统的目录结构发生变化时,例如文件名或目录结构被修改、文件被创建或删除时,相关的dentry缓存会失效,系统会从磁盘重新加载更新后的目录项。
dentry缓存在Linux系统中被广泛使用,为文件系统的性能和效率提供了重要的改进。它使文件和目录的查找操作更快速、更高效,减少了对磁盘I/O的需求,提供了更好的用户体验。
系统io队列
在写入磁盘的过程,存在着内核中一个个request结构体(表示着请求内容),他们组成了不同的队列。其中IO request queue表示的系统中的io队列。为了提高写入的效率,会进行io排序。
IO请求队列可以分为以下几个队列:
IO请求等待队列(IO Request Waiting Queue):当应用程序发起IO请求时,请求会先进入等待队列,在队列中等待处理。这个队列用于暂存待处理的IO请求。
IO请求调度队列(IO Request Scheduling Queue):等待队列中的IO请求会根据调度算法被调度到调度队列中,按照一定的顺序进行排序。调度算法根据不同的策略来确定IO请求的顺序,以最大程度地提高磁盘的读写效率。常见的调度算法包括FIFO(先进先出)、SSTF(最短寻道时间优先)、SCAN(扫描算法)等。
IO请求处理队列(IO Request Processing Queue):调度队列中的IO请求会被分派给磁盘驱动程序进行处理。驱动程序负责将IO请求转换为硬件操作,并发出对应的磁盘读写指令。IO请求处理队列用于管理这些待处理的IO请求,确保它们按照顺序被正确执行。
通过对IO请求队列的管理和排序,可以减少磁盘寻道和旋转的开销,提高磁盘的读写效率,并提供更高的系统性能和响应性能。




















![2023智慧树刷课脚本 基于Python selenium的自动化刷网课程序 [有免安装发行版]](https://img-blog.csdnimg.cn/direct/3e2a30a4e8564db5bf2f64c60892a090.png)