目录
1. 补充知识
在我们正式谈线程之前,我们需要对一些知识进行补充,作为线程理解的前置性认识!
1.1. 什么叫做进程呢?
对于进程而言,我们对其的理解不能仅仅局限于将磁盘中的可执行程序加载到内存中就完事了,这种理解是非常肤浅的。因为操作系统需要管理进程,而要管理就必须先描述在组织,因此操作系统必须要有描述进程的相关内核数据结构!
而我们知道,与进程相关的内核数据结构: 进程的PCB、进程的地址空间、相关页表、CPU内部寄存器中的数据 (进程的上下文)、进程通信、进程信号等等。
进程的代码和数据通过页表进行映射,而页表又分为用户级页表、内核级页表;用户级页表每个进程都会私有一份;而内核级页表所有进程共享!
因此,我们对进程的总结就是: 进程 = 与进程强相关的内核数据结构 + 被加载到内存的数据和代码的整体集合!
1.2. 堆区的知识补充
我们需要知道,堆区看似是一个整体,但实际上堆区是被零散化的!表现上就是上层不同的指针指向堆区不同的位置!
换言之,堆空间是需要细粒度的划分的!我们还需要知道堆区内的某一个小区域是属于谁的!例如,我们需要知道,哪一块区域是第一次malloc申请的,那一块区域是第二次malloc申请的!实际上,在内核中还有一种数据结构,具体为struct vm_area_struct, vm_area_struct 是 Linux 内核中用于管理虚拟内存区域的数据结构,它定义在
<linux/mm_types.h>头文件中。
struct vm_area_struct {
struct mm_struct * vm_mm; /* The address space we belong to. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
struct rb_node vm_rb;
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
union {
struct {
struct list_head list;
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_node; /* Serialized by anon_vma->lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units, *not* PAGE_CACHE_SIZE */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
unsigned long vm_truncate_count;/* truncate_count or restart_addr */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};这个数据结构就可以描述每一次malloc申请的小空间!若干个该对象再通过链表组织起来!堆区指向该链表!如图所示:
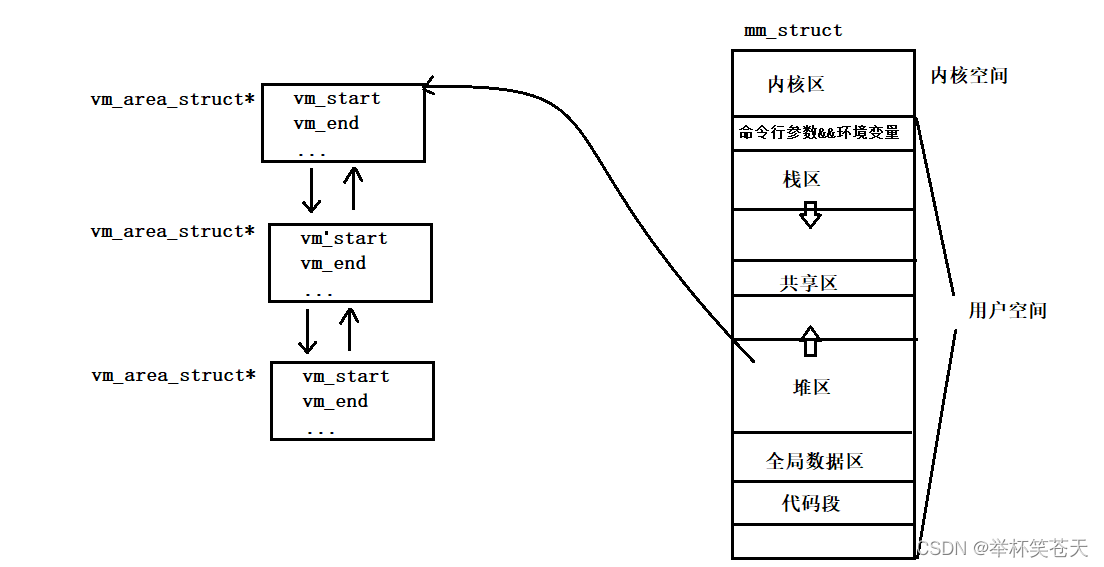
地址空间中的堆区只表明堆区整体的起始和结束! 但堆区的详细信息,我们可以用一个一个 struct vm_area_struct 节点表示!
当上层调用 malloc 申请空间时,操作系统会创建一个 vm_area_struct 对象,这里面的 vm_start 表面虚拟地址的起始位置,vm_end 表明虚拟地址的结束位置,再将这段空间经过页表映射到物理内存中,当上层访问这段 malloc 申请的空间时,操作系统检索该链表,找到特定的节点 (此时就可以根据 vm_area_struct 的特定字段得知这一段空间的起始位置和大小),就可以通过该节点经过页表映射到访问到相应的物理内存块!
从上面堆区的理解,我们可以知道操作系统是可以做到让进程进行资源的细粒度划分的。
1.3. 虚拟地址到物理地址的转化过程
我们知道,地址空间上的地址本质上就是一个虚拟地址!而我们以前的认识就是,进程要访问某段物理内存,首先就需要将地址空间的虚拟地址转化为物理地址。
可是现在有一个问题,如何将一个虚拟地址映射到物理地址呢?在了解该问题之前,我们还需要有一个前置性认识!
在以前说过,可执行程序本质上就是一个磁盘上的二进制文件,实际上,我们的可执行程序本来就是按照地址空间的方式进行编译的,并且,可执行程序按照区域已经被划分成为了以4KB伟大的那位的若干个区域! 这样的4KB区域的内容我们称之为页帧。 不仅如此,物理内存也按照4KB为单位划分若干个4KB区域 (软件层),这样的4KB区域我们称之为页框!因此,操作系统进行IO的基本单位就是4KB,本质上就是将页帧的数据填入到页框中!如图所示:

在32位机器下,假设物理内存的大小为4GB,根据上面所说,物理内存会被划分为若干个4KB区域,那么我们计算一下,会有1024 * 1024 (100w+)这样的区域! 这样的区域如此之多,操作系统需不需要知道这些区域的相关信息呢?例如哪些区域被占了,哪些区域没有被占用,换言之,操作系统需不需要管理这么多的4KB区域呢?
答案显而易见,操作系统必然要管理!那么操作系统如何管理?先描述在组织!因此在操作系统的内核当中存在着这样的数据结构,具体为 struct page, 位于
<linux/mm_types.h>头文件中,具体如下:
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
atomic_t _count; /* Usage count, see below. */
union {
atomic_t _mapcount; /* Count of ptes mapped in mms,
* to show when page is mapped
* & limit reverse map searches.
*/
struct { /* SLUB */
u16 inuse;
u16 objects;
};
};
union {
struct {
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
};
#if USE_SPLIT_PTLOCKS
spinlock_t ptl;
#endif
struct kmem_cache *slab; /* SLUB: Pointer to slab */
struct page *first_page; /* Compound tail pages */
};
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsigned long debug_flags; /* Use atomic bitops on this */
#endif
#ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/
void *shadow;
#endif
};那么如何组织呢? 我们可以用 struct page mem[100w+] 组织起来,此时对物理内存的管理就变成了对特定数据结构的增删改查!这样的区域这么多,因此必须要求 struct page 足够小! 我么也可以从上面的声明中看出,其包含了很多的联合体。 不同版本的操作系统可能实现不同,但是必须要求其非常的小,否则会占用大量的内存空间。
操作系统再通过页表进行地址转换时,发现你当前访问的内容不在内存当中,会引发缺页中断;
缺页中断:先申请好物理内存,随后在磁盘中找到你要加载的目标数据的地址并将目标内容加载到物理内存指定的位置,然后重新填充页表,最后返回到用户,让用户继续访问!
缺页中断用户是0感知的,即对用户透明化!
磁盘和物理内存的IO过程是按照4KB为单位的,这个机制是需要操作系统和编译器共同支持的!比如编译器在编译源文件的时候就应该按照地址空间的方式进行编译且需要划分为若干个4KB;操作系统在进行内存管理的时候也必须按照4KB为单位将物理内存划分为若干个区域进而管理!
有了上面的认识,我们就可以正式了解虚拟地址到物理地址的过程了。
在32位机器下,虚拟地址空间会有2^32个地址,而我们目前知道的是,操作系统会通过页表 + MMU 将虚拟地址映射到物理地址,进而间接的访问物理内存。而映射,必然会有key也要有value,我们以前也说过,页表还有会有一些标记位,如果仅仅只有一张页表。那么就需要维护2 ^ 32个映射关系, 假设一个映射关系至少需要9字节 (两个地址 + 标记为等等),而页表并非硬件,而是软件,需要保存在物理内存中,可是你现在光单纯的保存一个页表的映射关系就需要 (9 * 4GB)的空间,这显然是不现实的。实际上,操作系统的设计者考虑到了这一点,实际上,在虚拟地址转化成物理地址的整个过程中,并不是我们想象的这样简单。

通过一级页表 + 二级页表 + 前20个比特位就能锁定要访问的目标数据在物理内存中特定页的起始地址!再通过低12个比特位 (页内偏移)就能锁定特定数据的起始地址!
一级页表维护 2^10个映射关系,其中 key 就是最高的10个比特位,其 value 是相应的二级页表,而二级页表中也有 2^10个映射关系,key值是中间的10个比特位,value是特定页的起始地址,也就是说,通过一级页表 + 二级页表 我们就可以维护 1024 * 1024个特定页 (所有的页) 的起始地址,再通过低12个比特位即页内偏移锁定特定内容的起始地址!
严格意义上讲,页表并不是将虚拟地址映射到物理地址,而是将虚拟地址映射到特定页!建设的是虚拟地址到特定页的映射,找到物理内存特定页的起始地址,再根据页内偏移 (低12个比特位) 锁定特定内容的物理地址。
实际上,二级页表不一定全部开辟出来,一般只会使用少量的二级页表,因此,其存储成本大大降低。
通过这样的方案,我们就可以通过将虚拟地址转化为物理地址!这种方案的基础就是:磁盘上的可执行程序是以地址空间的方式进行编译的并且是以4KB为单位划分为若干个区域,物理内存也被操作系统划分为若干个4KB区域。
2. 线程概念
对于线程,我们首先提出一个概念: 线程在进程内部运行, 是OS调度的基本单位! 可是如何理解呢?
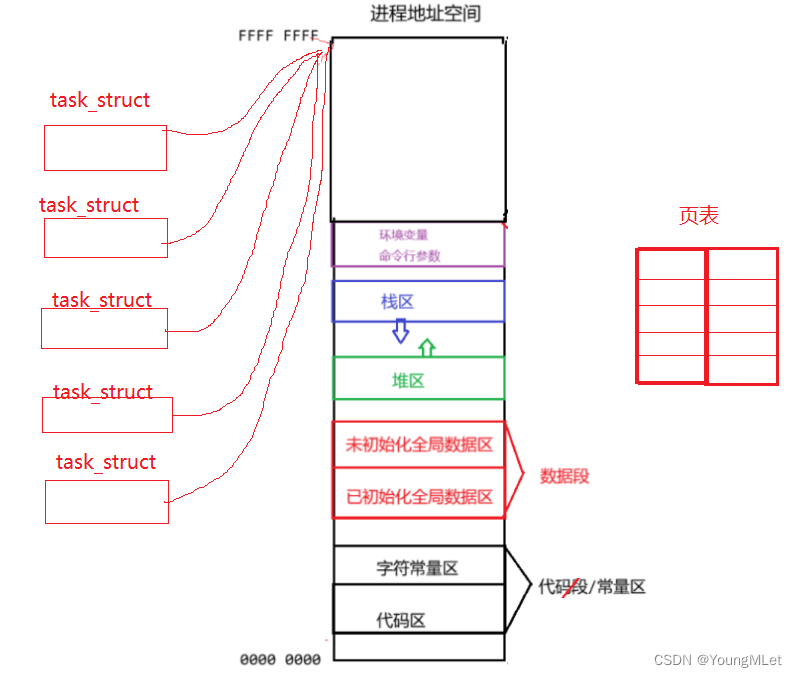
在学习进程的时候,我们是可以理解下面这张图的:

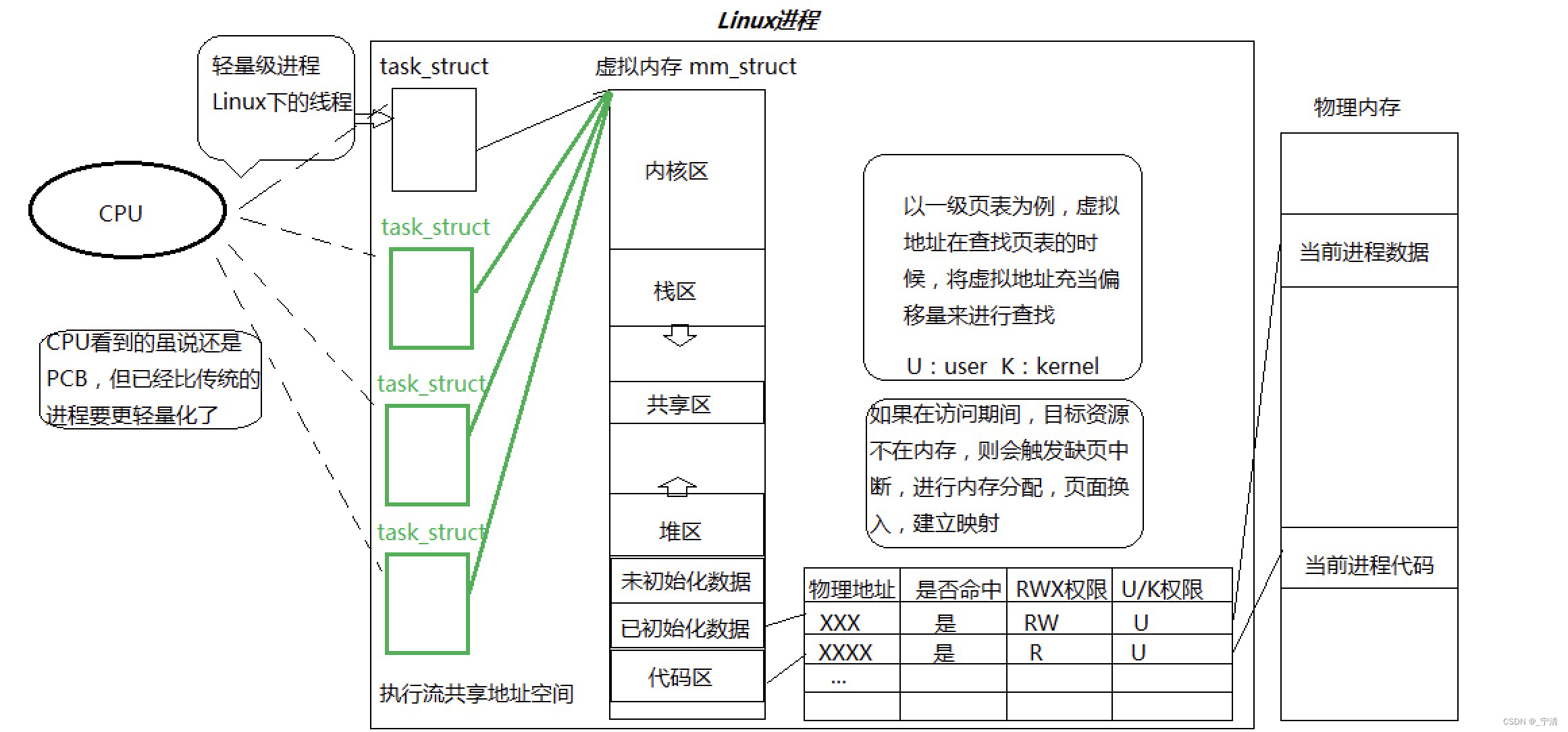
如果此时我们以 fork 创建子进程,那么操作系统就会以上面进程的内核数据结构为模板创建子进程,并将代码和数据以写实拷贝的方式共享给子进程。这个之前我们就可以理解,而今天我们提出一种新方案:当我们创建一个新执行流的时候,我们不创建新的地址空间,新的页表等等,我们只创建一个 task_struct,并让该 task_struct 指向原有的地址空间,如图所示:

现在我们就知道了,之所以说线程在进程内部运行,是因为线程在进程的地址空间内运行!之所以说线程是OS系统调度的基本单位, 是因为CPU其实不关心执行流是进程还是线程,只关心PCB。
上面这种实现方案是Linux特有的方案!
有一种执行流比进程更轻量化、细粒化,对线程的创建与释放都更轻,那么这种执行流我们就称之为线程。
不同操作系统对线程的实现方案是不同的。
Linux没有为线程设计出专门的数据结构!因此,Linux上没有真正意义上的线程。而Windows是有真正意义上的线程的。因为Windows是为线程设计了专门的数据结构的。
从上面的图我们也可以看,一个进程是可以存在多个线程的,而操作系统内可能会存在大量的进程,那么也可能会存在着大量的线程,线程如此之多,操作系统需不需要管理这些线程呢? 答案是:当然要管理。 如何管理? 先描述再组织!
因此必然要有与线程相关的数据结构!只不过这个数据结构和进程的数据结构是高度重合的的。
因此,Linux的社区工作者经过各种讨论,他们认为没有必要在为线程专门设计一种数据结构,即没有必要在内核级别区分线程或者是进程!对线程和进程都统一用 task_struct 用以表示! 只不过,进程是有自己独立的地址空间、页表等等,而线程是和进程共享地址空间、页表等等的!Linux对线程的设计方案:对进程的 task_struct 的软件复用。
Windows是真正有线程相关的内核数据结构,因此Windows对于线程和进程的处理就会更加复杂,一旦复杂,就特别容易出问题,但是也能提供更精细的控制和调度。
通过上面的分析,我们对线程有了简单的了解,可是现在有一个问题,什么叫做进程呢?
1. 站在资源角度
用户视角:内核数据结构 + 进程的代码和数据!与以前不同的是,以前只有一个PCB,而现在可能存在多个PCB。
内核视角:对于操作系统而言,来申请资源的都是进程!因此所谓的进程:承担分配系统资源的基本实体。

如何理解进程是承担分配系统资源的基本实体?
当我们只有一个执行流的时候,这些地址空间、页表等等内核数据结构是谁申请的呢?
首先,这些地址空间、页表等等内核数据结构是不是操作系统的资源呢? 答案是的。 那么这些数据结构操作系统是给谁的呢? 答案是进程。 换言之, 来申请操作系统的资源都是进程。
而后面的这些我们创建的执行流并不会再去创建新的地址空间、页表等等,而是与原进程共享这些资源,换句话说,这些线程的资源的来源是进程,因此我们说承担分配系统资源的基本实体是进程。
因此我们可以比较一下以前的进程和现在的进程:
在现在看来,我们就可以认为 task_struct 是进程内部的一个执行流!
以前的概念:内部只有一个执行流的进程。
现在的概念:内部具有多个执行流的进程!
以前的概念是现在的概念的子集!
进程 = 一大批的执行流 (至少有一个)+ 内核数据结构 + 代码和数据 (进程的上下文)。
2. 站在CPU角度
CPU在调度的时候,CPU其实不怎么关心当前是进程还是线程这样的概念,它之认task_struct,和之前的概念不冲突!
严格讲,以前只有一个 task_struct 的时候,CPU调度的并不是这个进程,而应该是调这个task_struct 结构。而这里的每一个 task_struct 我们称之为线程,故CPU调度的基本单位就是 “ 线程 ” !
在Linux下,PCB <= 其他OS内的PCB的,量级更轻,Linux下的进程:我们可以统一称之为轻量级进程 (Lightweight Process LWP)!
最后一个问题: Linux有没有真正意义上的线程呢?
答案是,没有。 因为Linux操作系统没有为线程专门设计对应的数据结构,Linux是用进程PCB (对PCB进行软件复用) 模拟线程的。
Windows 是真正存在线程结构的!是真正存在创建进程或者创建线程的系统调用接口!
但是Linux不在严格的区分线程或者进程 (在内核层面),统一称之为轻量级进程!
进程内部只有一个执行流,就对应其他操作系统的单进程;
进程内部有多个执行流,对应其他操作系统的多线程!
实际上,Linux没有真正意义上的线程,只有轻量级进程的概念 ,因此Linux操作系统并不能直接给我们提供线程相关的系统调用接口,只能提供轻量级进程的系统调用接口!
由于Linux操作系统只提供了轻量级进程的接口,但是对于用户而言,他只能分辨线程和进程,他不懂什么是轻量级进程,因此,这种方案给用户带来了不便,因此考虑到自身操作系统的生态问题,因此它必须通过某种方式为我们提供完整的线程接口!故Linux提供了一种方案:在用户层实现了一套用户层多线程方案,以库的方式提供给用户进而使用, 这个库 --- pthread 线程库!!该库我们称之为 --- 原生线程库!!! 遵守POSIX标准!
注意:该库是在用户层实现的 (通过库的形式),并不是由Linux操作系统直接提供的!
3. 见见代码
3.1. pthread_create
man 3 pthread_create
NAME
pthread_create - create a new thread
SYNOPSIS
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
RETURN VALUE
On success, pthread_create() returns 0; on error, it returns an error number, and the contents of *thread are undefined.thread: 一个指向
pthread_t类型的指针。pthread_t是一个线程的标识符,通过该参数可以存储新创建的线程的标识符。attr:一个指向
pthread_attr_t类型的指针。pthread_attr_t结构体用于指定线程的属性,比如设置线程的栈大小、调度策略等。使用默认属性时,可以将该参数设为nullptr。start_routine: 一个指向函数的指针,该函数将作为新线程的入口点,在新线程中被调用执行。该函数的返回类型是
void*,它可以接受一个void*类型的参数。你可以传递一个函数指针作为该参数来指定新线程的执行函数。arg: 一个指向任意类型的指针,用于传递给
start_routine函数的参数。你可以传递任何类型的参数,只需要将其转换为void*类型。该函数在创建新线程时有以下特点:
- 新线程的执行会从
start_routine函数开始;start_routine函数被调用时,会将arg作为参数传递给它;- 可以通过修改
attr参数来设置线程的属性,如设置线程的栈大小、线程的调度策略,但我们一般设置为nullptr。
mythrad.cc 代码如下:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#define THREAD_NUM 3
#define BUFFER_SIZE 32
void* thread_func(void* arg)
{
char* name = static_cast<char*>(arg);
while(true)
{
std::cout << name << " new thread beigin ... PID: " << getpid() << std::endl;
sleep(1);
}
delete[] name;
return nullptr;
}
void Test(void)
{
pthread_t tid[THREAD_NUM];
for(size_t i = 0; i < THREAD_NUM; ++i)
{
char* name = new char[BUFFER_SIZE];
snprintf(name, BUFFER_SIZE, "%s-%ld","thread", i + 1);
pthread_create(tid + i, nullptr, thread_func,reinterpret_cast<void*>(name));
sleep(1);
}
while(true)
{
std::cout << "main thread begin ... PID " << getpid() << std::endl;
sleep(1);
}
}
int main()
{
Test();
return 0;
}
Makefile 代码如下:
thread:mythread.cc
g++ -o $@ $^ -std=gnu++11
.PHONY:clean
clean:
rm -f thread
准备工作已经完毕,我们make,结果如下:
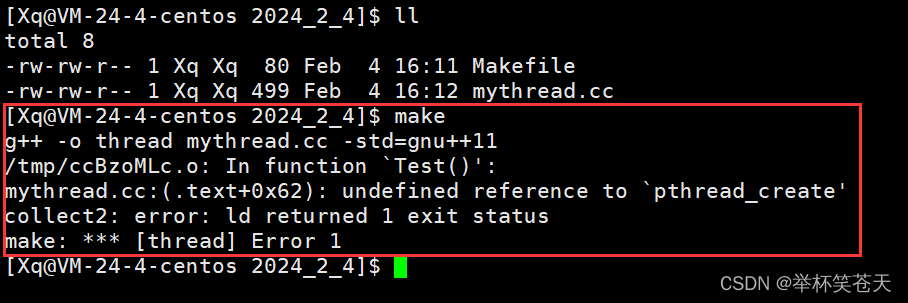
咦, 为何报错了? 还是链接错误。
由于我们所使用的pthread_create接口是由pthread库为我们提供的,而该库不属于C/C++,属于操作系统,因此用g++直接编译就会报链接错误,解决方案就是,我们需要用 -l 指明pthread库。具体如下:
thread:mythread.cc
g++ -o $@ $^ -std=gnu++11 -l pthread # 特别注意
.PHONY:clean
clean:
rm -f thread此时就能正常编译,编译结果如下:
[Xq@VM-24-4-centos 2024_2_4]$ make
g++ -o thread mythread.cc -std=gnu++11 -l pthread
[Xq@VM-24-4-centos 2024_2_4]$ ll
total 20
-rw-rw-r-- 1 Xq Xq 91 Feb 4 16:17 Makefile
-rw-rw-r-- 1 Xq Xq 499 Feb 4 16:12 mythread.cc
-rwxrwxr-x 1 Xq Xq 9208 Feb 4 16:20 thread查看该可执行程序所依赖的库:

[Xq@VM-24-4-centos 2024_2_4]$ ll /lib64/libpthread.so.0
lrwxrwxrwx 1 root root 18 Jul 25 2022 /lib64/libpthread.so.0 -> libpthread-2.17.so
[Xq@VM-24-4-centos 2024_2_4]$ ll /usr/include/pthread.h
-rw-r--r-- 1 root root 40911 May 18 2022 /usr/include/pthread.h解决好了之后,我们跑一下代码,现象如下:
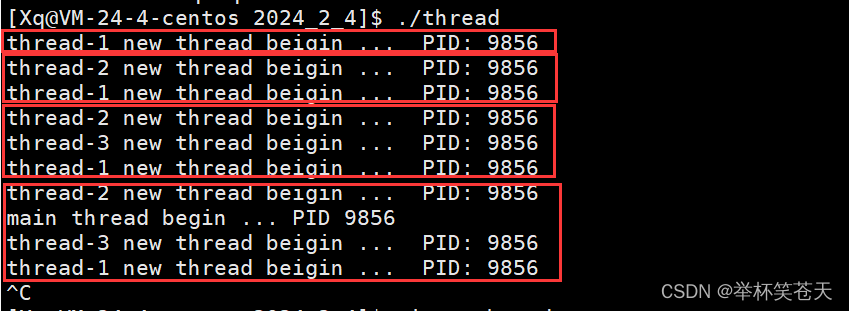
由于线程在进程内部运行!因此在一个线程内部中获取 getpid();那么所有线程获取的 PID值应该是一样的,因为线程再进程内部运行!从上面的现象我们也可以看出,如我们所想。
在多进程场景下,我们称之为父进程、子进程!
在多线程场景下,我们称之为主线程、新线程!
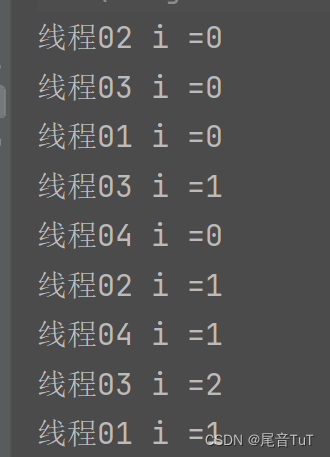
再补充一点,从上面的现象我们可以看出,打印是无序的,换言之。主线程和新线程谁先被调度是不确定的,与调度器相关。
如果我们想查看线程信息,那么可以用 ps -aL 查看。
ps是用于显示当前系统进程状态的命令;-a参数表示显示所有用户的进程,包括具有终端和无终端的进程;-L参数表示显示每个进程的线程信息。示例如下:
while :; do ps -aL | head -1 && ps -aL | grep 'thread'; sleep 1; done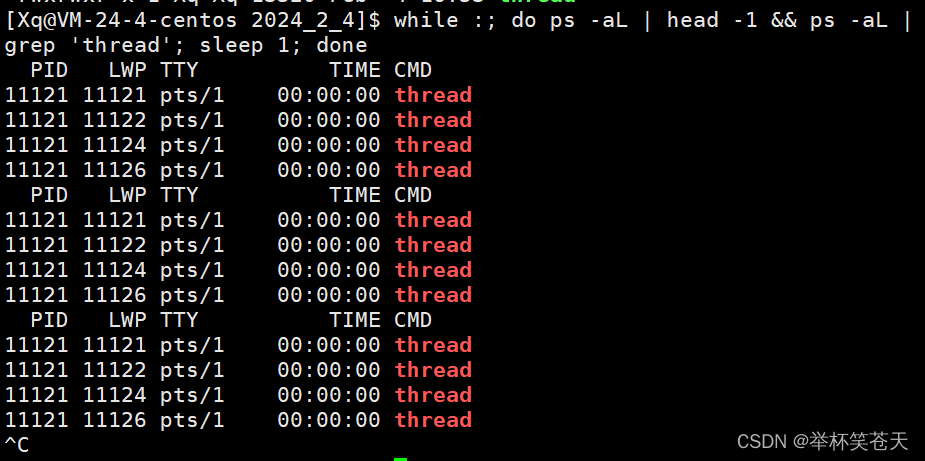
PID列代表进程的标识符,LWP列表示线程的标识符,TTY列表示进程所关联的终端,TIME列显示进程/线程的累计 CPU 时间,CMD列显示进程/线程的命令名称。PID == LWP 就是主线程! 其余的线程称之为新线程。
主线程退出,所有线程都会退出!
因为新线程的资源都是依赖于主线程的,当主线程退出后,会释放相关的资源 (内核数据结构 + 代码和数据),因此新线程所依赖的资源都没了,自然也会随之退出!
LWP这个字段位于PCB内部
执行流在被调度的时候,关注的是LWP。
进程一旦退出,那么与进程强相关的资源就会被释放,而线程是依赖于进程的资源,因此进程一旦退出,线程也会随之退出。
4. Linux进程 && 线程
进程是操作系统分配资源的基本实体。
线程是调度的基本单位。
4.1. 线程如何看待进程内部的资源
进程的大部分资源都是被线程共享的,线程会共享进程的地址空间、页表等。 在地址空间中代码段、全局数据区、堆区、共享区都是共享的,如果定义一个函数,在各线程中都可以调用。除此之外,线程还共享以下进程资源:
文件描述符表是被线程共享的。 换言之,一个线程打开了一个文件,其他线程也会看到该文件,如果一个线程打开一个文件描述符是3, 那么其他执行流再打开文件 (不关闭文件) 的文件描述符必然是4。
每种信号的处理方式是共享的。
当前工作目录是共享的。
用户id && 组id是共享的。
线程虽然可以共享进程内的一部分数据,但是线程也私有自己的一部分数据,例如下面:
1. 独立的线程ID是私有的。
2. 一组寄存器 ( CPU内置的寄存器内的数据我们称之为线程的上下文 ) 是私有的。
3. 栈是线程自己独自占用的,线程具体自己独立的栈结构。
4. errno 错误码是私有的。
5. 信号屏蔽字是私有的。
6. 调度优先级是私有的。
这两点非常重要:一组寄存器、栈 是线程的独自占用资源,寄存器中的临时数据称之为线程的上下文!这两点体现了线程的动态属性!
4.2. 进程 vs 线程
进程切换和线程切换,线程切换的成本更低。
为什么说线程切换的成本更低呢?
其一: 线程切换不需要切换PCB、地址空间、页表等数据结构。而进程切换是需要切换PCB、地址空间、页表这些数据结构的,这是第一个原因 (次要的)。这是因为在多线程编程中,多个线程共享同一个进程的地址空间和页表,它们之间的切换只需要保存和恢复寄存器中的上下文即可。而在多进程编程中,每个进程拥有独立的地址空间和页表,进程切换需要切换这些数据结构,会增加额外的开销。
首先PCB、地址空间、页表的地址 是会被Load进 CPU中的寄存器的!可是单单切换CPU中寄存器的值的成本并不高啊,实际上,进程切换比线程切换成本高的主要原因:
其二:CPU内部是有硬件级别的缓存的,这个缓存我们称之为 L1 ~ L3 cache。如果CPU读取每一条指令都要去访问内存,由于内存较于CPU相比,处理数据的能力太慢,就会限制CPU处理数据的能力,进而导致整机的效率低下!因此CPU会有缓存!对内存的代码和数据,会根据局部性原理,提前预读到CPU内部的缓存中!加载一条指令时,该指令附近的指令也会被局部性预读到CPU内部的缓存中!如果,是进程切换,由于进程具有独立性,一旦切换,此时CPU内部中的 cache 的数据就立即失效,当新进程被CPU调度时,只能重新缓存数据 (清空 + 预读),而这就是进程切换成本更高的主要原因;而线程切换并不会导致 cache 中的数据失效,也就不会导致CPU去重新缓存数据,因此线程的切换的成本更低 (主要的)。
创建线程轻量化:因为你只创建了一个PCB,其他资源都是依赖于主线程的!
删除线程也轻量化:因为它不需要释放相关执行流的数据结构,也不需要释放代码和数据。
执行过程轻量化:不切换地址空间、不切换页表、更重要的是不需要对CPU内部的缓存频繁的清空和预读 ;
4.3. 线程的优点
1. 线程更轻量级。相比于进程,线程是比较轻量级的执行单位。创建和销毁线程所需的开销较小,并且线程切换的成本相对较低,这使得线程适用于需要频繁创建和销毁执行单元的场景,并且线程之间的切换开销较小。
2. 线程占用资源少。 这很好理解,因为线程的资源依赖与进程。
3. 并发执行。 线程允许程序以并发的方式执行多个任务。多个线程可以在同一个程序中同时执行不同的操作,从而提高程序的执行效率和响应速度。
4. 计算密集型应用, 为了能在多处理器系统上运行,将计算分解到多个线程中实现。
5. IO密集型应用, 为了提高性能,就 IO 操作重叠。 线程可以同时等待不同的IO操作。
4.4. 线程的缺点
共享资源问题:由于线程共享同一个进程的内存空间和数据结构,因此多个线程之间共享相同的资源。这可能导致竞态条件(Race Condition)和死锁(Deadlock)等并发编程中常见的问题。必须仔细设计并使用同步机制(如互斥锁)来避免竞争条件和保护共享资源的一致性。
复杂的调试和测试:多线程程序的调试和测试相对复杂。由于线程的并发性和异步性,可能会出现难以重现和检测的问题,如死锁、竞态条件和数据一致性问题。调试和测试多线程程序需要特殊的技术和工具,并且需要更多的注意力和精力。
上下文切换开销:线程之间的切换需要保存和恢复线程的上下文(包括寄存器状态、栈指针等),而切换的频繁发生可能会引入一定的开销。虽然线程切换的成本较进程切换低,但过多的线程切换仍可能降低系统的性能。
复杂的并发控制:在多线程编程中,需要仔细管理和控制线程之间的并发操作。线程之间的通信和协调可能需要使用同步原语和线程间的通信机制(如信号量、条件变量等),这增加了编程的复杂性。不正确的并发控制可能导致死锁、饥饿(Starvation)和活锁(Livelock)等问题。
资源消耗:每个线程都需要分配一部分系统资源,包括栈空间、内核数据结构等。如果创建过多的线程,可能会导致资源消耗过大,甚至耗尽可用的资源。过多的线程也可能导致调度器的负担增加,降低系统性能。
4.5. 线程异常
单个线程如果出现除零、野指针问题导致线程崩溃,进程也会随之崩溃。
线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,当进程被终止,该进程内的所有线程也会随之退出。
4.6. 线程用途
并行计算:线程的一个主要用途是实现并行计算。通过将任务分解成多个子任务,并创建多个线程并发执行这些子任务,可以提高计算性能和效率。多线程的并行计算在科学计算、大规模数据处理、图像处理等领域得到广泛应用。
提高程序响应性和用户体验:使用线程可以使应用程序具有更好的响应性和用户体验。例如,将耗时的操作(如网络请求、文件读写等)放在单独的线程中执行,而不阻塞主线程,可以避免应用程序在执行这些操作时变得不响应。
多任务处理:线程使得程序能够同时执行多个任务。在图形界面应用程序中,可以使用一个线程处理用户界面的响应和更新,同时使用其他线程处理后台任务,以避免阻塞用户界面。
事件处理和回调:线程可用于处理异步事件和回调。例如,在网络编程中,可以创建一个专门的线程来处理接收到的网络消息,这样可以实现并发的网络通信。
后台服务:线程可以用于创建后台服务进程,用于执行长时间运行的任务,如定期进行数据备份、服务监控等。这些后台服务可以以独立的线程运行,不会影响到其他的前台任务。
线程池:线程池是一种管理和复用线程的机制。通过线程池,可以预先创建一组线程,并将任务提交给线程池进行处理,避免频繁创建和销毁线程的开销,提高线程的利用率。线程池常用于服务器和并发处理场景中。
5. 线程控制
5.1. pthread_join
pthread_join 函数是 POSIX 线程库(pthread) 提供的一个方法, 用于等待特定线程的结束并获取其返回值。
man 3 pthread_join
NAME
pthread_join - join with a terminated thread
SYNOPSIS
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
RETURN VALUE
On success, pthread_join() returns 0; on error, it returns an error number.thread: 即要等待的线程ID。一般都是主线程等待新线程退出并获取返回值 (如果必要的话)。
retval: 是一个二级指针 (因为 pthread_create 中的回调函数的返回值是 void*, 故这里需要用void** 的变量获取之),用于存储线程的返回值。如果不需要获取返回值,可将其设置为nullptr。
pthread_join 函数的主要目的是阻塞当前线程,直到指定的线程结束。一旦指定的线程结束,当前线程会从阻塞状态恢复,并且可以获取到指定线程的返回值。
pthread_join 函数的返回值是一个整数,用于表示函数的执行结果。如果调用成功,返回值为0;如果发生错误,它可能返回一些特定的错误代码,用于指示出现的问题。
需要注意的是,如果线程是在分离状态下创建的(通过 pthread_detach 函数设置),则调用 pthread_join 函数将返回错误。只有在线程处于非分离状态下时,才能成功地调用 pthread_join 函数等待线程的结束并获取其返回值。
5.1.1 demo
#include <iostream>
#include <pthread.h>
#include <cassert>
#include <unistd.h>
void* start_routine(void* arg)
{
char* name = static_cast<char*>(arg);
int i = 0;
for(;;)
{
std::cout << name << " running... " << std::endl;
if(++i > 3) break;
sleep(1);
}
std::cout << "new thread exit " << std::endl;
uint64_t* ptr = new uint64_t(100);
return static_cast<void*>(ptr);
}
void Test1(void)
{
pthread_t tid;
pthread_create(&tid, nullptr, start_routine, static_cast<void*>(const_cast<char*>("new thread")));
void* ret = nullptr;
pthread_join(tid, &ret);
std::cout << "wait success,main thread wait done..." << std::endl;
std::cout << "get a ret: " << *(uint64_t*)ret << std::endl;
delete (uint64_t*)ret;
while(true)
{
std::cout << "main thread running..." << std::endl;
sleep(1);
}
}
int main()
{
Test1();
return 0;
}观察现象:

通过现象,我们可以看出,主线程在调用 pthread_join 等待新线程退出的时候,会以阻塞的方式进行等待新线程退出。 并且我们也可以通过 pthread_join 的第二个参数得到新线程的退出信息 (返回值),这个退出信息没有限制 (因此用户的处理思维也不用被限制),可以是任意类型的数据,但在获取时需要进行适当的类型转换。
不过在这里补充一下,可以发现,主线程在进行等待新线程时,我们没关心线程退出的异常,我们最多是获取了线程的退出信息,那么在进行线程等待时需不需要关心线程退出的异常呢?
答案是:不需要,因为我们说过,在多线程场景下,如果某一个执行流异常崩溃了,那么所有的执行流都会崩溃,因此,在进行线程等待的时候,我们不需要关心线程退出的异常,只要它不出问题,就万事大吉了,总而言之,在进行线程等待时,我们通常不需要特别关心线程退出的异常,只要保证线程能正常退出即可。
退出信号、退出码都是以进程为载体的!
退出信号是由操作系统发送给进程,以通知其终止执行的信号。常见的退出信号包括SIGTERM(终止信号)和SIGKILL(强制终止信号)。当接收到终止信号时,进程可以选择在处理完当前任务后自行终止。
退出码是进程在终止时返回给其父进程或操作系统的值。通过这个退出码,父进程或系统可以获取进程的终止状态和执行结果。一般约定,退出码为0表示进程正常终止,非零值表示进程异常终止,可以根据具体的需求和约定来确定退出码的具体含义。
5.1.2. pthread_join的必要性
在多线程场景下,一般情况,主线程都是需要等待新线程退出的。这是为了确保所有线程都能正确执行完毕,不会出现未完成的线程导致的问题。
如果主线程不等待子线程,而是直接结束,可能会导致以下问题:
提前结束:如果主线程提前结束,而子线程还在执行,操作系统会强制终止子线程的执行,可能导致子线程的资源没有释放,从而引发内存泄漏和其他资源泄漏问题。
未完成的操作:如果主线程不等待子线程,可能会造成子线程的操作未完成。这可能导致子线程处理的数据不完整,或者因为资源未释放而导致数据一致性问题。
综上所述,主线程确实需要等待子线程执行完毕,以避免引发类似于进程的僵尸问题和资源泄漏问题。合理地管理线程的结束和资源释放是有效避免问题的关键。
5.2. 终止线程
首先,在多线程场景下,如果要终止某个新线程,不要调用 exit , 因为 exit 是终止进程的。
一般而言,在多线程场景下,如果我们想终止某个线程,一般有三种方案:
1、 在新线程的入口函数中使用 return 语句:在线程的入口函数中,通过执行 return 语句可以使线程正常终止。这是一种简单而常用的线程终止方式。
2、在新线程的入口函数中调用 pthread_exit 函数:调用 pthread_exit 函数可以使线程自行终止,并将退出信息作为参数传递给 pthread_exit 函数。这种方式允许线程在某些特定条件满足时自行终止。
3、 在主线程中调用 pthread_cancel 函数:调用 pthread_cancel 函数可以向指定的线程发送取消请求。被取消的线程可以选择在适当的时机进行清理和终止操作,以响应取消请求。
需要注意的是,使用pthread_exit或pthread_cancel终止线程时,我们需要确保线程内部进行了相应的资源清理工作,以避免资源泄漏和数据一致性问题
对于第一种方案的demo我就不演示了,在这里演示后两者方案。
5.2.1. pthread_exit 的 demo
man 3 pthread_exit
NAME
pthread_exit - terminate calling thread
SYNOPSIS
#include <pthread.h>
void pthread_exit(void *retval);
void* start_routine1(void* arg)
{
std::string* str = new std::string("haha");
int i = 0;
for(;;)
{
std::cout << static_cast<char*>(arg) << " running... " << std::endl;
if(++i > 3) break;
sleep(1);
}
pthread_exit(static_cast<void*>(str));
}
void Test2(void)
{
pthread_t tid;
pthread_create(&tid, nullptr, start_routine1, static_cast<void*>(const_cast<char*>("new thread")));
void* ret = nullptr;
pthread_join(tid, &ret);
std::cout << "wait success, get a ret: " << (static_cast<std::string*>(ret))->c_str() << std::endl;
delete (static_cast<std::string*>(ret));
ret = nullptr;
while(true)
{
std::cout << "main thread exit" << std::endl;
sleep(1);
}
}
现象如下:

可以看到,pthread_exit 可以将某个线程终止,并且可以将该线程的退出信息作为参数传递给 pthread_exit 并返回。
5.2.2. pthread_cancel 的 demo
man 3 pthread_cancel
NAME
pthread_cancel - send a cancellation request to a thread
SYNOPSIS
#include <pthread.h>
int pthread_cancel(pthread_t thread);
RETURN VALUE
On success, pthread_cancel() returns 0; on error, it returns a nonzero error number.void* start_routine2(void* arg)
{
for(;;)
{
std::cout << static_cast<char*>(arg) << " running... " << std::endl;
sleep(1);
}
return nullptr;
}
void Test3(void)
{
pthread_t tid;
pthread_create(&tid, nullptr, start_routine2, static_cast<void*>(const_cast<char*>("new thread")));
int i = 5;
while(i--)
{
std::cout << "i: " << i << std::endl;
sleep(1);
}
pthread_cancel(tid);
void* ret = nullptr;
pthread_join(tid, &ret);
// #define PTHREAD_CANCELED ((void*)-1)
std::cout << "get a ret: " << reinterpret_cast<long long>(ret) << std::endl;
while(true)
{
std::cout << "main thread running... " << std::endl;
sleep(1);
}
}
现象如下:

第一个现象: 我们发现,当一个线程被取消了,那么该线程的返回值自动被 pthread 线程库设置为 -1, 而这个 -1 本质上是 PTHREAD_CANCELED,具体如下:
#define PTHREAD_CANCELED ((void *) -1)第二,当用户使用 pthread_cancel 取消某个线程的时候,用户应该要保证该线程是存在的且该线程已经在运行了! 此时我们在通过主线程调用 pthread_cancel 取消某个新线程,因此, 用户在使用 pthread_cancel 的时候要根据场景判定是否合适。
第三,对于 pthread_cancel 而言,一般情况下,用户都应该用主线程取消某一个线程, 而最好不要用新线程取消主线。
在多线程编程中,主线程通常是整个程序的核心,并且扮演着重要的角色。因此,使用新线程来取消主线程可能会导致不可预测的结果和程序的异常终止。
总之,为了确保线程的管理和程序的稳定性,推荐在多线程编程中使用主线程来取消其他线程,并遵循相应的线程管理机制。
5.3. 线程ID的探索
首先我们看看这个线程ID的类型,pthread_t 的声明在 pthreadtypes.h 头文件中。具体如下:
typedef unsigned long int pthread_t;接下来,我们创建一个线程,并打印它的 id :
void* start_routine4(void* arg)
{
std::cout << static_cast<char*>(arg) << " running... "<< std::endl;
sleep(1000);
return nullptr;
}
void Test5(void)
{
pthread_t tid;
pthread_create(&tid, nullptr, start_routine4, static_cast<void*>(const_cast<char*>("new thread")));
usleep(100);
printf("tid: %ld, %p\n", tid, tid);
pthread_join(tid, nullptr);
}现象如下:

可以看到,这个线程id值是一个非常大的值,事实上,这个线程id 本质是一个地址,共享区的地址!在之前我们说过,每一个线程都要有自己的独立栈结构,那么如何保证这一点呢?难道说我们把地址空间的栈 (操作系统提供的栈结构) 也给拆分了? 那么操作系统是不是就会感知到了线程的存在呢?而我们说过,Linux操作系统是没有线程的概念的,只有轻量级进程的概念,因此实际上新线程的栈结构就不能在操作系统层面体现,而应该在用户层体现,即需要由用户层 (线程库) 为新线程提供独立栈结构!如图所示:

从上图可以看出,线程属性集合的起始地址就充当着新线程的ID。因此线程ID本质上就是一个地址,其代表的是特定线程在线程库内部的相关属性集合的起始地址!
主线程用的是内核级提供的栈结构 (地址空间的栈结构);
新线程用的是共享区 (线程库)提 供的私有栈结构!
因此我们可以保证每一个线程都具有自己的独立栈结构!并且不和我们的单执行流的进程的概念冲突!
至于库是如何做到这一点的,我们不用担心,因为 Linux 已经提供了类似于 clone 这样的系统调用接口,用于创建轻量级进程并提供独立栈结构。这些接口允许库在内核级别处理线程的创建和管理,并确保线程之间具有独立的栈空间。
5.4. pthread_self
man 3 pthread_self
NAME
pthread_self - obtain ID of the calling thread
SYNOPSIS
#include <pthread.h>
phtread_t pthread_self(void);
RETURN VALUE
This function always succeeds, returning the calling thread's ID.该函数不接收任何参数,并返回 pthread_t 类型的线程ID,表示当前线程的标识符。
5.5. 证明全局数据是被所有线程共享的
思路: 创建新线程,定义一个全局变量,主\新线程任意一个线程修改全局变量,那么另一个线程也会看到这个被修改的全局数据!demo如下:
size_t g_val = 1;
void* start_routine5(void* arg)
{
while(true)
{
std::cout << static_cast<char*>(arg) << " running g_val: " << (int)g_val << " &g_val: " << &g_val << std::endl;
g_val++;
sleep(1);
}
return nullptr;
}
void Test6(void)
{
pthread_t tid;
pthread_create(&tid, nullptr, start_routine5, static_cast<void*>(const_cast<char*>("new thread")));
for(;;)
{
std::cout << "main thread running " << "g_val: " << (int)g_val << " &g_val: " << &g_val << std::endl;
sleep(1);
}
pthread_join(tid, nullptr);
}测试现象:
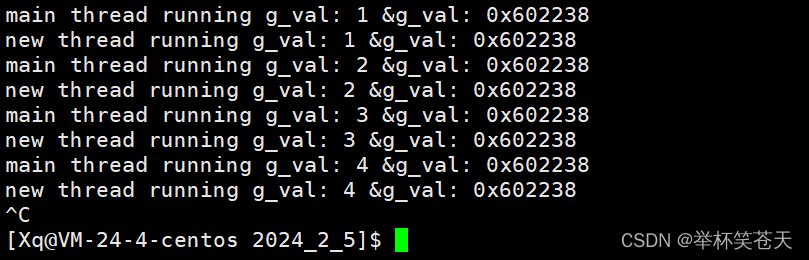
如我们预期的一样,任意一个线程对某个全局变量做修改,那么其他的线程也可以看到这个被修改的全局变量,换言之,全局数据是被所有线程共享的。
如果我们想让这个全局变量成为某个线程私有的,那么我们可以用 __thread 修饰这个全局变量,而这个全局变量也就是线程的局部存储,demo如下:
__thread size_t g_val = 1; // 注意这里是两个_
void* start_routine5(void* arg)
{
while(true)
{
std::cout << static_cast<char*>(arg) << " running g_val: " << (int)g_val << " &g_val: " << &g_val << std::endl;
g_val++;
sleep(1);
}
return nullptr;
}
void Test6(void)
{
pthread_t tid;
pthread_create(&tid, nullptr, start_routine5, static_cast<void*>(const_cast<char*>("new thread")));
for(;;)
{
std::cout << "main thread running " << "g_val: " << (int)g_val << " &g_val: " << &g_val << std::endl;
sleep(1);
}
pthread_join(tid, nullptr);
}
测试现象如下:

__thread 修饰的全局变量带来的结果就是让每一个线程各自拥有一个全局变量,这个全局变量称之为线程的局部存储!
最后,再补充一点,在多线程场景下,一旦某个线程进行了进程的程序替换 ( exec* ),就相当于进程进行了进程的程序替换,那么此时除了主线程之外,其他所有的新线程都会被终止,终止以后,再去执行程序替换。
那么,如果是 fork 呢? ,只要某一个线程调用了 fork 。那么此时会以主线程为主创建子进程!
5.6. 分离线程
man 3 pthread_detach
NAME
pthread_detach - detach a thread
SYNOPSIS
#include <pthread.h>
int pthread_detach(pthread_t thread);
RETURN VALUE
On success, pthread_detach() returns 0; on error, it returns an error number.默认情况下,新创建的线程都是 joinable 的,线程退出后,需要主线程对其进行 pthread_join。
那么当新线程退出的时候,如果我不想等待该线程,也不想获取该线程的退出信息,那么我们可以调用 pthread_detach,该函数用于将线程设置为 "可分离(detached)"状态。可分离状态的线程在结束时会自动释放其资源,而不需要其他线程调用 pthread_join 来获取线程的返回值或等待线程终止。
注意事项:
1、 必须在线程创建 (pthread_create) 之后且在线程终止 (pthread_exit 或线程函数返回)之前调用 pthread_detach。
2、 一旦线程被设置为可分离状态,就不能再被设置为可连接(joinable)状态了。
3、 可分离状态的线程的资源会在线程终止时自动被操作系统回收,无需其他线程调用 pthread_join 进行处理。
pthread_detach 函数只设置线程的状态,不会等待线程终止。如果需要等待线程终止并获取其返回值,应该使用 pthread_join 函数。
一般情况下,可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离;
joinable 和 detached 是两态的, 一个线程不能既是 joinable 又是 detach的。
1、可连接状态(joinable):一个可连接状态的线程在终止时会保留其终止状态,直到其他线程调用 pthread_join 函数来获取该线程的返回值和释放其资源。在线程创建时,默认是可连接状态。
2、可分离状态(detached):一个可分离状态的线程在终止时会立即释放其资源,无需其他线程调用 pthread_join 来获取返回值或等待线程终止。
那么如果当某个线程被分离了 (处于 detached 状态),此时再用 pthread_join 对其等待会发生什么呢? demo如下:
void* start_routine6(void* arg)
{
pthread_detach(pthread_self());// 自己分离自己
return nullptr;
}
void Test7(void)
{
pthread_t tid;
pthread_create(&tid, nullptr, start_routine6, static_cast<void*>(const_cast<char*>("new thread")));
sleep(1); // 确保线程分离后,在进行join
int n = pthread_join(tid, nullptr);
printf("n = %d, exit message: %s\n", n, strerror(n));
}现象如下:

现象是,pthread_join 错误,退出码是22 。
最后,在提出一个问题,如果一个线程分离了,但又出现异常了,会有什么影响吗?
答案:当然会,因为即使该线程被分离了,但它依旧是创建它的线程的一部分,依旧共享着进程资源,因此,如果此时异常,可能会导致进程崩溃或产生其他未定义行为,尤其是在主线程中。
总结:在多线程场景下,主线程退出,就意味着进程退出! 一旦进程退出,此时进程内所有的执行流都会退出,无论其他执行流此时正在干什么!
因为我们要保证,进程退出,就是真正的退出了,线程作为进程的一部分,自然而然也会退出!这是操作系统和线程库必须满足的!
因此无论是多进程亦或者是多线程场景,我们最好是保证父进程或者主线程最后退出!主线程或父进程通常需要负责管理和回收子线程或子进程的资源。主线程或父进程通常会首先等待其他线程或子进程完成工作,然后进行清理和资源回收,最后自己退出。
在多线程和多进程的场景中,正确的管理和回收资源非常重要,以确保程序的稳定性和正确性。父进程负责管理子进程,主线程负责管理其他线程。通过合理的资源管理和清理,可以避免资源泄露和不一致的状态。