数据表供大家练习
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`name` varchar(50) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
`age` int(0) NULL DEFAULT NULL,
`job` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '职位',
`salary` int(0) NULL DEFAULT NULL,
`entrydate` date NULL DEFAULT NULL COMMENT '入职时间',
`managerid` int(0) NULL DEFAULT NULL COMMENT '直属领导id',
`dept_id` int(0) NULL DEFAULT NULL COMMENT '所在部门id',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 17 CHARACTER SET = utf8 COLLATE = utf8_bin COMMENT = '员工表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of emp
-- ----------------------------
INSERT INTO `emp` VALUES (1, ' 金庸', 66, '总裁', 20000, '2000-01-01', NULL, 5);
INSERT INTO `emp` VALUES (2, '张无忌', 20, '项目经理', 12500, '2005-12-05', 1, 1);
INSERT INTO `emp` VALUES (3, '杨晓', 33, '开发', 8400, '2000-11-03', 2, 1);
INSERT INTO `emp` VALUES (4, ' 韦一笑', 48, '开发', 11000, '2002-02-05', 2, 1);
INSERT INTO `emp` VALUES (5, '陈玉存', 43, '开发', 10500, '2004-09-07', 3, 1);
INSERT INTO `emp` VALUES (6, '小昭', 19, '程序员鼓励师', 6600, '2004-10-12', 2, 1);
INSERT INTO `emp` VALUES (7, '灭绝', 60, '财务总监', 8500, '2002-09-12', 1, 3);
INSERT INTO `emp` VALUES (8, '周芷若', 19, '会计', 48000, '2006-06-02', 7, 3);
INSERT INTO `emp` VALUES (9, '丁敏君', 23, '出纳', 5250, '2009-05-13', 7, 3);
INSERT INTO `emp` VALUES (10, '赵敏', 20, '市场部总监', 12500, '2004-10-12', 1, 2);
INSERT INTO `emp` VALUES (11, '鹿杖客', 56, '职员', 3750, '2006-10-03', 10, 2);
INSERT INTO `emp` VALUES (12, '何碧文', 19, '职员', 3750, '2007-05-09', 10, 2);
INSERT INTO `emp` VALUES (13, '东方白', 19, '职员', 5500, '2009-02-12', 10, 2);
INSERT INTO `emp` VALUES (14, '张三丰', 88, '销售总监', 14000, '2004-10-12', 1, 4);
INSERT INTO `emp` VALUES (15, '鱼梁洲', 38, '销售', 4600, '2004-10-12', 14, 4);
INSERT INTO `emp` VALUES (16, '宋远桥', 40, '销售', 4600, '2004-10-12', 14, 4);
SET FOREIGN_KEY_CHECKS = 1;一、单表查询
|
1、排序
- 单列排序
- asc升序(默认,可不写),desc降序
- 语法格式:
SELECT 字段名 FROM 表名 [WHERE 字段 = 值] ORDER BY 字段名 [ASC / DESC]
- 组合排序
- 同时对多个字段进行排序, 如果第一个字段相同就按照第二个字段进行排序,以此类推。
- 比如order by 字段1,字段2 desc—代表先按照字段1升序,再按字段2降序。
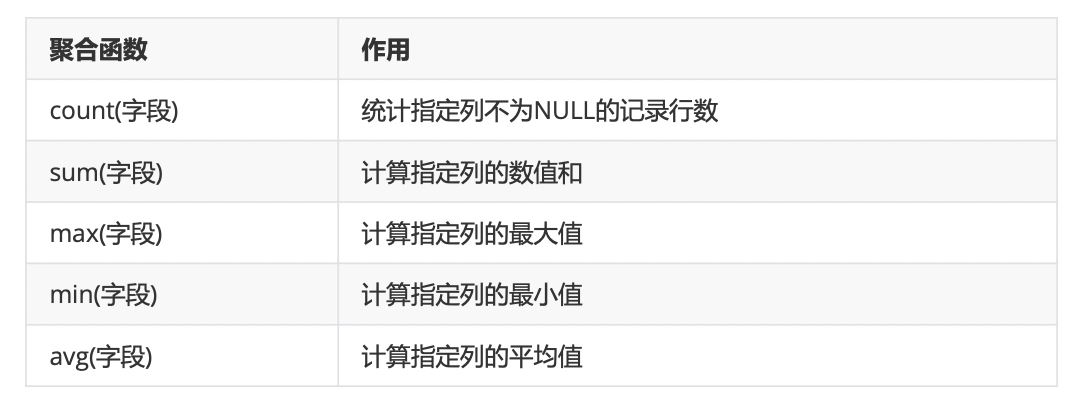
2、聚合函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
count(1)count(*)count(列名)的区别: count(1)和count(*)统计所有条数,包括null值; count(列名)统计所有不为null的条数。
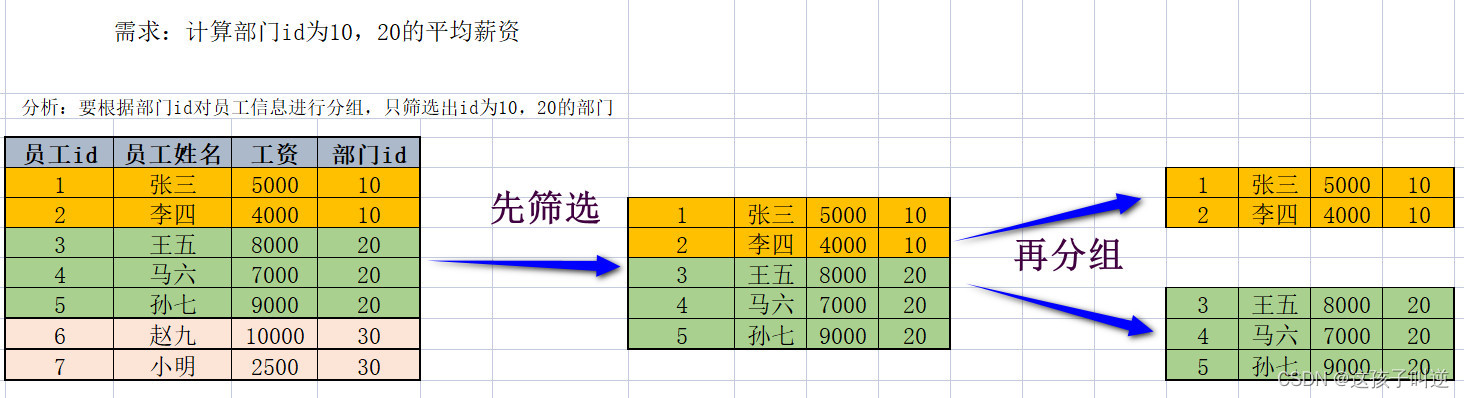
3、分组
分组往往和聚合函数一起使用,对数据进行分组,分完组之后在各个组内进行聚合统计分析。 语法格式:
1 |
|
代码示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
having的用法:
1 2 3 4 5 6 7 8 9 |
|
where 与 having 的区别:
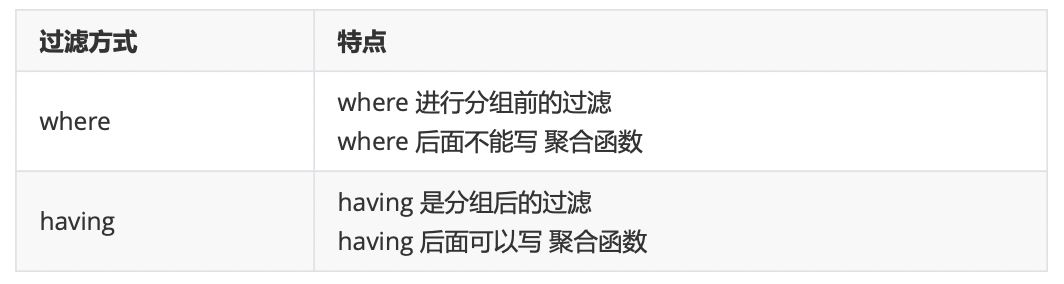
having要放在where和分组之后
4、limit
语法格式:
1 |
|
参数说明: offset起始行数,从0开始记数,如果省略则默认为0。 length返回的行数。
1 2 3 4 5 6 |
|
二、SQL约束
约束的作用: 对表中的数据进行进一步的限制,从而保证数据的正确性、有效性、完整性。 违反约束的不正确数据将无法插入到表中。注意:约束是针对字段的。
一般数据分析师对数据只是查询,基本没有创建修改表的权限,所以这块大家了解就好,不用纠结语法怎么写。在表结构中见到以下约束关键字,知道是对数据的约束就行了。

常见的四种约束
1、主键约束
特点:不可重复、唯一、非空
创建主键
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
增加主键
1 2 |
|
2、非空约束
3、唯一约束
4、外键约束
主键:数据表A中有一列,这一列可以唯一的标识一条记录。 外键:数据表A中有一列,这一列指向了另外一张数据表B的主键。
5、默认值
1 2 3 4 5 6 |
|
三、多表查询
数据分析师在实际工作中提取数据,不可能在一张表中就能把所有想要的数据都取到,而是关联多张表,从不同的表中拿到不同的目标数据,这就需要掌握表和表连接的知识了。这块非常重要!!!
1、内连接
**特点:**通过指定的条件去匹配两张表中的数据,匹配上就显示,匹配不上就不显示。
1)隐式内连接:
1 |
|
示例代码:
1 2 3 4 5 6 |
|
2)显式内连接:
1 2 |
|
示例代码:
1 2 3 |
|
2、外连接
1)左外连接
特点: 以左表为基准,匹配右边表中的数据,如果匹配的上就展示匹配到的数据; 如果匹配不到,左表中的数据正常展示,右边的展示为null。
语法格式:
1 |
|
示例代码:
1 2 3 4 |
|
2)右外连接
特点: 以右表为基准,匹配左边表中的数据,如果匹配的上就展示匹配到的数据; 如果匹配不到,右表中的数据正常展示,左边的展示为null。
语法格式:
1 |
|
示例代码:
1 2 3 4 |
|
各种连接方式的总结:
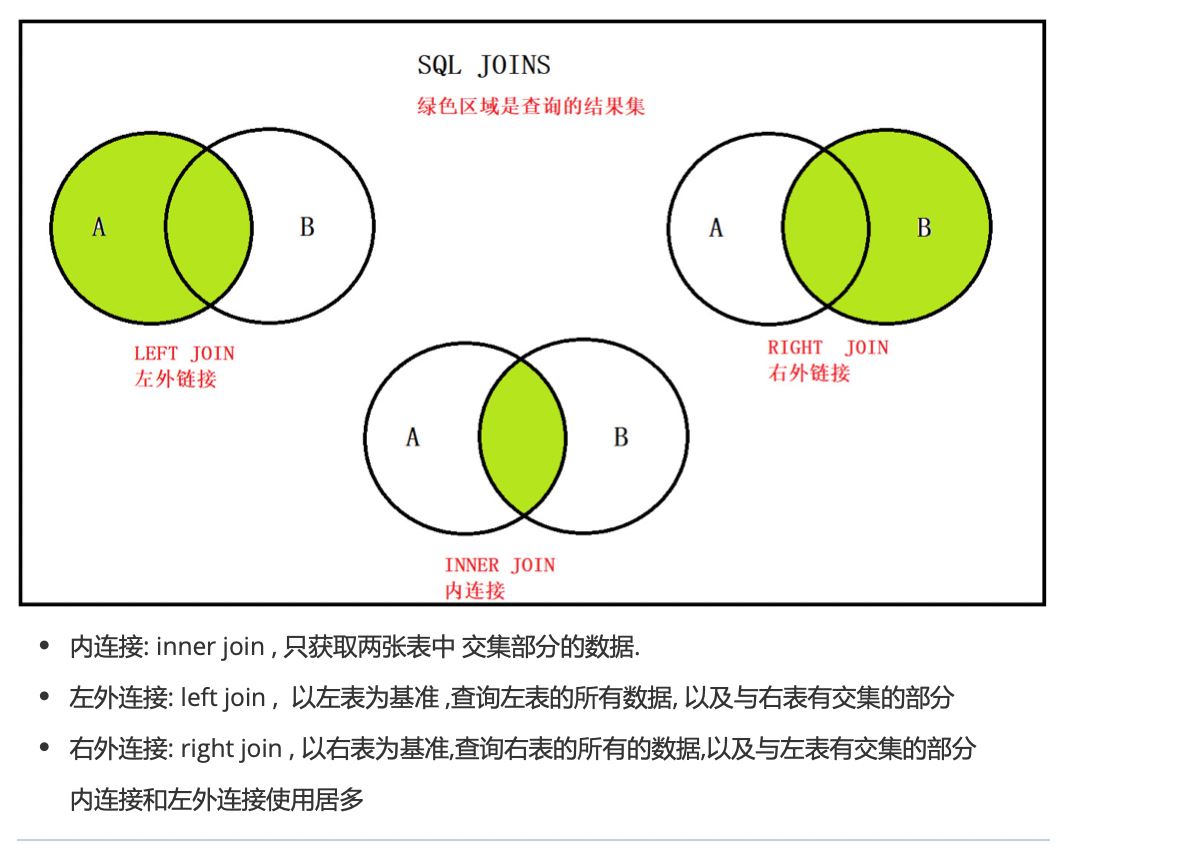
四、合并查询
1、UNION
UNION 操作符用于合并两个或多个SELECT语句的结果集,并消除重复行。 注意,UNION内部的SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。 同时,每条 SELECT 语句中的列的顺序必须相同。
代码示例:
1 2 3 4 5 6 7 |
|
注意:
1. 选择的列数必须相同;
2. 所选列的数据类型必须在相同的数据类型组中(如数字或字符);
3. 列的名称不必相同;
4. 在重复检查期间,NULL值不会被忽略;
2、UNION ALL
UNION ALL 运算符用于将两个 SELECT 语句的结果组合在一起,重复行也包含在内。 UNION ALL 运算符所遵从的规则与UNION一致。
总结: UNION和UNION ALL关键字都是将两个结果集合并为一个,也有区别。
1、重复值:UNION在进行表连接后会筛选掉重复的记录,而UNION All不会去除重复记录。
2、UNION ALL只是简单的将两个结果合并后就返回。
3、在执行效率上,UNION ALL 要比UNION快很多。因此,若可以确认合并的两个结果集中不 包含重复数据,那么就使用UNION ALL。
五、子查询
定义:一条select 查询语句的结果, 作为另一条select语句的一部分。
1、where型:
子查询的结果作为查询条件
1 |
|
代码示例:
1 2 |
|
2、from型:
将子查询的结果作为一张表
1 |
|
代码示例:
1 2 3 4 5 6 7 8 9 |
|
3、exists型:
子查询结果是单列多行
1 |
|
代码示例:
1 2 3 4 |
|
总结:
1. 子查询如果查出的是一个字段(单列),那就在where后面作为条件使用。 单列单行 = 单列多行 in
2. 子查询如果查询出的是多个字段(多列),就当做一张表使用(要起别名)。
六、MySQL函数
函数常用的就这些了,不用硬记,不会的百度查就行了,写着写着就记住了。
1、数学函数
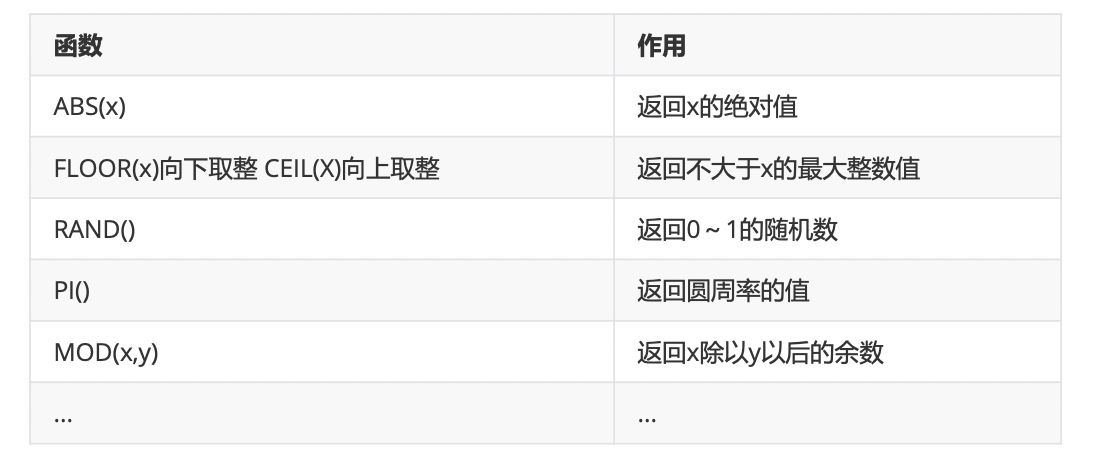
2、字符串函数
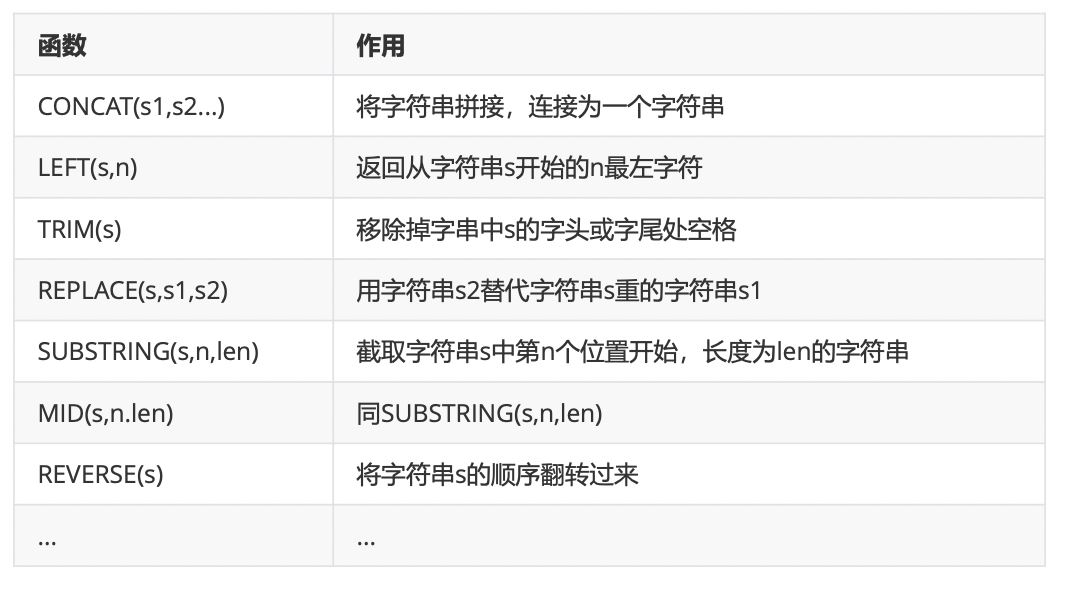
3、日期和时间函数(必学)
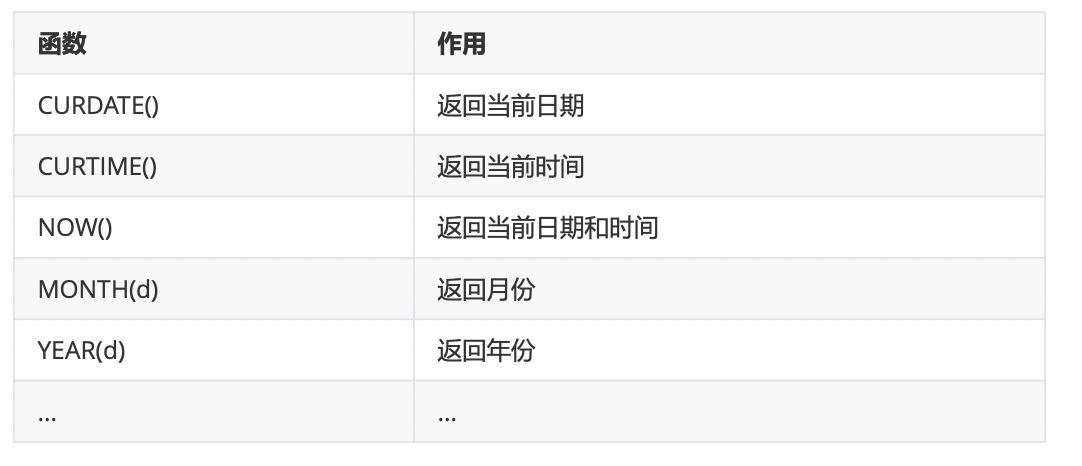
4、条件判断函数(这个必须掌握!!!)
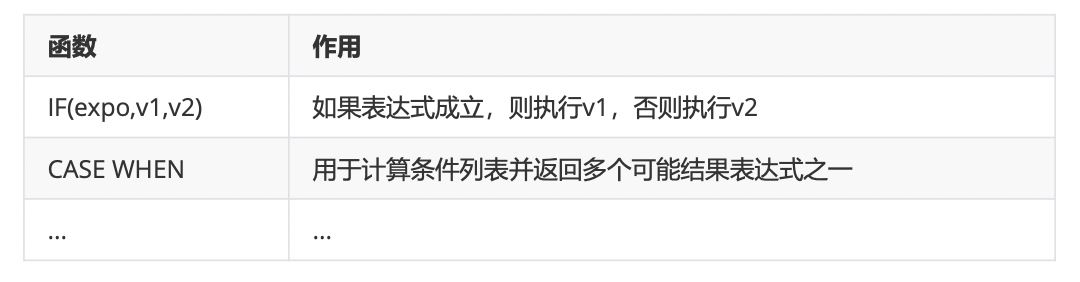
5、系统信息函数(可忽略)

到此MySQL的核心查询语句详解的文章就介绍到这了,更多相关MySQL的核心查询内容可访问主页查看,希望对大家有帮助!!!