MySQL知识点总结(三)——事务
事务
事务是保证一批SQL同时成功或同时失败的一种机制,是保证一致性的一种手段。
事务的四大特性ACID
- A:原子性
- C:一致性
- I:隔离性
- D:持久性

原子性
事务的原子性是指事务是一个原子性的操作,必须保证同一个事务里面的这一批SQL同时成功或同时失败,不可以某些成功某些失败。
一致性
这个要表达清楚还真不容易,往往需要举例。事务的一致性,是指事务在提交之前,和提交之后,事务涉及到的所有修改的表记录,它们的状态的变化是保持一致。比如银行转账。。。。(还是不说了,这例子都被举烂掉了)

隔离性
事务的隔离性是指两个事务之间互不影响,互不干扰。
持久性
事务的持久性是指事务一旦提交,涉及的修改是持久生效的。
脏读、幻读、不可重复读
这是事务可能会发生的三大问题。

脏读
当前事务读取到了另一个事务还没有提交的修改,如果另一个事务把这个修改回滚了,那么就相当于是读到了脏数据。
不可重复读
当前事务对同一行数据的读取,前后两次读到了不同的结果。出现这种情况,一般是隔离级别设的不够高,其他事务对该行数据做了修改后提交了,当前事务再次读取,就是修改后的值,因此出现了前后两次读到的值不一致。
幻读
当前事务前后两次读取,读到的记录数不一致,比如前面读到了9条,后面再次读取读到了10条,多出了一条,这就好像出现了幻觉。出现这种情况,一般是其他事务在当前事务第一次读取后,在读取范围内新增了数据,导致当前事务第二次读取时读到了其他事务新增的数据。
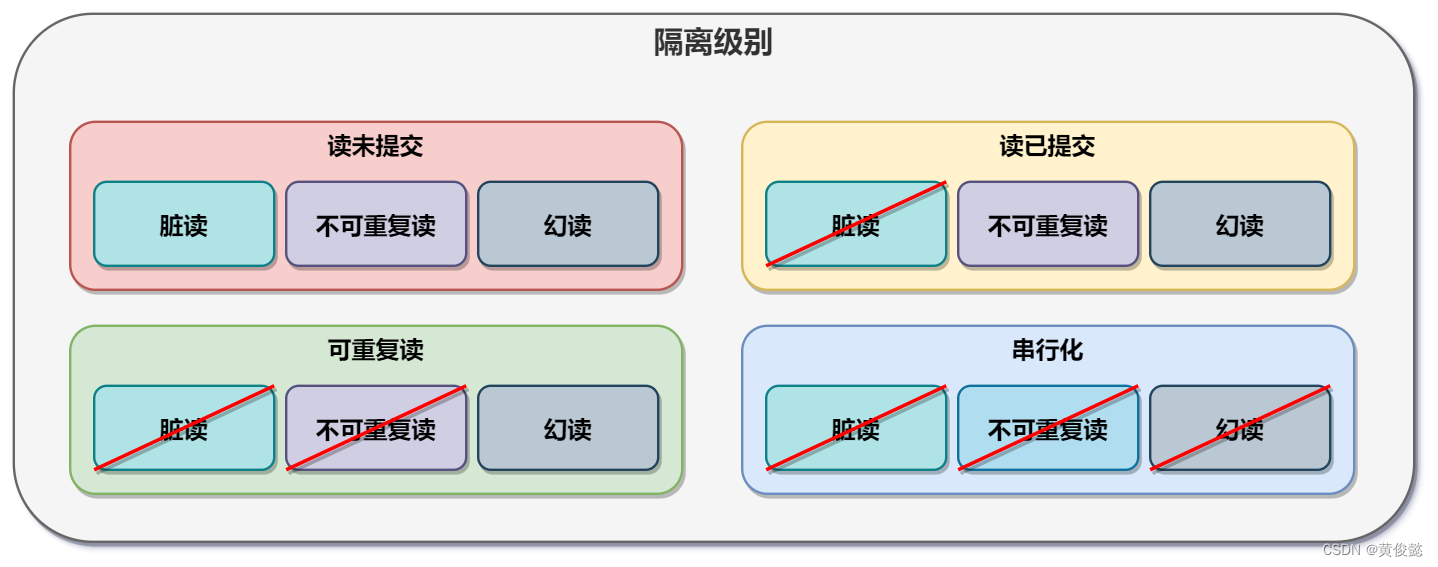
隔离级别
- 读未提交
- 读已提交
- 可重复读
- 串行化
读未提交
当前事务可以读到其他事务还没有提交的修改。这种隔离级别是最低的,无法防止脏读、不可重复读和幻读。
读已提交
当前事务只能读取到其他事务已经提交的修改,其他事务没有提交的修改则不能被当前事务读取到。这是大多数数据库默认的隔离级别,但是MySQL并没有把它作为默认的隔离级别。这种隔离级别下可以防止脏读,但是无法防止不可重复读和幻读。
可重复读
比读已提交更严格的隔离级别,是MySQL默认的隔离级别。在这种隔离级别下,可以保证一个事务内,对同一条记录的读取,总是能读到相同的结果。可以防止脏读和不可重复读,但是还是有可能出现幻读。
串行化
最严格的隔离级别,一般很少会使用,隔离性最高,但是性能最低。在这种隔离级别下,可以认为事务是一个个串行执行的(读读可以并行),事务的读取会加读锁,修改会加写锁。这种隔离级别可以防止脏读、幻读、不可重复读。
事务的原理
InnoDB如何实现事务的ACID
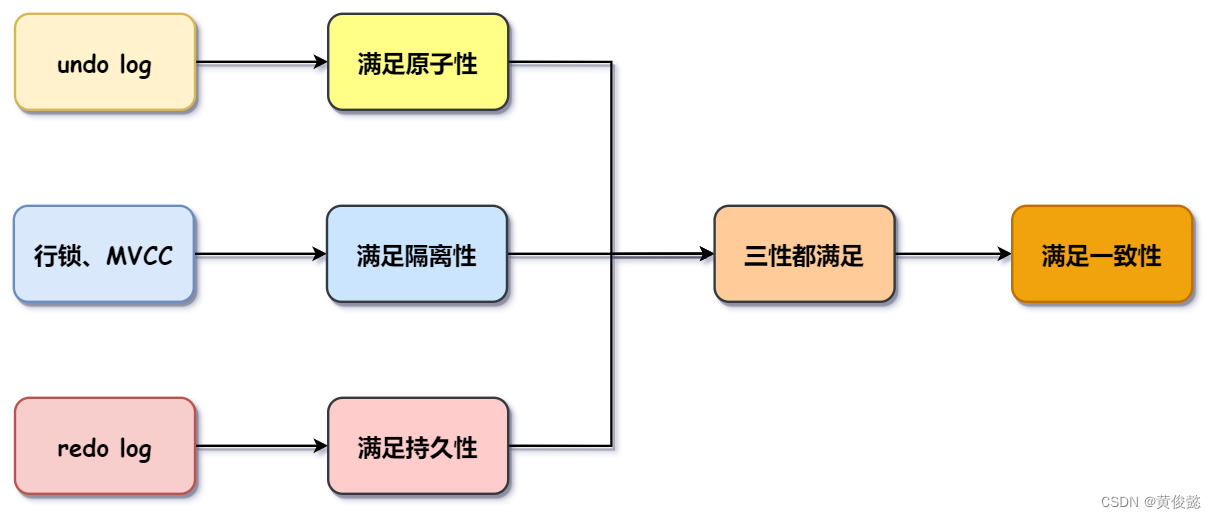
事务的原子性,通过undo log实现,undo log可以理解为数据库表行记录的历史版本,每次事务对库表的行记录进行修改时,都会先记录它的历史版本到undo log中,如果该事务回滚了,那么就从undo log中读取行记录的历史版本,把它还原回去。
事务的隔离性通过锁和MVCC(多版本并发控制)保证。如果一个事务对一行或多行加了锁,其他事务自然是无法对它们进行修改,也就达到了隔离效果,只是加锁这种隔离手段代价太高了,会阻塞其他事务的执行。于是就有了MVCC,MVCC是多版本并发控制,简单理解就是一个行记录可以同时存在多个版本,那么不同事务间读写同一个行记录的不同的版本,自然可以互不影响。
事务的持久性是通过redo log实现的,redo log是一种WAL(预写日志)机制,一个事务提交了对库表行记录的修改,InnoDB并不会马上持久化到磁盘的索引页中,因为磁盘中的索引页读写是随机读写,性能是极低的,InnoDB会通过redo log记录“某索引页,某个位置,要修改成某某值”之类的日志,把它持久化到磁盘,假设MySQL宕机了,重启之后也可以利用redo log恢复,这样就不会发生更新丢失,这就是redo log的作用,而redo log在磁盘中是顺序写的,性能是极高的,这样就满足了持久性的同时又保证了性能。
而一致性,是最终目的,满足了原子性、隔离性和持久性,才能满足一致性。
事务的两阶段提交
redo log与binlog的区别
除了redo log、undo log以外,MySQL还有一个binlog。binlog与redo log的功能看似很相似,实际上并不一样。
redo log是InnoDB存储引擎独有的,binlog是属于MySQL服务端的,是所有存储引擎共享的。
redo log记录的是索引页的修改,是用于崩溃恢复的,比如有一个事务提交了,修改记录到redo log中,但是没有持久化到磁盘索引页,此时MySQL宕机了,当我们重启MySQL后,InnoDB就会自动使用redo log去恢复索引页,把更新持久化到索引页中。而binlog日志记录的是事务提交的SQL本身,是用于备份和主从同步到,当然遇到删库跑路的场景,也可以用它来恢复到某个时间点。
因此当一个事务提交时,需要保证redo log和binlog的一致性。
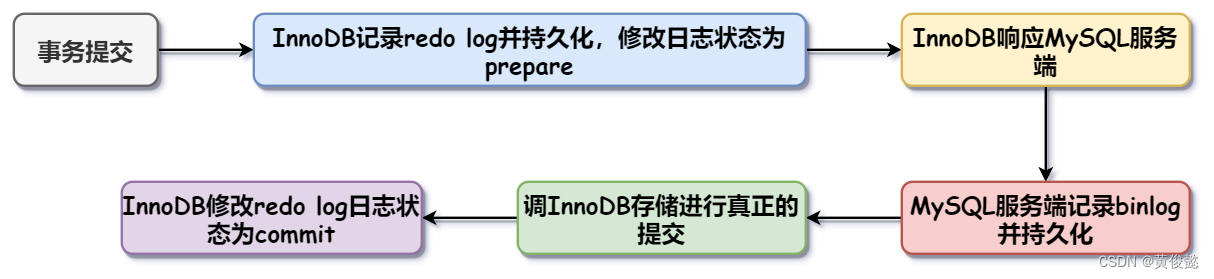
事务两阶段提交流程
当一个事务要提交时,首先InnoDB会记录redo log日志,并持久化到磁盘,并修改日志的状态位prepare状态,然后响应MySQL服务端。当服务端收到响应时,会记录binlog并持久化。然后服务端再调InnoDB存储引擎,执行真正的事务提交,此时InnoDB把redo log的状态改为commit状态。
为什么要两阶段提交,一阶段不行吗?
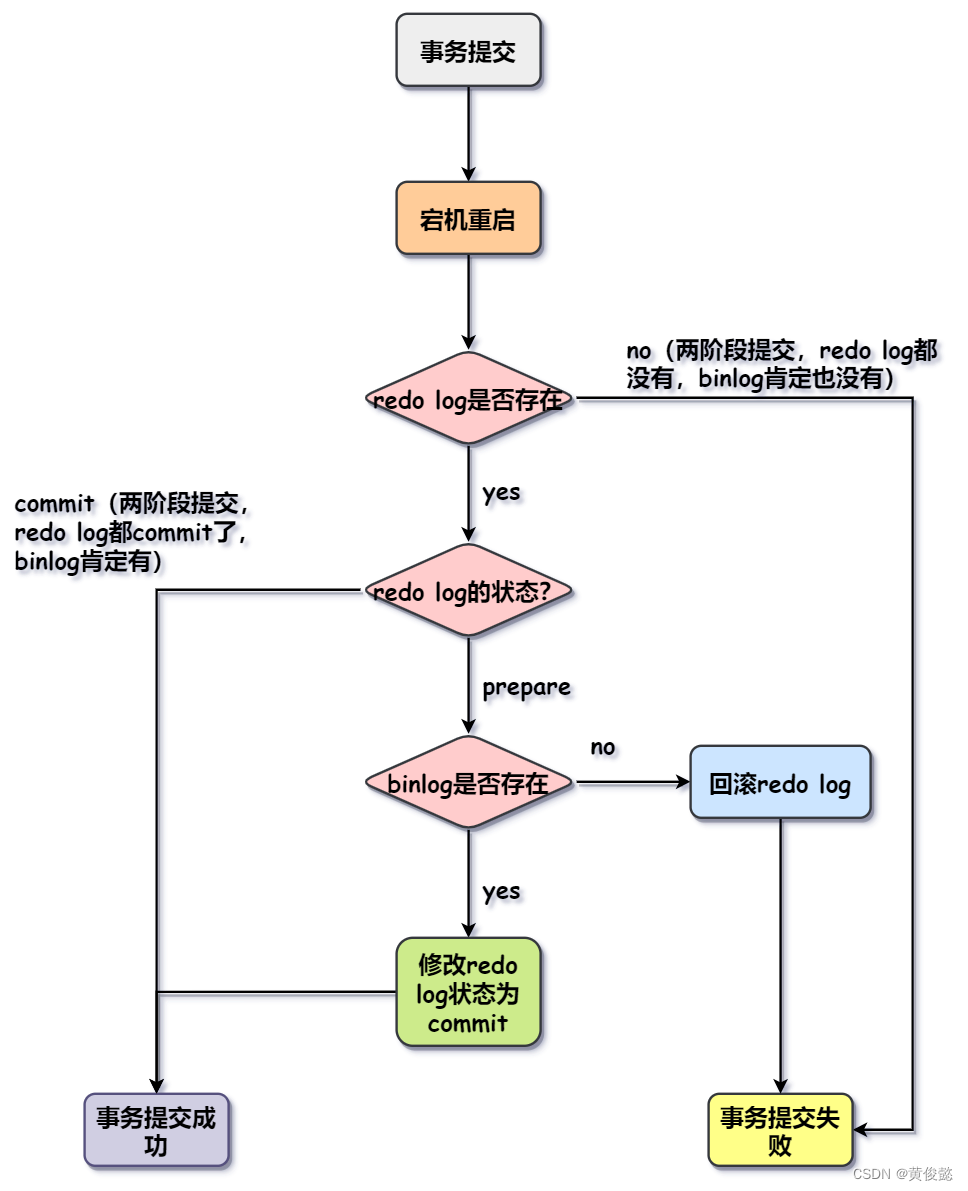
我们看一下当MySQL宕机重启后,两阶段提交的各种可能情况。
当MySQL宕机重启时,检查发现事务提交后记录了redo log处于prepare状态,而binlog并没有记录,那么会把记录的redo log日志回滚掉,这相当于是事务提交失败了,但是redo log和binlog是保持一致的。
如果事务提交时记录了redo log处于prepare状态,并且MySQL服务端也记录了binlog,此时才宕机的,那么MySQL重启后会把redo log提交,这样事务就算是提交成功了,redo log和binlog也是一致的。
如果是redo log和binlog都没有记录,或者redo log记录了并处于commit状态并且MySQL服务端也记录了binlog,这两种情况本身就是一致的。
嗯~~~,怎么看都是没有问题,横竖都是一致的。
那假如改成了一阶段提交呢?
比如先提交redo log,再记录binlog,此时就有可能出现这种情况:提交完redo log后MySQL宕机了,没来得及记录binlog,此时MySQL重启后,发现redo log是有的,于是当前库表的修改是生效的,但是如果我们配了主从同步,由于binlog上是没有修改记录的,因此同步到从库时,从库就少了一次修改。

那改成先记录binlog,再提交redo log呢?那又有可能出现另一个问题:MySQL服务端记录了binlog,此时MySQL宕机了,InnoDB没来得及提交redo log。当MySQL重启时,发现没有redo log,那么当前数据库的库表是不存在此次事务的修改的,但是binlog却记录事务的修改,同步到从库时,从库就比主库多了一次更新,于是又出现了主从不一致。

redo log、undo log、binlog
redo log
redo log是“重做日志”,它的作用就是可以使得InnoDB每次执行SQL的增删改操作,修改了数据行记录之后,无需马上把修改持久化到磁盘,而是记一条redo log日志,redo log是顺序写入的,写入速度非常快,大大提高了写入更新的性能。而数据索引页的修改,InnoDB会异步的以随机写入的方式写入到磁盘,如果没来得及写入就宕机了,InnoDB可以利用redo log去恢复,数据的更新不会丢失。
redo log记录的是索引页的修改,类似于“某个索引页,某某位置,修改为xxx”,是物理日志,物理层面的修改。
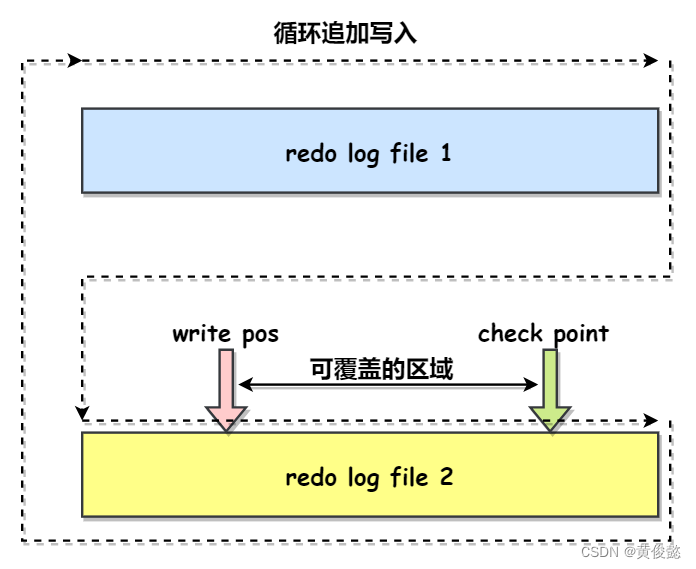
redo log是固定大小的,我们可以配置它的固定大小,以及分成几个文件。redo log 有一个 write pos指针,指向当前写入到的位置,当redo log写满之后,就会回到开头,此时会覆盖掉最开始写入的日志。redo log还有一个check point指针,当数据更新被持久化到磁盘数据索引页后,check point会往前推进,write pos到check point之间的区域都是可以覆盖的。当write pos追上check point后,InnoDB只能停止redo log的写入,先把一部分数据更新到磁盘,把check point往前推一段距离,让write pos有空间可以写入。
binlog
binlog是二进制日志,与redo log不同的是,binlog是属于MySQL服务端日志,是所有存储引擎共享的,而redo log是InnoDB存储引擎专有的日志,只有使用了InnoDB存储引擎,才有redo log日志。
binlog是二进制归档日志,记录的是SQL语句的逻辑,比如“给某某表的某某id的行记录的某某字段的值改为xxx”,因此执行binlog是需要经过解析的,不像redo log那样拿到之后可以直接重放。
binlog是不固定大小的,写满了一个文件,再新开一个。
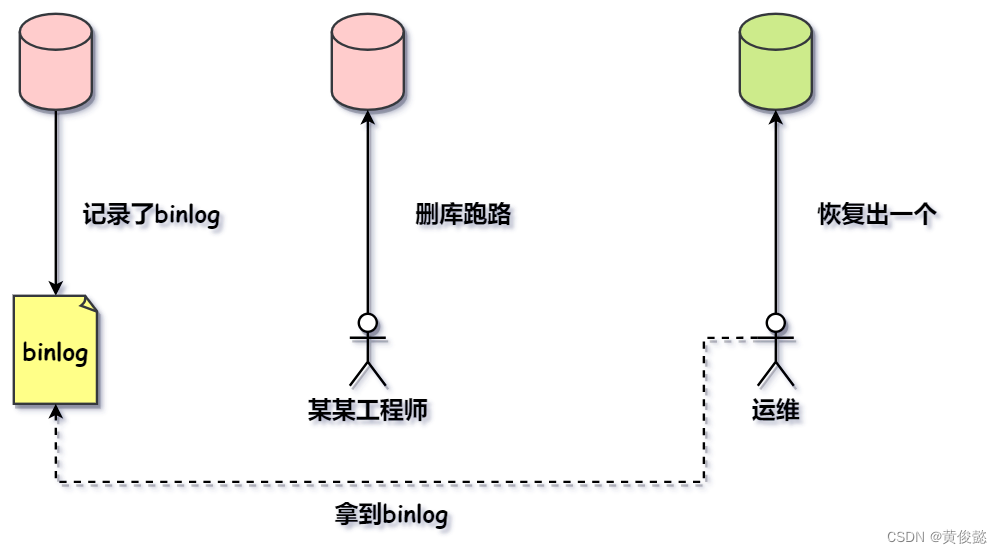
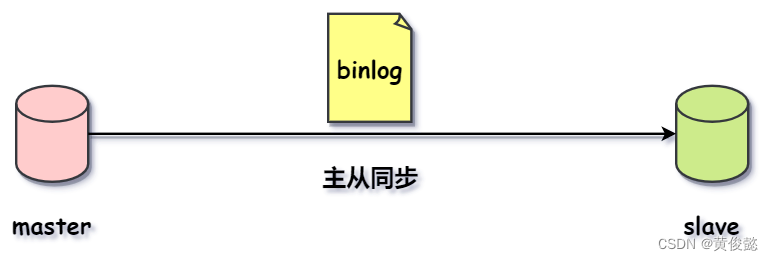
binlog是不具备崩溃自动恢复的能力的,它不像redo log,binlog的作用主要用于归档,也就是用来做备份,当有人删库跑路时,我们可以拿它来人工手动恢复出一个某时间点的库,不至于删完就GG,同时也可以用于主从同步。
undo log
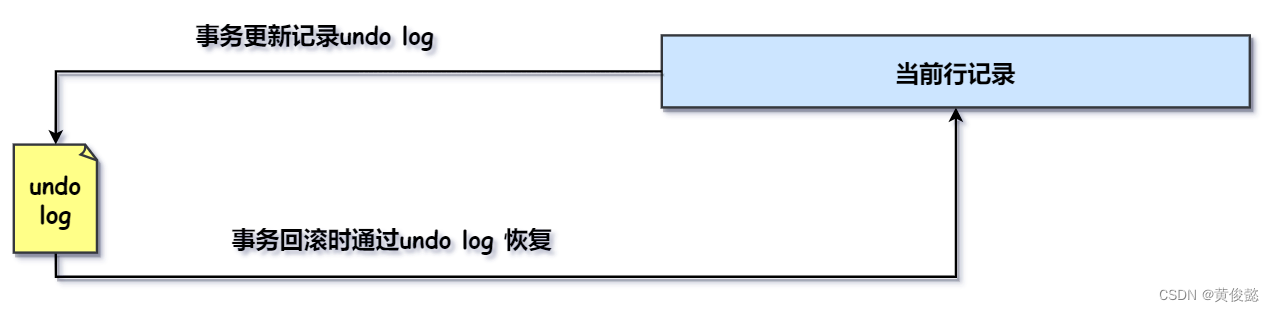
undo log是回滚日志,顾名思义,它是在事务回滚时使用的,所以它的一大作用是事务事务回滚。
undo log记录的是行记录的历史版本,当事务发生回滚时,就从undo log中拿到该行记录的历史版本,恢复回去。


























![[UI5 常用控件] 05.FlexBox, VBox,HBox,HorizontalLayout,VerticalLayout](https://img-blog.csdnimg.cn/direct/d8f503ffd9524510aa20df6405cdacf6.png)









![【蓝桥杯冲冲冲】[NOIP2001 普及组] 装箱问题](https://img-blog.csdnimg.cn/direct/6e67173901fe4580b2975a4c0c11abb1.jpeg#pic_center)