这两天主要在学习二叉树和并查集,刚学起来的时候还有有点困难的,通过看啊哈算法和b站上的一些网课也是能够有了一些理解,但是感觉学的还不是很透彻(对于二叉树的线索化理解还是有一些困难),自己跟着书和网课写了一些代码来加深自己的理解,有了一定的知识基础之后再去写洛谷团队里的题
一、二叉树
基本概念和注意事项
二叉树是n(n>=0)个节点的有限集合:
1.二叉树可以为空二叉树(即n=0)
2.由一个根节点和左子树、右子树构成,左子树和右子树又分别是一棵二叉树
对于二叉树需要注意的是:
1.每个结点最多只有两棵子树
2.左右子树不能颠倒(二叉树是有序树)
 二叉树可以分为五种状态:
二叉树可以分为五种状态:
空、只有左子树、只有右子树、只有根节点、左右子树都有

特殊情况:
完全二叉树、满二叉树和平衡二叉树
(完全二叉树我们可以看成是特殊的满二叉树)
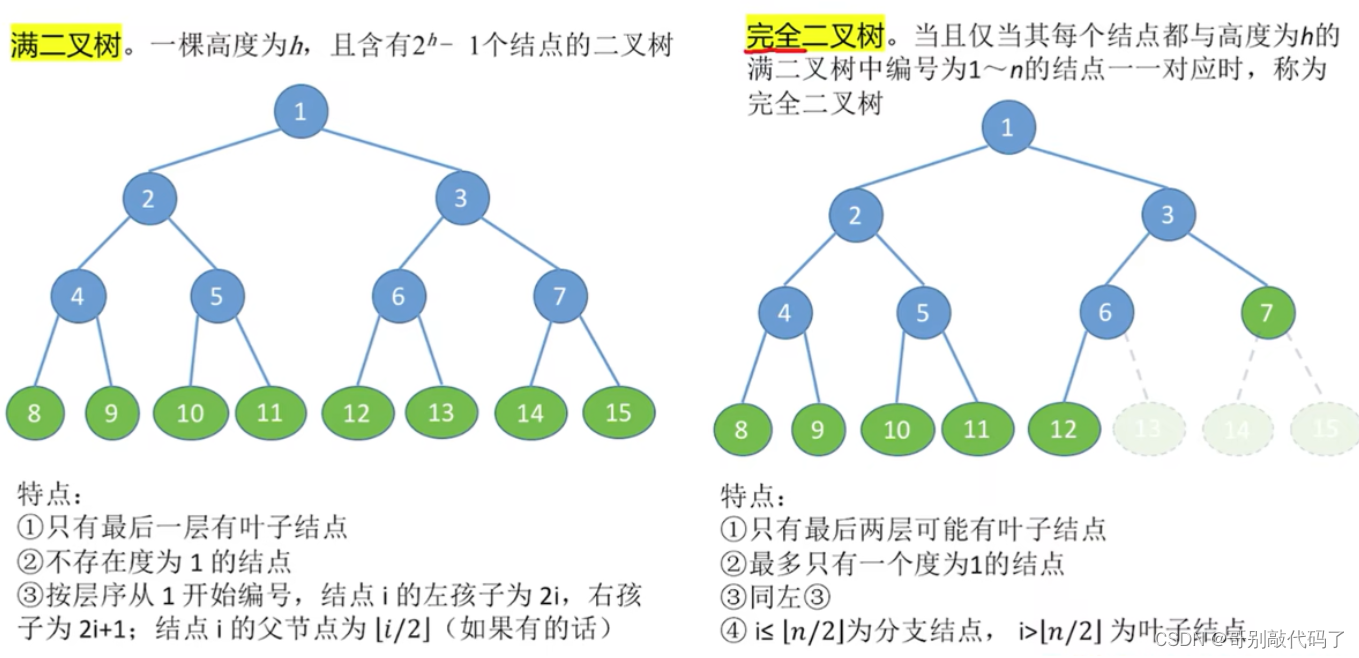

二叉树有两种存储结构:
顺序存储和链式存储
一般来说链式存储效率更快、更加便捷
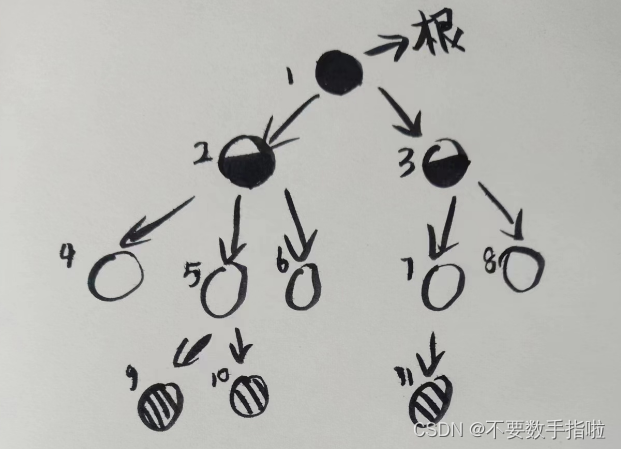
我认为最最重要的就是二叉树的遍历
二叉树的遍历有四种:
先序遍历(根左右)、中序遍历(左根右)、后序遍历(左右根)、层序遍历
这里我用一张图来加深印象、


我们有时会遇到给定两个遍历求第三个遍历的问题(前两个中必须含有中序遍历,否则可能得不到正确的遍历结果)
对于二叉树的应用我通过堆排序来加深了解:
堆排序(啊哈算法):
堆排序1
#include<iostream>
using namespace std;
int h[101];
int n;
void swap(int x,int y) {
int t;
t = h[x];
h[x] = h[y];
h[y] = t;
return;
}
void siftdown(int i) {
int t, flag = 0;
while (i * 2 <= n && flag == 0) {
if (h[i] > h[i * 2])t = i * 2;
else t = i;
if (i * 2 + 1 <= n) {
if (h[t] > h[2 * i + 1])t = 2 * i + 1;
}
if (t != i) {
swap(t, i);
i = t;
}
else flag = 1;
}
return;
}
void creat() {
int i;
for (int i = n / 2; i >= 1; i--) {
siftdown(i);
}
return;
}
int deletemax() {
int t;
t = h[1];
h[1] = h[n];
n--;
siftdown(1);
return t;
}
int main() {
int i, num;
cin >> num;
for (int i = 1; i <= num; i++)
cin >> h[i];
n = num;
creat();
for (int i = 1; i <= num; i++)
printf("%d ", deletemax());
return 0;
}二、并查集
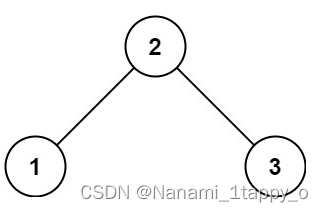
并查集顾名思义就是要把“并”和“查”一起进行,集合就是几棵互不相交的树
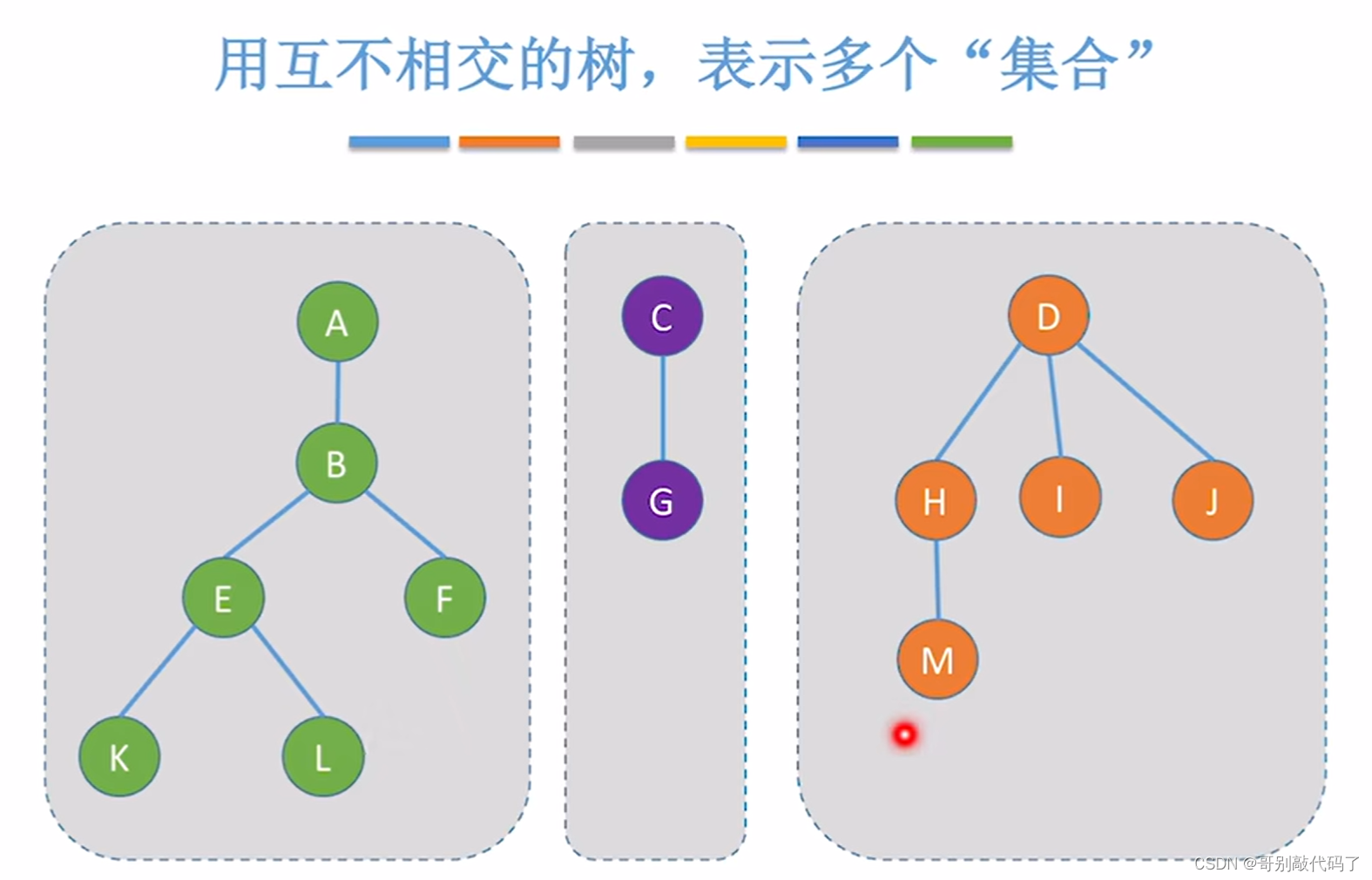
并查集有着自己特殊的存储结构(它可以通过数组里的值来寻找到下一个数的下标)
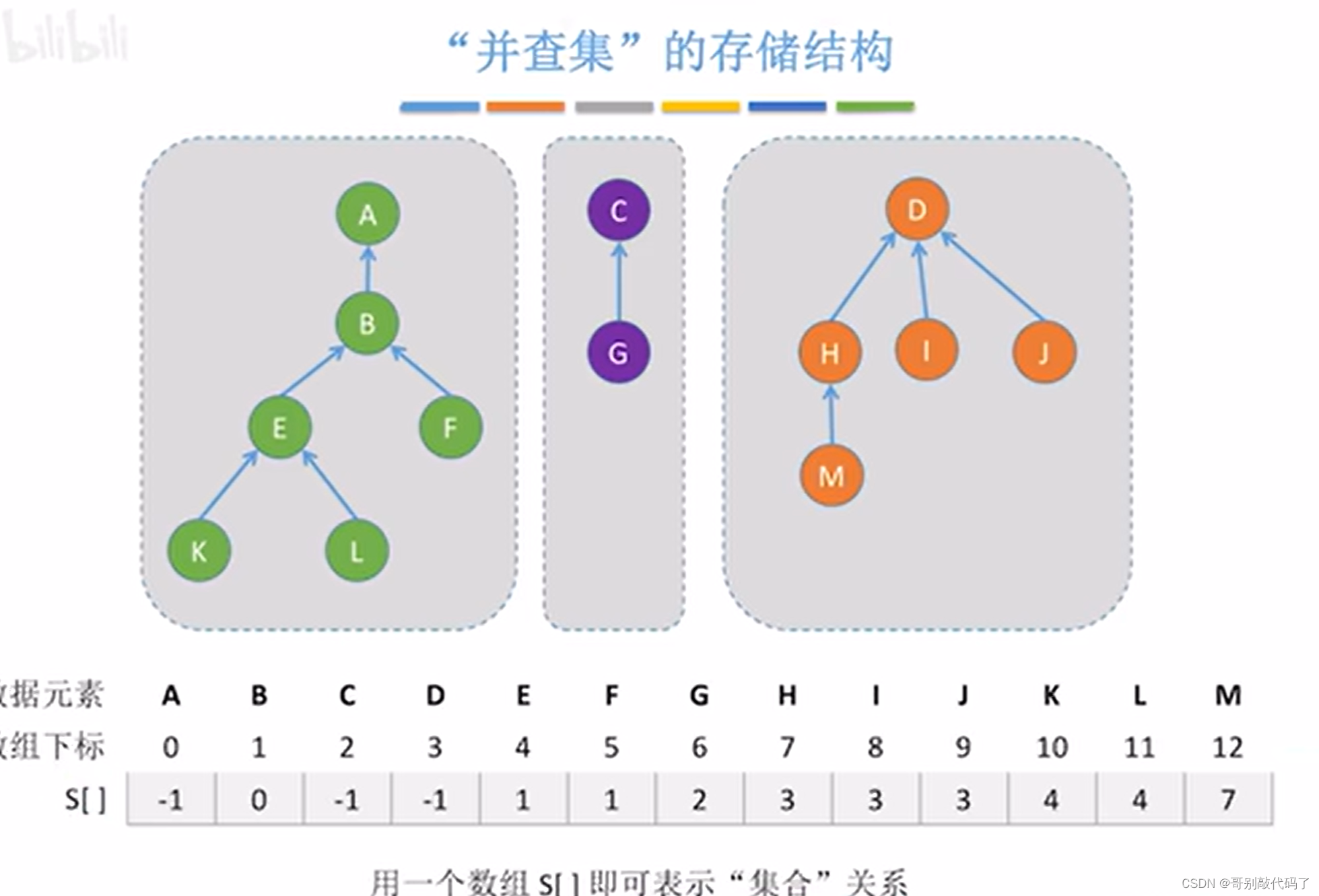
并查集的代码实现(从王道数据结构学的)也是分为并和查两个部分

上面代码中,查的时间复杂度为O(n),并的时间复杂度为O(1),对于这样的时间复杂度还可以进行优化:
因为这查一步里的时间复杂度O(n)主要与树的高度h有关,所以我们在进行并这一步操作时要尽可能的把小树合并到大树里(这样我们就可以得到最小的时间复杂度)
对于并查集明天通过代码来进一步加深学习,同时也可以尝试去写洛谷团队里的题