1 目的
- 持久化元数据
Flink利用Hive的MetaStore作为持久化的Catalog,我们可通过HiveCatalog将不同会话中的 Flink元数据存储到Hive Metastore 中。
- 利用 Flink 来读写 Hive 的表
Flink打通了与Hive的集成,如同使用SparkSQL或者Impala操作Hive中的数据一样,我们可以使用Flink直接读写Hive中的表。
2 环境及依赖
环境:
vim /etc/profile
export HADOOP_CLASSPATH=`hadoop classpath`依赖项:
flink-sql-connector-hive-3.1.2_2.12-1.16.2.jar
https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-hive-3.1.2_2.12
hudi-hive-sync-0.13.0.jar(存在于Hive安装路径下的lib文件夹)
3 使用Catalog
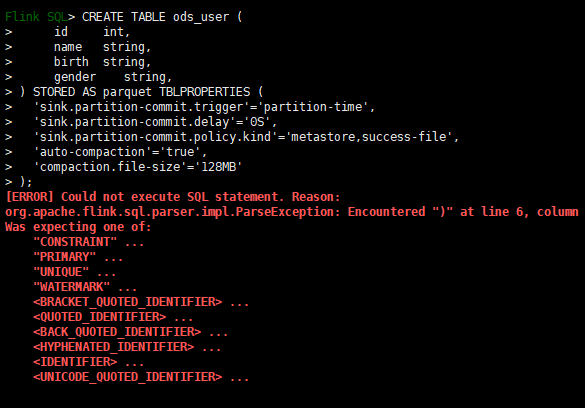
Hive Catalog的主要作用是使用Hive MetaStore去管理Flink的元数据。Hive Catalog可以将元数据进行持久化,这样后续的操作就可以反复使用这些表的元数据,而不用每次使用时都要重新注册。如果不去持久化catalog,那么在每个session中取处理数据,都要去重复地创建元数据对象,这样是非常耗时的。
-- 创建一个catalag
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'hive-conf-dir' = '/etc/hive/conf'
);show catalogs
use catalog hive_catalog;打开hive命令窗口
beeline -u "jdbc:hive2://bigdataxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" -n hive
这样可以在flink sql读写hive表
切换方言:
SET table.sql-dialect=hive;
SET table.sql-dialect=default;