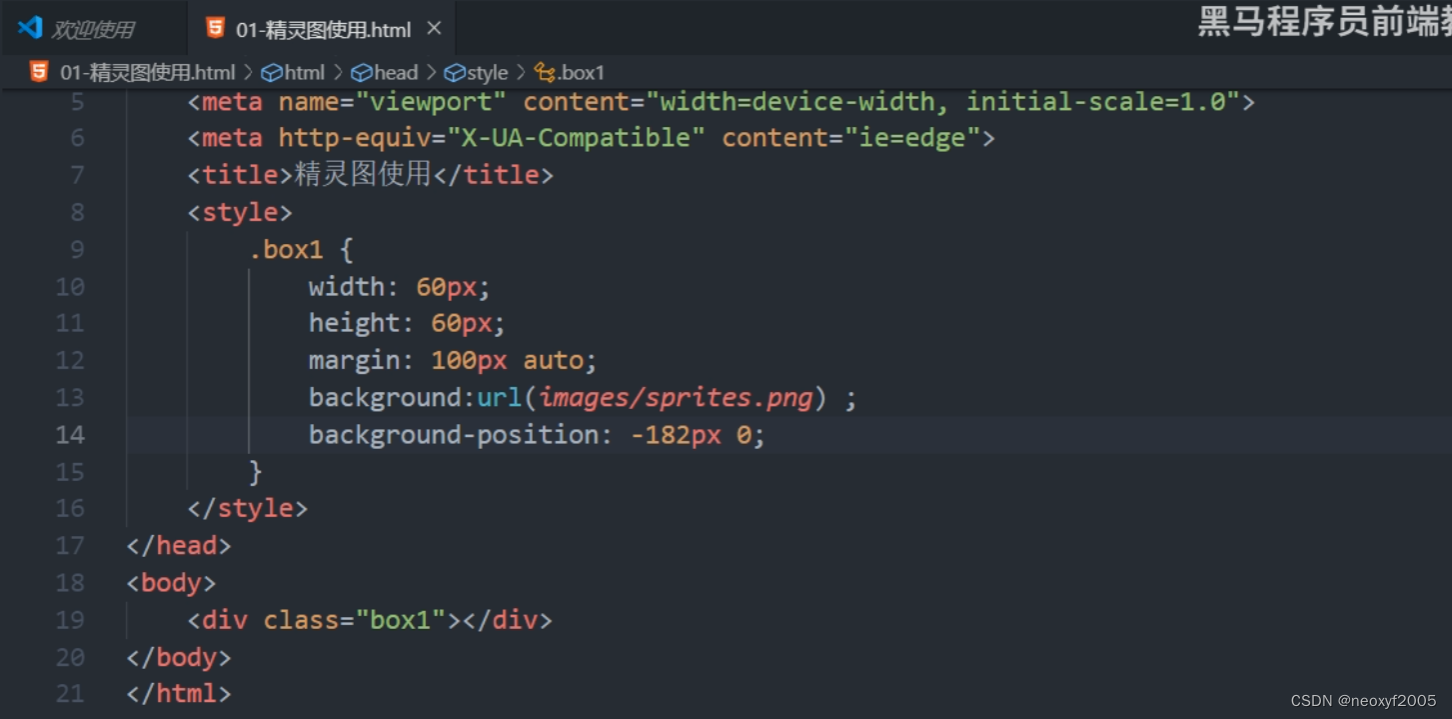
MySQL中的B+树索引结构是用来支持高效的数据检索的。当你使用B+树索引进行查询时,算法的复杂度(或者说,算法的次数)主要取决于查询的类型和数据的分布情况。
范围查询:如果你正在执行范围查询(例如查找某个范围内的值),那么算法的复杂度通常是O(log n),其中n是索引中的记录数。这是因为B+树的设计允许你在对数时间内遍历树来找到范围内的所有记录。
等值查询:对于等值查询(例如查找某个特定的值),算法的复杂度也是O(log n)。
最坏情况:在最坏的情况下,如果你需要查找的记录恰好分布在B+树的底部,那么可能需要遍历更多的记录。在这种情况下,复杂度可能会接近O(n),但这通常是不常见的。
数据分布和分裂:随着时间的推移,B+树可能会因为插入、删除等操作而分裂或合并。这些操作可能会影响查询的效率,但它们通常是局部的,并且对整个树的影响是有限的。
磁盘I/O:B+树索引通常存储在磁盘上,这意味着每次访问一个节点或记录都可能需要磁盘I/O。在实践中,磁盘I/O通常是查询性能的瓶颈,而不是B+树本身的复杂度。
总的来说,对于大多数常见的查询类型和数据分布情况,B+树索引在MySQL中的表现是相当高效的。然而,对于非常大的数据集或非常特殊的查询模式,你可能需要优化查询或调整数据库结构来获得更好的性能。
当使用B+树进行搜索时,算法的次数取决于查询的类型和数据的分布。以下是一个简单的例子来说明B+树搜索的算法次数计算:
假设我们有一个B+树索引,其中包含以下数据:
markdown
10
20
30
40
50
60
70
80
90
100
等值查询:如果我们查询值为50的记录,B+树搜索算法的次数如下:
根节点:1次(因为根节点总是包含查询范围的最小值)
第一个中间节点:1次(因为50大于根节点的最小值10)
第二个中间节点:1次(因为50大于上一个中间节点的最小值30)
叶子节点:1次(找到值为50的记录)总计:4次
范围查询:如果我们查询值在30到70之间的记录,B+树搜索算法的次数如下:
根节点:1次(因为根节点总是包含查询范围的最小值)
第一个中间节点:1次(因为30大于根节点的最小值10)
第二个中间节点:1次(因为30大于上一个中间节点的最小值30)
叶子节点:2次(找到值为40和50的记录)总计:5次
注意:这只是简化的例子,实际的B+树结构可能更复杂,但基本的搜索算法次数计算原理是相同的。