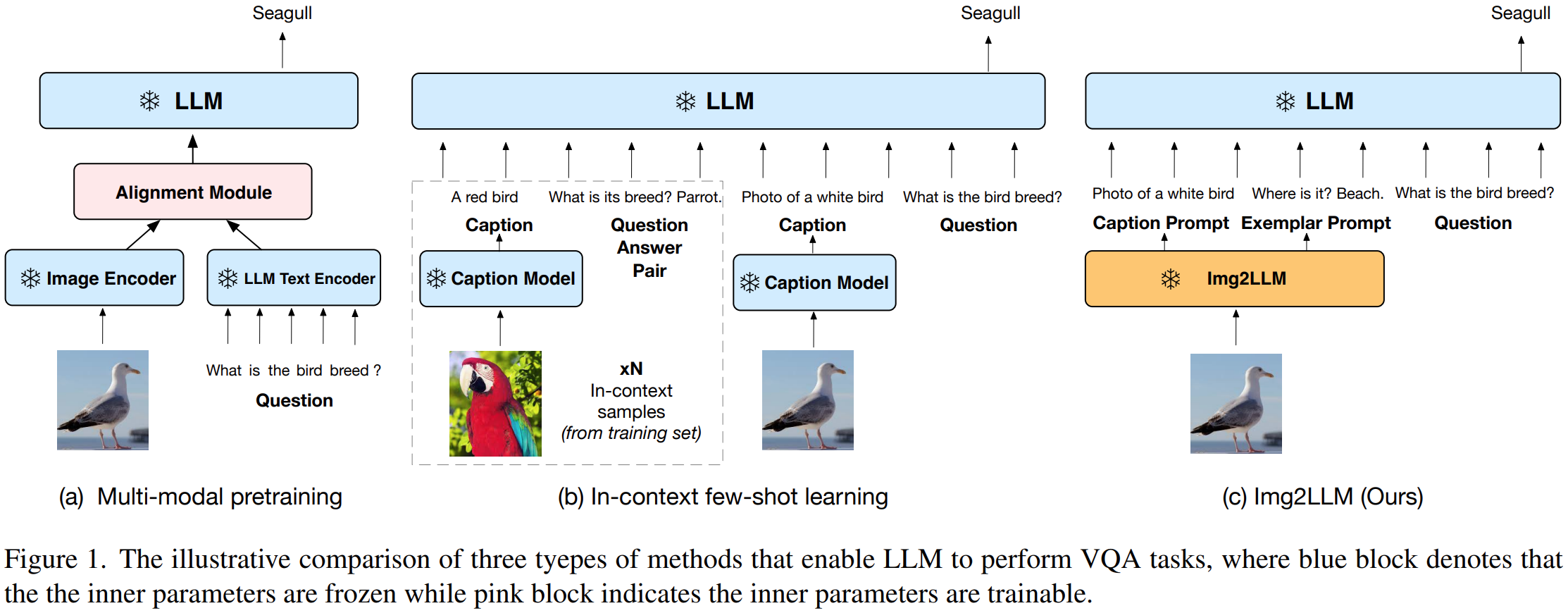
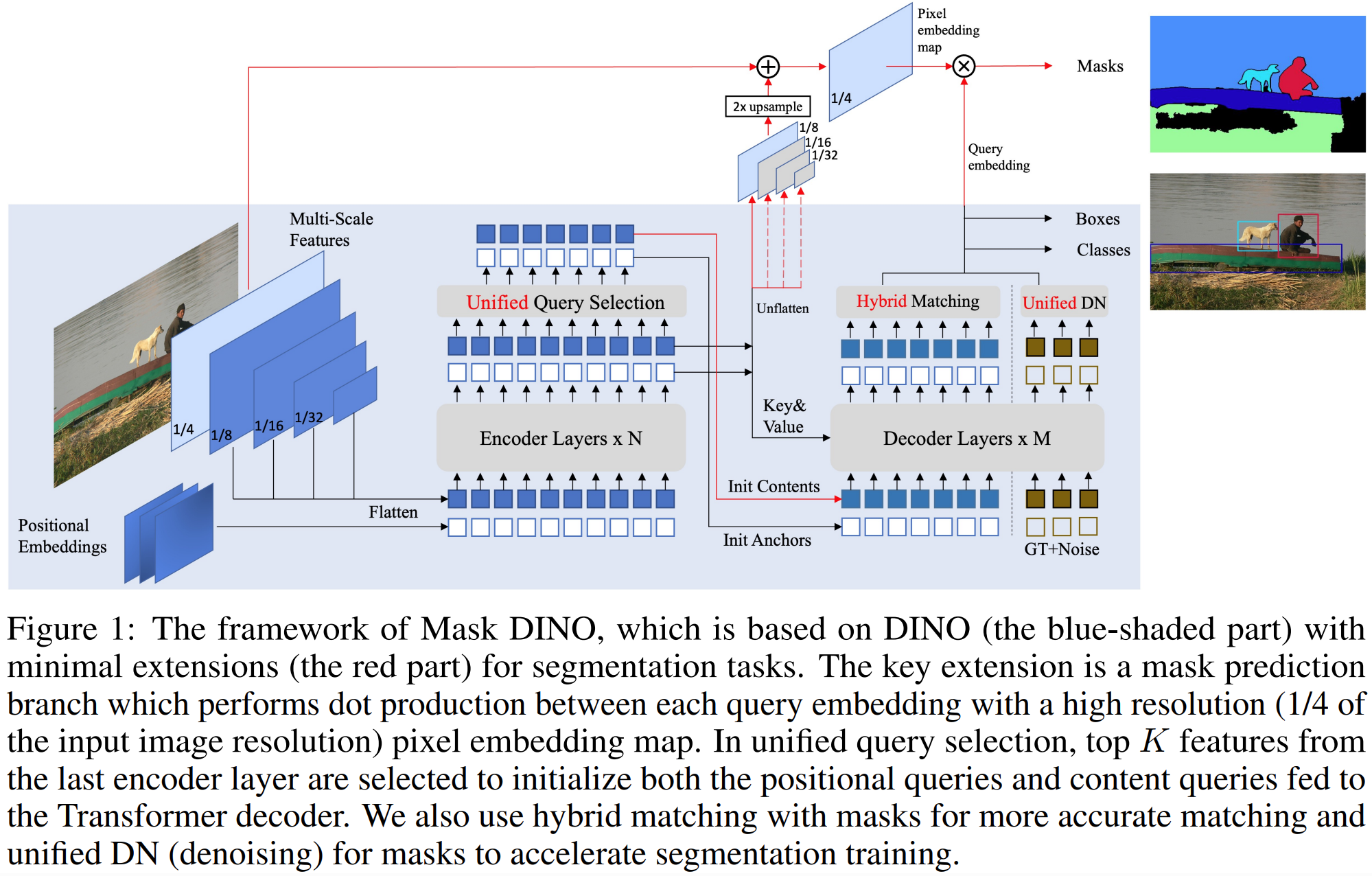
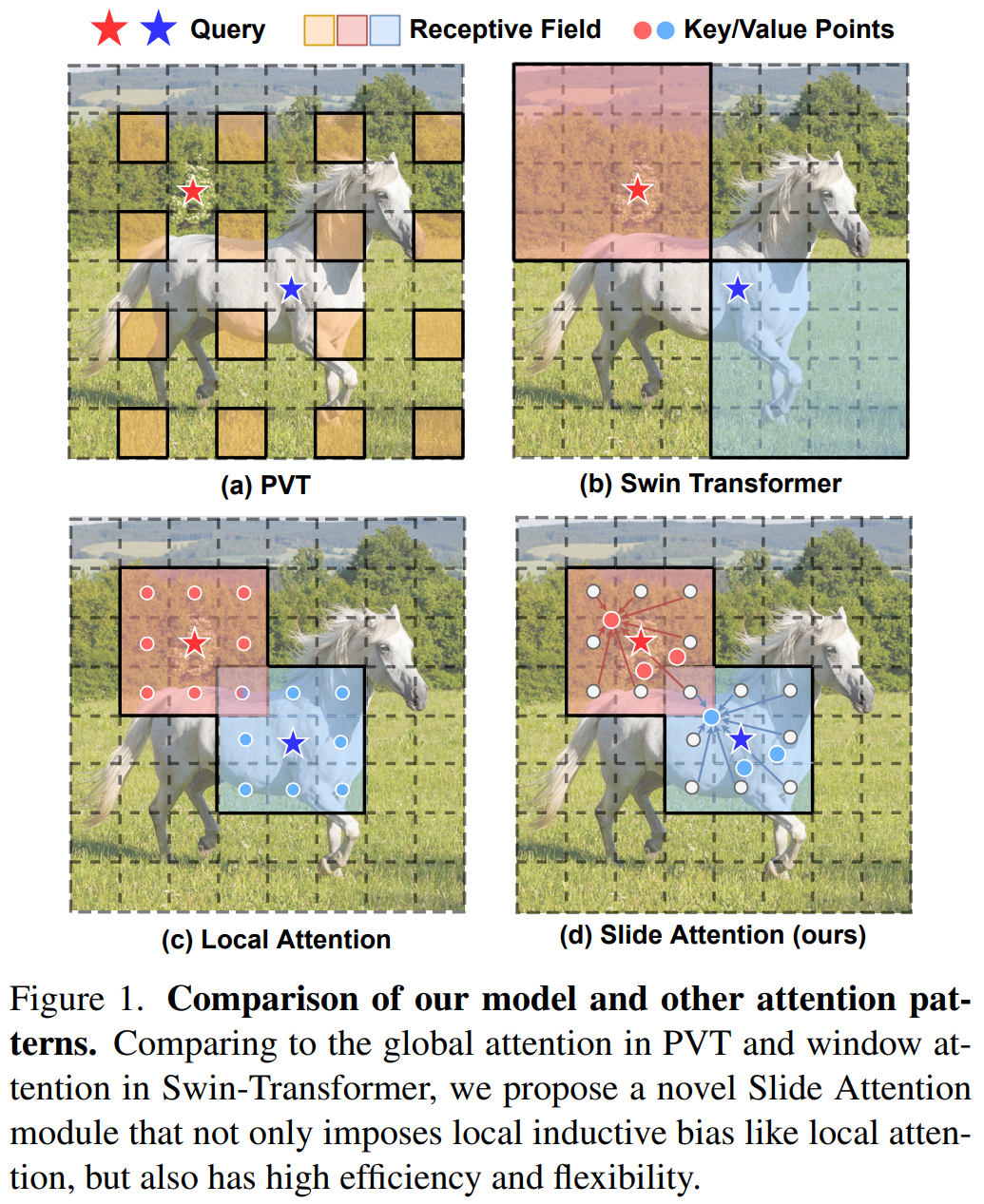
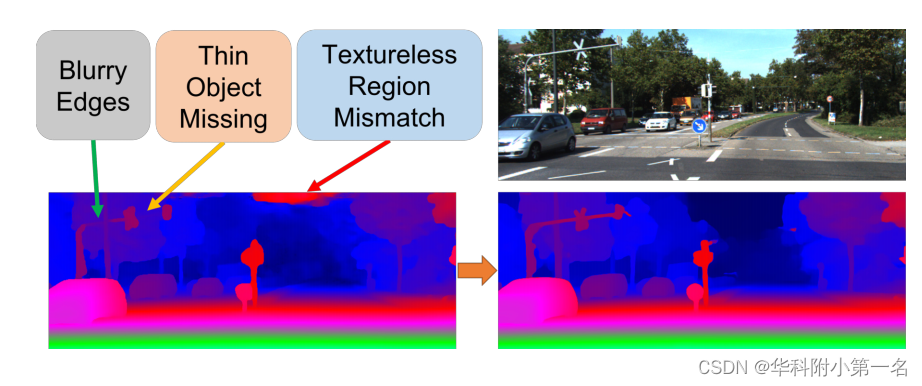
我们使用以下6个分类标准对本文的研究选题进行分析:
I. 模型类型:
几何模型: 这些模型描述图像或场景中实体之间的几何关系。在这个例子中,研究特别关注 单应性,它可以将两个平面上的点相互映射。理解模型类型可以帮助了解研究的范围和局限性。
未知数量的模型: 与传统假设固定数量模型的方法不同,该研究解决了自动 发现数据中存在的模型的精确数量 的难题。这对于事先不知道对象或关系数量的场景至关重要。
II. 模型发现过程:
基于聚类: 该方法不是直接将数据点分配给模型,而是根据数据点与多个模型的 “一致性” 对其进行分组,形成代表潜在新模型实例的簇。这对于抵抗异常值和噪声提供鲁棒性。
渐进选择: 模型发现过程 迭代进行,首先识别 主导 (高度支持) 的模型实例,然后利用它们指导对其他模型的搜索。这避免陷入局部最优,并允许适应复杂的数据结构。
类似 RANSAC 的采样: 与 RANSAC (随机样本一致性) 算法类似,该研究采用 随机采样方法 找到符合大量数据的模型实例。这确保了对异常值的鲁棒性和提高了准确性。
III. 应用领域:
视觉问题: 该研究主要针对 计算机视觉任务,例如: