前言
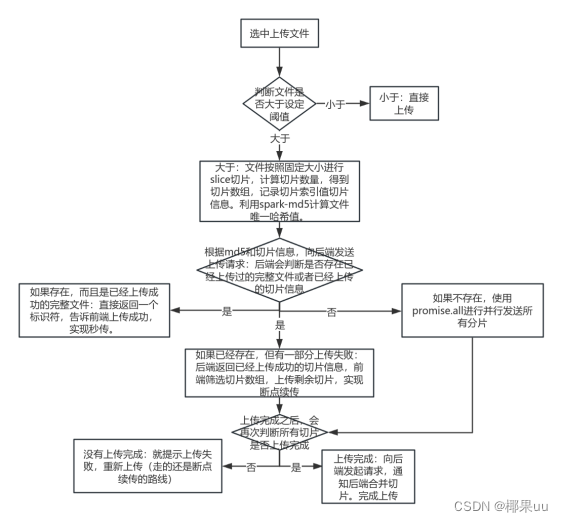
文件上传的场景在工作中时常遇见,必不可免的有时会需要上传一个很大的文件,上传时间比较久,如果遇见网络问题或其他因素影响,容易导致传输失败,这里可以使用分片上传来解决这个问题。
思路:将大文件切成小片异步上传可以解决大文件上传过慢的问题,但如果文件很大时,采用一次性异步上传,会在同一时间产生过多的请求,后端服务器处理不过来,导致请求异常。因此将文件切成小片后,再分组上传,比如一组10个切片,等待10个切片的请求上传完成后,再接着下一组,以此减轻对服务器的压力。
项目目录:
示例功能在 Vue3 中实现:
在 App.vue 中代码
<script setup>
import { nextTick, onMounted } from 'vue'
onMounted(() => {
nextTick(() => {
initFile()
})
})
const initFile = () => {
const inpFile = document.querySelector('#inpFile')
inpFile.onchange = async (e) => {
const file = e.target.files[0]
console.time('cutTime')
// 文件分片结果
const chunks = await cutFile(file)
console.timeEnd('cutTime')
console.log(chunks)
}
}
// 分片大小
const CHUNK_SIZE = 1024 * 1024 * 5;
// 线程数量:cpu数量或者默认4个
const THREAD_COUNT = navigator.hardwareConcurrency || 4;
// 将文件进行分片
const cutFile = (file) => {
return new Promise((resolve) => {
const result = [];
// 分片数量
const chunkCount = Math.ceil(file.size / CHUNK_SIZE);
// 每个线程需要处理的分片数量
const workerChunkCount = Math.ceil(chunkCount / THREAD_COUNT);
// 完成的分片数量
let finishCount = 0;
for (let i = 0; i < THREAD_COUNT; i++) {
// 创建线程,不开启线程在处理时会出现页面卡顿的情况
const worker = new Worker("/src/worker.js", {
type: "module",
});
// 每个线程的起始和结束索引
const startIndex = i * workerChunkCount;
let endIndex = startIndex + workerChunkCount;
if (endIndex > chunkCount) {
endIndex = chunkCount;
}
// 向线程发送消息
worker.postMessage({
file,
CHUNK_SIZE,
startIndex,
endIndex,
});
// 监听线程返回的消息
worker.onmessage = (e) => {
for (let i = startIndex; i < endIndex; i++) {
result[i] = e.data[i - startIndex];
}
// 关闭线程
worker.terminate();
finishCount++;
// 线程全部完成
if (finishCount >= THREAD_COUNT) {
resolve(result);
}
};
}
});
}
</script>
<template>
<div>
<input type="file" id="inpFile"/>
</div>
</template>
<style scoped>
.logo {
height: 6em;
padding: 1.5em;
will-change: filter;
transition: filter 300ms;
}
.logo:hover {
filter: drop-shadow(0 0 2em #646cffaa);
}
.logo.vue:hover {
filter: drop-shadow(0 0 2em #42b883aa);
}
</style>
前提:安装 spark-md5 插件
npm i --save spark-md5在 worker.js 文件中代码
import SparkMD5 from 'spark-md5'
onmessage = async (e) => {
const { file, CHUNK_SIZE, startIndex, endIndex } = e.data
// promise 数据
const proms = []
for (let i = startIndex; i < endIndex; i++) {
proms.push(createChunk(file, i, CHUNK_SIZE))
}
// 一起获取全部的 promise 结果
const chunks = await Promise.all(proms)
// 发送消息
postMessage(chunks)
}
// 创建分片
function createChunk(file, index, size) {
return new Promise((resolve) => {
const start = index * size;
const end = start + size;
// 创建md5对象
const spark = new SparkMD5.ArrayBuffer();
// 创建文件读取实例
const fileReader = new FileReader();
fileReader.onload = (e) => {
// 将分片数据追加到md5对象
spark.append(e.target.result);
resolve({
start,
end,
index,
hash: spark.end(),
});
};
// 读取文件
fileReader.readAsArrayBuffer(file.slice(start, end));
});
}