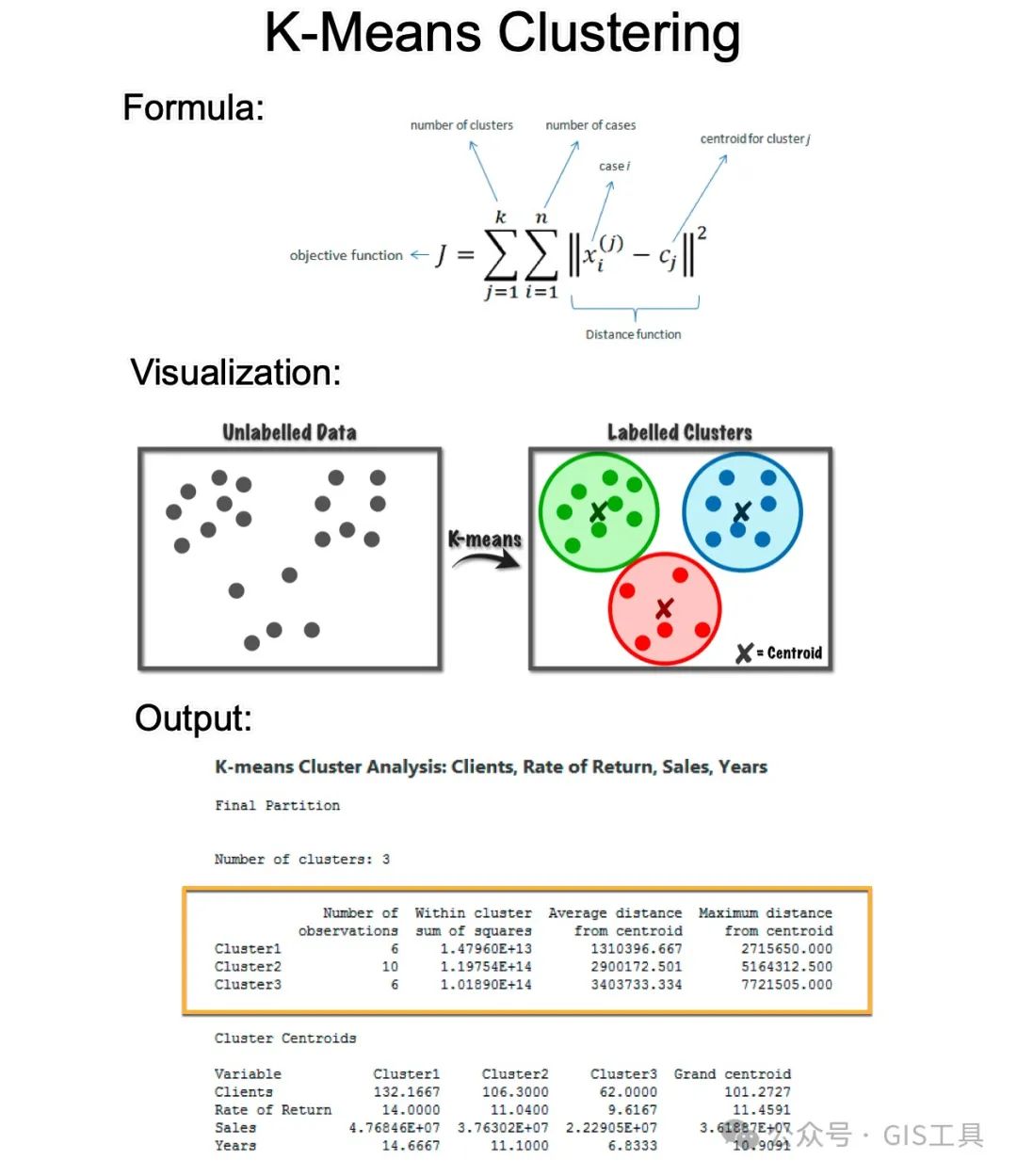
K-means 是数据科学和商业的基本算法。只需 4 分钟即可了解需要 4 周时间才弄清楚的内容。让我们深入了解一下。
1. K-means是一种流行的用于聚类的无监督机器学习算法。它是用于客户细分、库存分类、市场细分甚至异常检测的核心算法。
2. 无监督:K-means 是一种无监督算法,用于没有标签或预定义结果的数据。目标不是预测目标输出,而是通过识别数据集中的模式、聚类或关系来探索数据的结构。
3. 目标函数:K-means 的目标是最小化簇内平方和(WCSS)。它通过一系列迭代步骤(包括分配和更新步骤)来实现这一点。
4. 分配步骤:在此步骤中,将每个数据点分配给最近的聚类质心。“最近”通常使用欧几里得距离来确定。
5.更新步骤:重新计算质心作为簇中所有点的平均值。每个质心是其簇中点的平均值。
6.迭代:重复分配和更新步骤,直到质心不再发生显着变化,表明集群稳定。此过程最大限度地减少了簇内方差。
7. 输出:聚类质心、标签和距离平方和。质心代表每个聚类中所有点的平均位置,对于解释聚类结果至关重要。标签是聚类分配。距离平方和是簇中每个点距簇质心距离的度量。
8. 评估。有多种评估 K 均值的方法。两种常见的方法是剪影评分法和肘部法。
9. Silhouette Score:该指标衡量数据点与其他集群相比与其自身集群的相似程度。轮廓得分范围从 -1 到 1,其中高值表示数据点与其自己的簇匹配良好,而与相邻簇匹配较差。
10. 肘部法:该方法涉及将惯性绘制为簇数量的函数,并在图中寻找“肘部”。下降率急剧变化的肘点对于簇数来说是一个不错的选择。























![[word] Macbook big sur 打不开word- MacOS big sur word闪退怎么恢复 #其他#知识分享#其他](https://img-blog.csdnimg.cn/img_convert/b340a31322e3ca61e2f80cbc07d5fbed.png)