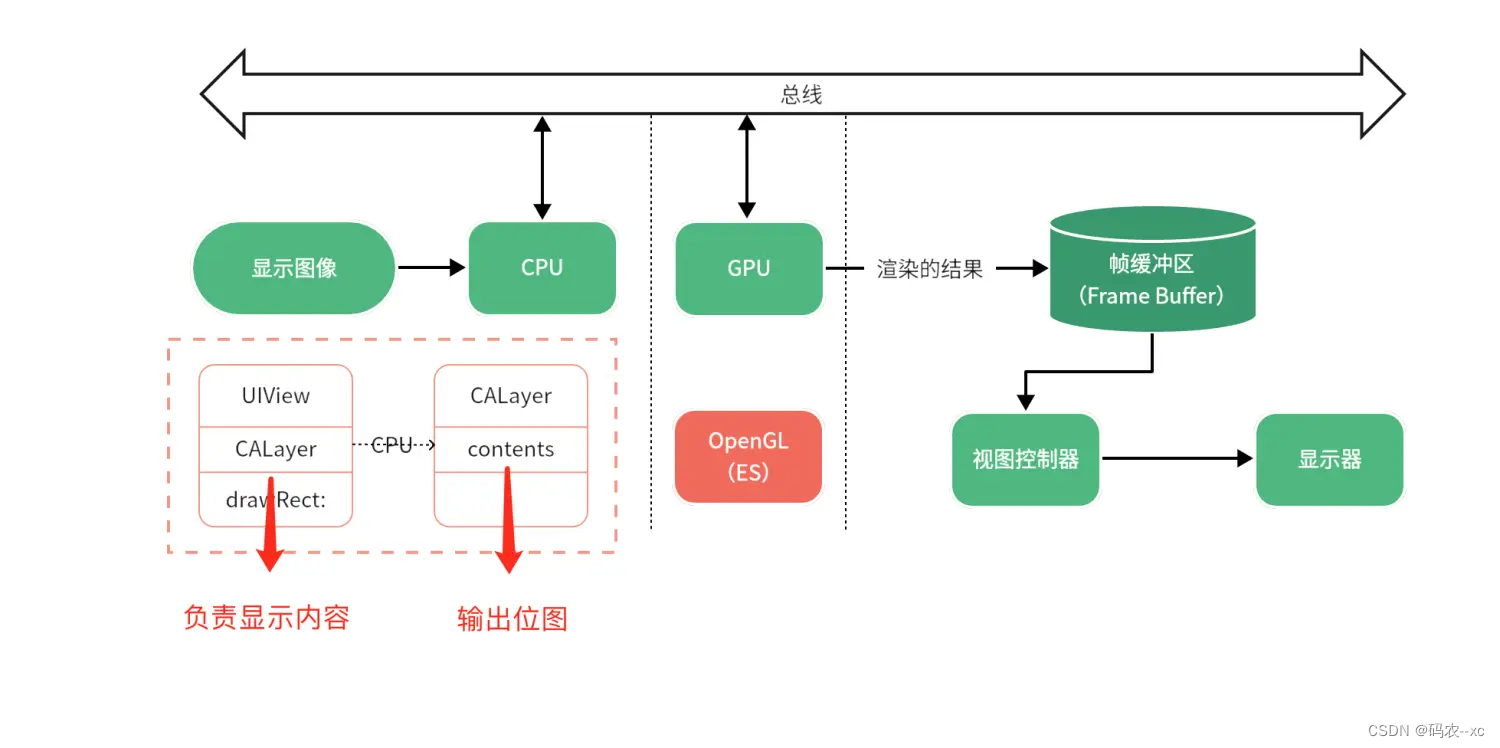
Java中的引用类型有哪些?这些引用类型对应的使用场景有哪些?为什么要有这么多的引用类型?
在Java中,引用是指向对象在内存中存储位置的指针,引用类型主要是分为四种:强引用、软引用、弱引用、虚引用
- 强引用:强引用指的是在程序代码之中普遍存在的,类似Object obj = new Object()这类引用,只要强引用还存在,垃圾回收器就不会回收掉被引用的对象实例
- 使用场景:日常使用的new XXX()创建的对象都是强引用1
- 软引用:软引用是用来描述一些还有用但是不是必须的对象。对于软引用关联的对象,在系统中将要发生内存溢出之前,会把这些对象列入回收范围之中进行第二次回收。人如果这次回收还是没有足够的内存,才会抛出内存溢出异常。在JDK 1.2之后,提供了SoftReference类来实现软引用
- 使用场景:软引用通常是用来实现内存敏感的缓存,如果还有空闲内存,就可以暂时保留缓存,当内存不足的时候清理掉,这样就保证了使用缓存的同时,不会耗尽内存
- 弱引用:弱引用也是用来描述非必须的对象的,它的强度要弱于软引用。被弱引用关联的对象之恶能生存到下一次垃圾回收之前。当垃圾回收器开始工作的时候,无论当前内存是否够用,都会回收掉弱引用关联的对象。在JDK 1.2之后提供了WeakReference类来实现弱引用
- 使用场景:维护一种非强制性的映射关系,如果试图获取对象还存在,就使用它,否则就重新实例化。例如ThreadLocal中的ThreaddLocal中的ThreadLocalMap使用的就是弱引用
- 虚引用:虚引用也被称为幽灵引用或者幻影引用,不能通过它访问对象。幻想引用仅仅是提供一种确保对象被finalize以后,做某些事情的机制
- 使用场景:监控对象的创建和销毁
为什么要有这么多引用类型
这些引用类型为Java程序提供一种更加精细的内存管理手段,使得开发者可以根据应用程序的具体需求来调整对象的生命周期,特别是在处理大量数据缓存、资源管理和防止内存泄露等场景尤其重要
Java中的垃圾回收算法有哪些?它们各自有哪些优缺点?
垃圾回收是指自动管理程序中不再需要的内存的过程。在Java中,垃圾回收负责识别和释放不再适用对象所占用的内存空间,以便将其重新分配给新的对象使用。Java中常见的垃圾回收算法重要是有以下几种:
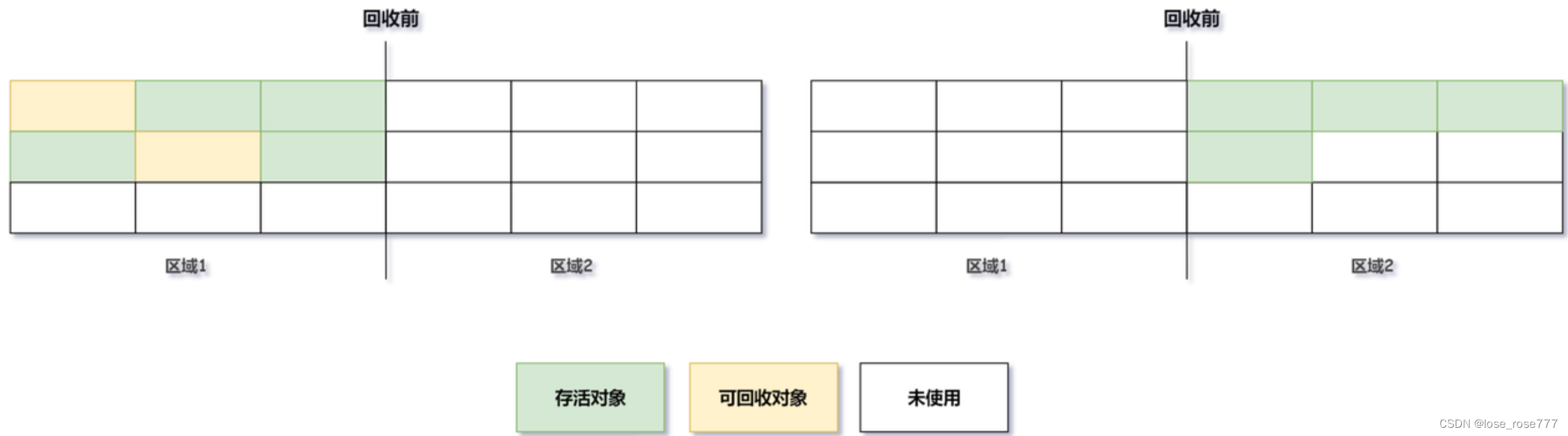
- 标记-清除算法:标记-清除算法是最基础的收集算法。算法分为标记和清除两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象,如下图:
- 优点:实现简单且执行效率相当高效
- 缺点:会产生内存碎片问题,在标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行中需要分配较大的对象时,无法找到足够连续内存而不得不提前出发另一次垃圾收集
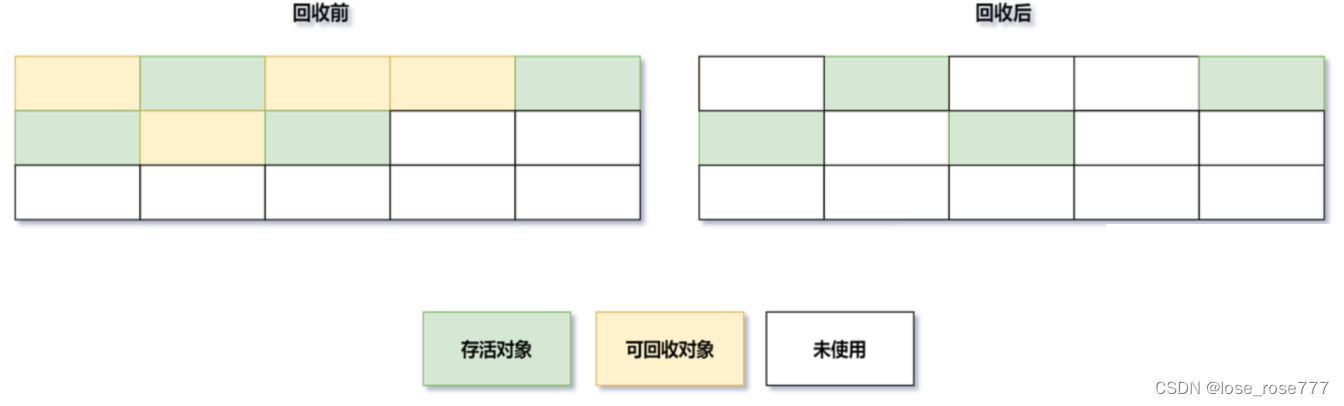
- 标记-整理算法:标记-整理算法也是分为两个阶段标记和整理,其中标记与上述相同,但是后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉

- 优点:无内存碎片化问题
- 缺点:执行效率比较低
- 复制算法:复制算法是为了解决标记-整理的效率问题,它将可用内存按照容量分为大小相等的两块,每次只是用其中的一块。当这块内存需要进行垃圾回收时,会将此区域还存活着的对象复制到另一块上面,然后再把已经使用过的内存区域一次性清理掉。这样做的好处是每次都是对整个半区进行内存回收,内存分配时也就不需要考虑内存碎片化问题等复杂情况,只需要移动堆顶指针,按顺序分配即可。简单高效,运行高效
- 优点:执行效率高
- 缺点:空间利用率低
- 分代算法:分代算法是通过区域划分的,实现不同区域和不同的垃圾回收策略,从而更好的垃圾回收
- 优点:分而治之,不同场景实现不同的算法,整体的性能更高且空间效率高
- 缺点:实现复杂度比较高
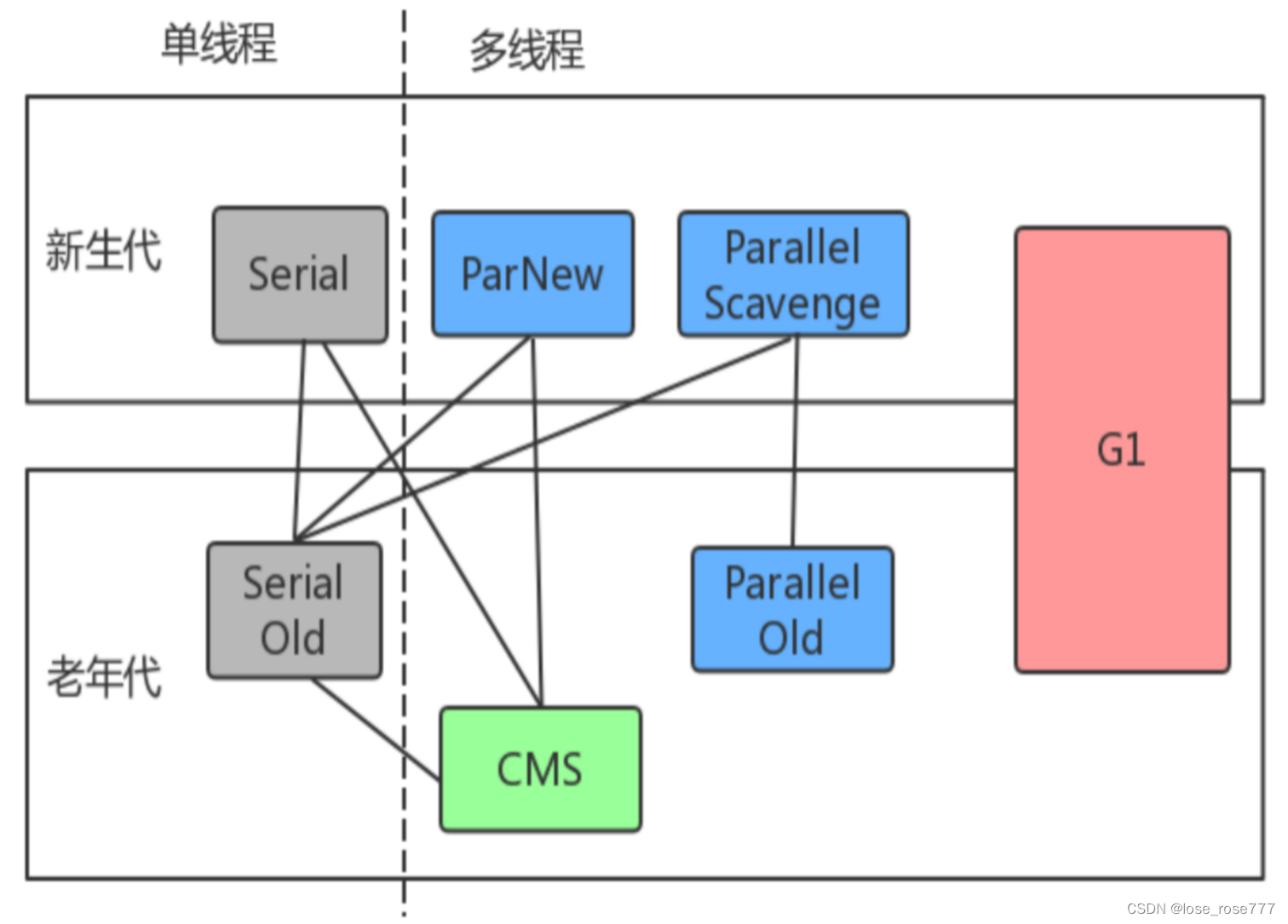
JVM中的常见垃圾回收器有哪些?
Serial/Serial Old:
- 使用的是标记-整理(Mark-Compact)算法。
- 在新生代中,使用标记-复制(Mark-Copy)算法。
- 这些算法是基于停止-复制或者停止-整理的方法,在垃圾回收过程中会暂停所有应用程序线程。
ParNew:
- ParNew是Serial的多线程版本,因此在新生代中也使用标记-复制(Mark-Copy)算法。
- ParNew垃圾回收器可以与CMS垃圾回收器一起工作,在CMS旧代回收时使用。
Parallel Scavenge/Parallel Old:
- Parallel Scavenge在新生代中使用标记-复制(Mark-Copy)算法,目标是达到一个可控的吞吐量。
- Parallel Old在老年代中使用的是标记-整理(Mark-Compact)算法。
CMS (Concurrent Mark-Sweep):
- 使用的是并发标记和并发清除算法。
- CMS垃圾回收器在尽量减少停顿时间的前提下进行垃圾回收,通过与应用程序并发执行标记和清除操作来实现。
G1 (Garbage-First):
- 使用的是分代垃圾回收算法,结合了标记-整理(Mark-Compact)和标记-清除(Mark-Sweep)的特性。
- G1将堆内存划分为多个区域,并使用标记-整理和标记-清除操作来进行垃圾回收,以尽量减少停顿时间。
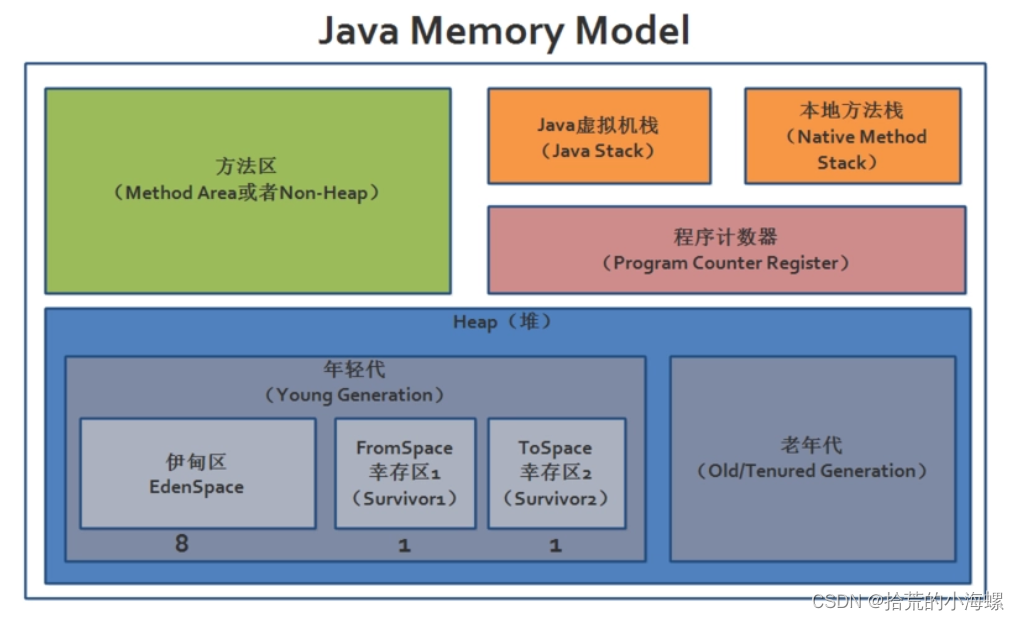
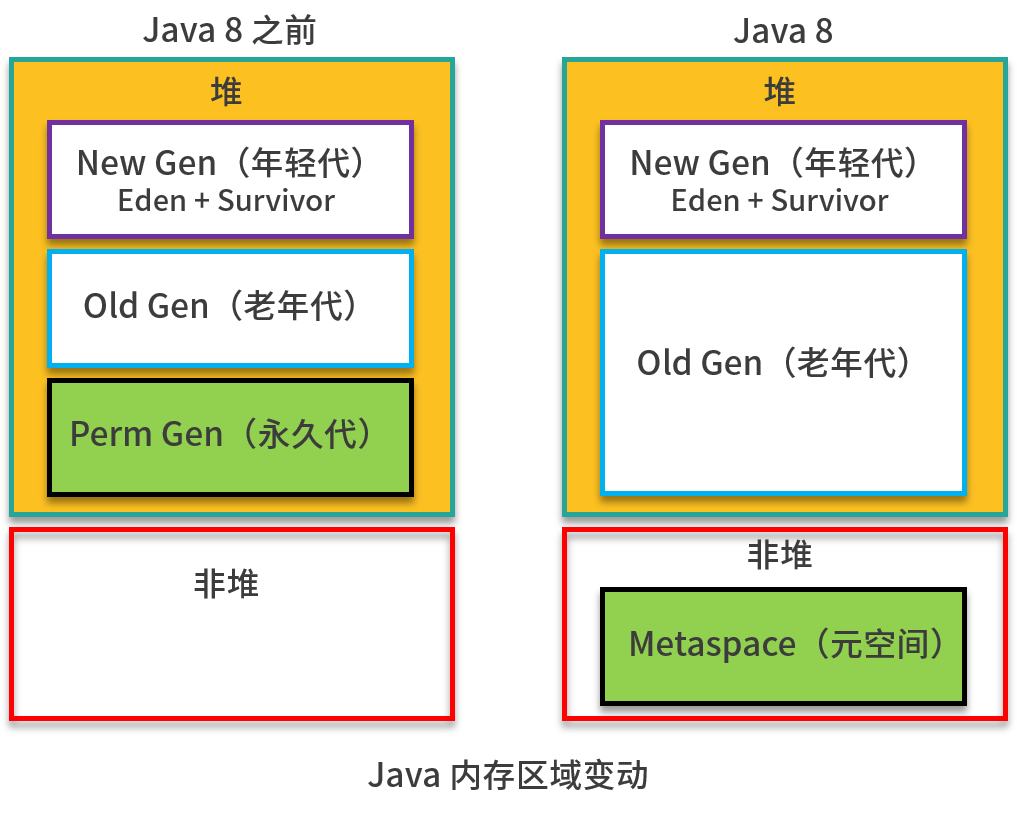
新生代指的是新创建的对象内存区域/老年代适用于存放长时间存活对象的内存区域
CMS垃圾回收器有什么优缺点?它使用了什么算法?
CMS(并发标记清理)回收器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分Java应用集中在互联网站或者B/S系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,已给用户带来更好的体验,CMS收集器就非常符合这类应用的需求
优点:低延迟、并发收集效率高
缺点:
产生内存碎片:因为CMS使用的是标记-清除算法,所以会产生内存碎片
CPU资源敏感:因为垃圾回收时虽然不会STW(停止),但是占用用户线程的CPPU资源,如果用户线程本身的CPU资源已经很吃紧了,那么此时在使用CMS无疑是雪山加霜
CMS如何解决内存碎片问题?它能使用标记-整理算法吗?为什么?
CMS并不能直接解决内存碎片的问题,因为CMS时使用的是标记-清除算法。但是当内存碎片比较多的时候(连续内存不足以申请大对象时),CMS会借助Serial Old垃圾回收执行内存碎片的回收工作,因Serial Old使用的是标记-整理算法,所以内存碎片问题就会得到解决
CMS可以使用标记-整理算法呢
不能,这是因为CMS最后一个阶段是并发清楚阶段,此阶段CMS垃圾回收回和用户线程并发执行,如果使用并发-整理算法需要移动内存位置,而此时用户线程只在执行,所以不能使用并发-整理算法
说一下CMS执行流程?它需要全局停顿(STW)几次?
CMS执行流程总共分为以下四个阶段:
- 初始标记(STW):GC Roots能直接关联的对象,执行速度很快
- 并发标记(和用户线程并发执行):GC Roots直接关联的对象继续往下(一直)遍历和标记,耗时会比较长
- 重新标记(STW):对上一步的并发标记阶段,因为用户线程执行而导致变动的对象进行修正标记
- 并发清除(和用户线程并发执行):使用并发-清除算法将垃圾对象进行删除
由此可以看出CMS执行的时候,一共有两次停顿
Old GC和Full GC有什么区别?JVM中的垃圾回收类型还有哪些?
Old GC是老年代垃圾回收,而Full GC是全局垃圾回收,区别如下:
Old GC(老年代垃圾回收):Old GC又被称为Major GC。它主要是针对老年代内存区域进行垃圾回收,当老年代内存空间不足,或从新生代晋升的对象过多导致老年代无法容纳的时候,会发生Old GC。Old GC的发生频率是低于新生代GC,但是其执行时间通常是比新生代GC长的多
Full GC(全局垃圾回收会泽和完全垃圾回收):Full GC是对整个堆内存(年轻代和老年代)、方法去进行全面的垃圾回收。发生Full GC的情况是较为复杂的,例如:老年代空间不足、元空间不足、System.gc(显式调用(不推荐)、CMS 并发标记失败后 fallback 到 Serial 0ld 收集器等。Full GC 的开销非常大,因为它涉及到了IVM 几乎所有的内存区域,因此应尽量避免不必要的 Ful GC,以减少系统停顿时间
所以说:Full GC=Minor GC+Major Gc+方法区 GC
JVM有哪些优化手段?说说JIT和逃逸分析?
JVM优化手段主要分为以下几种:
- JIT(即时编译):是一种在程序运行时将部分热点代码(频发使用的代码)编译成机器代码的技术,以提高程序的执行性能的机制
- 逃逸分析:用于确定对象动态作用域是否超过当前方法或线程,通过逃逸分析,编译器可以决定一个对象的作用范围,从而进行相应的优化,但是确定对象没有逃逸时,可以进行以下优化:
- 栈上分配:如果编译器可以确定一个对象不会逃逸出方法,它可以将对象分配到栈上而不是堆上。在栈上的分配对象在方法返回后会自动销毁,不会进行垃圾回收,提高了程序执行效率
- 锁消除:如果对象只在单线程中使用,那么同步锁可能会被消除,提高程序性能
- 标量替换:将原本需要分配在堆上的对象拆分成若干基础数据类型存储在栈上,进一步减少堆空间的使用
- 字符串池优化:JVM通过共享字符串常量,重用字符串对象,以减少内存占用和提升字符串操作性能
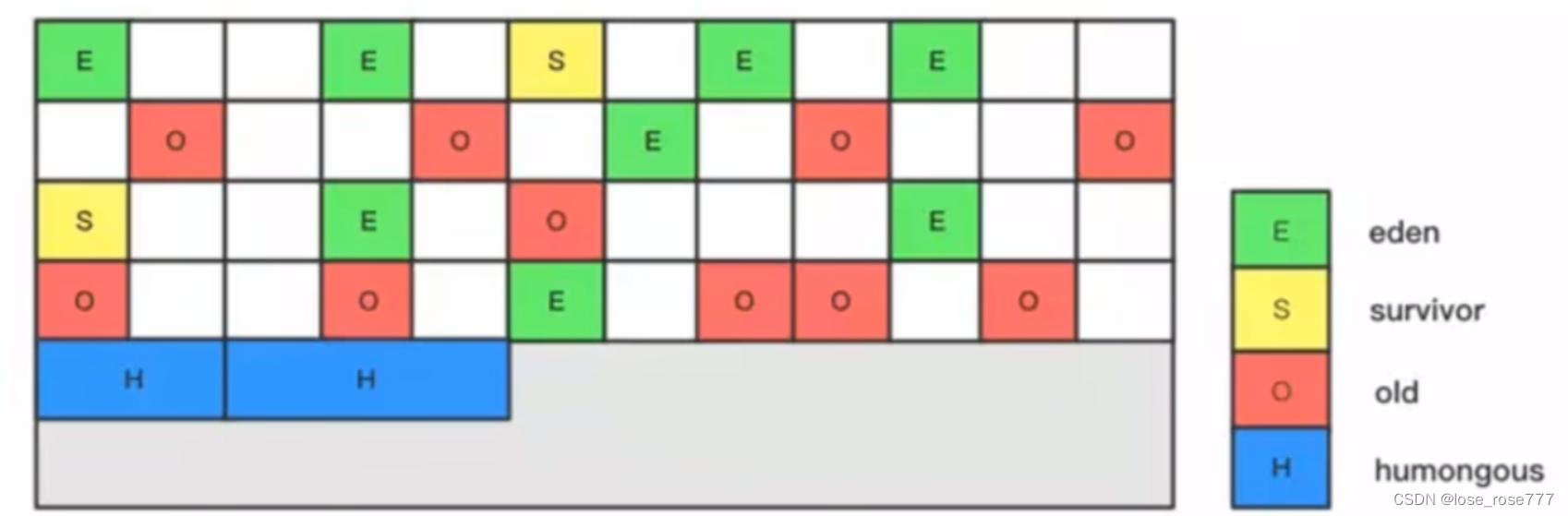
G1是如何分区的?
G1总共分为以下四个区域:
- Eden(伊甸园区):新创建的对象都会存储在此区域
- Survivor(存活区):eden经过GC(垃圾回收)之后存活的对象就会移动到此区域
- Old(老年代):经过n次GC之后还存活的对象
- Humongous(巨型区):用来存放大对象的,大对象会直接存放到此区域,当一个对象的大小超过 Region(内存) 的一半时(50%),则该对象定义为大对象
G1和CMS有什么区别?
G1和CMS垃圾回收器都是HotSpot虚拟机最终的最常用的垃圾回收器。区别如下:
- 回收算法
- G1:使用的是分代垃圾回收算法,结合了标记-整理(Mark-Compact)和标记-清除(Mark-Sweep)的特性。G1将堆内存划分为多个区域,并使用标记-整理和标记-清除操作来进行垃圾回收,以尽量减少停顿时间
- CMS:使用的是标记-清除算法。CMS垃圾回收器在尽量减少停顿时间的前提下进行垃圾回收,通过与应用程序并发执行标记和清除操作来实现
- 停顿时间
- G1:G1回收器的设计目标之一是尽量减少垃圾回收造成的停顿时间,它通过在整个堆内存中采用并发标记、并发整理和并发清理等技术来实现。由于G1使用了区域化的垃圾回收策略,因此可以更好地控制垃圾回收的停顿时间
- CMS:CMS也致力于减少垃圾回收造成的停顿时间,但由于其并发清除阶段并不是完全并发的,可能会导致一些额外的停顿时间
- 内存占用
- G1:G1的设计目标之一是减少内存碎片,通过区域化的垃圾回收策略和压缩空间的操作来提高内存的利用率,从而减少堆内存的占用。
- CMS:CMS的设计目标之一是最小化停顿时间,因此在内存利用率方面可能没有G1优秀。此外,由于CMS回收器在并发清除阶段可能会产生大量的空间碎片,可能会影响到堆内存的分配和使用
























![Flink 1.18.1 部署与配置[CentOS7]](https://img-blog.csdnimg.cn/direct/e06e1abfbca04bbf9c19452edeb41f08.png)

![[C++]继承(续)](https://img-blog.csdnimg.cn/direct/656cb42891d54d9dab31cbb93adeba8e.png)