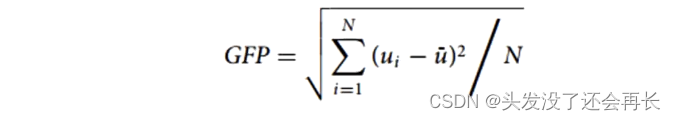Redis学习——高级篇⑤


= = = = = = = = = Redis7高级之案例实战 hyperloglog(五)= = = = = = = = =

面试——记录对集合中的数据进行统计
- 在移动应用中,需要统计每天的新增用户数和第2天的留存用户数;
- 在电商网站的商品评论中,需要统计评论列表中的最新评论;
- 在签到打卡中,需要统计一个月内连续打卡的用户数;
- 在网页访问记录中,需要统计独立访客(Unique Visitor, UV)量。
痛点:类似今日头条、抖音、淘宝这样的额用户访问级别都是亿级的,请问如何处理?
存的进+取得快+多维度
5.1 系统中常见的四种统计
1.聚合统计——set
统计多个集合元素的聚合结果(交并差集合统计) set集合

2.排序统计——zset
抖音短视频最新评论留言的场景,设计一个展现列表
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议使用zset

3.二值统计——bitmap
集合元素的取值就只有 0 和 1 ,来记录签到还是没签到 bitmap
4.基数统计——hyperloglog
只统计一个集合中不重复的元素个数 hyperloglog
5.2hyperloglog
1.名词解释
- UV (Unique Visitor) 独立访客,一般理解为客户端IP (需要考虑去重)
- PV (Page View) 页面浏览量,不用去重
- DAU(Daily Active User)日活跃用户量,登录或者使用了某个产品的用户数(去重复登录的用户),常用于反映网站、互联网应用或者网络游戏的运营情况
- MAU(Monthly Active User)月活跃用户量
既要埋头苦干,又要仰望星空
2.需求
很多计数类场景,比如 每日注册 IP 数、每日访问 IP 数、页面实时访问数 PV、访问用户数 UV等。
因为主要的目标高效、巨量地进行计数,所以对存储的数据的内容并不太关心。
也就是说它只能用于统计巨量数量,不太涉及具体的统计对象的内容和精准性。
统计单日一个页面的访问量(PV),单次访问就算一次。
统计单日一个页面的用户访问量(UV),即按照用户为维度计算,单个用户一天内多次访问也只算一次。
多个key的合并统计,某个门户网站的所有模块的PV聚合统计就是整个网站的总PV。
3.hyperloglog复习
基数
- 是一种数据集,去重复后的真实个数
- 在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2的64次方个不同元素的基数
| 命令 | 作用 |
|---|---|
| pfadd key element… | 将所有元素添加到key中 |
| pfcount key | 统计key的估算值(不精确) |
| pgmerge new. key key1 key2. … | 合并key至新key |

基数统计就是 HyperLogLog
- 去重复统计功能
- hashSet
- 小范围还行吧
- bitmap
- bitmap是通过用位bit数组来表示各元素是否出现,每个元素对应一位,所需的总内存为N个bit。
- 新进入的元素只需要将已经有的bit数组和新加入的元素进行按位或计算就行。这个方式能大大减少内存占用且位操作迅速。
- 如果数据较大,比如一个样本案例就是一亿个基数拉值数据,一个样本就是一亿,如果要统计一亿个数据的基数拉值,大约需要内存 1100000000/8/1024/1024 约等于 12M,内存减少占用的效果显著。这样得到统计一个对象样本的基数值需要12M。
- 如果统计10000个对象样本(1w个亿级),就需要117.1875G将近120G,可见使用bitmaps还是不适用大数据量下(亿级)的基数计数场景,
- 但是bitmap是精确计算的
- 结论
- 量变会引起质变
- 办法
- 概率算法
- 通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身,通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身
- HyperLogLog就是一种概率算法的实现。
- 概率算法
- 原理说明
只是进行不重复的基数统计,不是集合也不保存数据,只记录数量而不是具体内容
有误差
- hyperloglog提供不精确的去重技术方案
- 牺牲准确率来换取空间,误差仅仅只是 0.81% 左右
5.3统计亿级UV的Redis方案
1.对于技术的选型
用mysql
- mysql扛不住稍微大一点的并发,而且都需要存入mysql中,导致mysql的检索也会变慢

用redis的hash结构存储
- 按照ipv4的结构来说明,一个ip最多15个字节(ip=“192.168.238.1xx”),某一天 1.5亿*15个字节 = 2G,一个月60G,内存直接没了,加内存条都没用
hyperloglog
- 在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近2的64次方个不同元素的基数

Redis使用了 2 14 = 16384 2^{14}=16384 214=16384个桶,按照上面的标准差,误差为0.81%, 精度相当高。Redis使用一个long型哈希值的前14个比特用来确定桶编号,剩下的50个比特用来做基数估计。而 2 6 = 64 2^6=64 26=64,所以只需要用6个比特表示下标值,在一 般情况下, 一个HLL数据结构占用内存的大小为 16384 ∗ 6 / 8 = 124 16384*6/8= 124 16384∗6/8=124kB, Redis将这种情况称为密集(dense) 存储。
2.编码(yml和pom与上次一致)
HypeLogLogService
public interface HypeLogLogService {
public long uv();
}
HyperLogLogServiceImpl
import com.xfcy.service.HypeLogLogService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.Random;
import java.util.concurrent.TimeUnit;
@Slf4j
@Service
public class HypeLogLogServiceImpl implements HypeLogLogService {
@Resource
private RedisTemplate redisTemplate;
/**
* 模拟后台有用户点击网站首页,每个用户来自不同的IP地址
*
* @PostConstruct修饰的方法会在服务器加载Servlet的时候运行,并且只会被服务器执行一次。
*/
@PostConstruct
public void initIp() {
new Thread(() -> {
String ip = null;
for (int i = 0; i < 200; i++) {
Random random = new Random();
ip = random.nextInt(256) + "." + random.nextInt(256) + "." + random.nextInt(256) + "." + random.nextInt(256);
Long hll = redisTemplate.opsForHyperLogLog().add("hll", ip);
log.info("ip = {}, 该IP地址访问首页的次数={}",ip,hll);
try {
// 暂停3秒钟
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}, "t1").start();
}
public long uv() {
// PFCOUNT
return redisTemplate.opsForHyperLogLog().size("hll");
}
}
HyperLogLogController
import com.xfcy.service.HypeLogLogService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@Api(tags = "淘宝亿级UV的Redis统计方案")
@Slf4j
@RestController
public class HyperLogLogController {
@Resource
private HypeLogLogService hypeLogLogService;
@ApiOperation("获得IP去重复后的UV统计访问量")
@RequestMapping(value = "/uv",method = RequestMethod.GET)
public long uv(){
return hypeLogLogService.uv();
}
}
- 启动项目后测试


= = = = = = = = = Redis7高级之案例实战GEO(六)= = = = = = = = =
6.1 附近的人、附近的美食店铺怎么实现的

- 用mysql
- 查询性能问题,并发高、数据量大这种查询要搞垮mysql数据库
- 一般mysql查询的是一个平面矩形访问,而叫车服务要以我为中心N公里为半径的圆形覆盖
- 精准度的问题,我们知道地球不是平面坐标系,而是一个圆球,这种矩形计算在长距离计算时会有很大误差,mysql不合适
- 用GEO
- 可以解决上述问题

6.2 命令复习
GEOADD添加经纬度坐标

会出现中文乱码
redis -cli -a 123456 --raw
GEOPOS返回经纬度

GEOHASH返回坐标的 geohash 表示 (base32编码)

主要分为三步
- 将三维的地球变为二维的坐标
- 在将二维的坐标转换为一维的点块
- 最后将一维的点块转换为二进制再通过base32编码
GEODIST返回两个位置之间的距离

GEORADIUS以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。

GEORADIUSBYMEMBER 找出指定范围内的元素,中心点是由给定的位置元素决定

6.3 案例景点附近的推送功能
GEORADIUS: 以给定的经纬度为中心,找出某一半径内的元素

- GEOService
public interface GeoService {
String geoAdd();
Point position(String member);
String hash(String member);
Distance distance(String member1, String member2);
GeoResults radiusByxy();
GeoResults radiusMember();
}
- GEOServiceImpl
import com.xfcy.service.GeoService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.geo.*;
import org.springframework.data.redis.connection.RedisGeoCommands;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
@Slf4j
public class GeoServiceImpl implements GeoService {
public static final String CITY = "city";
@Autowired
private RedisTemplate redisTemplate;
@Override
public String geoAdd() {
Map<String, Point> map = new HashMap<>();
map.put("白马寺", new Point(112.610356,34.728481));
map.put("龙门石窟", new Point(112.484071,34.564375));
map.put("老君山", new Point(111.663,33.75186));
map.put("白马寺的公共厕所1", new Point(112.608311,34.726809));
map.put("白马寺的公共厕所2", new Point(112.610356,34.728481));
redisTemplate.opsForGeo().add(CITY, map);
return null;
}
@Override
public Point position(String member) {
// 获取经纬度坐标
List<Point> position = redisTemplate.opsForGeo().position(CITY, member);
return position.get(0);
}
@Override
public String hash(String member) {
// geohash 算法生成的base32编码
List<String> hash = redisTemplate.opsForGeo().hash(CITY, member);
return hash.get(0);
}
@Override
public Distance distance(String member1, String member2) {
// 获取两个给定位置之间的距离
Distance distance = redisTemplate.opsForGeo().distance(CITY, member1, member2,
RedisGeoCommands.DistanceUnit.KILOMETERS);
return distance;
}
@Override
public GeoResults radiusByxy() {
// 通过经纬度查找附近的,白马寺的位置 112.610356,34.728481
Circle circle = new Circle(112.610356, 34.728481, Metrics.KILOMETERS.getMultiplier());
// 返回50条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeCoordinates().sortDescending().limit(50);
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults = redisTemplate.opsForGeo().radius(CITY, circle, args);
return geoResults;
}
@Override
public GeoResults radiusMember() {
// 通过地方查找附近,洛阳白马寺为例
String member = "白马寺";
// 返回10条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().sortAscending().limit(10);
// 半径 10 公里内
Distance distance = new Distance(10, Metrics.KILOMETERS);
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults = redisTemplate.opsForGeo().radius(CITY, member, distance, args);
return geoResults;
}
}
- GEOController
import com.xfcy.service.GeoService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.data.geo.Distance;
import org.springframework.data.geo.GeoResults;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import org.springframework.data.geo.Point;
@Api(tags = "美团地图位置附近的酒店推送GEO")
@Slf4j
@RestController
public class GeoController {
@Resource
private GeoService geoService;
@ApiOperation("添加经纬度坐标")
@RequestMapping(value = "/geoadd",method = RequestMethod.GET)
public String geoAdd() {
return geoService.geoAdd();
}
@ApiOperation("获取经纬度坐标geopos")
@RequestMapping(value = "/geopos",method = RequestMethod.GET)
public Point position(String member){
return geoService.position(member);
}
@ApiOperation("获取经纬度生成的base32编码值geohash")
@RequestMapping(value = "/geohash",method = RequestMethod.GET)
public String hash(String member){
return geoService.hash(member);
}
@ApiOperation("获取两个给定位置之间的距离")
@RequestMapping(value = "/geodist",method = RequestMethod.GET)
public Distance distance(String member1, String member2){
return geoService.distance(member1,member2);
}
@ApiOperation("通过经纬度查找洛阳白马寺附近的")
@RequestMapping(value = "/georadius",method = RequestMethod.GET)
public GeoResults radiusByxy(){
return geoService.radiusByxy();
}
@ApiOperation("通过地方查找附近,白马寺为例")
@RequestMapping(value = "/georadiusByMember",method = RequestMethod.GET)
public GeoResults radiusMember(){
return geoService.radiusMember();
}
}
= = = = = = = = = = = = Redis7高级+ bitmap(七)= = = == = = = = = = =
7.1 bitmap复习
1 是什么
- 由 0 和 1 状态表现得二进制位的 bit 数组
2 能干嘛
- 用于状态统计
- Y、N 类似 AutomicBoolean
- 需求
- 用户是否登录过Y、N,比如京东每日签到送京东
- 电影、广告是否被点击播放过
- 钉钉打卡上班,签到统计
3.京东签到领取京东
- 小厂方法,传统 mysql 方式
CREATE TABLE user_sign
(
keyid BIGINT NOT NULL PRIMARY KEY AUTO_INCREMENT,
user_key VARCHAR(200),#京东用户ID
sign_date DATETIME,#签到日期(20210618)
sign_count INT #连续签到天数
)
INSERT INTO user_sign(user_key,sign_date,sign_count)
VALUES ('20210618-xxxx-xxxx-xxxx-xxxxxxxxxxxx','2020-06-18 15:11:12',1);
SELECT
sign_count
FROM
user_sign
WHERE
user_key = '20210618-xxxx-xxxx-xxxx-xxxxxxxxxxxx'
AND sign_date BETWEEN '2020-06-17 00:00:00' AND '2020-06-18 23:59:59'
ORDER BY
sign_date DESC
LIMIT 1;
签到量用户小这个可以,如何解决这个点
一条签到记录对应一条记录,会占据越来越大的空间。
一个月最多31天,刚好我们的int类型是32位,那这样一个int类型就可以搞定一个月,32位大于31天,当天来了位是1没来就是0。
一条数据直接存储一个月的签到记录,不再是存储一天的签到记录。
- 大厂方法
基于redis的 Bitmap 实现签到日历
在签到统计时,每个用户一天的签到用1个bit位就能表示,
一个月(假设是31天)的签到情况用31个bit位就可以,一年的签到也只需要用365个bit位,根本不用太复杂的集合类型
4. 基本命令
SETBIT key offset value // 将第offset的值设为value value只能是0或1 offset 从0开始
GETBIT key offset // 获得第offset位的值
STRLEN key // 得出占多少字节 超过8位后自己按照8位一组一byte再扩容
BITCOUNT key // 得出该key里面含有几个1
BITOP and destKey key1 key2 // 对一个或多个 key 求逻辑并,并将结果保存到 destkey
BITOP or destKey key1 key2 // 对一个或多个 key 求逻辑或,并将结果保存到 destkey
BITOP XOR destKey key1 key2 // 对一个或多个 key 求逻辑异或,并将结果保存到 destkey
BITOP NOT destKey key1 key2 // 对一个或多个 key 求逻辑非,并将结果保存到 destkey