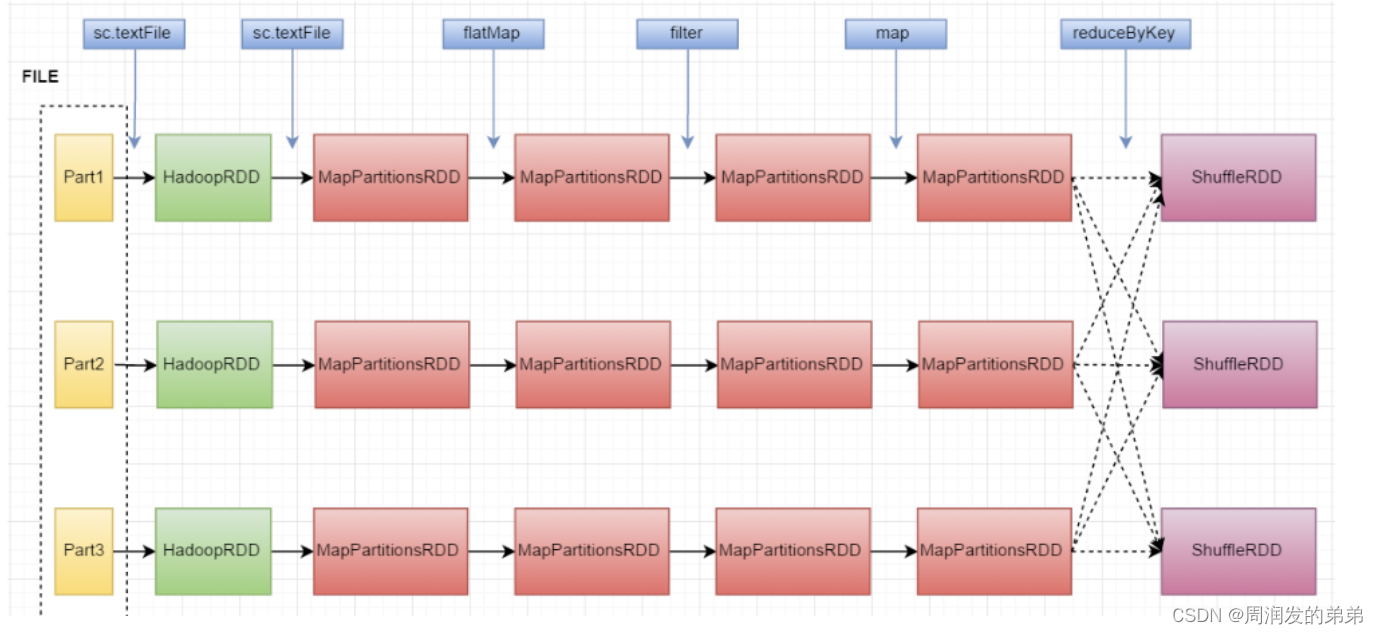
LEARN_FREQ = 5 # training frequency
MEMORY_SIZE = 200000
MEMORY_WARMUP_SIZE = 200
BATCH_SIZE = 64
LEARNING_RATE = 0.0005
GAMMA = 0.99
# train an episode
def run_train_episode(agent, env, rpm):
total_reward = 0
obs = env.reset()
step = 0
while True:
step += 1
action = agent.sample(obs)
next_obs, reward, done, _ = env.step(action)
rpm.append(obs, action, reward, next_obs, done)
# train model
if (len(rpm) > MEMORY_WARMUP_SIZE) and (step % LEARN_FREQ == 0):
# s,a,r,s',done
(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done) = rpm.sample_batch(BATCH_SIZE)
train_loss = agent.learn(batch_obs, batch_action, batch_reward,
batch_next_obs, batch_done)
total_reward += reward
obs = next_obs
if done:
break
return total_reward
# evaluate 5 episodes
def run_evaluate_episodes(agent, eval_episodes=5, render=False):
# Compatible for different versions of gym
if is_gym_version_ge("0.26.0") and render: # if gym version >= 0.26.0
env = gym.make('CartPole-v1', render_mode="human")
else:
env = gym.make('CartPole-v1')
env = CompatWrapper(env)
eval_reward = []
for i in range(eval_episodes):
obs = env.reset()
episode_reward = 0
while True:
action = agent.predict(obs)
obs, reward, done, _ = env.step(action)
episode_reward += reward
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
def main():
env = gym.make('CartPole-v0')
# Compatible for different versions of gym
env = CompatWrapper(env)
obs_dim = env.observation_space.shape[0]
act_dim = env.action_space.n
logger.info('obs_dim {}, act_dim {}'.format(obs_dim, act_dim))
# set action_shape = 0 while in discrete control environment
rpm = ReplayMemory(MEMORY_SIZE, obs_dim, 0)
# build an agent
model = CartpoleModel(obs_dim=obs_dim, act_dim=act_dim)
alg = DQN(model, gamma=GAMMA, lr=LEARNING_RATE)
agent = CartpoleAgent(
alg, act_dim=act_dim, e_greed=0.1, e_greed_decrement=1e-6)
# warmup memory
while len(rpm) < MEMORY_WARMUP_SIZE:
run_train_episode(agent, env, rpm)
max_episode = args.max_episode
# start training
episode = 0
while episode < max_episode:
# train part
for i in range(50):
total_reward = run_train_episode(agent, env, rpm)
episode += 1
# test part
eval_reward = run_evaluate_episodes(agent, render=False)
logger.info('episode:{} e_greed:{} Test reward:{}'.format(
episode, agent.e_greed, eval_reward))
# save the parameters to ./model.ckpt
save_path = './model.ckpt'
agent.save(save_path)
# save the model and parameters of policy network for inference
save_inference_path = './inference_model'
input_shapes = [[None, env.observation_space.shape[0]]]
input_dtypes = ['float32']
agent.save_inference_model(save_inference_path, input_shapes, input_dtypes)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--max_episode',
type=int,
default=800,
help='stop condition: number of max episode')
args = parser.parse_args()
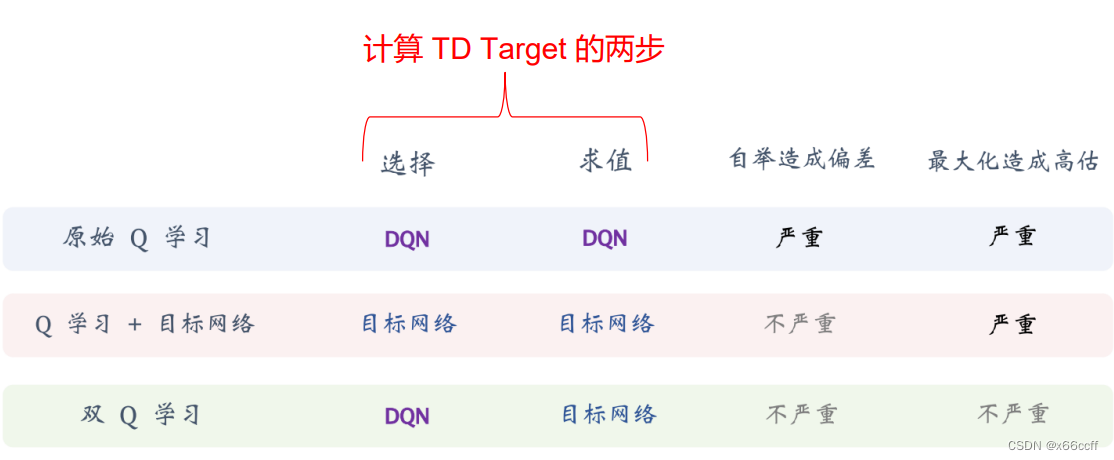
main()这段代码是一个使用深度强化学习算法DQN(Deep Q-Network)训练倒立摆(CartPole)问题的例子。倒立摆问题是强化学习中的一个经典问题,目标是通过在一维空间中移动车辆来保持其上方的杆保持直立。
代码的主要组成部分如下:
导入必要的库:导入PaddlePaddle的强化学习库PARL,以及其他必要的库如gym(用于环境模拟)、numpy等。
设置超参数:设置一些训练过程中用到的超参数,如学习频率、记忆库大小、批次大小、学习率等。
定义训练和评估函数:
run_train_episode:该函数用于训练一个回合,并返回总奖励。在每一步中,智能体根据当前状态选择动作,环境返回新的状态和奖励,然后将这些信息存储在回放记忆库中。当记忆库中的样本数量超过预热大小,并且步数是学习频率的倍数时,从记忆库中随机抽取一批样本进行训练。run_evaluate_episodes:该函数用于评估智能体的性能,运行指定数量的回合并返回平均奖励。
定义主函数:
- 初始化环境,并获取观测空间和动作空间的维度。
- 创建一个回放记忆库来存储经验。
- 构建一个智能体,包括DQN算法和一个策略网络。
- 使用一些随机样本对记忆库进行预热。
- 开始训练循环,每个循环包括一定数量的训练回合和一个评估阶段。
- 在训练过程中,智能体的贪婪度会逐渐减少,以鼓励探索。
- 保存训练好的模型参数和用于推理的模型。
解析命令行参数:使用argparse库解析命令行参数,这里主要是最大回合数。
运行主函数:如果此脚本是作为主程序运行,则调用
main()函数。
需要注意的是,这段代码中有一些拼写和格式错误,以及一些未定义的变量和函数(如CartpoleModel和CartpoleAgent),这些都需要在实际运行之前进行修正和定义。另外,args.max_episode在main()函数中被使用,但在这个函数的作用域内并没有定义,它应该是从命令行参数中解析得到的。因此,在main()函数开始之前,应该添加args = parser.parse_args()这一行来解析命令行参数。