深度强化学习(DRL)
本文是学习笔记,如有侵权,请联系删除。本文在ChatGPT辅助下完成。
参考链接
Deep Reinforcement Learning官方链接:https://github.com/wangshusen/DRL
源代码链接:https://github.com/DeepRLChinese/DeepRL-Chinese
文章目录
连续控制:确定策略网络DPG,TD3,随机高斯策略
连续控制
前面的内容全部都是离散控制,即动作空间是一个离散的集合,比如超级玛丽游戏中的动作空间 A = { 左,右,上 } A= \{ 左,右,上\} A={ 左,右,上} 就是个离散集合。本章的内容是连续控制,即动作空间是个连续集合,比如汽车的转向 A = [ − 4 0 ∘ , 4 0 ∘ ] A=[-40^{\circ},40^{\circ}] A=[−40∘,40∘]就是连续集合。如果把连续动作空间做离散化,那么离散控制的方法就能直接解决连续控制问题;先讨论连续集合的离散化。然而更好的办法是直接用连续控制方法,而非离散化之后借用离散控制方法。本章介绍两种连续控制方法:确定策略网络和随机策略网络。
ChatGPT对DPG的解释:
确定性策略梯度(Deterministic Policy Gradient,DPG)是强化学习中一种用于训练确定性策略的方法。与传统的随机策略不同,确定性策略直接映射状态到具体的动作,而不是输出一个动作的概率分布。DPG 主要应用于连续动作空间的问题,其中动作是实数空间中的连续值。
下面是 DPG 的基本思想和主要要素:
确定性策略: 在 DPG 中,智能体的策略是确定性的,即给定一个状态,它直接输出一个具体的动作。这样的确定性策略可以表示为 ( a = μ ( s ) a = \mu(s) a=μ(s)),其中 ( μ \mu μ) 是策略函数,输入为状态 (s),输出为动作 (a)。
值函数: DPG 使用值函数来评估策略的好坏。通常,包括状态值函数(State Value Function)和动作值函数(Action Value Function)。其中,状态值函数表示在给定状态下的期望累积回报,动作值函数表示在给定状态和动作的情况下的期望累积回报。
策略梯度: DPG 使用策略梯度方法来更新策略参数。策略梯度是关于策略参数的梯度,它告诉我们如何调整策略以最大化期望累积回报。在 DPG 中,通过对值函数对动作的梯度来计算策略梯度。
Actor-Critic 结构: DPG 通常采用 Actor-Critic 结构,其中包括一个 Actor 网络负责输出动作,一个 Critic 网络负责估计值函数。这两个网络共同工作,Actor 的参数通过 Critic 的估计值函数的梯度进行更新。
总体来说,DPG 的训练过程涉及通过策略梯度来调整 Actor 网络的参数,以最大化 Critic 网络估计的值函数。这样,DPG 可以在连续动作空间中有效地训练确定性策略。
离散控制与连续控制的区别
考虑这样一个问题:我们需要控制一只机械手臂,完成某些任务,获取奖励。机械手臂有两个关节,分别可以在 [0°,360°]与 [0°,180°] 的范围内转动。这个问题的自由度是 d = 2 d=2 d=2, 动作是二维向量,动作空间是连续集合 A = [ 0 , 360 ] × [ 0 , 180 ] A=[0,360]\times[0,180] A=[0,360]×[0,180]。
此前我们学过的强化学习方法全部都是针对离散动作空间,不能直接解决上述连续控制问题。想把此前学过的离散控制方法应用到连续控制上,必须要对连续动作空间做离散化 (网格化)。比如把连续集合 A = [ 0 , 360 ] × [ 0 , 180 ] \mathcal{A}=[0,360]\times[0,180] A=[0,360]×[0,180] 变成离散集合 A ′ = A^{\prime}= A′= { 0 , 20 , 40 , ⋯ , 360 } × { 0 , 20 , 40 , ⋯ , 180 } \{0,20,40,\cdots,360\}\times\{0,20,40,\cdots,180\} { 0,20,40,⋯,360}×{ 0,20,40,⋯,180}; 见图 10.1。

对动作空间做离散化之后,就可以应用之前学过的方法训练 DQN 或者策略网络,用于控制机械手臂。可是用离散化解决连续控制问题有个缺点。把自由度记作 d d d。自由度 d d d 越大,网格上的点就越多,而且数量随着 d d d 指数增长,会造成维度灾难。动作空间的大小即网格上点的数量。如果动作空间太大,DQN 和策略网络的训练都变得很困难,强化学习的结果会不好。上述离散化方法只适用于自由度 d d d 很小的情况;如果 d d d 不是很小, 就应该使用连续控制方法。后面两节介绍两种连续控制的方法。
确定策略梯度 (DPG)
确定策略梯度 (deterministic policy gradient, DPG) 是最常用的连续控制方法。DPG 是一种 actor-critic 方法,它有一个策略网络 (演员), 一个价值网络 (评委)。策略网络控制智能体做运动,它基于状态 s s s 做出动作 a a a。价值网络不控制智能体,只是基于状态 s s s 给动作 a a a 打分,从而指导策略网络做出改进。图 10.2 是两个神经网络的关系。
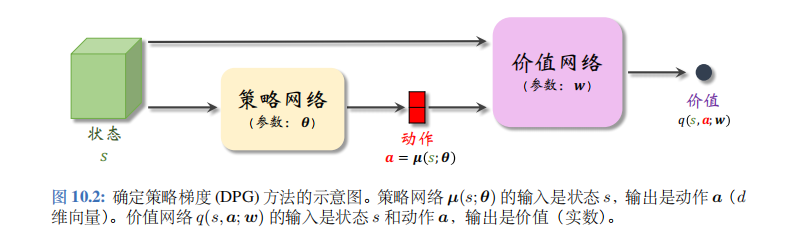
策略网络和价值网络
本节的策略网络不同于前面章节的策略网络。在之前章节里,策略网络 π ( a ∣ s ; θ ) \pi(a|s;\boldsymbol{\theta}) π(a∣s;θ) 是一个概率质量函数,它输出的是概率值。本节的确定策略网络 μ ( s ; θ ) \boldsymbol{\mu}(s;\boldsymbol{\theta}) μ(s;θ) 的输出是 d d d 维的向量 a a a,作为动作。两种策略网络一个是随机的,一个是确定性的:
之前章节中的策略网络 π ( a ∣ s ; θ ) \pi(a|s;\boldsymbol{\theta}) π(a∣s;θ) 带有随机性:给定状态 s s s, 策略网络输出的是离散动作空间 A \mathcal{A} A 上的概率分布; A \mathcal{A} A 中的每个元素 (动作) 都有一个概率值。智能体依据概率分布,随机从 A A A 中抽取一个动作,并执行动作。
本节的确定策略网络没有随机性:对于确定的状态 s s s, 策略网络 μ \mu μ 输出的动作 a a a 是确定的。动作 a a a 直接是 μ \mu μ 的输出,而非随机抽样得到的。
确定策略网络 μ \mu μ的结构如图 10.3 所示。如果输入的状态 s s s 是个矩阵或者张量 (例如图片、视频),那么 μ \mu μ 就由若干卷积层、全连接层等组成。
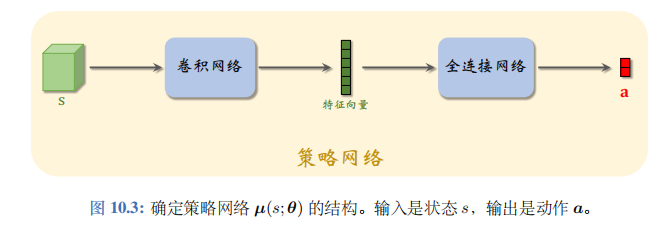
确定策略可以看做是随机策略的一个特例。确定策略 μ ( s ; θ ) \mu(s;\theta) μ(s;θ) 的输出是 d d d 维向量,它的第 i i i 个元素记作 μ ^ i = [ μ ( s ; θ ) ] i \widehat{\mu}_i=\left[\boldsymbol{\mu}(s;\boldsymbol{\theta})\right]_i μ i=[μ(s;θ)]i。定义下面这个随机策略:
$ π ( a ∣ s ; θ , σ ) = ∏ i = 1 d 1 6.28 σ i ⋅ exp ( − [ a i − μ ^ i ] 2 2 σ i 2 ) . ( 10.1 ) \pi(\boldsymbol{a}|s;\boldsymbol{\theta},\boldsymbol{\sigma})=\prod\limits_{i=1}^d\frac{1}{\sqrt{6.28}\sigma_i}\cdot\exp\bigg(-\frac{\big[a_i-\widehat{\mu}_i\big]^2}{2\sigma_i^2}\bigg). \quad{(10.1)} π(a∣s;θ,σ)=i=1∏d6.28σi1⋅exp(−2σi2[ai−μ i]2).(10.1)
这个随机策略是均值为 μ ( s ; θ ) \mu(s;\theta) μ(s;θ)、协方差矩阵为 diag ( σ 1 , ⋯ , σ d ) (\sigma_1,\cdots,\sigma_d) (σ1,⋯,σd) 的多元正态分布。本节的确定策略可以看做是上述随机策略在 σ = [ σ 1 , ⋯ , σ d ] \sigma=[\sigma_1,\cdots,\sigma_d] σ=[σ1,⋯,σd] 为全零向量时的特例。
本节的价值网络 q ( s , a ; w ) q(s,a;w) q(s,a;w) 是对动作价值函数 Q π ( s , a ) Q_\pi(s,\boldsymbol{a}) Qπ(s,a) 的近似。价值网络的结构如图 10.4 所示。价值网络的输入是状态 s s s 和动作 a a a ,输出的价值 q ^ = q ( s , a ; w ) \widehat{q}=q(s,a;w) q =q(s,a;w) 是个实数, 可以反映动作的好坏;动作 a a a 越好,则价值 q ^ \hat{q} q^就越大。所以价值网络可以评价策略网络的表现。在训练的过程中,价值网络帮助训练策略网络;在训练结束之后,价值网络就被丢弃,由策略网络控制智能体。
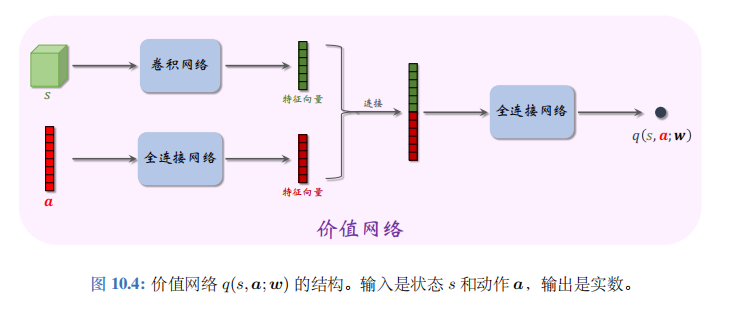
算法推导
用行为策略收集经验:
本节的确定策略网络属于异策略(off-policy) 方法,即行为策略 (behavior policy) 可以不同于目标策略 (target policy)。目标策略即确定策略网络 μ ( s ; θ n o w ) \mu(s;\theta_\mathrm{now}) μ(s;θnow),其中 θ n o w \theta_\mathrm{now} θnow 是策略网络最新的参数。行为策略可以是任意的,比如
a = μ ( s ; θ o l d ) + ϵ . a\:=\:\mu(s;\theta_{\mathrm{old}})+\epsilon. a=μ(s;θold)+ϵ.
公式的意思是行为策略可以用过时的策略网络参数,而且可以往动作中加入噪声 ϵ ∈ R d \epsilon\in\mathbb{R}^d ϵ∈Rd。异策略的好处在于可以把收集经验与训练神经网络分割开;把收集到的经验存入经验回放数组(replay buffer),在做训练的时候重复利用收集到的经验。见图 10.5。
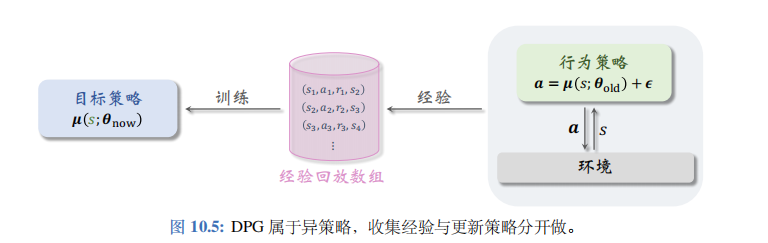
用行为策略控制智能体与环境交互,把智能体的轨迹(trajectory) 整理成 ( s t , a t , r t (s_t,a_t,r_t (st,at,rt, s t + 1 ) s_{t+1}) st+1) 这样的四元组,存入经验回放数组。在训练的时候,随机从数组中抽取一个四元组, 记作 ( s j , a j , r j , s j + 1 ) (s_j,\boldsymbol{a}_j,r_j,s_{j+1}) (sj,aj,rj,sj+1)。在训练策略网络 μ ( s ; θ ) \mu(s;\boldsymbol{\theta}) μ(s;θ) 的时候,只用到状态 s j s_j sj。在训练价值网络 q ( s , a ; w ) q(s,\boldsymbol{a};\boldsymbol{w}) q(s,a;w) 的时候,要用到四元组中全部四个元素: s j , a j , r j , s j + 1 s_j,\boldsymbol{a}_j,r_j,s_{j+1} sj,aj,rj,sj+1。
训练策略网络:
首先通俗解释训练策略网络的原理。如图 10.6 所示,给定状态 s s s,策略网络输出一个动作 a = μ ( s ; θ ) a=\mu(s;\theta) a=μ(s;θ),然后价值网络会给 a a a 打一个分数: q ^ = q ( s , a ; w ) \widehat{q}=q(s,a;\boldsymbol{w}) q =q(s,a;w)。
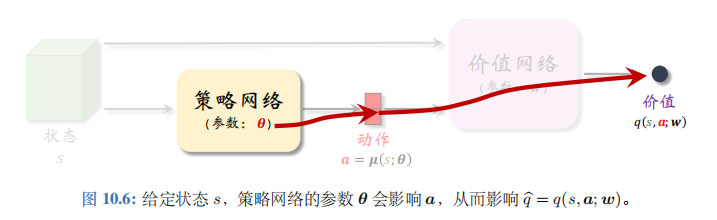
参数 θ \theta θ 影响 a a a, 从而影响 q ^ \widehat{q} q 。分数 q ^ \widehat{q} q 可以反映出 θ \theta θ 的好坏程度。训练策略网络的目标就是改进参数 θ \theta θ,使 q ^ \widehat{q} q 变得更大。把策略网络看做演员,价值网络看做评委。训练演员(策略网络)的目的就是让他迎合评委 (价值网络) 的喜好,改变自己的表演技巧 (即参数 θ \theta θ), 使得评委打分 q ^ \widehat{q} q 的均值更高。
根据以上解释,我们来推导目标函数。如果当前状态是 s s s, 那么价值网络的打分就是:
q ( s , μ ( s ; θ ) ; w ) . q(s,\boldsymbol{\mu}(s;\boldsymbol{\theta});\boldsymbol{w}). q(s,μ(s;θ);w).
我们希望打分的期望尽量高,所以把目标函数定义为打分的期望:
J ( θ ) = E S [ q ( S , μ ( S ; θ ) ; w ) ] . J(\boldsymbol{\theta})=\mathbb{E}_{S}\Big[q(S,\boldsymbol{\mu}(S;\boldsymbol{\theta});\boldsymbol{w})\Big]. J(θ)=ES[q(S,μ(S;θ);w)].
关于状态 S S S 求期望消除掉了 S S S 的影响;不管面对什么样的状态 S S S, 策略网络(演员)都应该做出很好的动作,使得平均分 J ( θ ) J(\theta) J(θ) 尽量高。策略网络的学习可以建模成这样一个最大化问题:
max θ J ( θ ) . \max_{\theta}\:J(\boldsymbol{\theta}). θmaxJ(θ).
注意,这里我们只训练策略网络,所以最大化问题中的优化变量是策略网络的参数 θ \theta θ,而价值网络的参数 w w w 被固定住。
可以用梯度上升来增大 J ( θ ) J(\boldsymbol{\theta}) J(θ)。每次用随机变量 S S S 的一个观测值(记作 s j s_j sj) 来计算梯度:
g j ≜ ∇ θ q ( s j , μ ( s j ; θ ) ; w ) . \boldsymbol{g}_{j}\:\triangleq\:\nabla_{\boldsymbol{\theta}}q(s_{j},\:\boldsymbol{\mu}(s_{j};\boldsymbol{\theta});\:\boldsymbol{w}). gj≜∇θq(sj,μ(sj;θ);w).
它是 ∇ θ J ( θ ) \nabla_{\theta}J(\theta) ∇θJ(θ) 的无偏估计。 g j g_j gj 叫做确定策略梯度 (deterministic policy gradient), 缩写DPG。
可以用链式法则求出梯度 g j g_j gj。复习一下链式法则。如果有这样的函数关系 : θ → a → :\theta\to a\to :θ→a→ q q q,那么 q q q 关于 θ \theta θ 的导数可以写成
∂ q ∂ θ = ∂ a ∂ θ ⋅ ∂ q ∂ a \frac{\partial\:q}{\partial\:\theta}\:=\:\frac{\partial\:a}{\partial\:\theta}\cdot\frac{\partial\:q}{\partial\:a} ∂θ∂q=∂θ∂a⋅∂a∂q
价值网络的输出与 θ \theta θ的函数关系如图 10.6 所示。应用链式法则,我们得到下面的定理。
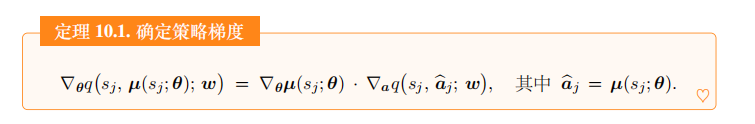
定理 10.1. 确定策略梯度
∇ θ q ( s j , μ ( s j ; θ ) ; w ) = ∇ θ μ ( s j ; θ ) ⋅ ∇ a q ( s j a ^ j ; w ) , 其中 a ^ j = μ ( s j ; θ ) . ♡ \nabla_{\theta }q(s_j,\:\mu(s_j;\boldsymbol{\theta});\:\boldsymbol{w})\:=\:\nabla_{\theta}\boldsymbol{\mu}(s_j;\boldsymbol{\theta})\:\cdot\:\nabla_{\boldsymbol{a}}q(s_j\:\widehat{\boldsymbol{a}}_j;\:\boldsymbol{w}),\quad\text{其中}\:\widehat{\boldsymbol{a}}_j\:=\:\boldsymbol{\mu}(s_j;\boldsymbol{\theta}).\quad\color{red}{\heartsuit} ∇θq(sj,μ(sj;θ);w)=∇θμ(sj;θ)⋅∇aq(sja
j;w),其中a
j=μ(sj;θ).♡
由此我们得到更新 θ \theta θ 的算法。每次从经验回放数组里随机抽取一个状态,记作 s j s_j sj。计算 a ^ j = μ ( s j ; θ ) \widehat{a}_j=\mu(s_j;\boldsymbol{\theta}) a
j=μ(sj;θ)。用梯度上升更新一次 θ \theta θ:
θ ← θ + β ⋅ ∇ θ μ ( s j ; θ ) ⋅ ∇ a q ( s j , a ^ j ; w ) . \boxed{\quad\boldsymbol{\theta}\:\leftarrow\:\boldsymbol{\theta}\:+\:\boldsymbol{\beta}\:\cdot\:\nabla_{\boldsymbol{\theta}}\boldsymbol{\mu}(s_{j};\boldsymbol{\theta})\:\cdot\:\nabla_{\boldsymbol{a}}q(s_{j},\:\widehat{\boldsymbol{a}}_{j};\:\boldsymbol{w}).} θ←θ+β⋅∇θμ(sj;θ)⋅∇aq(sj,a
j;w).
此处的 β \beta β 是学习率,需要手动调。这样做梯度上升,可以逐渐让目标函数 J ( θ ) J(\theta) J(θ) 增大,也就是让评委给演员的平均打分更高。
训练价值网络 :
首先通俗解释训练价值网络的原理。训练价值网络的目标是让价值网络 q ( s , a ; w ) q(s,\boldsymbol{a};\boldsymbol{w}) q(s,a;w) 的预测越来越接近真实价值函数 Q π ( s , a ) Q_\pi(s,\boldsymbol{a}) Qπ(s,a)。如果把价值网络看做评委,那么训练评委的目标就是让他的打分越来越准确。每一轮训练都要用到一个实际观测的奖励 r r r,可以把 r r r看做“真理”,用它来校准评委的打分。
训练价值网络要用 TD 算法。这里的 TD 算法与之前学过的标准 actor-critic 类似,都是让价值网络去拟合 TD 目标。每次从经验回放数组中取出一个四元组 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1), 用它更新一次参数 w w w。首先让价值网络做预测:
q ^ j = q ( s j , a j ; w ) 和 q ^ j + 1 = q ( s j + 1 , μ ( s j + 1 ; θ ) ; w ) \widehat q_{j}\:=\:q(s_{j},\boldsymbol{a}_{j};\boldsymbol{w})\quad\text{和}\quad\widehat q_{j+1}=q(s_{j+1},\boldsymbol{\mu}(s_{j+1};\boldsymbol{\theta});\boldsymbol{w}) q j=q(sj,aj;w)和q j+1=q(sj+1,μ(sj+1;θ);w)
计算 TD 目标 y ^ j = r j + γ ⋅ g ^ j + 1 \widehat{y}_j=r_j+\gamma\cdot\widehat{g}_{j+1} y j=rj+γ⋅g j+1。定义损失函数
L ( w ) = 1 2 [ q ( s j , a j ; w ) − y ^ j ] 2 , L(\boldsymbol{w})\:=\:\frac{1}{2}\Big[q(s_{j},\boldsymbol{a}_{j};\:\boldsymbol{w})-\widehat{y}_{j}\Big]^{2}, L(w)=21[q(sj,aj;w)−y j]2,
计算梯度
∇ w L ( w ) = ( q ^ j − y ^ j ) ⏟ T D 误差 δ j ⋅ ∇ w q ( s j , a j ; w ) , \nabla_{\boldsymbol{w}}L\big(\boldsymbol{w}\big)\:=\:\underbrace{\left(\widehat{q}_{j}-\widehat{y}_{j}\right)}_{\mathrm{TD~}\text{误差 }\delta_{j}}\cdot\nabla_{\boldsymbol{w}}q\big(s_{j},a_{j};\boldsymbol{w}\big), ∇wL(w)=TD 误差 δj (q j−y j)⋅∇wq(sj,aj;w),
做一轮梯度下降更新参数 w : w: w:
w ← w − α ⋅ ∇ w L ( w ) . w\:\leftarrow\:w-\alpha\cdot\nabla_{\boldsymbol{w}}L(\boldsymbol{w}). w←w−α⋅∇wL(w).
这样可以让损失函数 L ( w ) L(w) L(w) 减小,也就是让价值网络的预测 q ^ j = q ( s , a ; w ) \widehat{q}_j=q(s,\boldsymbol{a};\boldsymbol{w}) q j=q(s,a;w) 更接近 TD 目标 y ^ j \widehat{y}_j y j。公式中的 α \alpha α 是学习率,需要手动调。
训练流程 :
做训练的时候,可以同时对价值网络和策略网络做训练。每次从经验回放数组中抽取一个四元组,记作 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1)。把神经网络当前参数记作 w n o w w_\mathrm{now} wnow 和 θ n o w \theta_\mathrm{now} θnow。执行以下步骤更新策略网络和价值网络:
- 让策略网络做预测:
a ^ j = μ ( s j ; θ n o w ) 和 a ^ j + 1 = μ ( s j + 1 ; θ n o w ) . \widehat{\boldsymbol{a}}_{j}=\boldsymbol{\mu}\big(s_{j};\boldsymbol{\theta}_{\mathrm{now}}\big)\quad\text{和}\quad\widehat{\boldsymbol{a}}_{j+1}=\boldsymbol{\mu}\big(s_{j+1};\boldsymbol{\theta}_{\mathrm{now}}\big). a j=μ(sj;θnow)和a j+1=μ(sj+1;θnow).
注 计算动作 a ^ j \widehat{a}_j a j用的是当前的策略网络 μ ( s j ; θ n o w ) \mu(s_j;\theta_\mathrm{now}) μ(sj;θnow),用 a ^ j \widehat{a}_j a j 来更新 θ n o w \theta_\mathrm{now} θnow: 而从经验回放数组中抽取的 a j a_j aj 则是用过时的策略网络 μ ( s j ; θ o l d ) \mu(s_j;\theta_\mathrm{old}) μ(sj;θold) 算出的,用 a j a_j aj 来更新 w n o w w_\mathrm{now} wnow 。请注意 a ^ j \hat{a}_j a^j 与 a j a_j aj 的区别。
- 让价值网络做预测:
q ^ j = q ( s j , a j ; w n o w ) 和 q ^ j + 1 = q ( s j + 1 , a j + 1 ^ ; w n o w ) . \widehat q_{j}\:=\:q(s_{j},\boldsymbol{a_{j}};\boldsymbol{w_{\mathrm{now}}})\quad\text{和}\quad\widehat q_{j+1}\:=\:q(s_{j+1},\widehat{\boldsymbol{a_{j+1}}};\boldsymbol{w_{\mathrm{now}}}). q j=q(sj,aj;wnow)和q j+1=q(sj+1,aj+1 ;wnow).
- 计算 TD 目标和 TD 误差:
y ^ j = r j + γ ⋅ q ^ j + 1 和 δ j = q ^ j − y ^ j . \widehat y_{j}\:=\:r_{j}+\gamma\cdot\widehat q_{j+1}\quad\text{和}\quad\delta_{j}\:=\:\widehat q_{j}-\widehat y_{j}. y j=rj+γ⋅q j+1和δj=q j−y j.
- 更新价值网络:
w n e w ← w n o w − α ⋅ δ j ⋅ ∇ w q ( s j , a j ; w n o w ) . \boldsymbol{w_\mathrm{new}}\:\leftarrow\:\boldsymbol{w_\mathrm{now}}-\alpha\cdot\delta_{j}\cdot\nabla_{\boldsymbol{w}}q(s_{j},\boldsymbol{a_{j}};\boldsymbol{w_\mathrm{now}}). wnew←wnow−α⋅δj⋅∇wq(sj,aj;wnow).
- 更新策略网络:
θ n e w ← θ n o w + β ⋅ ∇ θ μ ( s j ; θ n o w ) ⋅ ∇ a q ( s j , a ^ j ; w n o w ) . \boldsymbol{\theta}_{\mathrm{new}}\:\leftarrow\:\boldsymbol{\theta}_{\mathrm{now}}+\beta\cdot\nabla_{\boldsymbol{\theta}}\boldsymbol{\mu}(s_{j};\boldsymbol{\theta}_{\mathrm{now}})\:\cdot\:\nabla_{\boldsymbol{a}}q(s_{j},\:\widehat{\boldsymbol{a}}_{j};\:\boldsymbol{w}_{\mathrm{now}})\:. θnew←θnow+β⋅∇θμ(sj;θnow)⋅∇aq(sj,a j;wnow).
在实践中,上述算法的表现并不好;读者应当采用后面介绍的技巧训练策略网络和价值网络。
深入分析 DPG
上一节介绍的 DPG 是一种“四不像”的方法。DPG 乍看起来很像前面介绍的策略学习方法,因为 DPG 的目的是学习一个策略 μ \mu μ,而价值网络 q q q 只起辅助作用。然而 DPG 又很像之前介绍的 DQN, 两者都是异策略 (Off-policy), 而且两者存在高估问题。鉴于 DPG 的重要性,我们更深入分析 DPG。
从策略学习的角度看待 DPG

答案是动作价值函数 Q π ( s , a ) Q_\pi(s,a) Qπ(s,a)。上一节 DPG 的训练流程中,更新价值网络用到 TD 目标:
y ^ j = r j + γ ⋅ q ( s j + 1 , μ ( s j + 1 ; θ n o w ) ; w n o w ) . \widehat{y}_{j}\:=\:r_{j}\:+\:\gamma\:\cdot\:q\Big(s_{j+1},\:\boldsymbol{\mu}\left(s_{j+1};\boldsymbol{\theta}_{\mathrm{now}}\right);\:\boldsymbol{w}_{\mathrm{now}}\Big). y j=rj+γ⋅q(sj+1,μ(sj+1;θnow);wnow).
很显然,当前的策略 μ ( s ; θ n o w ) \mu(s;\theta_\mathrm{now}) μ(s;θnow) 会直接影响价值网络 q q q。策略不同,得到的价值网络 q q q 就不同。
虽然价值网络 q ( s , a ; w ) q(s,a;w) q(s,a;w) 通常是对动作价值函数 Q π ( s , a ) Q_\pi(s,\boldsymbol{a}) Qπ(s,a) 的近似,但是我们最终的目标是让 q ( s , a ; w ) q(s,\boldsymbol{a};\boldsymbol{w}) q(s,a;w) 趋近于最优动作价值函数 Q ⋆ ( s , a ) Q_\star(s,\boldsymbol{a}) Q⋆(s,a)。回忆一下,如果 π \pi π 是最优策略 π ⋆ \pi^{\star} π⋆, 那么 Q π ( s , a ) Q_{\pi}(s,\boldsymbol{a}) Qπ(s,a) 就等于 Q ⋆ ( s , a ) Q_{\star}(s,\boldsymbol{a}) Q⋆(s,a)。训练 DPG 的目的是让 μ ( s ; θ ) \mu(s;\boldsymbol{\theta}) μ(s;θ) 趋近于最优策略 π ⋆ \pi^{\star} π⋆ 那么理想情况下, q ( s , a ; w ) q(s,a;w) q(s,a;w) 最终趋近于 Q ⋆ ( s , a ) Q_\star(s,\boldsymbol{a}) Q⋆(s,a)。

答案是目标策略 μ ( s ; θ n o w ) \mu(s;\theta_\mathrm{now}) μ(s;θnow),因为目标策略对价值网络的影响很大。在理想情况下,行为策略对价值网络没有影响。我们用 TD 算法训练价值网络,TD 算法的目的在于鼓励价值网络的预测趋近于 TD 目标。理想情况下,
q ( s j , a j ; w ) = r j + γ ⋅ Q ( s j + 1 , μ ( s j + 1 ; θ n o w ) ; w n o w ) ⏟ TD 目标 , ∀ ( s j , a j , r j , s j + 1 ) . q(s_j,\boldsymbol{a}_j;\boldsymbol{w})\:=\:\underbrace{r_j\:+\:\gamma\:\cdot\:Q(s_{j+1},\:\boldsymbol{\mu}(s_{j+1};\boldsymbol{\theta}_{\mathrm{now}});\:\boldsymbol{w}_{\mathrm{now}})}_{\text{TD 目标}}\:,\quad\:\forall\:(s_j,\boldsymbol{a}_j,r_j,s_{j+1}). q(sj,aj;w)=TD 目标
rj+γ⋅Q(sj+1,μ(sj+1;θnow);wnow),∀(sj,aj,rj,sj+1).
在收集经验的过程中,行为策略决定了如何基于 s j s_j sj 生成 a j a_j aj,然而这不重要。上面的公式只希望等式左边去拟合等式右边,而不在乎 a j a_j aj 是如何生成的。
从价值学习的角度看待 DPG
假如我们知道最优动作价值函数 Q ⋆ ( s , a ; w ) Q_\star(s,a;\boldsymbol{w}) Q⋆(s,a;w),我们可以这样做决策:给定当前状态 s t s_t st,选择最大化 Q 值的动作
a t = a r g m a x a ∈ A Q ⋆ ( s t , a ) . a_{t}\:=\:\underset{a\in\mathcal{A}}{\mathrm{argmax}}\:Q_{\star}\big(s_{t},a\big). at=a∈AargmaxQ⋆(st,a).
DQN 记作 Q ( s , a ; w ) Q(s,a;w) Q(s,a;w),它是 Q ⋆ ( s , a ; w ) Q_{\star}(s,a;\boldsymbol{w}) Q⋆(s,a;w) 的函数近似。训练 DQN 的目的是让 Q ( s , a ; w ) Q(s,a;\boldsymbol{w}) Q(s,a;w) 趋近 Q ⋆ ( s , a ; w ) Q_\star(s,a;\boldsymbol{w}) Q⋆(s,a;w), ∀ s ∈ S , a ∈ A \forall s\in\mathcal{S},\:a\in\mathcal{A} ∀s∈S,a∈A。在训练好 DQN 之后,可以这样做决策:
a t = a r g m a x a ∈ A Q ( s t , a ; w ) . a_{t}\:=\:\mathop{\mathrm{argmax}}_{a\in\mathcal{A}}\:Q\big(s_{t},a;\:\boldsymbol{w}\big). at=argmaxa∈AQ(st,a;w).
如果动作空间 A A A 是离散集合,那么上述最大化很容易实现。可是如果 A A A 是连续集合,则很难对 Q Q Q求最大化。
可以把 DPG 看做对最优动作价值函数 Q ⋆ ( s , a ) Q_\star(s,\boldsymbol{a}) Q⋆(s,a) 的另一种近似方式,用于连续控制问题。我们希望学到策略网络 μ ( s ; θ ) \mu(s;\theta) μ(s;θ) 和价值网络 q ( s , a ; w ) q(s,a;\boldsymbol{w}) q(s,a;w), 使得
q ( s , μ ( s ; θ ) ; w ) ≈ max a ∈ A Q ⋆ ( s , a ) , ∀ s ∈ S . q\Big(s,\:\boldsymbol{\mu}(s;\boldsymbol{\theta});\:\boldsymbol{w}\Big)\:\approx\max_{\boldsymbol{a}\in\mathcal{A}}\:Q_{\star}(s,\boldsymbol{a}),\quad\forall\:s\in\mathcal{S}. q(s,μ(s;θ);w)≈a∈AmaxQ⋆(s,a),∀s∈S.
我们可以把 μ \mu μ 和 q q q 看做是 Q ⋆ Q_{\star} Q⋆ 的近似分解,而这种分解的目的在于方便做决策:
a t = μ ( s t ; θ ) ≈ a r g m a x a ∈ A Q ⋆ ( s t , a ) . \begin{array}{rcl}a_t&=&\boldsymbol{\mu}(s_t;\boldsymbol{\theta})\\&\approx&\mathop{\mathrm{argmax}}_{\boldsymbol{a}\in\mathcal{A}}Q_\star(s_t,\boldsymbol{a}).\end{array} at=≈μ(st;θ)argmaxa∈AQ⋆(st,a).
DPG 的高估问题
在之前的笔记 深度强化学习(王树森)笔记08-CSDN博客,我们讨过 DQN 的高估问题:如果用 Q 学习算法训练 DQN, 则 DQN 会高估真实最优价值函数 Q ⋆ Q_{\star} Q⋆。把 DQN 记作 Q ( s , a ; w ) Q(s,a;\boldsymbol{w}) Q(s,a;w)。如果用 Q 学习算法训练 DQN, 那么 TD 目标是
y ^ j = r j + γ ⋅ max a ∈ A Q ( s j + 1 , a ; w ) . \widehat{y}_{j}\:=\:r_{j}\:+\:\gamma\:\cdot\:\max_{a\in\mathcal{A}}\:Q\big(s_{j+1},a;\boldsymbol{w}\big). y
j=rj+γ⋅a∈AmaxQ(sj+1,a;w).
之前得出结论:如果 Q ( s , a ; w ) Q(s,a;\boldsymbol{w}) Q(s,a;w) 是最优动作价值函数 Q ⋆ ( s , a ) Q_\star(s,a) Q⋆(s,a) 的无偏估计,那么 y ^ j \widehat{y}_j y j 是对 Q ⋆ ( s j , a j ) Q_\star(s_j,a_j) Q⋆(sj,aj) 的高估。用 y ^ j \widehat{y}_j y j 作为目标去更新 DQN, 会导致 Q ( s j , a j ; w ) Q(s_j,a_j;\boldsymbol{w}) Q(sj,aj;w) 高估 Q ⋆ ( s j , a j ) Q_\star(s_j,a_j) Q⋆(sj,aj)。另一个结论是自举会导致高估的传播,造成高估越来越严重。
DPG 也存在高估问题,用上一节的算法训练出的价值网络 q ( s , a ; w ) q(s,a;w) q(s,a;w) 会高估真实动作价值 Q π ( s , a ) Q_\pi(s,\boldsymbol{a}) Qπ(s,a)。造成 DPG 高估的原因与 DQN 类似:第一,TD 目标是对真实动作价值的高估;第二,自举导致高估的传播。下面具体分析两个原因;如果读者不感兴趣,只需要记住上述结论即可,可以跳过下面的内容。
最大化造成高估:
训练策略网络的时候,我们希望策略网络计算出的动作 a ^ = \widehat{a}= a
= μ ( s ; θ ) \mu(s;\theta) μ(s;θ) 能得到价值网络尽量高的评价,也就是让 q ( s , a ^ ; w ) q(s,\widehat{a};w) q(s,a
;w) 尽量大。我们通过求解下面的优化模型来学习策略网络:
θ ⋆ = argmax θ E S [ q ( S , A ^ ; w ) ] , s . t . A ^ = μ ( S ; θ ) . \boldsymbol{\theta}^{\star}\:=\:\operatorname*{argmax}_{\boldsymbol{\theta}}\:\mathbb{E}_{S}\Big[\:q\big(S,\widehat{A};\boldsymbol{w}\big)\:\Big],\quad\:\mathrm{s.t.}\:\widehat{A}=\boldsymbol{\mu}(S;\boldsymbol{\theta}). θ⋆=θargmaxES[q(S,A
;w)],s.t.A
=μ(S;θ).
这个公式的意思是 μ ( s ; θ ⋆ ) \mu(s;\theta^\star) μ(s;θ⋆) 是最优的确定策略网络。 上面的公式与下面的公式意义相同(虽然不严格等价):
μ ( s ; θ ⋆ ) = a r g m a x a ∈ A q ( s , a ; w ) , ∀ s ∈ S . \boldsymbol{\mu}(s;\boldsymbol{\theta}^{\star})\:=\:\mathop{\mathrm{argmax}}_{\boldsymbol{a}\in\mathcal{A}}\:q(s,\boldsymbol{a};\boldsymbol{w})\:,\quad\forall\:s\in\mathcal{S}. μ(s;θ⋆)=argmaxa∈Aq(s,a;w),∀s∈S.
这个公式的意思也是 μ ( s ; θ ⋆ ) \mu(s;\theta^\star) μ(s;θ⋆) 是最优的确定策略网络。训练价值网络 q q q 时用的 TD 目标是
y ^ j = r j + γ ⋅ q ( s j + 1 , μ ( s j + 1 ; θ ) ; w ) ≈ r j + γ ⋅ max a j + 1 q ( s j + 1 , a j + 1 ; w ) . \begin{array}{rcl}\widehat{y}_{j}&=&r_{j}\:+\:\gamma\cdot q\Big(\:s_{j+1},\:\boldsymbol{\mu}(s_{j+1};\boldsymbol{\theta});\:\boldsymbol{w}\:\Big)\\&\approx&r_{j}\:+\:\gamma\cdot\max_{\boldsymbol{a}_{j+1}}q\big(\:s_{j+1},\:\boldsymbol{a}_{j+1};\:\boldsymbol{w}\:\big).\end{array} y j=≈rj+γ⋅q(sj+1,μ(sj+1;θ);w)rj+γ⋅maxaj+1q(sj+1,aj+1;w).
根据前面的分析,上面公式中的 max 会导致 y ^ j \widehat{y}_j y j 高估真实动作价值 Q π ( s j , a j ; w ) Q_\pi(s_j,a_j;\boldsymbol{w}) Qπ(sj,aj;w)。在训练 q q q 时,我们把 y ^ j \widehat{y}_j y j 作为目标,鼓励价值网络 q ( s j , a j ; w ) q(s_j,a_j;\boldsymbol{w}) q(sj,aj;w) 接近 y ^ j \widehat{y}_j y j, 这会导致 q ( s j , a j ; w ) q(s_j,a_j;\boldsymbol{w}) q(sj,aj;w) 高估真实动作价值。
自举造成偏差传播:
前面的笔记中讨论过自举(bootstrapping)造成偏差的传播。
TD 目标
y ^ j = r j + γ ⋅ q ( s j + 1 , μ ( s j + 1 ; θ ) ; w ) \widehat{y}_{j}\quad=\quad r_{j}\:+\:\gamma\cdot q\Big(\:s_{j+1},\:\boldsymbol{\mu}(s_{j+1};\boldsymbol{\theta})\:;\:\boldsymbol{w}\:\Big) y
j=rj+γ⋅q(sj+1,μ(sj+1;θ);w)
是用价值网络算出来的,而它又被用于更新价值网络 q q q 本身,这属于自举。假如价值网络 q ( s j + 1 , a j + 1 ; θ ) q(s_{j+1},a_{j+1};\theta) q(sj+1,aj+1;θ) 高估了真实动作价值 Q π ( s j + 1 , a j + 1 ) Q_\pi(s_{j+1},a_{j+1}) Qπ(sj+1,aj+1),那么 TD 目标 y ^ j \widehat{y}_j y j 则是对 Q π ( s j , a j ) Q_\pi(s_j,a_j) Qπ(sj,aj) 的高估,这会导致 q ( s j , a j ; w ) q(s_j,a_j;\boldsymbol{w}) q(sj,aj;w) 高估 Q π ( s j , a j ) Q_\pi(s_j,\boldsymbol{a}_j) Qπ(sj,aj)。自举让高估从 ( s j + 1 , a j + 1 ) (s_{j+1},\boldsymbol{a}_{j+1}) (sj+1,aj+1) 传播到 ( s j , a j ) (s_j,\boldsymbol{a}_j) (sj,aj)。
双延时确定策略梯度 (TD3)
由于存在高估等问题,DPG 实际运行的效果并不好。本节介绍的 Twin Delayed Deep Deterministic Policy Gradient (TD3) 可以大幅提升算法的表现,把策略网络和价值网络训练得更好。注意,本节只是改进训练用的算法,并不改变神经网络的结构。
高估问题的解决方案
解决方案——目标网络:
为了解决自举和最大化造成的高估,我们需要使用目标网络 (Target Networks) 计算 TD 目标 y ^ j \widehat{y}_j y
j。训练中需要两个目标网络:
q ( s , a ; w − ) 和 μ ( s ; θ − ) . q(s,\boldsymbol{a};\boldsymbol{w}^{-})\quad\text{和}\quad\boldsymbol{\mu}(s;\boldsymbol{\theta}^{-}). q(s,a;w−)和μ(s;θ−).
它们与价值网络、策略网络的结构完全相同,但是参数不同。TD 目标是用目标网络算的:
y ^ j = r j + γ ⋅ q ( s j + 1 , a ^ j + 1 ; w − ) , 其中 a ^ j + 1 = μ ( s j + 1 ; θ − ) . \widehat{y}_{j}\:=\:r_{j}\:+\:\gamma\cdot q\big(s_{j+1},\:\widehat{\boldsymbol{a}}_{j+1};\:\boldsymbol{w}^{-}\big),\quad\:\text{其中}\:\widehat{\boldsymbol{a}}_{j+1}\:=\:\mu\big(s_{j+1};\:\boldsymbol{\theta}^{-}\big). y j=rj+γ⋅q(sj+1,a j+1;w−),其中a j+1=μ(sj+1;θ−).
把 y ^ j \widehat{y}_j y j作为目标,更新 w \boldsymbol{w} w,鼓励 q ( s j , a j ; w ) q(s_j,a_j;\boldsymbol{w}) q(sj,aj;w) 接近 y ^ j \widehat{y}_j y j。四个神经网络之间的关系如图 10.7所示。
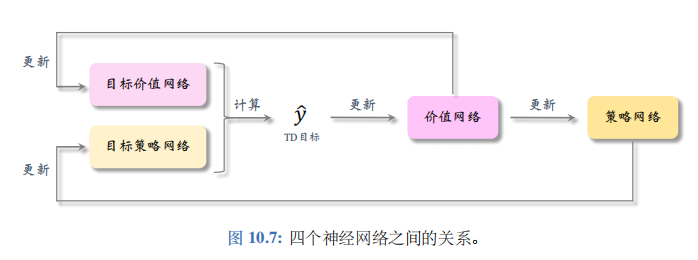
这种方法可以在一定程度上缓解高估,但是实验表明高估仍然很严重。
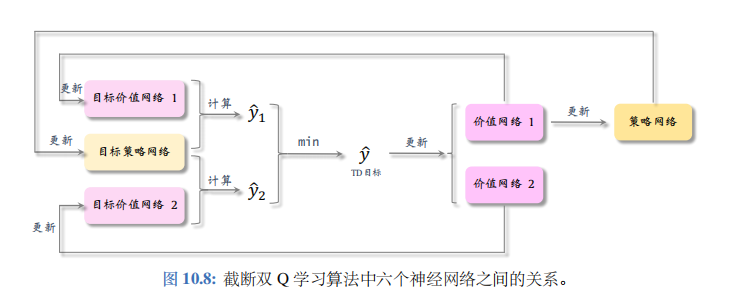
更好的解决方案——截断双 Q 学习 (clipped double Q-learning):
这种方法使用两个价值网络和一个策略网络:
q ( s , a ; w 1 ) , q ( s , a ; w 2 ) , μ ( s ; θ ) . q(s,\boldsymbol{a};\boldsymbol{w}_{1}),\quad q(s,\boldsymbol{a};\boldsymbol{w}_{2}),\quad\boldsymbol{\mu}(s;\boldsymbol{\theta}). q(s,a;w1),q(s,a;w2),μ(s;θ).
三个神经网络各对应一个目标网络:
q ( s , a ; w 1 − ) , q ( s , a ; w 2 − ) , μ ( s ; θ − ) . q(s,\boldsymbol{a};\boldsymbol{w}_1^-),\quad q(s,\boldsymbol{a};\boldsymbol{w}_2^-),\quad\boldsymbol{\mu}(s;\boldsymbol{\theta}^-). q(s,a;w1−),q(s,a;w2−),μ(s;θ−).
用目标策略网络计算动作:
a ^ j + 1 − = μ ( s j + 1 ; θ − ) , \widehat a_{j+1}^{-}\:=\:\mu(s_{j+1};\boldsymbol{\theta}^{-}), a
j+1−=μ(sj+1;θ−),
然后用两个目标价值网络计算:
y ^ j , 1 = r j + γ ⋅ q ( s j + 1 , a ^ j + 1 − ; w 1 − ) , y ^ j , 2 = r j + γ ⋅ q ( s j + 1 , a ^ j + 1 − ; w 2 − ) . \begin{array}{rcl}{ {\widehat y_{j,1}}}&{=}&{ {r_{j}\:+\:\gamma\cdot q\big(s_{j+1},\:\widehat a_{j+1}^{-};\:\boldsymbol w_{1}^{-}\big),}}\\{ {\widehat y_{j,2}}}&{=}&{ {r_{j}\:+\:\gamma\cdot q\big(s_{j+1},\:\widehat a_{j+1}^{-};\:\boldsymbol w_{2}^{-}\big).}}\end{array} y
j,1y
j,2==rj+γ⋅q(sj+1,a
j+1−;w1−),rj+γ⋅q(sj+1,a
j+1−;w2−).
取两者较小者为TD 目标:
y ^ j = min { y ^ j , 1 , y ^ j , 2 } . \widehat{y}_{j}\:=\:\operatorname*{min}\Big\{\widehat{y}_{j,1}\:,\:\widehat{y}_{j,2}\Big\}. y
j=min{ y
j,1,y
j,2}.
截断双 Q 学习中的六个神经网络的关系如图 10.8 所示。
其他改进方法
可以在截断双 Q 学习算法的基础上做两处小的改进、进一步提升算法的表现。两种改进分别是往动作中加噪声、减小更新策略网络和目标网络的频率。
往动作中加噪声:
上一小节中截断双 Q 学习用目标策略网络计算动作 : a ^ j + 1 − = :\hat{a}_{j+1}^{-}= :a^j+1−= μ ( s j + 1 ; θ − ) \mu(s_{j+1};\theta^-) μ(sj+1;θ−)。把这一步改成:
a ^ j + 1 − = μ ( s j + 1 ; θ − ) + ξ . \widehat a_{j+1}^{-}\:=\:\mu(s_{j+1};\theta^{-})\:+\:\xi. a
j+1−=μ(sj+1;θ−)+ξ.
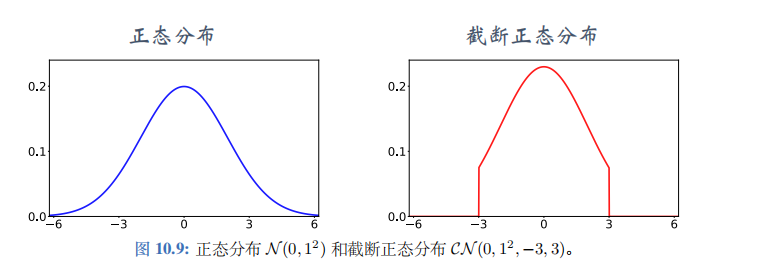
公式中的 ξ \xi ξ是个随机向量,表示噪声,它的每一个元素独立随机从截断正态分布 (clipped normal distribution) 中抽取。把截断正态分布记作 C N ( 0 , σ 2 , − c , c ) \mathcal{CN}(0,\sigma^2,-c,c) CN(0,σ2,−c,c),意思是均值为零,标准差为 σ \sigma σ 的正态分布,但是变量落在区间 [ − c , c ] [-c,c] [−c,c] 之外的概率为零。正态分布与截断正态分布的对比如图 10.9 所示。使用截断正态分布,而非正态分布,是为了防止噪声 ξ \xi ξ 过大。使用截断,保证噪声大小不会超过 − c -c −c 和 c c c。
减小更新策略网络和目标网络的频率 :
Actor-critic 用价值网络来指导策略网络的更新。如果价值网络 q q q 本身不可靠,那么用价值网络 q q q 给动作打的分数是不准确的,无助于改进策略网络 μ \mu μ。在价值网络 q q q 还很差的时候就急于更新 μ \mu μ, 非但不能改进 μ \mu μ,反而会由于 μ \mu μ 的变化导致 q q q 的训练不稳定。
实验表明,应当让策略网络 μ \mu μ 以及三个目标网络的更新慢于价值网络 q q q。传统的actor-critic 的每一轮训练都对策略网络、价值网络、以及目标网络做一次更新。更好的方法是每一轮更新一次价值网络,但是每隔 k k k 轮更新一次策略网络和三个目标网络。 k k k 是超参数,需要调。
训练流程
本节介绍了三种技巧,改进 DPG 的训练。第一,用截断双 Q 学习,缓解价值网络的高估。第二,往目标策略网络中加噪声,起到平滑作用。第三,降低策略网络和三个目标网络的更新频率。使用这三种技巧的算法被称作双延时确定策略梯度 (twin delayed deep deterministic policy gradient), 缩写是 TD3。
TD3 与 DPG 都属于异策略 (off-policy), 可以用任意的行为策略收集经验,事后做经验回放训练策略网络和价值网络。收集经验的方式与原始的训练算法相同,用 a t = a_t= at= μ ( s t ; θ ) + ϵ \boldsymbol{\mu}(s_t;\boldsymbol{\theta})+\boldsymbol{\epsilon} μ(st;θ)+ϵ 与环境交互,把观测到的四元组 ( s t , a t , r t , s t + 1 ) (s_t,\boldsymbol{a}_t,r_t,s_{t+1}) (st,at,rt,st+1) 存入经验回放数组。
初始的时候,策略网络和价值网络的参数都是随机的。这样初始化目标网络的参数:
w 1 − ← w 1 , w 2 − ← w 2 , θ − ← θ . w_1^-\:\leftarrow\:w_1,\quad\:w_2^-\:\leftarrow\:w_2,\quad\:\theta^-\:\leftarrow\:\theta. w1−←w1,w2−←w2,θ−←θ.
训练策略网络和价值网络的时候,每次从数组中随机抽取一个四元组,记作 ( s j , a j , r j , s j + 1 ) (s_j,a_j,r_j,s_{j+1}) (sj,aj,rj,sj+1)。用下标 now 表示神经网络当前的参数,用下标 new 表示更新后的参数。然后执行下面的步骤,更新价值网络、策略网络、目标网络。
让目标策略网络做预测 : a ^ j + 1 − = μ ( s j + 1 ; θ n o w − ) + ξ :\hat{a}_{j+1}^-=\mu(s_{j+1};\theta_\mathrm{now}^-)+\xi :a^j+1−=μ(sj+1;θnow−)+ξ。其中向量 ξ \xi ξ的每个元素都独立从截断正态分布 C N ( 0 , σ 2 , − c , c ) \mathcal{CN}(0,\sigma^2,-c,c) CN(0,σ2,−c,c) 中抽取。
让两个目标价值网络做预测:
q ^ 1 , j + 1 − = q ( s j + 1 , a ^ j + 1 − ; w 1 , n o w − ) 和 q ^ 2 , j + 1 − = q ( s j + 1 , a ^ j + 1 − ; w 2 , n o w − ) . \widehat{q}_{1,j+1}^{-}\:=\:q\big(s_{j+1},\widehat{a}_{j+1}^{-};\boldsymbol{w}_{1,\mathrm{now}}^{-}\big)\quad\text{和}\quad\widehat{q}_{2,j+1}^{-}\:=\:q\big(s_{j+1},\widehat{\boldsymbol{a}}_{j+1}^{-};\boldsymbol{w}_{2,\mathrm{now}}^{-}\big)\:. q 1,j+1−=q(sj+1,a j+1−;w1,now−)和q 2,j+1−=q(sj+1,a j+1−;w2,now−).
- 计算 TD 目标:
y ^ j = r j + γ ⋅ min { q ^ 1 , j + 1 , q ^ 2 , j + 1 } . \widehat y_{j}\:=\:r_{j}\:+\:\gamma\:\cdot\:\operatorname*{min}\Big\{\:\widehat q_{1,j+1}\:,\:\widehat q_{2,j+1}\:\Big\}. y j=rj+γ⋅min{ q 1,j+1,q 2,j+1}.
- 让两个价值网络做预测:
q ^ 1 , j = q ( s j , a j ; w 1 , n o w ) 和 q ^ 2 , j = q ( s j , a j ; w 2 , n o w ) . \widehat q_{1,j}\:=\:q(s_{j},\boldsymbol{a}_{j};\boldsymbol{w}_{1,\mathrm{now}})\quad\text{和}\quad\widehat q_{2,j}\:=\:q(s_{j},\boldsymbol{a}_{j};\boldsymbol{w}_{2,\mathrm{now}}). q 1,j=q(sj,aj;w1,now)和q 2,j=q(sj,aj;w2,now).
- 计算 TD 误差:
δ 1 , j = q ^ 1 , j − y ^ j 和 δ 2 , j = q ^ 2 , j − y ^ j . \delta_{1,j}\:=\:\widehat q_{1,j}\:-\:\widehat y_{j}\quad\text{和}\quad\delta_{2,j}\:=\:\widehat q_{2,j}\:-\:\widehat y_{j}. δ1,j=q 1,j−y j和δ2,j=q 2,j−y j.
- 更新价值网络:
w 1 , n e w ← w 1 , n o w − α ⋅ δ 1 , j ⋅ ∇ w q ( s j , a j ; w 1 , n o w ) , w 2 , n e w ← w 2 , n o w − α ⋅ δ 2 , j ⋅ ∇ w q ( s j , a j ; w 2 , n o w ) . \begin{array}{rcl}w_{1,\mathrm{new}}&\leftarrow&w_{1,\mathrm{now}}-\alpha\cdot\delta_{1,j}\cdot\nabla_{\boldsymbol{w}}q\big(s_{j},\boldsymbol{a}_{j};\boldsymbol{w}_{1,\mathrm{now}}\big),\\w_{2,\mathrm{new}}&\leftarrow&\boldsymbol{w}_{2,\mathrm{now}}-\alpha\cdot\delta_{2,j}\cdot\nabla_{\boldsymbol{w}}q\big(s_{j},\boldsymbol{a}_{j};\boldsymbol{w}_{2,\mathrm{now}}\big).\end{array} w1,neww2,new←←w1,now−α⋅δ1,j⋅∇wq(sj,aj;w1,now),w2,now−α⋅δ2,j⋅∇wq(sj,aj;w2,now).
- 每隔 k k k 轮更新一次策略网络和三个目标网络:
- 让策略网络做预测 : a ^ j = μ ( s j ; θ ) :\widehat{a}_j=\mu(s_j;\theta) :a j=μ(sj;θ)。然后更新策略网络:
θ n e w ← θ n o w + β ⋅ ∇ θ μ ( s j ; θ n o w ) ⋅ ∇ a q ( s j , a ^ j ; w 1 , n o w ) . \theta_\mathrm{new}\:\leftarrow\:\theta_\mathrm{now}\:+\:\beta\cdot\:\nabla_{\theta}\boldsymbol{\mu}(s_{j};\boldsymbol{\theta}_\mathrm{now})\:\cdot\:\nabla_{\boldsymbol{a}}q(s_{j},\:\widehat{\boldsymbol{a}}_{j};\:\boldsymbol{w}_{1,\mathrm{now}}). θnew←θnow+β⋅∇θμ(sj;θnow)⋅∇aq(sj,a j;w1,now).
- 更新目标网络的参数:
θ n e w − ← τ θ n e w + ( 1 − τ ) θ n o w − , w 1 , n e w − ← τ w 1 , n e w + ( 1 − τ ) w 1 , n o w − , w 2 , n e w − ← τ w 2 , n e w + ( 1 − τ ) w 2 , n o w − . \begin{aligned}\\ \theta_{\mathrm{new}}^{-}& \leftarrow\tau\theta_{\mathrm{new}}+(1-\tau)\theta_{\mathrm{now}}^{-}, \\ w_{1,\mathrm{new}}^{-}& \leftarrow\tau w_{1,\mathrm{new}}+\left(1-\tau\right)\boldsymbol{w}_{1,\mathrm{now}}^{-}, \\ w_{2,\mathrm{new}}^{-}& \leftarrow\tau\boldsymbol{w}_{2,\mathrm{new}}+(1-\tau)\boldsymbol{w}_{2,\mathrm{now}}^{-}. \end{aligned} θnew−w1,new−w2,new−←τθnew+(1−τ)θnow−,←τw1,new+(1−τ)w1,now−,←τw2,new+(1−τ)w2,now−.
随机高斯策略
上一节用确定策略网络解决连续控制问题。本节用不同的方法做连续控制,本节的策略网络是随机的,它是随机正态分布 (也叫高斯分布)。
基本思路
我们先研究最简单的情形:自由度等于 1, 也就是说动作 a a a 是实数,动作空间 A ⊂ R A\subset\mathbb{R} A⊂R 。把动作的均值记作 μ ( s ) \mu(s) μ(s),标准差记作 σ ( s ) \sigma(s) σ(s), 它们都是状态 s s s 的函数。用正态分布的概率密度函数作为策略函数:
π ( a ∣ s ) = 1 6.28 ⋅ σ ( s ) ⋅ exp ( − [ a − μ ( s ) ] 2 2 ⋅ σ 2 ( s ) ) . ( 10.2 ) \pi(a|s)=\frac{1}{\sqrt{6.28}\cdot\sigma(s)}\cdot\exp\left(-\frac{\left[a-\mu(s)\right]^{2}}{2\cdot\sigma^{2}(s)}\right).\quad(10.2) π(a∣s)=6.28⋅σ(s)1⋅exp(−2⋅σ2(s)[a−μ(s)]2).(10.2)
假如我们知道函数 μ ( s ) \mu(s) μ(s) 和 σ ( s ) \sigma(s) σ(s) 的解析表达式,可以这样做控制:
- 观测到当前状态 s s s, 预测均值 μ ^ = μ ( s ) \widehat{\mu}=\mu(s) μ =μ(s) 和标准差 σ ^ = σ ( s ) \widehat{\sigma}=\sigma(s) σ =σ(s)。
- 从正态分布中做随机抽样 : a ∼ N ( μ ^ , σ ^ 2 ) :a\sim\mathcal{N}(\widehat{\mu},\widehat{\sigma}^2) :a∼N(μ ,σ 2); 智能体执行动作 a a a 。
然而我们并不知道 μ ( s ) \mu(s) μ(s) 和 σ ( s ) \sigma(s) σ(s) 是怎么样的函数。一个很自然的想法是用神经网络来近似这两个函数。把神经网络记作 μ ( s ; θ ) \mu(s;\theta) μ(s;θ) 和 σ ( s ; θ ) \sigma(s;\theta) σ(s;θ),其中 θ \theta θ 表示神经网络中的可训练参数。但实践中最好不要直接近似标准差 σ \sigma σ,而是近似方差对数 ln σ 2 \ln\sigma^{2} lnσ2。定义两个神经网络:
μ ( s ; θ ) 和 ρ ( s ; θ ) , \mu(s;\boldsymbol{\theta})\quad\text{和}\quad\rho(s;\boldsymbol{\theta}), μ(s;θ)和ρ(s;θ),
分别用于预测均值和方差对数。可以按照图10.10来搭建神经网络。
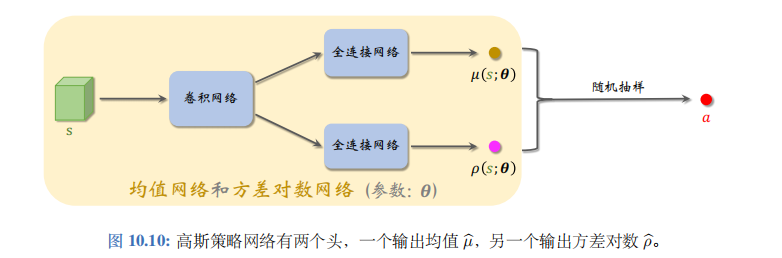
神经网络的输入是状态 s s s,通常是向量、矩阵或者张量。神经网络有两个输出头,分别记作 μ ( s ; θ ) \mu(s;\boldsymbol{\theta}) μ(s;θ) 和 ρ ( s ; θ ) \rho(s;\boldsymbol{\theta}) ρ(s;θ) 可以这样用神经网络做控制:
观测到当前状态 s s s, 计算均值 μ ^ = μ ( s ; θ ) \widehat{\mu}=\mu(s;\boldsymbol{\theta}) μ =μ(s;θ), 方差对数 ρ ^ = ρ ( s ; θ ) \widehat{\rho}=\rho(s;\boldsymbol{\theta}) ρ =ρ(s;θ), 以及方差 σ ^ 2 = \widehat{\sigma}^2= σ 2= exp ( ρ ^ ) 。 \exp(\widehat{\rho})。 exp(ρ )。
从正态分布中做随机抽样: a ∼ N ( μ ^ , σ ^ 2 ) a\sim\mathcal{N}(\widehat{\mu},\widehat{\sigma}^2) a∼N(μ ,σ 2); 智能体执行动作 a a a 。
用神经网络近似均值和标准差之后,公式 (10.2) 中的策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s) 变成了下面的策略网络:
π ( a ∣ s ; θ ) = 1 6.28 ⋅ exp [ ρ ( s ; θ ) ] ⋅ exp ( − [ a − μ ( s ; θ ) ] 2 2 ⋅ exp [ ρ ( s ; θ ) ] ) . \pi(a\:|\:s;\:\boldsymbol{\theta})\:=\:\frac{1}{\sqrt{6.28\cdot\exp[\rho(s;\boldsymbol{\theta})]}}\cdot\exp\bigg(-\frac{\left[a-\mu(s;\boldsymbol{\theta})\right]^{2}}{2\cdot\exp[\rho(s;\boldsymbol{\theta})]}\bigg). π(a∣s;θ)=6.28⋅exp[ρ(s;θ)]1⋅exp(−2⋅exp[ρ(s;θ)][a−μ(s;θ)]2).
实际做控制的时候,我们只需要神经网络 μ ( s ; θ ) \mu(s;\theta) μ(s;θ) 和 ρ ( s ; θ ) \rho(s;\theta) ρ(s;θ), 用不到真正的策略网络 π ( a ∣ s ; θ ) \pi(a|s;\boldsymbol{\theta}) π(a∣s;θ)。
随机高斯策略网络
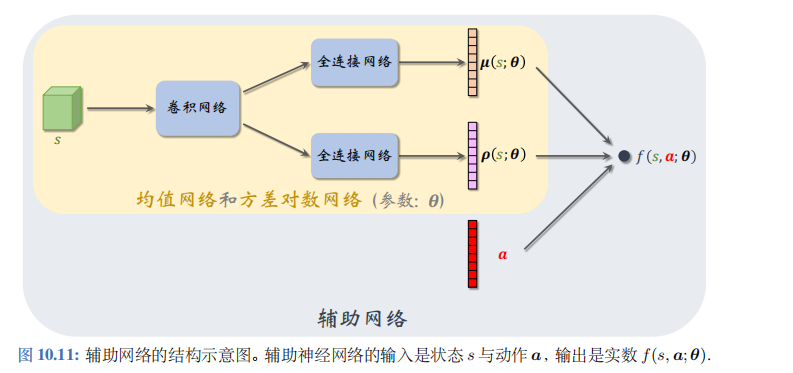
上一小节假设控制问题的自由度是 d = 1 d=1 d=1,也就是说动作 a a a 是标量。实际问题中的自由度 d d d 往往大于 1, 那么动作 a a a 是 d d d 维向量。对于这样的问题,我们修改一下神经网络结构,让两个输出 μ ( s ; θ ) \mu(s;\theta) μ(s;θ) 和 ρ ( s ; θ ) \rho(s;\theta) ρ(s;θ) 都 d d d 维向量;见图10.11。
用标量 a i a_i ai表示动作向量 a a a 的第 i i i 个元素。用函数 μ i ( s ; θ ) \mu_i(s;\boldsymbol{\theta}) μi(s;θ) 和 ρ i ( s ; θ ) \rho_i(s;\boldsymbol{\theta}) ρi(s;θ) 分别表示 μ ( s ; θ ) \mu(s;\boldsymbol{\theta}) μ(s;θ) 和 ρ ( s ; θ ) \rho(s;\boldsymbol{\theta}) ρ(s;θ) 的第 i i i 个元素。我们用下面这个特殊的多元正态分布的概率密度函数作为策略网络:
π ( a ∣ s ; θ ) = ∏ i = 1 d 1 6.28 ⋅ exp [ ρ i ( s ; θ ) ] ⋅ exp ( − [ a i − μ i ( s ; θ ) ] 2 2 ⋅ exp [ ρ i ( s ; θ ) ] ) . \pi(\boldsymbol{a}|s;\boldsymbol{\theta})\:=\:\prod_{i=1}^{d}\frac{1}{\sqrt{6.28\cdot\exp[\rho_{i}(s;\boldsymbol{\theta})]}}\cdot\exp\Big(\:-\frac{\left[a_{i}-\mu_{i}(s;\boldsymbol{\theta})\right]^{2}}{2\cdot\exp[\rho_{i}(s;\boldsymbol{\theta})]}\Big). π(a∣s;θ)=i=1∏d6.28⋅exp[ρi(s;θ)]1⋅exp(−2⋅exp[ρi(s;θ)][ai−μi(s;θ)]2).
做控制的时候只需要均值网络 μ ( s ; θ ) \mu(s;\theta) μ(s;θ) 和方差对数网络 ρ ( s ; θ ) \rho(s;\theta) ρ(s;θ),不需要策略网络 π ( u ∣ s ; θ ) s \pi(u|s;\theta)_s π(u∣s;θ)s 做训练的时候也不需要 π ( a ∣ s ; θ ) \pi(a|s;\theta) π(a∣s;θ), 而是要用辅助网络 f ( s , a ; θ ) f(s,\boldsymbol{a};\boldsymbol{\theta}) f(s,a;θ)。总而言之,策略网络 π \pi π 只是帮助你理解本节的方法而已,实际算法中不会出现 π。
图10.11描述了辅助网络 f ( s , a ; θ ) f(s,a;\theta) f(s,a;θ) 与μ、 ρ \rho ρ、 a a a 的关系。辅助网络具体是这样定义的:
f ( s , a ; θ ) = − 1 2 ∑ i = 1 d ( ρ i ( s ; θ ) + [ a i − μ i ( s ; θ ) ] 2 exp [ ρ i ( s ; θ ) ] ) . f\big(s,\boldsymbol{a};\boldsymbol{\theta}\big)=-\frac{1}{2}\sum_{i=1}^{d}\bigg(\rho_{i}(s;\boldsymbol{\theta})+\frac{[a_{i}-\mu_{i}(s;\boldsymbol{\theta})]^{2}}{\exp[\rho_{i}(s;\boldsymbol{\theta})]}\bigg). f(s,a;θ)=−21i=1∑d(ρi(s;θ)+exp[ρi(s;θ)][ai−μi(s;θ)]2).
它的可训练参数 θ \theta θ都是从 μ ( s ; θ ) \mu(s;\theta) μ(s;θ) 和 ρ ( s ; θ ) \rho(s;\theta) ρ(s;θ) 中来的。不难发现,辅助网络与策略网络有
这样的关系:
f ( s , a ; θ ) = ln π ( a ∣ s ; θ ) + C o n s t a n t . ( 10.3 ) \boxed{\quad f(s,\boldsymbol{a};\boldsymbol{\theta})\:=\:\ln\pi(\boldsymbol{a}|s;\boldsymbol{\theta})+\mathrm{Constant.}}\quad(10.3) f(s,a;θ)=lnπ(a∣s;θ)+Constant.(10.3)
策略梯度
回忆一下之前学过的内容。在 t t t 时刻的折扣回报记作随机变量
U t = R t + γ ⋅ R t + 1 + γ 2 ⋅ R t + 2 + ⋯ + γ n − t ⋅ R n . U_{t}\:=\:R_{t}+\gamma\cdot R_{t+1}+\gamma^{2}\cdot R_{t+2}+\cdots+\gamma^{n-t}\cdot R_{n}. Ut=Rt+γ⋅Rt+1+γ2⋅Rt+2+⋯+γn−t⋅Rn.
动作价值函数 Q π ( s t , a t ) Q_\pi(s_t,a_t) Qπ(st,at) 是对折扣回报 U t U_t Ut 的条件期望。前面章节推导过策略梯度的蒙特卡洛近似:
g = Q π ( s , a ) ⋅ ∇ θ ln π ( a ∣ s ; θ ) . \boldsymbol{g}\:=\:Q_{\pi}(s,\boldsymbol{a})\cdot\nabla_{\boldsymbol{\theta}}\ln\pi(\boldsymbol{a}|s;\boldsymbol{\theta}). g=Qπ(s,a)⋅∇θlnπ(a∣s;θ).
由公式 (10.3) 可得:
g = Q π ( s , a ) ⋅ ∇ θ f ( s , a ; θ ) . ( 10.4 ) \boldsymbol{g}\:=\:Q_{\pi}(s,\boldsymbol{a})\cdot\nabla_{\boldsymbol{\theta}}f(s,\boldsymbol{a};\boldsymbol{\theta}). \quad(10.4) g=Qπ(s,a)⋅∇θf(s,a;θ).(10.4)
有了策略梯度,就可以学习参数 θ \theta θ。训练的过程大致如下:
搭建均值网络 μ ( s ; θ ) \mu(s;\theta) μ(s;θ)、方差对数网络 ρ ( s ; θ ) \rho(s;\theta) ρ(s;θ)、辅助网络 f ( s , a ; θ ) f(s,\boldsymbol{a};\boldsymbol{\theta}) f(s,a;θ) 。
让智能体与环境交互,记录每一步的状态、动作、奖励,并对参数 θ \theta θ 做更新:
(a). 观测到当前状态 s s s,计算均值、方差对数、方差:
μ ^ = μ ( s ; θ ) , ρ ^ = ρ ( s ; θ ) , σ ^ 2 = exp ( ρ ^ ) . \widehat{\mu}\:=\:\mu(s;\theta),\quad\widehat{\rho}\:=\:\rho(s;\theta),\quad\widehat{\sigma}^{2}\:=\:\exp{(\widehat{\rho})}. μ =μ(s;θ),ρ =ρ(s;θ),σ 2=exp(ρ ).
此处的指数函数 exp ( ⋅ ) \exp(\cdot) exp(⋅) 应用到向量的每一个元素上。
(b). 设 μ ^ i \widehat{\mu}_i μ
i 和 σ ^ i \widehat{\sigma}_i σ
i 分别是 d d d 维向量 μ ^ \widehat{\boldsymbol{\mu}} μ
和 σ ^ \hat{\sigma} σ^ 的第 i i i 个元素。从正态分布中做抽样:
a i ∼ N ( μ ^ i , σ ^ i 2 ) , ∀ i = 1 , ⋯ , d . a_{i}\:\sim\:\mathcal{N}\big(\widehat{\mu}_{i},\widehat{\sigma}_{i}^{2}\big),\quad\forall\:i=1,\cdots,d. ai∼N(μ
i,σ
i2),∀i=1,⋯,d.
把得到的动作记作 a = [ a 1 , ⋯ , a d ] a=[a_1,\cdots,a_d] a=[a1,⋯,ad]。
(c ). 近似计算动作价值 : q ^ ≈ Q π ( s , a ) :\widehat{q}\approx Q_\pi(s,\boldsymbol{a}) :q ≈Qπ(s,a)。
(d). 用反向传播计算出辅助网络关于参数 θ \theta θ 的梯度: ∇ θ f ( s , a ; θ ) \nabla_{\theta}f(s,\boldsymbol{a};\boldsymbol{\theta}) ∇θf(s,a;θ)。
(e). 用策略梯度上升更新参数:
θ ← θ + β ⋅ q ^ ⋅ ∇ θ f ( s , a ; θ ) . \theta\:\leftarrow\:\theta\:+\:\beta\cdot\widehat{q}\cdot\nabla_{\boldsymbol{\theta}}f(s,\boldsymbol{a};\boldsymbol{\theta}). θ←θ+β⋅q
⋅∇θf(s,a;θ).
此处的 β \beta β 是学习率。
用 REINFORCE 学习参数
REINFORCE 用实际观测的折扣回报 u t = ∑ k = t n γ k − t ⋅ r k u_t=\sum_{k=t}^n\gamma^{k-t}\cdot r_k ut=∑k=tnγk−t⋅rk 代替动作价值 Q π ( s t , a t ) Q_\pi(s_t,\boldsymbol{a}_t) Qπ(st,at)。
道理是这样的。动作价值是回报的期望:
Q π ( s t , a t ) = E [ U t ∣ S t = s t , A t = a t ] . Q_{\pi}(s_{t},\boldsymbol{a}_{t})\:=\:\mathbb{E}\big[U_{t}\big|\:S_{t}=s_{t},A_{t}=\boldsymbol{a}_{t}\big]. Qπ(st,at)=E[Ut
St=st,At=at].
随机变量 U t U_t Ut 的一个实际观测值 u t u_t ut 是期望的蒙特卡洛近似。这样一来,公式 (10.4) 中的策略梯度就能近似成
g ≈ u t ⋅ ∇ θ f ( s , a ; θ ) . \boldsymbol{g}\:\approx\:u_{t}\cdot\nabla_{\boldsymbol{\theta}}f(s,\boldsymbol{a};\boldsymbol{\theta}). g≈ut⋅∇θf(s,a;θ).
在搭建好均值网络 μ ( s ; θ ) \mu(s;\theta) μ(s;θ)、方差对数网络 ρ ( s ; θ ) \rho(s;\theta) ρ(s;θ)、辅助网络 f ( s , a ; θ ) f(s,a;\theta) f(s,a;θ) 之后,我们用REINFORCE 更新参数 θ \theta θ。设当前参数为 θ n o w \theta_\mathrm{now} θnow。REINFORCE 重复以下步骤,直到收敛:
- 用 μ ( s ; θ n o w ) \mu(s;\theta_\mathrm{now}) μ(s;θnow) 和 ρ ( s ; θ n o w ) \rho(s;\theta_\mathrm{now}) ρ(s;θnow) 控制智能体与环境交互,完成一局游戏,得到一条轨迹
s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , ⋯ , s n , a n , r n . s_{1},\boldsymbol{a}_{1},r_{1},\quad s_{2},\boldsymbol{a}_{2},r_{2},\quad\cdots,\quad s_{n},\boldsymbol{a}_{n},r_{n}. s1,a1,r1,s2,a2,r2,⋯,sn,an,rn.
计算所有的回报:
u t = ∑ k = t T γ k − t ⋅ r k , ∀ t = 1 , ⋯ , n . u_t=\sum\limits_{k=t}^T\gamma^{k-t}\cdot r_k,\quad\forall t=1,\cdots,n. ut=k=t∑Tγk−t⋅rk,∀t=1,⋯,n.对辅助网络做反向传播,得到所有的梯度:
∇ θ f ( s t , a t ; θ n o w ) , ∀ t = 1 , ⋯ , n . \nabla_{\boldsymbol{\theta}}f\big(s_{t},\boldsymbol{a}_{t};\boldsymbol{\theta}_{\mathrm{now}}\big),\quad\forall\:t=1,\cdots\:,n. ∇θf(st,at;θnow),∀t=1,⋯,n.
- 用策略梯度上升更新参数:
θ n e w ← θ n o w + β ⋅ ∑ t = 1 n γ t − 1 ⋅ u t ⋅ ∇ θ f ( s t , a t ; θ n o w ) \theta_{\mathrm{new}}\:\leftarrow\:\theta_{\mathrm{now}}\:+\:\beta\cdot\sum_{t=1}^{n}\gamma^{t-1}\cdot u_{t}\cdot\nabla_{\theta}f\big(s_{t},\boldsymbol{a}_{t};\boldsymbol{\theta}_{\mathrm{now}}\big) θnew←θnow+β⋅t=1∑nγt−1⋅ut⋅∇θf(st,at;θnow)
上述算法标准的 REINFORCE, 效果不如使用基线的 REINFORCE。可以用基线改进上面描述的算法。REINFORCE 算法属于同策略(on-policy),不能使用经验回放。
用 Actor-Critic 学习参数
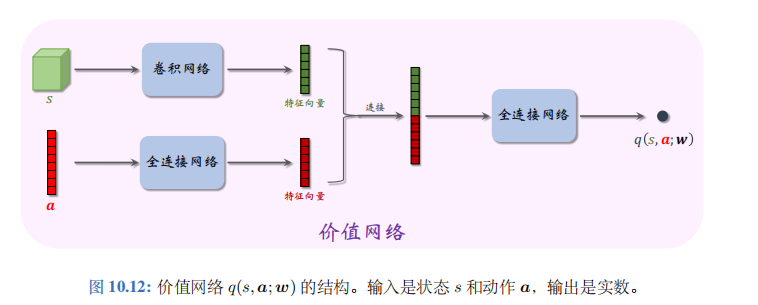
Actor-critic 需要搭建一个价值网络 q ( s , a ; w ) q(s,\boldsymbol{a};\boldsymbol{w}) q(s,a;w), 用于近似动作价值函数 Q π ( s , a ) Q_\pi(s,\boldsymbol{a}) Qπ(s,a)。价值网络的结构如图 10.12 所示。此外,还需要一个目标价值网络 q ( s , a ; w − ) q(s,a;w^-) q(s,a;w−), 网络结构相同,但是参数不同。
在搭建好均值网络 μ \mu μ、方差对数网络 ρ \rho ρ、辅助网络 f f f、价值网络 q q q 之后,我们用 SARSA 算法更新价值网络参数 w w w, 用近似策略梯度更新控制器参数 θ \theta θ。设当前参数为 w n o w w_\mathrm{now} wnow 和 θ n o w \theta_\mathrm{now} θnow。重复以下步骤更新价值网络参数、控制器参数,直到收敛:
实际观测到当前状态 s t s_t st,用控制器算出均值 μ ( s t ; θ n o w ) \mu(s_t;\theta_\mathrm{now}) μ(st;θnow) 和方差对数 ρ ( s t ; θ n o w ) \rho(s_t;\theta_\mathrm{now}) ρ(st;θnow),然后随机抽样得到动作 a t a_t at。智能体执行动作 a t a_t at, 观测到奖励 r t r_t rt 与新的状态 s t + 1 s_{t+1} st+1。
计算均值 μ ( s t + 1 ; θ n o w ) \mu(s_{t+1};\theta_\mathrm{now}) μ(st+1;θnow) 和方差对数 ρ ( s t + 1 ; θ n o w ) \rho(s_{t+1};\theta_\mathrm{now}) ρ(st+1;θnow),然后随机抽样得到动作 a ~ t + 1 \tilde{a}_{t+1} a~t+1。这个动作只是假想动作,智能体不予执行。
用价值网络计算出:
q t ^ = q ( s t , a t ; w n o w ) . \widehat{q_{t}}\:=\:q\big(s_{t},\boldsymbol{a_{t}};\boldsymbol{w_{\mathrm{now}}}\big). qt =q(st,at;wnow).
- 用目标网络计算出:
q ^ t + 1 = q ( s t + 1 , a ~ t + 1 ; w n o w ˉ ) . \widehat q_{t+1}\:=\:q\big(s_{t+1},\tilde{\boldsymbol{a}}_{t+1};\bar{\boldsymbol{w_{\mathrm{now}}}}\big). q t+1=q(st+1,a~t+1;wnowˉ).
- 计算 TD 目标和 TD 误差:
y ^ t = r t + γ ⋅ q ^ t + 1 , δ t = q ^ t − y ^ t . \widehat y_{t}\:=\:r_{t}+\gamma\cdot\widehat q_{t+1},\quad\delta_{t}\:=\:\widehat q_{t}-\widehat y_{t}. y t=rt+γ⋅q t+1,δt=q t−y t.
- 更新价值网络的参数:
w n e w ← w n o w − α ⋅ δ t ⋅ ∇ w q ( s t , a t ; w n o w ) . \boldsymbol{w_\mathrm{new}}\:\leftarrow\:\boldsymbol{w_\mathrm{now}}-\alpha\cdot\delta_{t}\cdot\nabla_{\boldsymbol{w}q}(s_{t},\boldsymbol{a_{t}};\boldsymbol{w_\mathrm{now}}). wnew←wnow−α⋅δt⋅∇wq(st,at;wnow).
- 更新策略网络参数参数:
θ n e w ← θ n o w + β ⋅ q ^ t ⋅ ∇ θ f ( s t , a t ; θ n o w ) \theta_{\mathrm{new}}\:\leftarrow\:\theta_{\mathrm{now}}+\beta\cdot\widehat{q}_{t}\cdot\nabla_{\boldsymbol{\theta}}f(s_{t},\boldsymbol{a}_{t};\boldsymbol{\theta}_{\mathrm{now}}) θnew←θnow+β⋅q t⋅∇θf(st,at;θnow)
- 更新目标网络参数:
w n e w ˉ ← τ ⋅ w n e w + ( 1 − τ ) ⋅ w n o w − . \bar{\boldsymbol{w_\mathrm{new}}}\:\leftarrow\:\tau\cdot\boldsymbol{w_\mathrm{new}}\:+\:(1-\tau)\cdot\boldsymbol{w_\mathrm{now}^-}. wnewˉ←τ⋅wnew+(1−τ)⋅wnow−.
算法中的 α \alpha α、β、 τ \tau τ都是超参数,需要手动调整。上述算法是标准的 actor-critic. 效果不如advantage actor-critic (A2C)。可以用A2C改进上述方法。
总结
离散控制问题的动作空间 A A A 是个有限的离散集,连续控制问题的动作空间 A A A 是个连续集。如果想将 DQN 等离散控制方法应用到连续控制问题,可以对连续动作空间做离散化,但这只适用于自由度较小的问题。
可以用确定策略网络 a = μ ( s ; θ ) a=\mu(s;\theta) a=μ(s;θ) 做连续控制。网络的输入是状态 s s s, 输出是动作 a a a, a a a 是向量,大小等于问题的自由度。
确定策略梯度 (DPG) 借助价值网络 q ( s , a ; w ) q(s,a;w) q(s,a;w) 训练确定策略网络。DPG 属于异策略,用行为策略收集经验,做经验回放更新策略网络和价值网络。
DPG 与 DQN 有很多相似之处,而且它们的训练都存在高估等问题。TD3 使用几种技巧改进 DPG: 截断双 Q 学习、往动作中加噪声、降低更新策略网络和目标网络的频率。
可以用随机高斯策略做连续控制。用两个神经网络分别近似高斯分布的均值和方差对数,并用策略梯度更新两个神经网络的参数。
后记
截至2024年1月30日13点04分,整理完王树森的《深度强化学习》的关于连续控制的笔记。


































![[Python] 什么是PCA降维技术以及scikit-learn中PCA类使用案例(图文教程,含详细代码)](https://img-blog.csdnimg.cn/direct/aefc47fdbed54d05a96c688e4a9d46fd.png)



