完整程序传送门
前些天接了一个大两届的师兄的小活,做了一下爬boss直聘岗位信息的程序,在这里记录一下
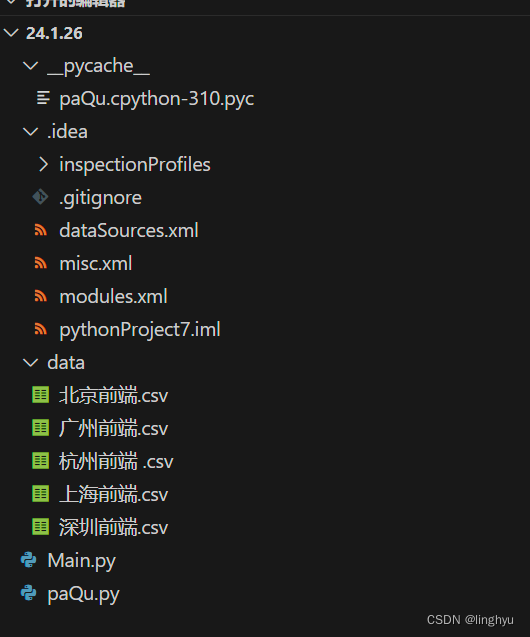
程序框架
定义一个名为paQu的接口函数,用于检查窗口的输入,它接受一个参数self,获取self对象的a属性(可能是一个变量或对象),并将其赋值给变量b,检查变量b是否为空,如果为空,则返回,不执行任何操作。再次获取self对象的a属性,并将其赋值给变量b。如果b不为空,则递归调用paQufun函数,并将b作为参数传递。
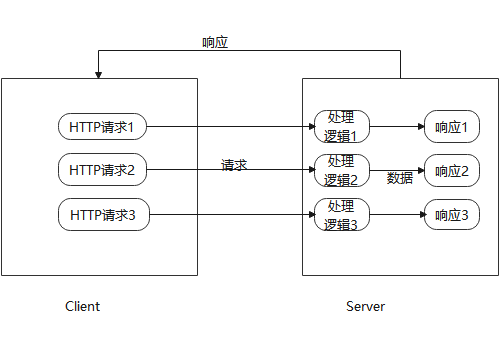
主要功能是从招聘网站上所需求的爬取职位信息,并将这些信息保存到一个CSV文件中。思路是使用Python的Selenium库模拟浏览器操作,访问招聘网站,输入所search的职位,获取职位信息,并将这些信息保存到一个CSV文件中。代码如下:
def paQufun(a):
f = open('./data/' + a + '.csv', mode='a', encoding='utf-8', newline='')
data = csv.DictWriter(f, fieldnames=['招聘职业', '地区', '公司', '薪资', '工作经验要求', '学历要求', '工作介绍', '公司福利', '详情页'])
data.writeheader()
driver = webdriver.Chrome()
# driver.get('https://sou.zhaopin.com/?jl=763&kw=%E5%89%8D%E7%AB%AF')
'''
city接城市后编码
business接区编码,可不加
'''
driver.get('https://www.zhipin.com/web/geek/job?query=&city=101270100&areaBusiness=510108')
# 隐式等待
driver.implicitly_wait(50)
find = driver.find_element('css selector', ' .search-input-box .input')
driver.find_element('css selector', ' .search-input-box .input').send_keys(a)
driver.implicitly_wait(50)
driver.find_element('css selector', '.search-btn').click()
# css选择器直接定位元素
lists = driver.find_elements('css selector', '.search-job-result li.job-card-wrapper')
for li in lists:
job = li.find_element('css selector', ' .job-name').text
area = li.find_element('css selector', ' .job-area').text
company = li.find_element('css selector', ' .company-name').text
salary = li.find_element('css selector', ' .salary').text
yao = li.find_element('css selector', ' .job-info.clearfix .tag-list').text
lines = yao.split("\n")
line1 = lines[0]
line2 = lines[1]
jie = li.find_element('css selector', ' .job-card-footer.clearfix .info-desc').text
fuLi = li.find_element('css selector', ' .job-card-footer.clearfix .tag-list').text
href = li.find_element('css selector', ' .job-card-left').get_attribute('href')
dit = {
'招聘职业': job,
'地区': area,
'公司': company,
'薪资': salary,
'工作经验要求': line1,
'学历要求': line2,
'工作介绍': jie,
'公司福利': fuLi,
'详情页': href,
}
data.writerow(dit)
print(job, area, company)
print(salary, line1, line2, jie, fuLi, href)
print('\n')1、修改URL:请将代码中的URL替换为您要爬取的城市对应的URL。例如,如果需要爬取上海的前端职位,可以将URL修改为:
driver.get('https://www.zhipin.com/web/geek/job?query=&city=101270100&areaBusiness=510108')
2、避免被ban:在爬取过程中,为避免被网站ban,请使用代理IP或设置隐式等待时间。在代码中,使用了隐式等待时间,可根据需要修改为代理IP。
3、异常处理:在爬取过程中,请确保进行异常处理,以防止程序在遇到错误时崩溃。例如:
try:
job = li.find_element('css selector', ' .job-name').text
except NoSuchElementException:
job = ''

























![[PHP]严格类型](https://img-blog.csdnimg.cn/direct/aaf86b2bd14448d7953a6b4afb731358.png)



![[数据结构]-哈希](https://img-blog.csdnimg.cn/f55a07090b3541518429c3017449bf1b.png)