一、相关网站
二、相关代码
import requests
from lxml import etree
import csv
with open('拉钩Python岗位数据.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['公司', '规模','岗位','地区','薪资','经验要求']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for page in range(1,31):
# url = 'https://www.lagou.com/wn/zhaopin?fromSearch=true&kd=python&city=%E5%85%A8%E5%9B%BD'
url = f'https://www.lagou.com/wn/zhaopin?fromSearch=true&kd=python&pn={page}'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
data = {
'fromSearch':'true',
'kd':'python',
'city':'全国'
}
response = requests.post(url=url,data=data,headers=headers)
# print(response.text)
result = etree.HTML(response.text)
company = result.xpath('//div[@class="company-name__2-SjF"]/a/text()')
scale = result.xpath('//div[@class="industry__1HBkr"]/text()')
post = result.xpath('//div[@class="p-top__1F7CL"]/a/text()[1]')
location = result.xpath('//div[@class="p-top__1F7CL"]/a/text()[2]')
salt = result.xpath('//div[@class="p-bom__JlNur"]/span/text()')
suffer = result.xpath('//div[@class="p-bom__JlNur"]/text()[1]')
# print(company,scale,post,location,salt,suffer)
for com, sca, pos, loc, sal,suf in zip(company, scale, post, location, salt,suffer):
print(f'{com} ====== {sca} ====== {pos} ====== {loc} ===== {sal} ===== {suf}')
writer.writerow({'公司': com, '规模': sca, '岗位': pos, '地区': loc, '薪资': sal,'经验要求':suf})
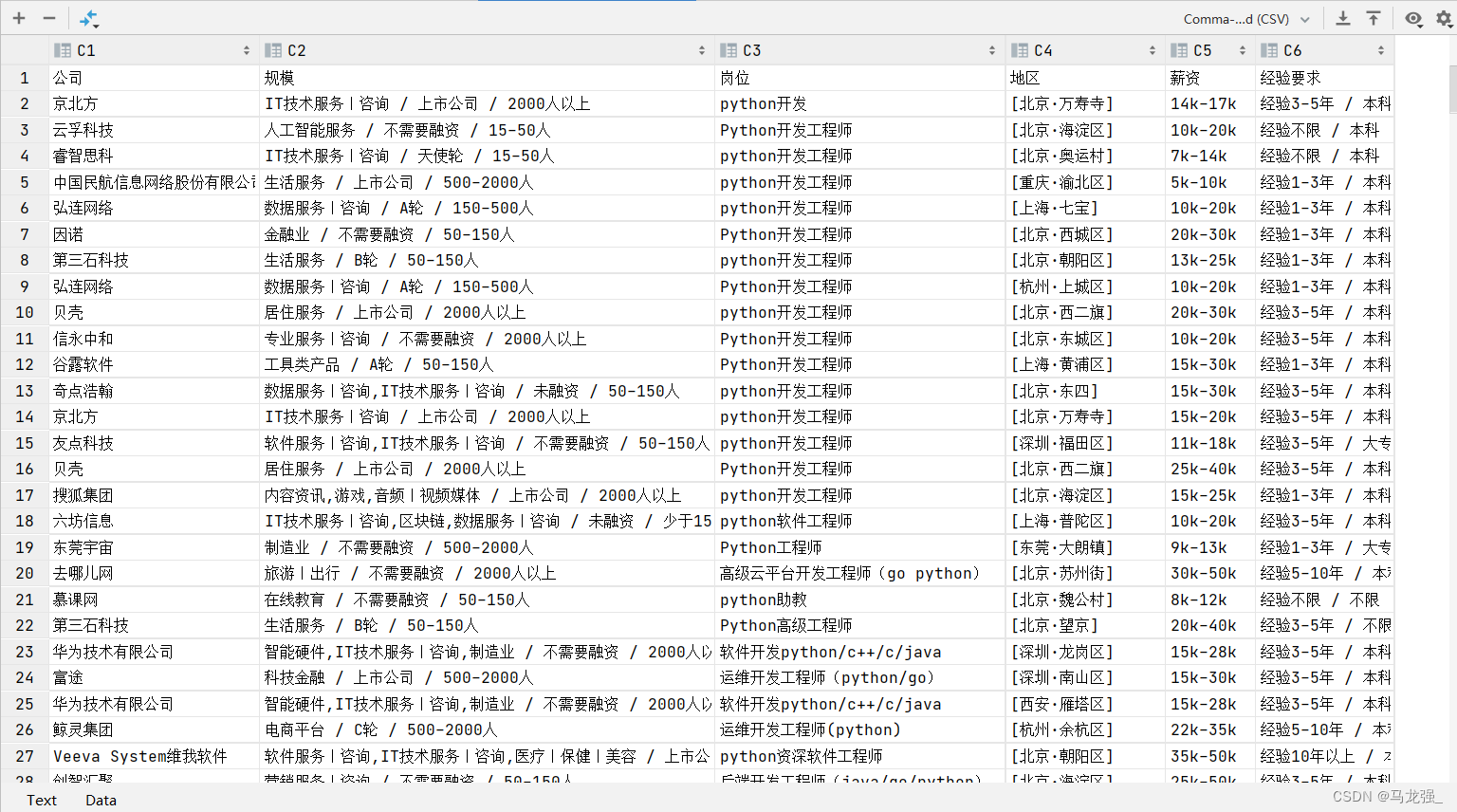
三、获取的结果
版权声明和免责声明 本博客提供的所有爬虫代码和相关内容(以下简称“内容”)仅供参考和学习之用。任何使用或依赖这些内容的风险均由使用者自行承担。我(博客所有者)不对因使用这些内容而产生的任何直接或间接损失承担责任。 严禁将本博客提供的爬虫代码用于任何违法、不道德或侵犯第三方权益的活动。使用者应当遵守所有适用的法律法规,包括但不限于数据保护法、隐私权法和知识产权法。 如果您选择使用本博客的爬虫代码,您应当确保您的使用行为符合所有相关法律法规,并且不会损害任何人的合法权益。在任何情况下,我(博客所有者)均不对您的行为负责。 如果您对本声明有任何疑问,或者需要进一步的澄清,请通过我的联系方式与我联系。 |