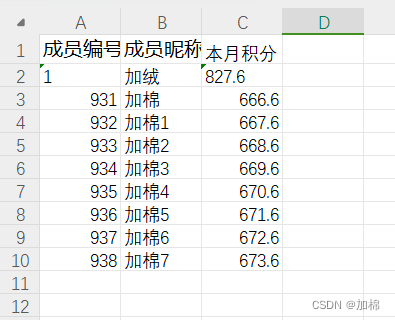
遇到这么一个需求, Excel解析时表头大小写可能与模板不一致, 顺序也会变化.... 所以原有的注解就不行了..如果使用名字匹配可以顺序但是无法匹配所有的大小写情况, 如果使用注解的index属性可以解决大小写匹配问题,但是顺序如果变化就又不行了.... 所以就有了以下的解决方案,可以根据自己的需求选用不同的方式.
方法一.@ExcelProperty注解:
表头别名不多的情况下推荐使用自带注解.ExcelProperty的value属性.
//使用示例
@ExcelProperty(value = {"member", "Member"})
private String member;@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface ExcelProperty {
/**
* The name of the sheet header.
*
* <p>
* write: It automatically merges when you have more than one head
* <p>
* read: When you have multiple heads, take the last one
*
* @return The name of the sheet header
*/
String[] value() default {""};
// 省略
.......
}当列名为"member"或"Member"时都可以读取列内的值,如果两个都有则会取最后一个.
方法二 :
这种就比较极端, 也是我遇到的实际需求情况.. 不仅列名可能不一样,列的顺序也可能会变化..裂开
/**
* 解析Excel内容 忽略表头大小写
**/
public class ExcelListener implements ReadListener<Map<Integer, String>> {
//定义一个list用于接收读取到的数据
private final List<UploadExcelDTO> collect;
//记录想要读取数据所在的下标
private final static Map<String, Integer> MAPPING = new HashMap<>();
//构造器,接受一个List<UploadExcelDTO>对象
public MskExcelListener(List<UploadExcelDTO> collect) {
this.collect = collect;
}
@Override
public void invoke(Map<Integer, String> rowInfoMap, AnalysisContext context) {
//rowInfoMap的key为数据表头所在列的下标, value为列值
ReadRowHolder readRowHolder = context.readRowHolder();
Integer rowIndex = readRowHolder.getRowIndex();
UploadExcelDTO dto = new UploadExcelDTO();
//表头处理,忽略大小写匹配,记录想要收集数据的下标位置
if (Objects.equals(rowIndex, 0)) {
rowInfoMap.forEach((k, v) -> {
if ("BookingNumber".equalsIgnoreCase(v)) {
MAPPING.put("BookingNumber", k);
} else if ("member".equalsIgnoreCase(v)) {
MAPPING.put("member", k);
} else if ("ServiceContract".equalsIgnoreCase(v)) {
MAPPING.put("ServiceContract", k);
} else if ("WeekNumber".equalsIgnoreCase(v)) {
MAPPING.put("WeekNumber", k);
} else if ("RouteCode".equalsIgnoreCase(v)) {
MAPPING.put("RouteCode", k);
} else if ("FFE".equalsIgnoreCase(v)) {
MAPPING.put("FFE", k);
} else if ("CreatedDttm".equalsIgnoreCase(v)) {
MAPPING.put("CreatedDttm", k);
} else if ("Booked By Customer Email".equalsIgnoreCase(v)) {
MAPPING.put("Booked By Customer Email", k);
}
});
} else {
//使用下标位置定位数据列 读取指定列的数据
MAPPING.forEach((mk, index) -> {
if ("BookingNumber".equalsIgnoreCase(mk)) {
dto.setBookingNumber(rowInfoMap.get(index));
} else if ("member".equalsIgnoreCase(mk)) {
dto.setMember(rowInfoMap.get(index));
} else if ("ServiceContract".equalsIgnoreCase(mk)) {
dto.setServiceContract(rowInfoMap.get(index));
} else if ("WeekNumber".equalsIgnoreCase(mk)) {
dto.setWeekNumber(Integer.valueOf(rowInfoMap.get(index)));
} else if ("RouteCode".equalsIgnoreCase(mk)) {
dto.setRouteCode(rowInfoMap.get(index));
} else if ("FFE".equalsIgnoreCase(mk)) {
dto.setFee(new BigDecimal(rowInfoMap.get(index)).doubleValue());
} else if ("CreatedDttm".equalsIgnoreCase(mk)) {
dto.setCreatedDttm(rowInfoMap.get(index));
} else if ("Booked By Customer Email".equalsIgnoreCase(mk)) {
dto.setBookedByCustomerEmail(rowInfoMap.get(index));
}
});
collect.add(dto);
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
String format = String.format("sheet:%s,解析完成", analysisContext.readSheetHolder().getSheetName());
MAPPING.clear();
System.out.println(format);
}
}