一、linux中的系统用户信息文件----/etc/passwd
下面是文件中的一个样例
christine:x:1001:1001::/home/christine:/bin/bash每个条目包含7个数据字段,字段之间用冒号分隔。系统使用字段中的数据来赋予用户账户某些特性。第7章会对其中多数条目进行更加详细的讨论。现在先将注意力放在最后一个字段上,该字段指定了用户使用的shell程序。
二、linux中的目录

1.1相对路径和绝对路径
1.绝对路径用户可以在虚拟目录中采用绝对路径来引用目录名。绝对路径定义了在虚拟目录结构中,该目录从根目录开始的确切位置,相当于目录的全名。绝对路径总是以正斜线(/)作为起始,以指明虚拟文件系统的根目录。因此,如果要指向usr目录所包含的子目录bin,可以写成下面这样:[插图]绝对路径可以清晰明确地表明用户想切换到的确切位置。要用绝对路径来到达文件系统中的某个特定位置,用户只需在cd命令后指定完整的路径名即可:
[christine@localhost ~]$ cd /usr/bin
[christine@localhost bin]$2.相对路径相对路径允许你指定一个基于当前位置的目标路径。相对路径不以代表根目录的正斜线(/)开头,而是以目录名(如果你准备切换到当前工作目录下的某个目录的话)或是一个特殊字符开始。假如你位于home目录中,希望切换到Documents子目录,那么可以使用cd命令配合相对路径:
[christine@localhost ~]$ pwd
/home/christine
[christine@localhost ~]$ cd Documents
[christine@localhost Documents]$ pwd
/home/christine/Documents
[christine@localhost Documents]$注意,在上面的例子中并没有使用正斜线(/),而是使用相对路径将当前工作目录从/home/christine改为了/home/christine/Documents,少敲了不少键盘。提示 如果刚接触命令行和Linux目录结构,推荐你先暂时坚持使用绝对路径,等熟悉了目录布局之后再使用相对路径。
1.2查询目录和文件 ls
ls:可以查看不隐藏的所有文件以及目录
ls -F:可以区分查看是目录还是文件夹
ls -a :可以查看所有文件 包含隐藏文件
ls -F -R(或者ls –FR):-R是ls命令的另一个选项,称作递归选项,可以列出当前目录所包含的子目录中的文件。如果子目录数量众多,则输出结果会很长。这里有个-R选项输出的简单例子。-F选项用于帮助你分辨文件类型
1.3文件过滤器,其实就是像通配符
$ touch my_script my_scrapt my_file
$ touch fall fell fill full
$ ls
Desktop Downloads fell full my_file my_script Public test_file
Documents fall fill Music my_scrapt Pictures Templates Videos
$
·问号(?)代表任意单个字符;·星号(*)代表零个或多个字符。
ls -l my_sc?ipt
1.4创建文件以及目录
touch:创建文件
touch命令会创建好指定的文件并将你的用户名作为该文件的属主。注意,新文件的大小为0,因为touch命令只是创建了一个空文件。touch命令还可用来改变文件的修改时间。该操作不会改变文件内容:
$ ls -l test_one
-rw-rw-r--. 1 christine christine 0 Feb 29 17:24 test_one
$ touch test_one
$ ls -l test_one
-rw-rw-r--. 1 christine christine 0 Feb 29 17:26 test_one
$1.5 复制文件:cp source destination
$ cp test_one test_two
$ ls -l test_one test_two
-rw-rw-r--. 1 christine christine 0 Feb 29 17:26 test_one
-rw-rw-r--. 1 christine christine 0 Feb 29 17:46 test_two
$新文件test_two和文件test_one的修改时间并不一样。如果目标文件已经存在,则cp命令可能并不会提醒你这一点。最好加上-i选项,强制shell询问是否需要覆盖已有文件:
$ ls -l test_one test_two
-rw-rw-r--. 1 christine christine 0 Feb 29 17:26 test_one
-rw-rw-r--. 1 christine christine 0 Feb 29 17:46 test_two
$
$ cp -i test_one test_two
cp: overwrite 'test_two'? n
$cp -R dandanProject/ dandan/ 递归复制目录下的所有文件 目标目录不存在则会创建
也可以在cp命令中使用通配符
1.6软连接
符号链接(也称为软链接)是一个实实在在的文件,该文件指向存放在虚拟目录结构中某个地方的另一个文件。这两个以符号方式链接在一起的文件彼此的内容并不相同。要为一个文件创建符号链接,原始文件必须事先存在。然后可以使用ln命令以及-s选项来创建符号链接:
$ ls -l test_file
-rw-rw-r--. 1 christine christine 74 Feb 29 15:50 test_file
$
$ ln -s test_file slink_test_file
$
$ ls -l *test_file
lrwxrwxrwx. 1 christine christine 9 Mar 4 09:46 slink_test_file -> test_file
-rw-rw-r--. 1 christine christine 74 Feb 29 15:50 test_file
$并且他们是独立存在的只是 slink_test_file指向 test_file文件罢了
可以使用 ls -i 来查看他们的inode编号是不一样的
1.7硬链接
硬链接创建的是一个独立的虚拟文件,其中包含了原始文件的信息以及位置。但是两者就根本而言是同一个文件。要想创建硬链接,原始文件也必须事先存在,只不过这次使用ln命令时不需要再加入额外的选项了:
$ ls -l *test_one
-rw-rw-r--. 1 christine christine 0 Feb 29 17:26 test_one
$
$ ln test_one hlink_test_one
$
$ ls -li *test_one
1415016 -rw-rw-r--. 2 christine christine 0 Feb 29 17:26 hlink_test_one
1415016 -rw-rw-r--. 2 christine christine 0 Feb 29 17:26 test_one
$在上面的例子中,创建好硬链接文件之后,我们使用ls -li命令显示了*test_one的inode编号以及长列表。注意,以硬链接相连的文件共享同一个inode编号。这是因为两者其实就是同一个文件。另外,彼此的文件大小也一模一样。注意 只能对处于同一存储设备的文件创建硬链接。要想在位于不同存储设备的文件之间创建链接,只能使用符号链接
1.8文件重命名以及文件移动 mv命令
重命名
$ ls -li f?ll
1414976 -rw-rw-r--. 1 christine christine 0 Feb 29 16:12 fall
1415004 -rw-rw-r--. 1 christine christine 0 Feb 29 16:12 fell
1415005 -rw-rw-r--. 1 christine christine 0 Feb 29 16:12 fill
1415011 -rw-rw-r--. 1 christine christine 0 Feb 29 16:12 full
$
$ mv fall fzll
$
$ ls -li f?ll
1415004 -rw-rw-r--. 1 christine christine 0 Feb 29 16:12 fell
1415005 -rw-rw-r--. 1 christine christine 0 Feb 29 16:12 fill
1415011 -rw-rw-r--. 1 christine christine 0 Feb 29 16:12 full
1414976 -rw-rw-r--. 1 christine christine 0 Feb 29 16:12 fzll
$移动位置
$ ls -li /home/christine/fzll
1414976 -rw-rw-r--. 1 christine christine 0 Feb 29 16:12 /home/christine/fzll
$
$ ls -li /home/christine/NewDocuments/fzll
ls: cannot access '/home/christine/NewDocuments/fzll': No such file or directory
$
$ mv /home/christine/fzll /home/christine/NewDocuments/
$
$ ls -li /home/christine/NewDocuments/fzll
1414976 -rw-rw-r--. 1 christine christine 0 Feb 29 16:12
/home/christine/NewDocuments/fzll
$
$ ls -li /home/christine/fzll
ls: cannot access '/home/christine/fzll': No such file or directory
$1.9删除文件
rm -rf /rm -i
2.1创建目录
创建单个: mkdir a
批量创建:
$ mkdir -p New_Dir/SubDir/UnderDir
$ ls -R New_Dir
New_Dir:
SubDir
New_Dir/SubDir:
UnderDir
New_Dir/SubDir/UnderDir:
$2.2删除目录
$ mkdir Wrong_Dir
$ touch Wrong_Dir/newfile
$
$ rmdir Wrong_Dir/
rmdir: failed to remove 'Wrong_Dir/': Directory not empty
$2.3查看文件内容
2.3.1 cat命令
$ cat test_file
Hello World
Hello World again
Hello World a third time
How are you World?
$-n选项会给所有的行加上行号:
$ cat -n test_file
1 Hello World
2 Hello World again
3 Hello World a third time
4 How are you World?
5
$这个功能在检查脚本时会很方便。如果只想给有文本的行加上行号,可以用-b选项:
$ cat -b test_file
1 Hello World
2 Hello World again
3 Hello World a third time
4 How are you World?
$如果是大文件可以使用more命令
2.3.2 more命令
cat命令的主要缺点是其开始运行之后你无法控制后续操作。为了解决这个问题,开发人员编写了more命令。more命令会显示文本文件的内容,但会在显示每页数据之后暂停下来。我们输入命令more /etc/profile会生成图3-4所示的内容
按q退出
more命令只支持文本文件中基本的移动。如果想要更多的高级特性,可以试试less命令。
2.3.3 less命令
less命令还可以在完成整个文件的读取之前显示文件的内容。cat命令和more命令则无法做到这一点。
2.3.4 tail命令
1.tail命令tail命令会显示文件最后几行的内容(文件的“尾部”)。在默认情况下,它会显示文件的末尾10行。作为演示,我们创建一个包含15行文本的文本文件。使用cat命令显示该文件的全部内容如下:
$ cat log_file
line1
line2
line3
line4
Hello World - line5
line6
line7
line8
line9
Hello again World - line10
line11
line12
line13
line14
Last Line - line15
$tail命令有一个非常酷的特性:-f选项,该选项允许你在其他进程使用此文件时查看文件的内容。tail命令会保持活动状态并持续地显示添加到文件中的内容。这是实时监测系统日志的绝佳方式。
2.3.5 head命令
head命令会显示文件开头若干行(文件的“头部”)。在默认情况下,它会显示文件前10行的文本:
$ head log_file
line1
line2
line3
line4
Hello World - line5
line6
line7
line8
line9
Hello again World - line10
$三、linux中的进程管理
1.检测程序
1.1 探查进程 ps
ps命令默认只显示运行在当前终端中属于当前用户的那些进程。
1.Unix风格选项
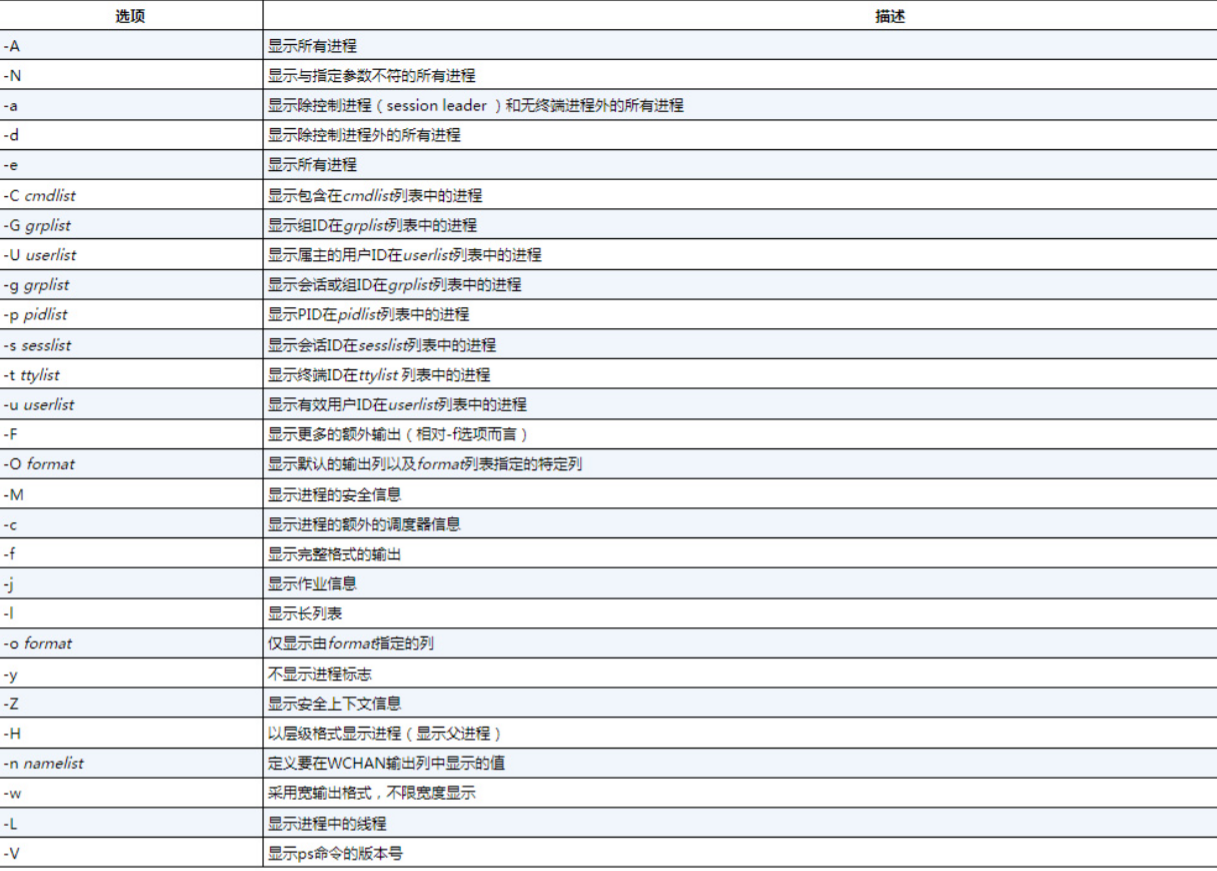
ps -ef命令
·UID:启动该进程的用户。
·PID:进程ID。
·PPID:父进程的PID(如果该进程是由另一个进程启动的)。
·C:进程生命期中的CPU利用率。
·STIME:进程启动时的系统时间。
·TTY:进程是从哪个终端设备启动的。
·TIME:运行进程的累计CPU时间。
·CMD:启动的程序名称
2.GNU风格(常用)

2.实时监控进程
ps命令虽然在收集系统中运行进程的信息时非常有用,但也存在不足之处:只能显示某个特定时间点的信息。如果想观察那些被频繁换入和换出内存的进程,ps命令就不太方便了。这正是top命令的用武之地。与ps命令相似,top命令也可以显示进程信息,但采用的是实时方式。图4-1是top命令运行时的截图。
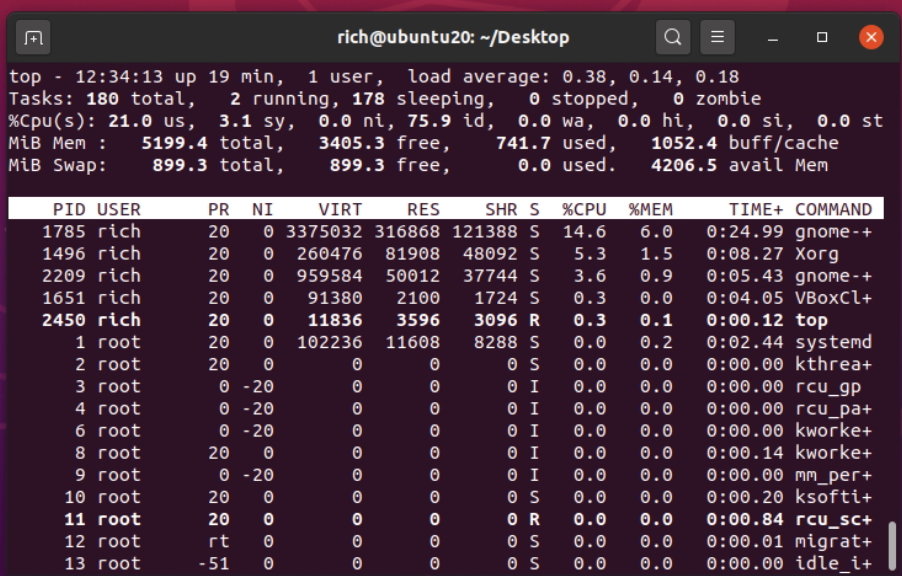
输出的第一部分显示的是系统概况:第一行显示了当前时间、系统的运行时长、登录的用户数以及系统的平均负载。平均负载有3个值,分别是最近1分钟、最近5分钟和最近15分钟的平均负载。值越大说明系统的负载越高。由于进程短期的突发性活动,出现最近1分钟的高负载值也很常见。但如果近15分钟内的平均负载都很高,就说明系统可能有问题了。注意 Linux系统管理的难点在于定义究竟到什么程度才算是高负载。这个值取决于系统的硬件配置以及系统中通常运行的程序。某个系统的高负载可能对其他系统来说就是普通水平。最好的做法是注意在正常情况下系统的负载情况,这样将更容易判断系统何时负载不足。
第二行显示了进程(top称其为task)概况:多少进程处于运行、休眠、停止以及僵化状态(僵化状态指进程已结束,但其父进程没有响应)。
下一行显示了CPU概况。top会根据进程的属主(用户或是系统)和进程的状态(运行、空闲或等待)将CPU利用率分成几类输出。
紧跟其后的两行详细说明了系统内存的状态。前一行显示了系统的物理内存状态:总共有多少内存、当前用了多少,以及还有多少空闲。后一行显示了系统交换空间(如果分配了的话)的状态。
最后一部分显示了当前处于运行状态的进程的详细列表,有些列跟ps命令的输出类似。·PID:进程的PID。·USER:进程属主的用户名。·PR:进程的优先级。·NI:进程的谦让度。·VIRT:进程占用的虚拟内存总量。·RES:进程占用的物理内存总量。·SHR:进程和其他进程共享的内存总量。·S:进程的状态(D代表可中断的休眠,R代表运行,S代表休眠,T代表被跟踪或停止,Z代表僵化)。·%CPU:进程使用的CPU时间比例。·%MEM:进程使用的可用物理内存比例。·TIME+:自进程启动到目前为止所占用的CPU时间总量。·COMMAND:进程所对应的命令行名称,也就是启动的程序名。在默认情况下,top命令在启动时会按照%CPU值来对进程进行排序,你可以在top命令运行时使用多种交互式命令来重新排序。每个交互式命令都是单字符,在top命令运行时键入可改变top的行为。键入f允许你选择用于对输出进行排序的字段,键入d允许你修改轮询间隔(polling interval),键入q可以退出top。用户对top命令输出有很大的控制权。利用该工具,你经常能找出占用系统大量资源的罪魁祸首。当然,找到之后,下一步就是结束这些进程。这也正是接下来的话题。
3.结束进程
身为系统管理员,所需掌握的一项关键技能是知道何时以及如何结束一个进程。有时候,进程会被挂起,此时只需动动手让进程重新运行或结束就行了。有时候,进程会霸占着CPU且拒绝让出。在这两种情景下,都需要能够控制进程的命令。Linux沿用了Unix的进程间通信方法。
在Linux中,进程之间通过信号来通信。进程的信号是预定义好的一个消息,进程能识别该消息并决定忽略还是做出反应。进程如何处理信号是由开发人员通过编程来决定的。大多数编写完善的应用程序能接收和处理标准Unix进程信号。这些信号如表4-4所示。
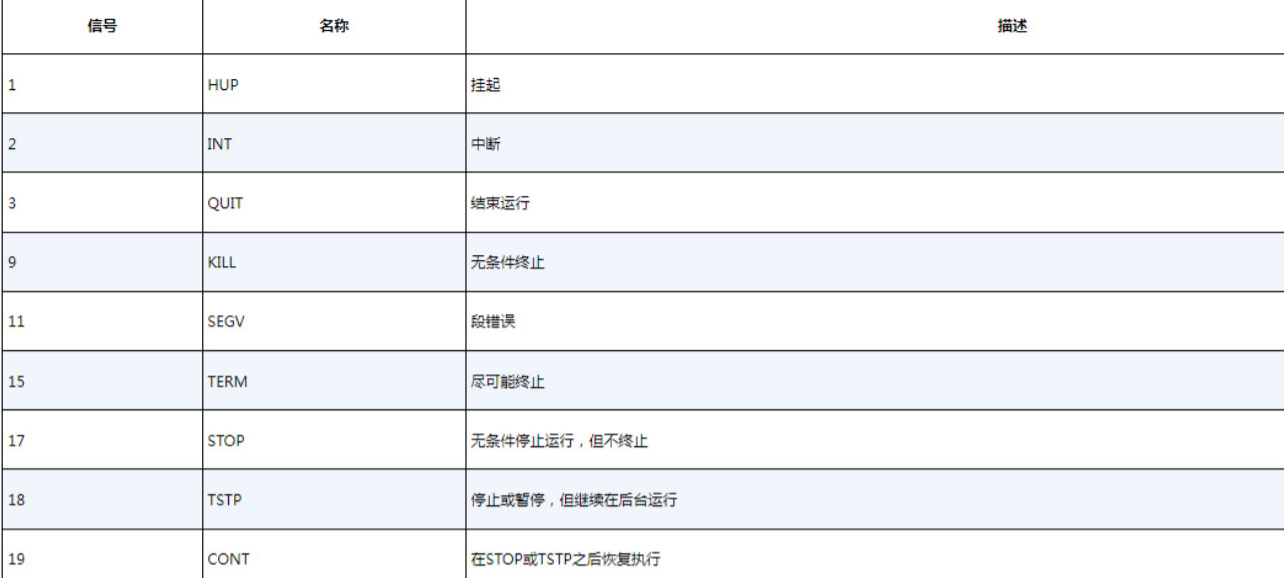
3.1 kill命令
kill命令可以通过PID向进程发送信号。在默认情况下,kill命令会向命令行中列出的所有PID发送TERM信号。遗憾的是,你只能使用进程的PID而不能使用其对应的程序名,这使得kill命令有时并不好用。要发送进程信号,必须是进程的属主或root用户:
3.2 pkill命令
pkill命令可以使用程序名代替PID来终止进程,这就方便多了。除此之外,pkill命令也允许使用通配符,当系统出问题时,这是一个非常有用的工具:
# pkill http*
#该命令将“杀死”所有名称以http起始的进程,比如Apahce Web Server的httpd服务。
警告 以root身份使用pkill命令时要格外小心。命令中的通配符很容易意外地将系统的重要进程终止。这可能会导致文件系统损坏。
4.检测磁盘空间
4.1 挂载存储设备
4.1.1 mount命令
mount命令提供了4部分信息。
·设备文件名
·设备在虚拟目录中的挂载点
·文件系统类型
·已挂载设备的访问状态
要手动在虚拟目录中挂载设备,需要以root用户身份登录,或是以root用户身份运行sudo命令。下面是手动挂载设备的基本命令:
mount -t type device directory其中,type参数指定了磁盘格式化所使用的文件系统类型。Linux可以识别多种文件系统类型。如果与Windows PC共用移动存储设备,那么通常需要使用下列文件系统类型。
4.1.2 umount命令
移除可移动设备时,不能直接将设备拔下,应该先卸载。提示 Linux不允许直接弹出已挂载的CD或DVD。如果在从光驱中移除CD或DVD时遇到麻烦,那么最大的可能是它还在虚拟目录中挂载着。应该先卸载,然后再尝试弹出。
卸载设备的命令是umount(是的,你没看错,命令名中并没有字母“n”,不是“unmount”,这一点有时候很让人困惑)。umount命令的格式非常简单:
umount [directory | device ]umount命令支持通过设备文件或者挂载点来指定要卸载的设备。如果有任何程序正在使用设备上的文件,则系统将不允许卸载该设备。
4.1.3 使用df命令
有时需要知道在某台设备上还有多少磁盘空间。df命令可以方便地查看所有已挂载磁盘的使用情况:
$ df -t ext4 -t vfat
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda5 19475088 7326256 11136508 40% /
/dev/sda2 524272 4 524268 1% /boot/efi
/dev/sdb1 983552 247264 736288 26% /media/
rich/54A1-7D7D
$4.1.4 使用du命令
通过df命令,很容易发现哪个磁盘存储空间不足。系统管理员面临的下一个问题是如何应对这种情况。另一个能助你一臂之力的是du命令。du命令可以显示某个特定目录(默认情况下是当前目录)的磁盘使用情况。这有助于你快速判断系统中是否存在磁盘占用“大户”。
在默认情况下,du命令会显示当前目录下所有的文件、目录和子目录的磁盘使用情况,并以磁盘块为单位来表明每个文件或目录占用了多大存储空间。对标准大小的目录来说,输出内容可不少。下面是du命令的部分输出:
$ du
484 ./.gstreamer-0.10
8 ./Templates
8 ./Download
8 ./.ccache/7/0
24 ./.ccache/7
368 ./.ccache/a/d
384 ./.ccache/a
424 ./.ccache
8 ./Public
8 ./.gphpedit/plugins
32 ./.gphpedit
72 ./.gconfd
128 ./.nautilus/metafiles
384 ./.nautilus
8 ./Videos
8 ./Music
16 ./.config/gtk-2.0
40 ./.config
8 ./Documents每行最左侧的数字是每个文件或目录所占用的磁盘块数。注意,这个列表是从目录层级的最底部开始,然后沿着其中包含的文件和子目录逐级向上的。单纯的du命令作用并不大。我们更想知道每个文件和目录各占用了多大的磁盘空间,但如果还需逐页翻找的话就没什么意义了。
下面这些选项能让du命令的输出更加清晰易读。
·-c:显示所有已列出文件的总大小。
·-h:按人类易读格式输出大小,分别用K表示千字节、M表示兆字节、G表示吉字节。
·-s:输出每个参数的汇总信息。
系统管理员的下一步任务是使用一些文件处理命令来操作大量数据。这正是下一节的主题。
4.2处理数据文件
4.2.1 数据排序
处理大量数据时的一个常用命令是sort。顾名思义,这是用来对数据进行排序的命令
如果希望这些数字按值排序,那你就要失望了。在默认情况下,sort命令会将数字视为字符并执行标准的字符排序,这种结果可能不是你想要的。可以使用-n选项来解决这个问题,该选项会告诉sort命令将数字按值排序:
$ sort -n file2
1
2
3
10
45
75
100
145
$现在好多了。另一个常用的选项是-M,该选择可以将数字按月排序。Linux的日志文件经常在每行的起始位置有一个时间戳,以表明事件是什么时候发生的:
Apr 13 07:10:09 testbox smartd[2718]: Device: /dev/sda, opened如果将含有时间戳日期的文件按默认的排序方法来排序,则会得到如下结果:
$ sort -M file3
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
$
sort -u等同于sort | uniq。在对按字段分隔的数据(比如/etc/passwd文件)进行排序时,-k选项和-t选项非常方便。先使用-t选项指定字段分隔符,然后使用-k选项指定排序字段。例如,要根据用户ID对/etc/passwd按数值排序,可以这么做:
4.2.2 数据搜索 grep
grep [options] pattern [file]grep命令会在输入或指定文件中逐行搜索匹配指定模式的文本。该命令的输出是包含了匹配模式的行。
下面两个简单的例子演示了使用grep命令对4.3.1节中的文件file1进行搜索:
$ grep three file1
three
$ grep t file1
two
three
$如果要进行反向搜索(输出不匹配指定模式的行),可以使用-v选项:
$ grep -v t file1
one
four
five
$如果要显示匹配指定模式的那些行的行号,可以使用-n选项:
$ grep -n t file1
2:two
3:three
$如果只想知道有多少行含有匹配的模式,可以使用-c选项:
$ grep -c t file1
2
$如果要指定多个匹配模式,可以使用-e选项来逐个指定:
$ grep -e t -e f file1
two
three
four
five
$4.2.3 数据压缩
·gzip:用于压缩文件。
·gzcat:用于查看压缩过的文本文件的内容。
·gzcat:用于查看压缩过的文本文件的内容。
$ gzip myprog
$ ls -l my*
-rwxrwxr-x 1 rich rich 2197 2007-09-13 11:29 myprog.gz
$4.3.4 数据归档
虽然zip命令能够很好地将数据压缩并归档为单个文件,但它并不是Unix和Linux中的标准归档工具。目前,Unix和Linux中最流行的归档工具是tar命令。
tar命令的格式如下。
tar function [options] object1 object2 ...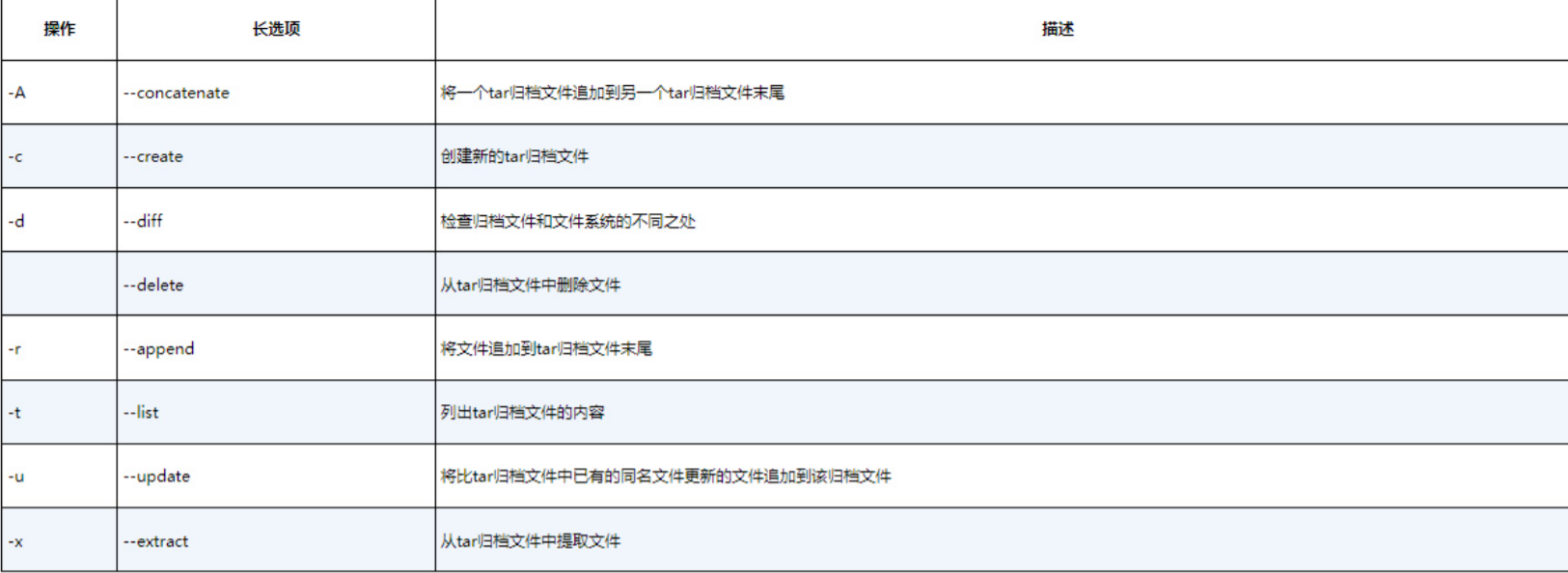
这些选项经常合并使用。可以用下列命令创建归档文件:
tar -cvf test.tar test/ test2/该命令创建了一个名为test.tar的归档文件,包含目录test和test2的内容。
tar -tf test.tar该命令列出了(但不提取)tar文件test.tar的内容。
tar -xvf test.tar提示 在下载开源软件时经常会看到文件名以.tgz结尾,这是经gzip压缩过的tar文件,可以用命令tar -zxvf filename.tgz来提取其中的内容。
四、shell
1.shell的类型
bash文件
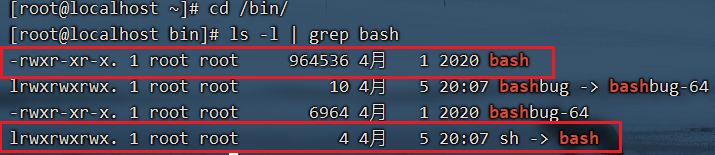
可以查看命令 which bash 查看bash文件的位置
长列表中文件名尾部的星号(*)表明bash文件(bash shell)是一个可执行程序。
$ ls -lF /usr/bin/bash
-rwxr-xr-x. 1 root root 1219248 Nov 8 11:30 /usr/bin/bash*
$注意 在现代Linux系统中,/bin目录通常是/usr/bin/目录的符号链接,这就是为什么用户christine的默认shell程序是/bin/bash,但bash shell程序实际位于/usr/bin/目录。有关符号链接(软链接)的相关内容参见第3章。
该Linux系统中还存在其他的shell程序,其中就有tcsh,其源自最初的C shell:
$ which tcsh
/usr/bin/tcsh
$ ls -lF /usr/bin/tcsh
-rwxr-xr-x. 1 root root 465200 May 14 2019 /usr/bin/tcsh*
$另外还有zsh,这是bash shell另一个更复杂的版本,兼具了tcsh的一些特性和其他元素。一样的查
提示 如果你在自己的Linux系统中没有找到这些shell,可以自行安装,具体方法参见第9章。
在大多数Linux系统中,/etc/shells文件中列出了各种已安装的shell,这些shell可以作为用户的默认shell。
$ cat /etc/shells
/bin/sh
/bin/bash
/usr/bin/sh
/usr/bin/bash
/bin/csh
/bin/tcsh
/usr/bin/csh
/usr/bin/tcsh
/usr/bin/zsh
/bin/zsh
$注意 在很多Linux发行版中,你会发现shell文件似乎存在于两个位置:/bin和/usr/bin。这是因为在现代Linux系统中,/bin是指向/usr/bin的符号链接。有关符号链接(软链接)的相关内容参见第3章。
有了方便的$0变量,就能知道当前使用的shell了。输入命令dash,启动Dash shell,通过echo $0显示新的shell。
$ echo $0
-bash
$
$ dash
$
$ echo $0
dash
$注意 在上面的例子中,注意第一个echo $0命令的输出:bash之前有一个连字符(-)。这表明该shell是用户的登录shell。
2.shell的父子关系
3.查看进程列表
可以在单行中指定要依次运行的一系列命令。这可以通过命令列表来实现,只需将命令之间以分号(;)分隔即可:
$ pwd ; ls test* ; cd /etc ; pwd ; cd ; pwd ; ls my*
/home/christine
test_file test_one test_two
/etc
/home/christine
my_file my_scrapt my_script my_scrypt
$在上面的例子中,所有命令依次执行,没有任何问题。不过这并不是进程列表。要想成为进程列表,命令列表必须将命令放入圆括号内:
$ (pwd ; ls test* ; cd /etc ; pwd ; cd ; pwd ; ls my*)
/home/christine
test_file test_one test_two
/etc
/home/christine
my_file my_scrapt my_script my_scrypt
$尽管多出来的圆括号看起来没什么太大的不同,但起到的效果确是非同寻常。圆括号的加入使命令列表摇身变成了进程列表,生成了一个子shell来执行这些命令。
注意 进程列表是命令分组(command grouping)的一种。另一种命令分组是将命令放入花括号内,并在命令列表尾部以分号(;)作结。语法为:{ command; }。使用花括号进行命令分组并不会像进程列表那样创建子shell。要想知道是否生成了子shell,需要使用命令输出一个环境变量(参见第6章)的值。这个命令就是echo $BASH_SUBSHELL。如果该命令返回0,那么表明没有子shell。如果该命令返回1或者其他更大的数字,则表明存在子shell。
4.子shell的用法
5.协程
协程同时做两件事:一是在后台生成一个子shell,二是在该子shell中执行命令。要进行协程处理,可以结合使用coproc命令以及要在子shell中执行的命令:
$ coproc sleep 10
[1] 2689
$6.理解外部命令和内建命令
6.1外部命令
外部命令(有时也称为文件系统命令)是存在于bash shell之外的程序。也就是说,它并不属于shell程序的一部分。外部命令程序通常位于 /bin、/usr/bin、/sbin或 /usr/sbin目录中。ps命令就是一个外部命令。可以使用which命令和type命令找到其对应的文件名:
$ which ps
/usr/bin/ps
$
$ type ps
ps is /usr/bin/ps
$
$ ls -l /usr/bin/ps
-rwxr-xr-x. 1 root root 142216 May 11 2019 /usr/bin/ps
$每当执行外部命令时,就会创建一个子进程。这种操作称为衍生(forking)。外部命令ps会显示其父进程以及自己所对应的衍生子进程:
$ ps -f
UID PID PPID C STIME TTY TIME CMD
christi+ 2367 2363 0 10:47 pts/0 00:00:00 -bash
christi+ 4242 2367 0 13:48 pts/0 00:00:00 ps -f
$在使用内建命令时,不需要衍生子进程。因此,内建命令的系统开销较低。
6.2 内建命令
与外部命令不同,内建命令无须使用子进程来执行。内建命令已经和shell编译成一体,作为shell的组成部分存在,无须借助外部程序文件来执行。
cd命令和exit命令都内建于bash shell。可以使用type命令来判断某个命令是否为内建:
$ type cd
cd is a shell builtin
$
$ type exit
exit is a shell builtin
$注意,有些命令有多种实现。例如,echo和pwd既有内建命令也有外部命令。两种实现略有差异。要查看命令的不同实现,可以使用type命令的 -a选项:
$ type -a echo
echo is a shell builtin
echo is /usr/bin/echo
$
$ which echo
/usr/bin/echo
$
$ type -a pwd
pwd is a shell builtin
pwd is /usr/bin/pwd
$
$ which pwd
/usr/bin/pwd
$提示 对于有多种实现的命令,如果想使用其外部命令实现,直接指明对应的文件即可。例如,要使用外部命令pwd,可以入/usr/bin/pwd。
6.2.1 使用history命令
bash shell会跟踪你最近使用过的命令。你可以重新唤回这些命令,甚至加以重用。history是一个实用的内建命令,能帮助你管理先前执行过的命令。
要查看最近用过的命令列表,可以使用不带任何选项的history命令:
$ history
1 ps -f
2 pwd
3 ls
4 coproc ( sleep 10; sleep 2 )
5 jobs
6 ps --forest
7 ls
8 ps -f
9 pwd
10 ls -l /usr/bin/ps
11 history
12 cd /etc
13 pwd
14 ls
15 cd
16 type -a pwd
17 which pwd
18 type -a echo
19 which echo
20 ls
[...]
$6.2.2.使用命令别名
alias命令是另一个实用的shell内建命令。命令别名允许为常用命令及其参数创建另一个名称,从而将输入量减少到最低。你所使用的Linux发行版很有可能已经为你设置好了一些常用命令的别名。使用alias命令以及选项 -p可以查看当前可用的别名:
$ alias -p
[...]
alias l='ls -CF'
alias la='ls -A'
alias ll='ls -alF'
alias ls='ls --color=auto'
$注意,在该Ubuntu Linux发行版中,有一个别名取代了标准命令ls。该别名中加入了 --color=auto选项,以便在终端支持彩色显示的情况下,ls命令可以使用色彩编码(比如,使用蓝色表示目录)。LS_COLORS环境变量(环境变量的相关内容参见第6章)控制着所用的色彩编码。提示 如果经常跳转于不同的发行版,那么在使用色彩编码来分辨某个名称究竟是目录还是文件时,一定要小心。因为色彩编码并未实现标准化,所以最好使用ls -F来判断文件类型。
可以使用alias命令创建自己的别名:
$ alias li='ls -i
$
$ li
34665652 Desktop 1415018 NetworkManager.conf
1414976 Doc.tar 50350618 OldDocuments
34665653 Documents 1414981 Pictures
51693739 Downloads 16789591 Public
1415016 hlink_test_one 1415019 really_ridiculously_long_file_name
1415021 log_file 1415020 slink_test_file
51693757 Music 1415551 Templates
1414978 Music.tar 1415523 test_file
1415525 my_file 1415016 test_one
1415524 my_scrapt 1415017 test_two
1415519 my_script 16789592 Videos
1415015 my_scrypt
$定义好别名之后,就可以随时在shell或者shell脚本中使用了。要注意,因为命令别名属于内建命令,所以别名仅在其被定义的shell进程中才有效。
五、linux的环境变量
1、什么是环境变量
bash shell使用环境变量来存储shell会话和工作环境的相关信息(这也是被称作环境变量的原因)。环境变量允许在内存中存储数据,以便shell中运行的程序或脚本能够轻松访问到这些数据。这也是存储持久数据的一种简便方法。bash shell中有两种环境变量。全局变量和局部变量
1.1 全局环境变量
全局环境变量对于shell会话和所有生成的子shell都是可见的。局部环境变量则只对创建它的shell可见。如果程序创建的子shell需要获取父shell信息,那么全局环境变量就能派上用场了。
Linux系统在你启动bash会话时就设置好了一些全局环境变量(6.6节将展示具体都有哪些变量)。系统环境变量基本上会使用全大写字母,以区别于用户自定义的环境变量。可以使用env命令或printenv命令来查看全局变量:
$ printenv
[...]
USER=christine
[...]
PWD=/home/christine
HOME=/home/christine
[...]
TERM=xterm
SHELL=/bin/bash
[...]
HISTSIZE=1000
[...]
$也可以使用echo命令显示变量的值。在引用某个环境变量时,必须在该变量名前加上美元符号($):
$ echo $HOME
/home/Christine
$如前所述,全局环境变量可用于进程的子shell:
$ bash
$ ps -f
UID PID PPID C STIME TTY TIME CMD
christi+ 2770 2766 0 11:19 pts/0 00:00:00 -bash
christi+ 2981 2770 4 11:37 pts/0 00:00:00 bash
christi+ 3003 2981 0 11:37 pts/0 00:00:00 ps -f
$
$ echo $HOME
/home/christine
$ exit
exit
$在这个例子中,用bash命令生成一个子shell后,显示了HOME环境变量的当前值。这个值和父shell中的值一模一样,都是/home/christine。
1.2 局部环境变量
顾名思义,局部环境变量只能在定义它的进程中可见。尽管是局部的,但是局部环境变量的重要性丝毫不输全局环境变量。事实上,Linux系统默认也定义了标准的局部环境变量。不过,你也可以定义自己的局部变量,如你所料,这些变量被称为用户自定义局部变量
在命令行中查看局部环境变量列表有点儿棘手。遗憾的是,没有哪个命令可以只显示这类变量。set命令可以显示特定进程的所有环境变量,既包括局部变量、全局变量,也包括用户自定义变量:
$ set
BASH=/bin/bash
[...]
HOME=/home/christine
[...]
PWD=/home/christine
[...]
SHELL=/bin/bash
[...]
TERM=xterm
[...]
USER=christine
[...]
colors=/home/christine/.dircolors
my_variable='Hello World'
[...]
_command ()
{
[...]
$注意 env命令、printenv命令和set命令之间的差异很细微。set命令既会显示全局和局部环境变量、用户自定义变量以及局部shell函数,还会按照字母顺序对结果进行排序。与set命令不同,env命令和printenv命令既不会对变量进行排序,也不会输出局部环境变量、局部用户自定义变量以及局部shell函数。在这种情况下,env命令和printenv命令的输出是重复的。不过,env命令有printenv命令不具备的一个功能,这使其略胜一筹。
1.3设置用户自定义变量
1.3.1 设置局部用户自定义变量
启动bash shell(或者执行shell脚本)之后,就能创建仅对该shell进程可见的局部用户自定义变量。可以使用等号为变量赋值,值可以是数值或字符串:
$ my_variable=Hello
$ echo $my_variable
Hello
$设置好局部变量后,就能在shell进程中随意使用了。但如果又生成了另一个shell,则该变量在子shell中不可用:
$ my_variable="Hello World"
$
$ bash
$ echo $my_variable
$ exit
exit
$ echo $my_variable
Hello World
$在本例中,通过bash命令生成了一个子shell。用户自定义变量my_variable无法在该子shell中使用。echo $my_variable命令返回的空行就是证据。当你退出子shell,返回到原来的shell中时,这个局部变量依然可用。
类似地,如果在子进程中设置了一个局部变量,那么一旦退出子进程,该局部变量就不能用了:
$ echo $my_child_variable
$ bash
$ my_child_variable="Hello Little World"
$ echo $my_child_variable
Hello Little World
$ exit
exit
$ echo $my_child_variable
$返回父shell后,子shell中设置的局部变量就不存在了。可以通过将局部用户自定义变量改为全局变量来解决这个问题
1.3.2 设置全局环境变量
全局环境变量在设置该变量的父进程所创建的子进程中都是可见的。创建全局环境变量的方法是先创建局部变量,然后再将其导出到全局环境中。
$ my_variable="I am Global now"
$
$ export my_variable
$
$ echo $my_variable
I am Global now
$ bash
$ echo $my_variable
I am Global now
$ exit
exit
$ echo $my_variable
I am Global now
$但是修改子shell中的全局环境变量并不会影响父shell中该变量的值:
$ export my_variable="I am Global now"
$ echo $my_variable
I am Global now
$
$ bash
$ echo $my_variable
I am Global now
$ my_variable="Null"
$ echo $my_variable
Null
$ exit
exit
$
$ echo $my_variable
I am Global now
$1.3.3 删除环境变量
既然可以创建新的环境变量,自然也能删除已有的环境变量。可以用unset命令来完成这个操作。在unset命令中引用环境变量时,记住不要使用$。
$ my_variable="I am going to be removed"
$ echo $my_variable
I am going to be removed
$
$ unset my_variable
$ echo $my_variable
$提示 在涉及环境变量名时,什么时候该使用$,什么时候不该使用$,实在让人摸不着头脑。只需记住一点:如果要用到(doing anything with)变量,就使用$;如果要操作(doing anything to)变量,则不使用$。这条规则的一个例外是使用printenv显示某个变量的值。
和修改变量一样,在子shell中删除全局变量后,无法将效果反映到父shell中。
1.3.4 默认的shell环境变量
在默认情况下,bash shell会用一些特定的环境变量来定义系统环境。这些变量在你的Linux系统中都已设置好,只管放心使用就行了。由于bash shell源自最初的Unix Bourne shell,因此也保留了Unix Bourne shell中定义的那些环境变量。



1.3.5 设置PATH环境变量
当你在shell CLI中输入一个外部命令(参见第5章)时,shell必须搜索系统,从中找到对应的程序。PATH环境变量定义了用于查找命令和程序的目录。在本书所用的Ubuntu Linux系统中,PATH环境变量的内容如下所示:
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:
/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
$PATH中的目录之间以冒号分隔。输出中显示共有9个目录,shell会在其中查找命令和程序。
如果命令或者程序所在的位置没有包括在PATH变量中,那么在不使用绝对路径的情况下,shell是无法找到的。shell在找不到指定的命令或程序时会产生错误信息:
如果命令或者程序所在的位置没有包括在PATH变量中,那么在不使用绝对路径的情况下,shell是无法找到的。shell在找不到指定的命令或程序时会产生错误信息:
$ myprog
myprog: command not found
$应用程序的可执行文件目录有时不在PATH环境变量所包含的目录中。解决方法是保证PATH环境变量包含所有存放应用程序的目录。
注意 有些脚本编写人员使用env命令作为bash shell脚本(参见第11章)的第一行,就像这样:#!/usr/bin/env bash。这种方法的优点在于env会在$PATH中搜索bash,使脚本具备更好的可移植性。
你可以把新的搜索目录添加到现有的PATH环境变量中,无须从头定义。PATH中各个目录之间以冒号分隔。只需引用原来的PATH值,添加冒号(:),然后再使用绝对路径输入新目录即可。在CentOS Linux系统中,就像下面这样:
$ ls /home/christine/Scripts/
myprog
$ echo $PATH
/home/christine/.local/bin:/home/christine/bin:/usr/local/bin:/usr/
bin:/usr/local/sbin:/usr/sbin
$
$ PATH=$PATH:/home/christine/Scripts
$
$ myprog
The factorial of 5 is 120
$提示 如果希望程序位置也可用于子shell,则务必确保将修改后的PATH环境变量导出。对于PATH变量的修改只能持续到退出或重启系统。这种效果并不能一直奏效。下一节会介绍如何永久保持环境变量的改动。
1.3.6 定位系统环境变量
环境变量在Linux系统中的用途很多。你现在已经知道如何修改系统环境变量,也知道如何创建自己的变量。接下来的问题是怎样让环境变量的作用持久化。
当你登录Linux系统启动bash shell时,默认情况下bash会在几个文件中查找命令。这些文件称作启动文件或环境文件。bash进程的启动文件取决于你启动bash shell的方式。启动bash shell有以下3种方式:·登录时作为默认登录shell;·作为交互式shell,通过生成子shell启动;·作为运行脚本的非交互式shell。下面几节介绍了bash shell在不同启动方式下执行的启动文件。
1.4数组变量
要为某个环境变量设置多个值,可以把值放在圆括号中,值与值之间以空格分隔:
$ mytest=(zero one two three four)
$没什么特别的地方。如果想像普通环境变量那样显示数组,你会失望的:
$ echo $mytest
zero
$以上代码只显示了数组的第一个值。要引用单个数组元素,必须使用表示其在数组中位置的索引。索引要写在方括号中,$符号之后的所有内容都要放入花括号中。
$ echo ${mytest[2]}
two
$提示 环境变量数组的索引都是从0开始的。这通常会带来一些困惑。要显示整个数组变量,可以用通配符*作为索引:
$ echo ${mytest[*]}
zero one two three four
$也可以改变某个索引位置上的值:
$ mytest[2]=seven
$ echo ${mytest[2]}
seven
$甚至能用unset命令来删除数组中的某个值,但是要小心,这有点儿复杂。看下面的例子
$ unset mytest[2]
$ echo ${mytest[*]}
zero one three four
$
$ echo ${mytest[2]}
$ echo ${mytest[3]}
three
$这个例子用unset命令来删除索引2位置上的值。显示整个数组时,看起来好像其他索引已经填补了这个位置。但如果专门显示索引2位置上的值时,你会发现这个位置是空的。可以在unset命令后跟上数组名来删除整个数组:
$ unset mytest
$ echo ${mytest[*]}
$有时候,数组变量只会把事情搞得更复杂,所以在shell脚本编程时并不常用。数组并不太方便移植到其他shell环境,如果需要在不同的shell环境中从事大量的脚本编写工作,这是一个不足之处。有些bash系统环境变量用到了数组(比如BASH_VERSINFO),但总体而言,你不会经常碰到数组。
六、理解Linux文件权限
1、对于新用户的增删改查
Linux安全系统的核心是用户账户。每个能访问Linux系统的用户都会被分配一个唯一的用户账户。用户对系统中各种对象的访问权限取决于他们登录系统时所用的账户。用户权限是通过创建用户时分配的用户ID(user ID,UID)来跟踪的。UID是个数值,每个用户都有一个唯一的UID。但用户在登录系统时是使用登录名(login name)来代替UID登录的。登录名是用户用来登录系统的最长8字符的字符串(字符可以是数字或字母),同时会关联一个对应的密码。Linux系统使用特定的文件和工具来跟踪及管理系统的用户账户。在讨论文件权限之前,先来看一下Linux是怎样处理用户账户的。本节将介绍管理用户账户所需要的文件和工具,这样在处理文件权限问题时,你就知道如何使用它们了。
6.1.1 /etc/passwd文件
Linux系统使用一个专门的文件/etc/passwd来匹配登录名与对应的UID值。该文件包含了一些与用户有关的信息。下面是Linux系统中典型的/etc/passwd文件示例:
$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
...
rich:x:500:500:Rich Blum:/home/rich:/bin/bash
mama:x:501:501:Mama:/home/mama:/bin/bash
katie:x:502:502:katie:/home/katie:/bin/bash
jessica:x:503:503:Jessica:/home/jessica:/bin/bash
mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/bash
$文件内容很长,我们做了部分删减。root用户账户是Linux系统的管理员,为其固定分配的UID是0。如你所见,Linux系统会为各种各样的功能创建不同的用户账户,而这些账户并非真正的人类用户。我们称其为系统账户,它们是系统中运行的各种服务进程访问资源使用的特殊账户。所有运行在后台的服务都需要通过一个系统用户账户登录到Linux系统中。在安全成为一个大问题之前,这些服务经常用root用户账户登录。遗憾的是,如果有非授权的用户攻陷了其中某个服务,那么他立刻就能作为root用户访问系统了。为了防止这种情况发生,现在运行在Linux服务器后台的大多数服务是用自己的账户登录。这样一来,即便有人攻陷了某个服务,也无法获取整个系统的访问权。Linux为系统账户预留了500以下的UID。有些服务甚至要用特定的UID才能正常工作。为普通用户创建账户时,大多数Linux系统会从500开始,将第一个可用UID分配给这个账户。(并非所有的Linux发行版都是这样,比如Ubuntu就是从1000开始的。)
你可能已经注意到/etc/passwd文件中包含的内容远不止用户的登录名和UID。该文件各个字段的含义如下。·登录用户名·用户密码·用户账户的UID(数字形式)·用户账户的组ID(数字形式)·用户账户的文本描述(称为备注字段)·用户$HOME目录的位置·用户的默认shell
你可能已经注意到/etc/passwd文件中包含的内容远不止用户的登录名和UID。该文件各个字段的含义如下。·登录用户名·用户密码·用户账户的UID(数字形式)·用户账户的组ID(数字形式)·用户账户的文本描述(称为备注字段)·用户$HOME目录的位置·用户的默认shell
1.2 /etc/shadow文件
/etc/shadow文件对Linux系统密码管理提供了更多的控制。只有root用户才能访问/etc/shadow文件,这使其与/etc/passwd相比要安全许多。/etc/shadow文件为系统中的每个用户账户都保存了一条记录。记录就像下面这样。
rich:$1$.FfcK0ns$f1UgiyHQ25wrB/hykCn020:11627:0:99999:7:::/etc/shadow文件中的每条记录共包含9个字段。·登录名,对应于/etc/passwd文件中的登录名。·加密后的密码。·自上次修改密码后已经过去的天数(从1970年1月1日开始计算)。·多少天后才能更改密码。·多少天后必须更改密码。·密码过期前提前多少天提醒用户更改密码。·密码过期后多少天禁用用户账户。·用户账户被禁用的日期(以从1970年1月1日到当时的天数表示)。·预留给以后使用的字段。
1.3 添加新用户
用来向Linux系统添加新用户的主要工具是useradd。该命令可以一次性轻松创建新用户账户并设置用户的$HOME目录结构。useradd命令使用系统的默认值以及命令行参数来设置用户账户。要想查看所使用的Linux发行版的系统默认值,可以使用加入了-D选项的useradd命令。
# useradd -D
GROUP=100
HOME=/home
INACTIVE=-1
EXPIRE=
SHELL=/bin/bash
SKEL=/etc/skel
CREATE_MAIL_SPOOL=yes
#注意 useradd命令的默认值使用/etc/default/useradd文件设置。另外,进一步的安全设置在/etc/login.defs文件中定义。你可以调整这些文件,改变Linux系统默认的安全行为。-D选项显示了在命令行中创建新用户账户时,如果不明确指明具体值,useradd命令所使用的默认值。这些默认值的含义如下。·新用户会被添加到GID为100的公共组。·新用户的主目录会位于/home/loginname。·新用户账户密码在过期后不会被禁用。·新用户账户不设置过期日期。·新用户账户将bash shell作为默认shell。·系统会将/etc/skel目录的内容复制到用户的$HOME目录。·系统会为该用户账户在mail目录下创建一个用于接收邮件的文件。
useradd命令允许管理员创建默认的$HOME目录配置,然后将其作为创建新用户$HOME目录的模板。这样就能自动在每个新用户的$HOME目录里放置默认的系统文件了。在Ubuntu Linux系统中,/etc/skel目录包含下列文件:
$ ls -al /etc/skel
total 32
drwxr-xr-x 2 root root 4096 2010-04-29 08:26 .
drwxr-xr-x 135 root root 12288 2010-09-23 18:49 ..
-rw-r--r-- 1 root root 220 2010-04-18 21:51 .bash_logout
-rw-r--r-- 1 root root 3103 2010-04-18 21:51 .bashrc
-rw-r--r-- 1 root root 179 2010-03-26 08:31 examples.desktop
-rw-r--r-- 1 root root 675 2010-04-18 21:51 .profile
$根据第6章的内容,你应该知道这些文件是做什么的。它们是bash shell环境的标准启动文件。系统会自动将这些默认文件复制到你创建的每个用户的$HOME目录。可以用默认系统参数创建一个新用户账户,然后检查一下新用户的$HOME目录:
# useradd -m test
# ls -al /home/test
total 24
drwxr-xr-x 2 test test 4096 2010-09-23 19:01 .
drwxr-xr-x 4 root root 4096 2010-09-23 19:01 ..
-rw-r--r-- 1 test test 220 2010-04-18 21:51 .bash_logout
-rw-r--r-- 1 test test 3103 2010-04-18 21:51 .bashrc
-rw-r--r-- 1 test test 179 2010-03-26 08:31 examples.desktop
-rw-r--r-- 1 test test 675 2010-04-18 21:51 .profile
#对很多Linux发行版而言,useradd命令默认并不创建$HOME目录,但是-m命令行选项会使其创建$HOME目录。你可以在/etc/login.defs文件中更改该行为。正如以上例子所展示的,useradd命令创建了新的$HOME目录,并将/etc/skel目录中的文件复制了过来。注意 本章中提到的用户账户管理命令需要以root用户账户登录或者通过sudo命令运行。
1.4 删除用户
如果想从系统中删除用户,userdel可以满足这个需求。在默认情况下,userdel命令只删除/etc/passwd和/etc/shadow文件中的用户信息,属于该账户的文件会被保留。如果加入-r选项,则userdel会删除用户的$HOME目录以及邮件目录。然而,系统中仍可能存有已删除用户的其他文件。这在有些环境中会造成问题。下面是用userdel命令删除已有用户账户的一个例子:
# userdel -r test
# ls -al /home/test
ls: cannot access /home/test: No such file or directory
#加入-r选项后,用户先前的/home/test目录就不存在了。警告 在有大量用户的环境中使用-r选项要特别小心。你永远不知道用户是否在个人的$HOME目录中存放了其他用户或程序要用到的重要文件。在删除用户的$HOME目录之前一定要检查清楚。
1.5 修改用户
Linux提供了一些工具来修改已有用户账户的信息,如表7-3所示。表7-3 用户账户修改工具

1.usermodusermod命令
是用户账户修改工具中最强大的一个,提供了修改/etc/passwd文件中大部分字段的相关选项,只需指定相应的选项即可。大部分选项与useradd命令的选项一样(比如-c用于修改备注字段,-e用于修改过期日期,-g用于修改默认的登录组)。除此之外,还有另外一些也许能派上用场的选项。·-l:修改用户账户的登录名。·-L:锁定账户,禁止用户登录。·-p:修改账户密码。·-U:解除锁定,恢复用户登录。·-L:选项尤为实用。该选项可以锁定账户,使用户无法登录,无须删除账户和用户数据。要恢复账户,只需使用-U选项即可。
2.passwd和chpasswdpasswd命令可以方便地修改用户密码:
# passwd test
Changing password for user test.
New UNIX password:
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
#如果只使用passwd命令,则修改的是你自己的密码。系统中的任何用户都能修改自己的密码,但只有root用户才有权限修改别人的密码。-e选项可以强制用户下次登录时修改密码。你可以先给用户设置一个简单的密码,之后强制用户在下次登录时改成他们能记住的更复杂的密码。如果需要为系统中的大量用户修改密码,那么chpasswd命令可以助你事半功倍。chpasswd命令能从标准输入自动读取一系列以冒号分隔的登录名和密码对偶(login name and password pair),自动对密码加密,然后为用户账户设置密码。你也可以用重定向命令将包含username:password对偶的文件重定向给该命令。
3.chsh、chfn和chage
chsh、chfn和chage用于修改特定的账户信息。chsh命令可以快速修改默认的用户登录shell。使用时必须用shell的全路径名作为参数,不能只用shell名:
# chsh -s /bin/csh test
Changing shell for test.
Shell changed.
#chfn命令提供了在/etc/passwd文件的备注字段中保存信息的标准方法。chfn命令会将用于Unix的finger命令的信息存入备注字段,而不是简单地写入一些随机文本(比如名字或昵称之类),或是干脆将备注字段留空。finger命令可以非常方便地查看Linux系统的用户信息。
# finger rich
Login: rich Name: Rich Blum
Directory: /home/rich Shell: /bin/bash
On since Thu Sep 20 18:03 (EDT) on pts/0 from 192.168.1.2
No mail.
No Plan.
#1.6 使用Linux组
用户账户在控制单个用户安全性方面还不错,但涉及共享资源的一组用户时就捉襟见肘了。为了解决这个问题,Linux系统采用了另一个安全概念——组。
组权限允许多个用户对系统对象(比如文件、目录或设备等)共享一组权限(参见7.3节)。
Linux发行版在处理默认组的成员关系时略有差异。有些Linux发行版会创建一个组,将所有用户都作为该组的成员。遇到这种情况要特别小心,因为你的文件有可能对于其他用户也是可读的。有些发行版会为每个用户创建一个单独的组,这样会更安全一些。每个组都有唯一的GID,和UID类似,该值在系统中是唯一的。除了GID,每个组还有一个唯一的组名。Linux系统中有一些组工具可用于创建和管理组。本节将讨论如何保存组信息以及如何用组工具来创建新组和修改已有的组
1.6.1 /etc/group文件
与用户账户类似,组信息也保存在一个文件中。/etc/group文件包含系统中每个组的信息。下面是Linux系统中一个典型的/etc/group文件示例:
root:x:0:root
bin:x:1:root,bin,daemon
daemon:x:2:root,bin,daemon
sys:x:3:root,bin,adm
adm:x:4:root,adm,daemon
rich:x:500:
mama:x:501:
katie:x:502:
jessica:x:503:
mysql:x:27:
test:x:504:与UID类似,GID在分配时也采用了特定的格式。对于系统账户组,为其分配的GID值低于500,而普通用户组的GID则从500开始分配。/etc/group文件有4个字段。·组名·组密码·GID·属于该组的用户列表组密码允许非组内成员使用密码临时性地成为该组成员。这个功能用得不多,但确实存在。由于/etc/group文件是一个标准的文本文件,因此可以手动编辑该文件来添加和修改组成员关系。但一定要小心,千万不要出现任何拼写错误,否则可能会损坏文件,引发系统故障。更安全的做法是使用usermod命令(参见7.1.5节)向组中添加用户。在将用户添加到不同的组之前,必须先创建组。
注意 用户账户列表多少有些误导人。你会发现列表中的一些组没有任何用户。这并不是说这些组没有成员。当一个用户在/etc/passwd文件中指定某个组作为主要组时,该用户不会作为该组成员再出现在/etc/group文件中。多年来被这个问题困扰的系统管理员可不止一两个。
1.6.2 创建新组
groupadd命令可用于创建新组:groupadd -r [组名称]
# /usr/sbin/groupadd shared
# tail /etc/group
haldaemon:x:68:
xfs:x:43:
gdm:x:42:
rich:x:500:
mama:x:501:
katie:x:502:
jessica:x:503:
mysql:x:27:
test:x:504:
shared:x:505:
#在创建新组时,默认不为其分配任何用户。groupadd命令没有提供向组中添加用户的选项,但可以用usermod命令来解决:
# /usr/sbin/usermod -G shared rich
# /usr/sbin/usermod -G shared test
# tail /etc/group
haldaemon:x:68:
xfs:x:43:
gdm:x:42:
rich:x:500:
mama:x:501:
katie:x:502:
jessica:x:503:
mysql:x:27:
test:x:504:
shared:x:505:rich, test
#shared组现在有两个成员:test和rich。usermod命令的-G选项会把这个新组添加到该用户账户的组列表中。注意 如果更改了已登录系统的用户所属的组,则该用户必须注销后重新登录,这样新的组关系才能生效。警告 为用户分配组时要格外小心。如果使用了-g选项,则指定的组名会替换掉在/etc/passwd文件中为该用户分配的主要组。-G选项则会将该组加入该用户的属组列表,不会影响主要组。
1.6.3 修改组
正如你在/etc/group文件中看到的,需要修改的组信息并不多。groupmod命令可以修改已有组的GID(使用-g选项)或组名(使用-n选项):
# groupmod -n sharing shared
# tail /etc/group
haldaemon:x:68:
xfs:x:43:
gdm:x:42:
rich:x:500:
mama:x:501:
katie:x:502:
jessica:x:503:
mysql:x:27:
test:x:504:
sharing:x:505:test,rich
#修改组名时,GID和组成员保持不变,只有组名会改变。由于所有的安全权限均基于GID,因此可以随意改变组名,不会影响文件的安全性。
1.7 理解文件权限
现在你已经知道了用户和组,是时候解读ls命令输出中出现的谜一般的文件权限了。本节将介绍如何解读权限及其设置方法。
1.7.1 使用文件权限符号
回忆一下第3章的内容,ls命令可以查看Linux系统中的文件、目录和设备的权限。
$ ls -l
total 68
-rw-rw-r-- 1 rich rich 50 2010-09-13 07:49 file1.gz
-rw-rw-r-- 1 rich rich 23 2010-09-13 07:50 file2
-rw-rw-r-- 1 rich rich 48 2010-09-13 07:56 file3
-rw-rw-r-- 1 rich rich 34 2010-09-13 08:59 file4
-rwxrwxr-x 1 rich rich 4882 2010-09-18 13:58 myprog
-rw-rw-r-- 1 rich rich 237 2010-09-18 13:58 myprog.c
drwxrwxr-x 2 rich rich 4096 2010-09-03 15:12 test1
drwxrwxr-x 2 rich rich 4096 2010-09-03 15:12 test2
$输出结果的第一个字段就是描述文件和目录权限的编码。这个字段的第一个字符表示对象的类型。·-代表文件·d代表目录·l代表链接·c代表字符设备·b代表块设备·p代表具名管道·s代表网络套接字
之后是3组三字符的编码。每一组定义了3种访问权限。·r代表对象是可读的·w代表对象是可写的·x代表对象是可执行的
之后是3组三字符的编码。每一组定义了3种访问权限。·r代表对象是可读的·w代表对象是可写的·x代表对象是可执行的
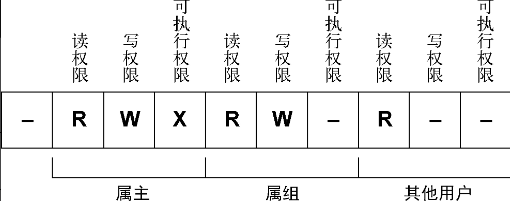
讨论这个问题的最简单的办法是找个文件作例子,逐一分析文件权限。
-rwxrwxr-x 1 rich rich 4882 2010-09-18 13:58 myprog文件myprog具有以下3组权限。·rwx:属主(rich)权限。·rwx:属组(rich)权限。·r-x:系统其他用户权限。这些权限表明用户rich可以读取、写入以及执行该文件(有全部权限)。类似地,rich组的成员也可以读取、写入以及执行该文件。然而,不属于rich组的其他用户只能读取和执行该文件:w被连字符取代了,说明这个安全级别没有写入权限。
1.7.2 默认文件权限
你可能会问这些文件权限从何而来,答案是umask。umask命令用来设置新建文件和目录的默认权限:
$ touch newfile
$ ls -al newfile
-rw-r--r-- 1 rich rich 0 Sep 20 19:16 newfile
$touch命令使用分配给当前用户的默认权限创建了新文件。umask命令可以显示和设置默认权限:
$ umask
0022
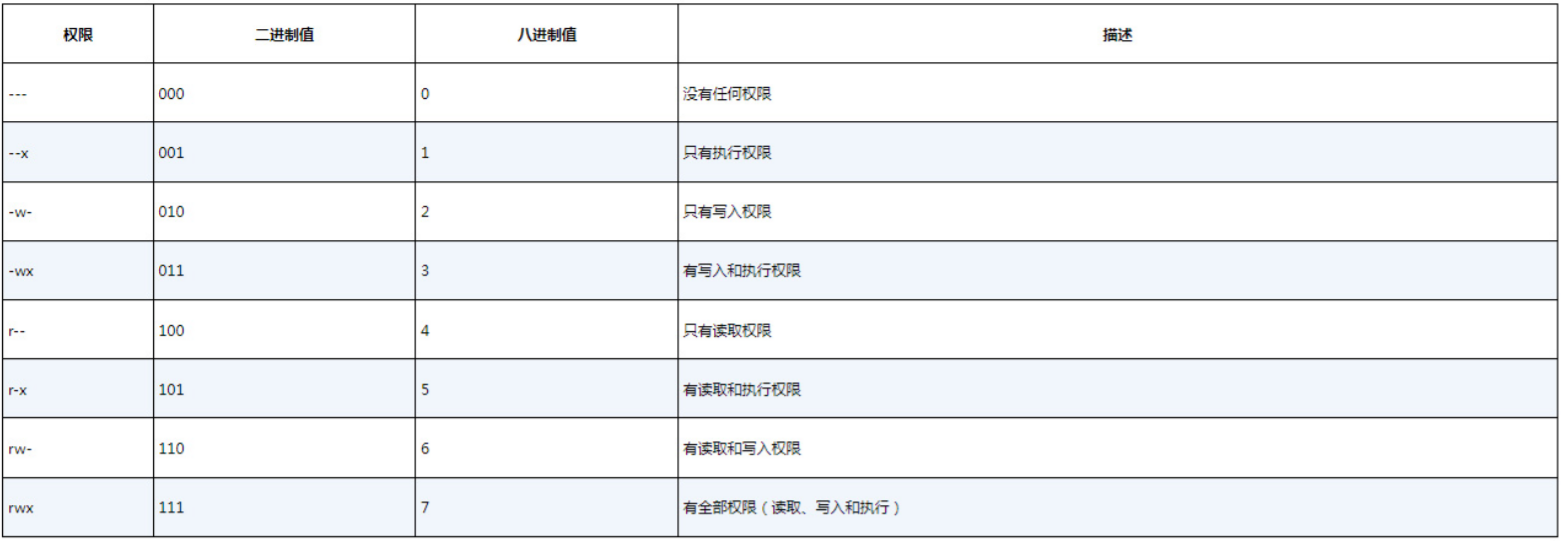
$遗憾的是,umask命令的设置方法不是那么简单明了,其中的工作原理更是让人一头雾水。第一个数位(digit)代表了一项特别的安全特性。7.5节会详述。接下来的3个数位表示文件或目录对应的umask八进制值。要理解umask是如何工作的,先得弄清楚八进制模式的安全设置。八进制模式的安全设置先获取rwx权限值,然后将其转换成3位(bit)二进制值,用一个八进制值来表示。在二进制表示中,每个位置代表一个二进制位。因此,如果读权限是唯一置位的权限,则权限值是r--,转换成二进制值就是100,代表的八进制值是4。表7-5列出了可能会遇到的组合。
1.8 更改安全设置
1.8.1 修改权限
chmod命令可以修改文件和目录的安全设置。该命令的格式如下:
chmod options mode filemode参数允许使用八进制模式或符号模式来进行安全设置。八进制模式设置非常直观,直接用打算赋予文件的标准3位八进制权限编码即可:
$ chmod 760 newfile
$ ls -l newfile
-rwxrw---- 1 rich rich 0 Sep 20 19:16 newfile
$八进制文件权限会自动应用于指定文件。符号模式的权限就没这么简单了。与通常用到的3组权限字符不同,chmod命令采用的是另一种方法。下面是在符号模式下指定权限的格式:
[ugoa...][[+-=][rwxXstugo...]颇为合理,不是吗?第一组字符定义了权限作用的对象。·u代表用户·g代表组·o代表其他用户·a代表上述所有接下来的符号表示你是想在现有权限基础上增加权限(+)、移除权限(-),还是设置权限(=)。最后,第三个符号代表要设置的权限。你会发现,可取的值要比通常的rwx多。这些额外值如下。·X:仅当对象是目录或者已有执行权限时才赋予执行权限。·s:在执行时设置SUID或SGID。·t:设置粘滞位(sticky bit)。·u:设置属主权限。·g:设置属组权限。·o:设置其他用户权限。具体用法如下:
$ chmod o+r newfile
$ ls -l newfile
-rwxrw-r-- 1 rich rich 0 Sep 20 19:16 newfile
$不管其他用户先前在该安全级别具有什么样的权限,o+r都为其添加了读取权限。
$ chmod u-x newfile
$ ls -l newfile
-rw-rw-r-- 1 rich rich 0 Sep 20 19:16 newfile
$u-x移除了属主已有的执行权限。注意,如果某个文件具有执行权限,则ls命令的-F选项会在该文件的名称后面加上一个星号。options为chmod命令提供了额外的增强特性。-R选项能够以递归方式修改文件和目录的权限。你可以使用通配符指定多个文件名,然后用单个命令批量修改权限。
1.8.2 改变所属关系
有时你需要改变文件的属主,比如有人离职,或是开发人员创建了一个需要在产品环境中归属于系统账户的应用程序。Linux为此提供了两个命令:chown和chgrp,前者可以修改文件的属主,后者可以修改文件的默认属组。
chown命令的格式如下:
chown options owner[.group] file可以使用登录名或UID来指定文件的新属主:
# chown dan newfile
# ls -l newfile
-rw-rw-r-- 1 dan rich 0 Sep 20 19:16 newfile
#非常简单。chown命令也支持同时修改文件的属主和属组:
# chown dan.shared newfile
# ls -l newfile
-rw-rw-r-- 1 dan shared 0 Sep 20 19:16 newfile
#如果不嫌麻烦,可以只修改文件的默认属组:
# chown .rich newfile
# ls -l newfile
-rw-rw-r-- 1 dan rich 0 Sep 20 19:16 newfile
#最后,如果你的Linux系统使用与用户登录名相同的组名,则可以同时修改二者:
# chown test. newfile
# ls -l newfile
-rw-rw-r-- 1 test test 0 Sep 20 19:16 newfile
#chown命令使用了一些不同的options。-R选项与通配符相配合可以递归地修改子目录和文件的所属关系。-h选项可以修改文件的所有符号链接文件的所属关系。注意 只有root用户能修改文件的属主。任何用户都可以修改文件的属组,但前提是该用户必须是原属组和新属组的成员。chgrp命令可以方便地修改文件或目录的默认属组:
$ chgrp shared newfile
$ ls -l newfile
-rw-rw-r-- 1 rich shared 0 Sep 20 19:16 newfile
$1.9 共享文件
你可能已经猜到了,Linux系统中共享文件的方法是创建组。但对一个完整的文件共享环境而言,事情会复杂得多。如7.3节所述,创建新文件时,Linux会用默认的UID和GID来给文件分配权限。要想让其他用户也能访问文件,要么修改所有用户一级的安全权限,要么给文件分配一个包含其他用户的新默认属组。如果想在大范围内创建并共享文件,这会很烦琐。幸好有一种简单的解决方法。Linux为每个文件和目录存储了3个额外的信息位。·SUID(set user ID):当用户执行该文件时,程序会以文件属主的权限运行。·SGID(set group ID):对文件而言,程序会以文件属组的权限运行;对目录而言,该目录中创建的新文件会以目录的属组作为默认属组。·粘滞位(sticky bit):应用于目录时,只有文件属主可以删除或重命名该目录中的文件。SGID位对文件共享非常重要。启用SGID位后,可以强制在共享目录中创建的新文件都属于该目录的属组,这个组也就成了每个用户的属组。可以通过chmod命令设置SGID,将其添加到标准3位八进制值之前(组成4位八进制值),或者在符号模式下用符号s。
1.10 访问控制列表
nux的基本权限方法有一个缺点:局限性。你只能将文件或目录的权限分配给单个组或用户账户。在一个复杂的商业环境中,对于文件和目录,不同的组需要不同的权限,基本权限方法解决不了这个问题。
Linux开发者设计出了一种更先进的文件和目录安全方法:访问控制列表(access control list,ACL)。ACL允许指定包含多个用户或组的列表以及为其分配的权限。和基本安全方法一样,ACL权限使用相同的读取、写入和执行权限位,但现在可以分配给多个用户和组。
$ touch test
$ ls -l
total 0
-rw-r----- 1 rich rich 0 Apr 19 17:33 test
$ getfacl test
# file: test
# owner: rich
# group: rich
user::rw-
group::r--
other::---
$如果只为文件分配了基本的安全权限,则这些权限就会像上面例子所显示的那样,出现在getfacl的输出中。
setfacl命令可以为用户或组分配权限:
setfacl [options] rule filenamessetfacl命令允许使用-m选项修改分配给文件或目录的权限,或使用-x选项删除特定权限。可以使用下列3种格式定义规则:
u[ser]:uid:perms
g[roup]:gid:perms
o[ther]::perms要为用户分配权限,可以使用user格式;要为组分配权限,可以使用group格式;要为其他用户分配权限,可以使用other格式。对于uid或gid,可以使用数字值或名称。来看下面的例子:
$ setfacl -m g:sales:rw test
$ ls -l
total 0
-rw-rw----+ 1 rich rich 0 Apr 19 17:33 test
$这个例子为test文件添加了sales组的读写权限。注意,setfacl命令不产生输出。在列出文件时,只显示标准的属主、属组和其他用户权限,但在权限列的末尾多了一个加号(+),指明该文件还应用了ACL。可以再次使用getfacl命令查看ACL:
$ getfacl test
# file: test
# owner: rich
# group: rich
user::rw-
group::r--
group:sales:rw-
mask::rw-
other::---
$getfacl的输出显示为两个组分配了权限。默认组(rich)对文件有读权限,sales组对文件有读写权限。要想删除权限,可以使用-x选项:
$ setfacl -x g:sales test
$ getfacl test
# file: test
# owner: rich
# group: rich
user::rw-
group::r--
mask::r--
other::---
$Linux也允许对目录设置默认ACL,在该目录中创建的文件会自动继承。这个特性称为ACL继承。要想设置目录的默认ACL,可以在正常的规则定义前加上d:,如下所示:
$ sudo setfacl -m d:g:sales:rw /sales这个例子为/sales目录添加了sales组的读写权限。在该目录中创建的所有文件都会自动为sales组分配读写权限。
七、管理文件系统
使用Linux系统时,需要做出的一个决定是为存储设备选用哪种文件系统。大多数Linux发行版在安装时会非常贴心地提供一种默认文件系统,大部分Linux初学者想都不想就直接选用了。使用默认文件系统未必是坏事,但了解一下可用的选择有时也有好处。本章将讨论Linux世界中各种可用的文件系统,展示如何在命令行中创建和管理文件系统。
7.1探索Linux文件系统
7.1.1 Linux文件系统的演进
1.ext文件系统
Linux操作系统最初引入的文件系统叫作扩展文件系统(extended filesystem,简称ext),它为Linux提供了一个基本的类Unix文件系统,使用虚拟目录处理物理存储设备并在其中以固定大小的磁盘块(fixed-length block)形式保存数据。
2.ext2文件系统
最早的ext文件系统限制颇多,比如文件大小不得超过2 GB。在Linux出现后不久,ext文件系统就升级到了第二代扩展文件系统,称作ext2。在保持与ext相同的文件系统结构的同时,ext2在功能上做了扩展。·在i节点表中加入了文件的创建时间、修改时间以及最后一次访问时间。·允许的最大文件大小增至2 TB,后期又增加到32 TB。·保存文件时按组分配磁盘块。ext2文件系统也有限制。如果系统在存储文件和更新i节点表之间发生了什么事情,则两者内容可能无法同步,潜在的结果是丢失文件在磁盘上的数据位置。ext2文件系统由于容易在系统崩溃或断电时损坏而臭名昭著。没过多久,开发人员就开始研究新的Linux文件系统了。
3.日志文件系统
日志文件系统为Linux系统增加了一层安全性。它放弃了之前先将数据直接写入存储设备再更新i节点表的做法,而是先将文件变更写入临时文件(称作日志)。在数据被成功写到存储设备和i节点表之后,再删除对应的日志条目。如果系统在数据被写入存储设备之前崩溃或断电,则日志文件系统会读取日志文件,处理尚未提交的数据。
Linux中有3种广泛使用的日志方法,每种的保护等级都不相同,如表8-1所示。

1.ext3文件系统ext3文件系统是ext2的后续版本,支持最大2 TB的文件,能够管理32 TB大小的分区。在默认情况下,ext3采用有序模式的日志方法,不过也可以通过命令行选项改用其他模式。ext3文件系统无法恢复误删的文件,也没有提供数据压缩功能。
2.ext4文件系统作为ext3的后续版本,ext4文件系统最大支持16 TiB的文件,能够管理1 EiB大小的分区。在默认情况下,ext4采用有序模式的日志方法,不过也可以通过命令行选项改用其他模式。另外还支持加密、压缩以及单目录下不限数量的子目录。先前的ext2和ext3也可以作为ext4挂载,以提高性能表现。
3.JFS文件系统作为可能是目前依然在用的最旧的日志文件系统之一,JFS(journaled file system,日志化文件系统)[插图]是IBM在1990年为其Unix衍生版AIX(advanced interactive executive)开发的。然而,直到第2版时它才被移植到Linux环境中。
4.ReiserFS文件系统2001年,Hans Reiser为Linux设计并编写了首个日志文件系统ReiserFS,ext3和ext4的特性都可以在其中找到。Linux现在已经不再支持最新的Reiser4了
5.XFS文件系统XFS(X file system)是Silicon Graphics公司为其高级图形工作站(现在已退出市场)开发的文件系统,提供了一些先进的高性能特性,这使其仍流行于Linux中。XFS文件系统采用回写模式的日志方法,在提供了高性能的同时也引入了一定的风险,因为实际数据并未存进日志文件。
7.1.2 卷管理文件系统
采用了日志技术,就必须在安全性和性能之间做出选择。尽管数据模式日志提供了最高的安全性,但是会给性能带来影响,因为i节点和数据都需要被日志化。如果是回写模式日志,那么性能倒是可以接受,但安全性又无法保证。就文件系统而言,日志技术的替代选择是一种称作写时复制(copy-on-write,COW)的技术。COW通过快照(snapshot)兼顾了安全性和性能。在修改数据时,使用的是克隆或可写快照。修改过的数据并不会直接覆盖当前数据,而是被放入文件系统中另一个位置。注意 真正的COW系统仅在数据修改完成之后才会改动旧数据。如果从不覆盖旧数据,那么这种操作准确来说称作写时重定向(redirect-on-write,ROW)。不过,通常都将ROW简称为COW。
尽管磁盘存储容量多年来显著增加,但对更多空间的需求始终存在。从一个或多个磁盘(或磁盘分区)创建的存储池提供了生成虚拟磁盘(称作卷)的能力。通过存储池,可以根据需要增加卷,在提供灵活性的同时大大减少停机时间。提供了COW、快照和卷管理特性的文件系统日渐流行。接下来将介绍其中最流行的Btrfs和ZFS,以及“新人”Stratis。
1.ZFS文件系统
ZFS文件系统最初由Sun Microsystems于2005年发布,用于OpenSolaris操作系统。从2008年起开始向Linux移植,最终在2012年投入使用。ZFS是一个稳定的文件系统,与Resier4、Btrfs和ext4势均力敌。它拥有数据完整性验证和自动修复功能,支持最大16 EB的文件,能够管理256万亿ZB(256quadrillion zettabyte)的存储空间。这可着实不小!ZFS最大的弱项是没有采用GNU通用公共许可证(GNU General Public License,GPL),因此无法被纳入Linux内核。幸运的是,大多数Linux发行版提供了相应的安装方法。
2.Btrfs文件系统
Btrfs文件系统(通常发音为butter-fs)也称为B-tree文件系统,由Oracle公司于2007年开始研发。Btrfs在Reiser4的诸多特性基础上改进了可靠性。其他开发人员随后也逐步加入了开发过程,帮助Btrfs迅速蹿升为最流行的文件系统。究其原因,还要归根于它的稳定性、易用性以及能够动态调整已挂载文件系统的大小。虽然openSUSE Linux发行版将Btrfs确立为其默认文件系统,但在2017年,Red Hat废弃了Btrfs,不再支持该文件系统(RHEL版本8以及后续版本)。遗憾的是,对那些选择了RHEL的组织而言,这意味着无法再选用Btrfs。
3.Stratis文件系统
当Red Hat弃用Btrfs时,决定创建一种新的文件系统,即Stratis。但是Stratis并不符合文件系统的标准定义。相反,它提供了更多的管理视角。Stratis维护的存储池由一个或多个XFS文件系统组成,同时还提供与传统的卷管理文件系统(比如ZFS和Btrfs)相似的COW功能。在描述该文件系统的时候,经常会听到“易用性”和“高级存储特性”这两个词,但就目前而言,Stratis是否实至名归,下结论还为时过早。注意 XFS近年来一直在改进其COW功能。例如,它现在有一个always_cow模式,这使得XFS在修改时不会覆盖原始数据。Stratis首次现身于Fedora 29(2018年发布),在RHEL v8中被作为技术预览功能。这意味着Stratis还适用于生产环境。
7.1.3 创建分区
首先,需要在存储设备上创建可容纳文件系统的分区。分区范围可以是整个硬盘,也可以是部分硬盘以包含虚拟目录的一部分。
有时候,创建磁盘分区时最麻烦的地方就是找出Linux系统中的物理硬盘。Linux采用了一种标准格式来为硬盘分配设备名称,在进行分区之前,必须熟悉这种格式。
·SATA驱动器和SCSI驱动器:设备命名格式为/dev/sdx,其中字母x具体是什么要根据驱动器的检测顺序决定(第一个检测到的驱动器是a,第二个是b,以此类推)。
·SSD NVMe驱动器:设备命名格式为/dev/nvmeNn#,其中数字N具体是什么要根据驱动器的检测顺序决定(从0起始)。#是分配给该驱动器的名称空间编号(从1起始)。
·IDE驱动器:设备命名格式为/dev/hdx,其中字母x具体是什么要根据驱动器的检测顺序决定(第一个检测到的驱动器是a,第二个是b,以此类推)。
为分区创建好文件系统之后,下一步是将其挂载到虚拟目录中的某个挂载点,以便在新分区中存储数据。挂载点可以是虚拟目录中的任何位置。
$ mkdir /home/christine/part
$
$ sudo mount -t ext4 /dev/sdb1 /home/christine/part
[sudo] password for christine:
$
$ lsblk -f /dev/sdb
NAME FSTYPE LABEL UUID MOUNTPOINT
sdb
⌙sdb1 ext4 a8d1d[...] /home/christine/part
$mkdir命令(参见第3章)在虚拟目录中创建了挂载点,mount命令会将新分区的文件系统添加到挂载点。mount命令的-t选项指明了要挂载的文件系统类型(ext4)。lsblk -f命令可以显示新近格式化过并挂载的分区。警告 这种挂载文件系统的方法只能实现临时挂载,重启系统后就失效了。要强制Linux在启动时自动挂载文件系统,可以将其添加到/etc/fstab文件中。文件系统现在已经被挂载到虚拟目录中,可以投入日常使用了。可惜,在日常使用过程中难免会出现一些严重的问题,比如文件系统损坏。接下来将演示如何应对这种问题。
7.1.4 文件系统的检查与修复
就算是现代文件系统,碰上突然断电或者某个不规矩的程序在访问文件时锁死了系统,也会出现错误。好在有一些命令行工具可以试着将文件系统恢复正常。
每种文件系统各自都有相应的恢复命令。这可能会让场面变得混乱,随着Linux环境中可用的文件系统越来越多,你不得不掌握大量的命令。幸运的是,通用的前端程序可以判断存储设备使用的文件系统并根据要恢复的文件系统调用适合的恢复命令。
fsck命令可以检查和修复大部分Linux文件系统类型,包括本章早些时候讨论的那些文件系统。该命令的格式如下:
fsck options filesystem你可以在命令行中列出多个要检查的文件系统。文件系统可以通过多种方法指定,比如设备名或其在虚拟目录中的挂载点。但在对其使用fsck之前,必须先卸载设备。提示 尽管日志文件系统的用户确实也要用到fsck命令,但对于使用COW的文件系统是否真的需要,还存在争议。实际上,ZFS文件系统甚至都没有提供fsck工具的接口。fsck.xfs命令和fsck.btrfs命令仅仅就是个桩(stub)[插图]而已,什么都不干。对于COW文件系统,如果需要高级修复选项,请查看其相应文件系统修复工具的手册页。
fsck命令会使用/etc/fstab文件自动决定系统中已挂载的存储设备的文件系统。如果存储设备尚未挂载(比如刚刚在新的存储设备上创建了文件系统),则需要用-t命令行选项指定文件系统类型。表8-5列出了其他可用的命令行选项。
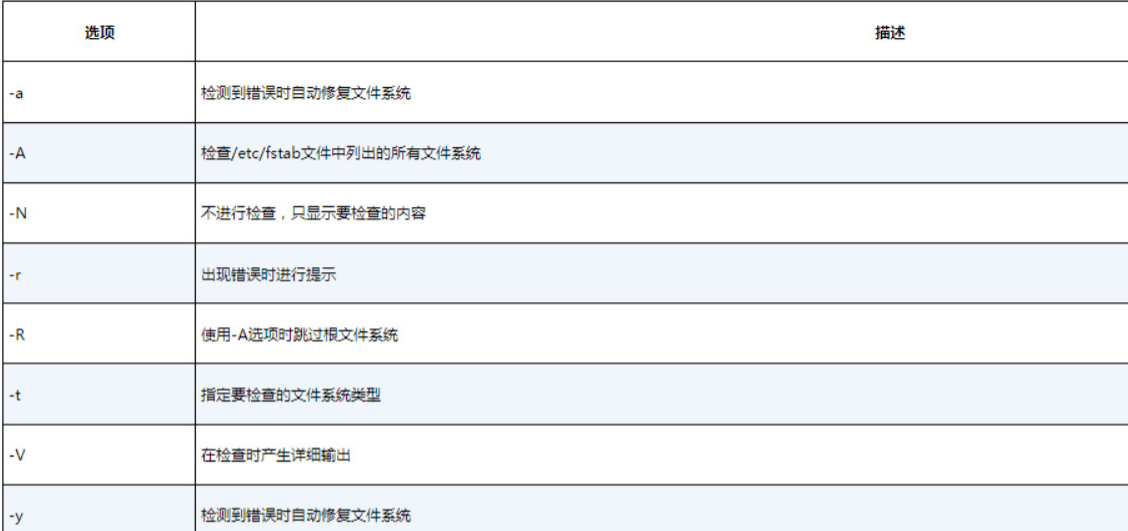
你可能注意到了,有些命令行选项是重复的。这是为多个命令实现通用前端带来的部分问题。有些文件系统修复命令有额外的可用选项。
提示 你只能对未挂载的文件系统执行fsck命令。对大多数文件系统来说,只需先卸载文件系统,检查完成之后再重新挂载即可。但因为根文件系统含有Linux所有的核心命令和日志文件,所以无法在处于运行状态的系统中卸载它。这正是Linux Live CD、DVD或USB大展身手的时机。只需用Linux Live媒介启动系统即可,然后对根文件系统执行fsck命令。到目前为止,本章讲解了如何处理物理存储设备中的文件系统。Linux还提供了另一些可以为文件系统创建逻辑存储设备的方法。下一节将介绍如何使用逻辑存储设备。
八、安装软件
8.1 基于Debian的系统(了解)
dpkg命令是基于Debian的软件包管理器的核心,用于在Linux系统中安装、更新、删除DEB包文件。
dpkg命令假定你已经将DEB包文件下载到本地Linux系统或是以URL的形式提供。但很多时候并非如此。通常情况下,你更愿意从所用的Linux发行版仓库中安装软件包。为此,需要使用APT(advanced package tool)工具集。
apt命令本质上是apt-cache命令和apt-get命令的前端。APT的好处是不需要记住什么时候该使用哪个工具——它涵盖了软件包管理所需的方方面面。apt命令的基本格式如下:
apt [options] commandcommand定义了apt要执行的操作。如果需要,可以指定一个或多个options进行微调。本节将介绍如何在Linux系统中使用APT命令行工具处理软件包。
8.2 基于Red Hat的系统(重点)
和基于Debian的发行版类似,基于Red Hat的系统有以下几种前端工具。·yum:用于Red Hat、CentOS和Fedora。·zypper:用于openSUSE。·dnf:yum的升级版,有一些新增的特性。
上述前端全部基于命令行工具rpm。接下来将讨论如何用这些基于rpm的工具来管理软件包。我们会重点介绍dnf,但也会讲到yum和zypper。
9. 文本编辑器
9.1vim文本编辑器
最初的vim编辑窗口显示了文件的内容(如果有的话),在窗口底部还有一行消息。如果文件内容并未占据整个屏幕,则vim会在非文件内容行放置一个波浪号(~)(参见图10-1)。根据文件的状态,底部的消息行显示了所编辑文件的信息以及vim安装时的默认设置。如果文件是新建的,那么会出现消息[New File]。vim编辑器有3种操作模式。·命令模式·Ex模式·插入模式刚打开要编辑的文件(或新建文件)时,vim编辑器会进入命令模式(有时也称为普通模式)。在命令模式中,vim编辑器会将按键解释成命令(本章随后会详述)。在插入模式中,vim会将你在当前光标位置输入的字符、数字或者符号都放入缓冲区。按下i键就可以进入插入模式。要退出插入模式并返回命令模式,按下Esc键即可。在命令模式中,可以用方向键在文本区域中移动光标(只要vim能正确识别你的终端类型)。如果恰巧碰到了一个罕见的没有定义方向键的终端连接,也不是没有办法。vim编辑器也有可用于移动光标的命令。·h:左移一个字符。·j:下移一行(下一行文本)。·k:上移一行(上一行文本)。·l:右移一个字符。
在大文本文件中逐行地来回移动特别麻烦。幸而vim提供了一些能够提高移动速度的命令。·PageDown(或Ctrl+F):下翻一屏。·PageUp(或Ctrl+B):上翻一屏。·G:移到缓冲区中的最后一行。·num G:移到缓冲区中的第num行。·gg:移到缓冲区中的第一行。vim编辑器的命令模式有个称作Ex模式的特别功能。Ex模式提供了一个交互式命令行,可以输入额外的命令来控制vim的操作。要进入Ex模式,在命令模式中按下冒号键(:)即可。光标会移动到屏幕底部的消息行处,然后出现冒号,等待输入命令。Ex模式中的以下命令可以将缓冲区的数据保存到文件中并退出vim。·q:如果未修改缓冲区数据,则退出。·q!:放弃对缓冲区数据的所有修改并退出。·w filename:将文件另存为其他名称。·wq:将缓冲区数据保存到文件中并退出。看过这些vim基础命令之后,估计你就理解为什么有人会厌恶vim编辑器了。要想发挥vim的全部威力,必须记住大量晦涩的命令。不过,只要掌握了一些基础命令,无论是什么环境,你都能快速在命令行下直接修改文件。尽管学习曲线很陡峭,但由于其强大的功能,vim编辑器仍然长盛不衰
九、构建基础脚本
9.1 使用多个命令
到目前为止,你已经了解了如何使用shell的命令行界面提示符来输入命令并查看命令结果。shell脚本的关键是能够输入多个命令并处理每个命令的结果,甚至是将一个命令的结果传给另一个命令。shell可以让你将多个命令串联起来,一次性执行完。如果想让两个命令一起运行,可以将其放在同一行中,彼此用分号隔开:
$ date ; who
Mon Jun 01 15:36:09 EST 2020
Christine tty2 2020-06-01 15:26
Samantha tty3 2020-06-01 15:26
Timothy tty1 2020-06-01 15:26
user tty7 2020-06-01 14:03 (:0)
user pts/0 2020-06-01 15:21 (:0.0)
$9.2 创建shell脚本文件
要将shell命令放到文本文件中,首先要用文本编辑器(参见第10章)创建一个文件,然后在其中输入命令。在创建shell脚本文件时,必须在文件的第一行指定要使用的shell,格式如下:
#!/bin/bash在普通的shell脚本中,#用作注释行。shell并不会处理shell脚本中的注释行。然而,shell脚本文件的第一行是个例外,#后面的惊叹号会告诉shell用哪个shell来运行脚本。(是的,可以使用bash shell,然后使用另一个shell来运行你的脚本。)
在指明了shell之后,可以在文件的各行输入命令,每行末尾加一个换行符。之前提到过,注释可用#添加,如下所示:
#!/bin/bash
# This script displays the date and who's logged on
date
who这就是脚本的所有内容了。你可以根据需要,使用分号将两个命令放在一行中,但在shell脚本中,可以将命令放在独立的行中。shell会根据命令在文件中出现的顺序进行处理。注意,还有另外一行也以#开头,并添加了注释。shell不会解释以#开头的行(除了以#!开头的第一行)。留下注释来说明对脚本做了什么,这种方法非常好,当你两年后再看这个脚本时,很容易想起来都做了什么。将这个脚本保存在名为test1的文件中,基本上就搞定了。在运行新脚本前,还有几件事要做。
如果尝试运行脚本,则结果可能会让你有点儿失望:
$ test1
bash: test1: command not found
$你要解决的第一个障碍是让bash shell找到你的脚本文件。如第6章所述,shell会通过PATH环境变量来查找命令。快速查看一下PATH便可弄清问题所在。
$ echo $PATH
/usr/kerberos/sbin:/usr/kerberos/bin:/usr/local/bin:/usr/bin
:/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/user/bin $PATH环境变量被设置为用于在其中查找命令的一系列目录。要让shell找到test1脚本,可以采用下列两种方法之一:·将放置shell脚本文件的目录添加到PATH环境变量中;·在命令行中使用绝对路径或相对路径来引用shell脚本文件。
提示 有些Linux发行版会将$HOME/bin目录加入PATH环境变量中。这样就在每个用户的$HOME目录中提供了一个存放文件的地方,shell可以在那里查找要执行的命令。
在这个例子中,我们使用第二种方法来告诉shell要运行的脚本文件所处的确切位置。可以使用单点号来引用当前目录下的文件:
$ ./test1
bash: ./test1: Permission denied
$现在shell已经可以找到脚本文件了,但还有一个问题:你还没有执行该文件的权限。查看一下文件权限就知道怎么回事了:
$ ls -l test1
-rw-r--r-- 1 user user 73 Jun 02 15:36 test1
$在创建test1文件时,umask的值决定了新文件的默认权限设置。由于umask变量被设为022(参见第7章),因此新建的文件只有文件属主和属组才有读/写权限。下一步是通过chmod命令(参见第7章)赋予文件属主执行文件的权限:
$ chmod u+x test1
$ ./test1
Mon Jun 01 15:38:19 EST 2020
Christine tty2 2020-06-01 15:26
Samantha tty3 2020-06-01 15:26
Timothy tty1 2020-06-01 15:26
user tty7 2020-06-01 14:03 (:0)
user pts/0 2020-06-01 15:21 (:0.0) $9.3 显示消息
大多数shell命令会产生自己的输出,这些输出会显示在脚本所运行的控制台显示器上。很多时候,你可能想添加自己的文本消息来告诉用户脚本正在做什么。可以通过echo命令来实现这一点。如果在echo命令后面加上字符串,那么echo命令就会显示出这个字符串:
$ echo This is a test
This is a test
$注意,在默认情况下,无须使用引号将要显示的字符串划定出来。然而,如果在字符串中使用引号,则有时会比较麻烦:
$ echo Let's see if this'll work
Lets see if thisll work
$echo命令可用单引号或双引号来划定字符串。如果你在字符串中要用到某种引号,可以使用另一种引号来划定字符串:
$ echo "This is a test to see if you're paying attention"
This is a test to see if you're paying attention
$ echo 'Rich says "scripting is easy".'
Rich says "scripting is easy".
$可以将echo命令添加到shell脚本中任何需要显示额外信息的地方:
$ cat test1
#!/bin/bash
# This script displays the date and who's logged on
echo The time and date are:
date
echo "Let's see who's logged into the system: "
who
$运行这个脚本时,会产生如下输出:
$ ./test1
The time and date are:
Mon Jun 01 15:41:13 EST 2020
Let's see who's logged into the system:
Christine tty2 2020-06-01 15:26
Samantha tty3 2020-06-01 15:26
Timothy tty1 2020-06-01 15:26
user tty7 2020-06-01 14:03 (:0)
user pts/0 2020-06-01 15:21 (:0.0)
$很好,但如果想把字符串和命令输出显示在同一行中,应该怎么办呢?可以使用echo命令的-n选项。只要将第一个echo改成下面这样就可以了:
echo -n "The time and date are: "9.4 使用变量
运行shell脚本中的单个命令自然有用,但也有局限。你经常需要在shell命令中使用其他数据来处理信息。这可以通过变量来实现。变量允许在shell脚本中临时存储信息,以便同脚本中的其他命令一起使用。本节将介绍如何在shell脚本中使用变量。
9.4.1 环境变量
shell维护着一组用于记录特定的系统信息的环境变量,比如系统名称、已登录系统的用户名、用户的系统ID(也称为UID)、用户的默认主目录以及shell查找程序的搜索路径。你可以用set命令显示一份完整的当前环境变量列表:
$ set
BASH=/bin/bash
...
HOME=/home/Samantha
HOSTNAME=localhost.localdomain
HOSTTYPE=i386
IFS=$' \t\n'
IMSETTINGS_INTEGRATE_DESKTOP=yes
IMSETTINGS_MODULE=none
LANG=en_US.utf8
LESSOPEN='|/usr/bin/lesspipe.sh %s'
LINES=24
LOGNAME=Samantha
...在脚本中,可以在环境变量名之前加上$来引用这些环境变量,用法如下:
$ cat test2
#!/bin/bash
# display user information from the system.
echo "User info for userid: $USER"
echo UID: $UID
echo HOME: $HOME
$环境变量$USER、$UID和$HOME用来显示已登录用户的相关信息。脚本输出如下:
$ chmod u+x test2
$ ./test2
User info for userid: Samantha
UID: 1001
HOME: /home/Samantha
$ $注意,echo命令中的环境变量会在脚本运行时被替换成当前值。另外,在第一个字符串中可以将$USER系统变量放入双引号中,而shell依然能够知道我们的意图。但这种方法存在一个问题。看看下面这个例子:
$ echo "The cost of the item is $15"
The cost of the item is 5显然这不是我们想要的。只要脚本在双引号中看到$,就会以为你在引用变量。在这个例子中,脚本会尝试显示变量$1的值(尚未定义),再显示数字5。要显示$,必须在它前面放置一个反斜线:
$ echo "The cost of the item is \$15"
The cost of the item is $159.4.2 用户自定义变量
除了环境变量,shell脚本还允许用户在脚本中定义和使用自己的变量。定义变量允许在脚本中临时存储并使用数据,从而使shell脚本看起来更像一个真正的计算机程序。
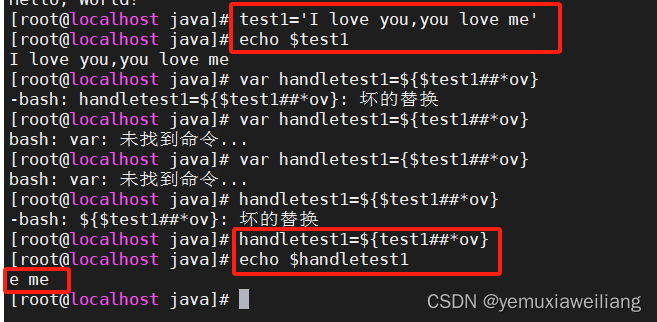
用户自定义变量的名称可以是任何由字母、数字或下划线组成的字符串,长度不能超过20个字符。因为变量名区分大小写,所以变量Var1和变量var1是不同的。这个小规矩经常让脚本编程初学者感到头疼。
使用等号为变量赋值。在变量、等号和值之间不能出现空格(另一个初学者经常犯错的地方)。下面是一些为用户自定义变量赋值的例子:
var1=10
var2=-57
var3=testing
var4="still more testing"shell脚本会以字符串形式存储所有的变量值,脚本中的各个命令可以自行决定变量值的数据类型。shell脚本中定义的变量在脚本的整个生命周期里会一直保持着它们的值,在脚本结束时会被删除。
与系统变量类似,用户自定义变量可以通过$引用:
$ cat test3
#!/bin/bash
# testing variables
days=10
guest="Katie"
echo "$guest checked in $days days ago"
days=5
guest="Jessica"
echo "$guest checked in $days days ago"
$运行脚本会有下列输出:
$ chmod u+x test3
$ ./test3
Katie checked in 10 days ago
Jessica checked in 5 days ago
$9.4.3命令替换
shell脚本中最有用的特性之一是可以从命令输出中提取信息并将其赋给变量。把输出赋给变量之后,就可以随意在脚本中使用了。在脚本中处理数据时,这个特性显得尤为方便。
有两种方法可以将命令输出赋给变量。
·反引号(`)
·$()格式
要注意反引号,这可不是用于字符串的那个普通的单引号。由于在shell脚本之外很少用到,你可能甚至都不知道在键盘的哪个位置能找到这个字符。但是你需要慢慢熟悉它,因为这是许多shell脚本中的重要组件。提示:在美式键盘上,反引号通常和波浪号(~)位于同一键位。
命令替换允许将shell命令的输出赋给变量。尽管这看起来好像也没什么,但它是脚本编程的一个主要组成部分。
你要么将整个命令放入反引号内:
testing=`date`要么使用$()格式:
testing=$(date)shell会执行命令替换符内的命令,将其输出赋给变量testing。注意,赋值号和命令替换符之间没有空格。下面是一个使用shell命令输出创建变量的例子:
$ cat test5
#!/bin/bash
testing=$(date)
echo "The date and time are: " $testing
$变量testing保存着date命令的输出,然后会使用echo命令显示出该变量的值。运行这个shell脚本会生成下列输出:
$ chmod u+x test5
$ ./test5
The date and time are: Mon Jun 01 15:45:25 EDT 2020
$这个例子看起来平平无奇(也可以干脆把命令替换放在echo语句中),但只要将命令输出存入变量,你就可以随心所欲了。
下面这个例子很常见,它在脚本中通过命令替换获得当前日期并用其来生成唯一文件名:
#!/bin/bash
# copy the /usr/bin directory listing to a log file
today=$(date +%y%m%d)
ls /usr/bin -al > log.$todaytoday变量保存着格式化后的date命令的输出。这是提取日期信息,用于生成日志文件名的一种常用技术。+%y%m%d格式会告诉date命令将日期显示为两位数的年、月、日的组合:
$ date +%y%m%d
200601
$该脚本会将日期值赋给变量,然后再将其作为文件名的一部分。文件本身包含重定向的目录列表输出(11.5节会详细讨论)。运行该脚本之后,应该能在目录中看到一个新文件:
-rw-r--r-- 1 user user 769 Jun 01 16:15 log.200601目录中出现的日志文件采用$today变量的值作为文件名的一部分。日志文件的内容是/usr/bin目录内容的列表输出。如果脚本在次日运行,那么日志文件名会是log.200602,因此每天都会创建一个新文件。警告 命令替换会创建出子shell来运行指定命令,这是由运行脚本的shell所生成的一个独立的shell。因此,在子shell中运行的命令无法使用脚本中的变量。如果在命令行中使用./路径执行命令,就会创建子shell,但如果不加路径,则不会创建子shell。不过,内建的shell命令也不会创建子shell。在命令行中运行脚本时要当心。
9.5 重定向输入和输出
有时候,你想要保存命令的输出而不只是在屏幕上显示。bash shell提供了几个运算符,它们可以将命令的输出重定向到其他位置(比如文件)。重定向既可用于输入,也可用于输出,例如将文件重定向,作为命令输入。本节将介绍如何在shell脚本中使用重定向。
9.5.1 输出重定向
最基本的重定向会将命令的输出发送至文件。bash shell使用大于号(>)来实现该操作:
command > outputfile有时,你可能并不想覆盖文件原有内容,而是想将命令输出追加到已有文件中,例如,你正在创建一个记录系统操作的日志文件。在这种情况下,可以用双大于号(>>)来追加数据:
$ date >> test6
$ cat test6
rich pts/0 Jun 01 16:55
Mon Jun 01 17:02:14 EDT 2020
$9.5.2 输入重定向
输入重定向和输出重定向正好相反。输入重定向会将文件的内容重定向至命令,而不是将命令输出重定向至文件。
输入重定向运算符是小于号(<):
command < inputfile一种简单的记忆方法是,在命令行中,命令总是在左侧,而重定向运算符“指向”数据流动的方向。小于号说明数据正在从输入文件流向命令。
下面是一个和wc命令一起使用输入重定向的例子
$ wc < test6
2 11 60
$wc命令可以统计数据中的文本。在默认情况下,它会输出3个值。·文本的行数·文本的单词数·文本的字节数通过将文本文件重定向到wc命令,立刻就可以得到文件中的行、单词和字节的数量。这个例子说明test6文件包含2行、11个单词以及60字节。
wc命令可以统计数据中的文本。在默认情况下,它会输出3个值。·文本的行数·文本的单词数·文本的字节数通过将文本文件重定向到wc命令,立刻就可以得到文件中的行、单词和字节的数量。这个例子说明test6文件包含2行、11个单词以及60字节。
内联输入重定向运算符是双小于号(<<)。除了这个符号,必须指定一个文本标记来划分输入数据的起止。任何字符串都可以作为文本标记,但在数据开始和结尾的文本标记必须一致:
command << marker
data
marker在命令行中使用内联输入重定向时,shell会用PS2环境变量中定义的次提示符(参见第6章)来提示输入数据,其用法如下所示:
$ wc << EOF
> test string 1
> test string 2
> test string 3
> EOF
3 9 42
$次提示符会持续显示,以获取更多的输入数据,直到输入了作为文本标记的那个字符串。wc命令会统计内联输入重定向提供的数据包含的行数、单词数和字节数。
9.6管道
有时候,你需要将一个命令的输出作为另一个命令的输入。这可以通过重定向来实现,只是略显笨拙:
$ rpm -qa > rpm.list
$ sort < rpm.list
abattis-cantarell-fonts-0.0.25-1.el7.noarch
abrt-2.1.11-52.el7.centos.x86_64
abrt-addon-ccpp-2.1.11-52.el7.centos.x86_64
abrt-addon-kerneloops-2.1.11-52.el7.centos.x86_64
abrt-addon-pstoreoops-2.1.11-52.el7.centos.x86_64
abrt-addon-python-2.1.11-52.el7.centos.x86_64
abrt-addon-vmcore-2.1.11-52.el7.centos.x86_64
abrt-addon-xorg-2.1.11-52.el7.centos.x86_64
abrt-cli-2.1.11-52.el7.centos.x86_64
abrt-console-notification-2.1.11-52.el7.centos.x86_64
...rpm命令通过Red Hat软件包管理系统(RPM)管理系统(比如上例中的CentOS系统)中已安装的软件包。配合-qa选项使用时,会生成已安装包的列表,但这个列表并不遵循某种特定的顺序。如果想查找某个或某些特定的软件包,在rpm命令的输出中就不太好找到了。
通过标准输出重定向,rpm命令的输出被重定向至文件rpm.list。命令完成后,rpm.list保存着系统中所有已安装的软件包列表。接下来,输入重定向将rpm.list文件的内容传给sort命令,由后者按字母顺序对软件包名称进行排序。
这种方法的确管用,但仍然是一种比较烦琐的信息生成方式。无须将命令输出重定向至文件,可以将其直接传给另一个命令。这个过程称为管道连接(piping)。
和命令替换所用的反引号(`)一样,管道操作符在shell编程之外也很少用到。该符号由两个竖线构成,一个在上,一个在下。然而,其印刷体往往看起来更像是单个竖线(|)。在美式键盘上,它通常和反斜线(\)位于同一个键。管道被置于命令之间,将一个命令的输出传入另一个命令中:
command1 | command2可别以为由管道串联起的两个命令会依次执行。实际上,Linux系统会同时运行这两个命令,在系统内部将二者连接起来。当第一个命令产生输出时,它会被立即传给第二个命令。数据传输不会用到任何中间文件或缓冲区。
现在,你可以利用管道轻松地将rpm命令的输出传入sort命令来获取结果:
$ rpm -qa | sort
abattis-cantarell-fonts-0.0.25-1.el7.noarch
abrt-2.1.11-52.el7.centos.x86_64
abrt-addon-ccpp-2.1.11-52.el7.centos.x86_64
abrt-addon-kerneloops-2.1.11-52.el7.centos.x86_64
abrt-addon-pstoreoops-2.1.11-52.el7.centos.x86_64
abrt-addon-python-2.1.11-52.el7.centos.x86_64
abrt-addon-vmcore-2.1.11-52.el7.centos.x86_64
abrt-addon-xorg-2.1.11-52.el7.centos.x86_64
abrt-cli-2.1.11-52.el7.centos.x86_64
abrt-console-notification-2.1.11-52.el7.centos.x86_64
...管道可以串联的命令数量没有限制。可以持续地将命令输出通过管道传给其他命令来细化操作。
在这个例子中,由于sort命令的输出一闪而过,因此可以用文本分页命令(比如less或more)强行将输出按屏显示:
$ rpm -qa | sort | more9.7 执行数学运算
9.7.1 expr命令
最初,Bourne shell提供了一个专门用于处理数学表达式的命令:expr,该命令可在命令行中执行数学运算,但是特别笨拙。
$ expr 1 + 5
6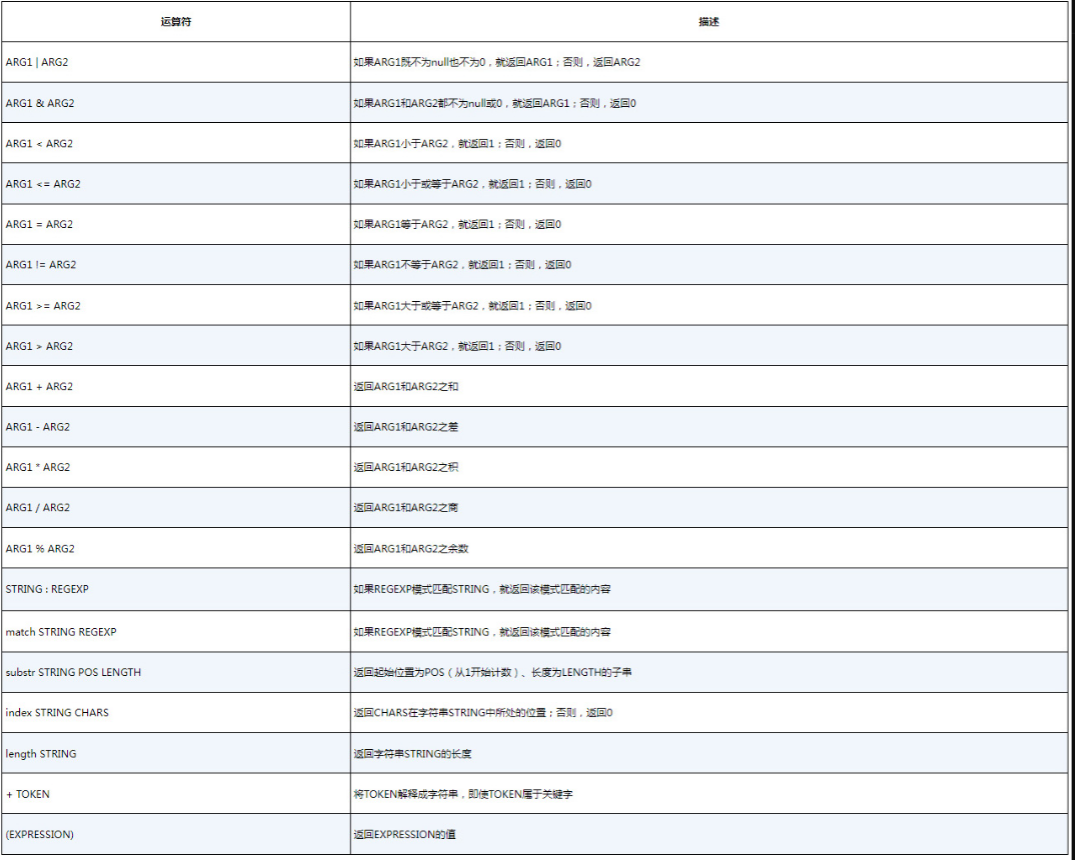
9.7.2 使用方括号
为了兼容Bourne shell,bash shell保留了expr命令,但同时也提供了另一种更简单的方法来执行数学运算。在bash中,要将数学运算结果赋给变量,可以使用$和方括号($[ operation ]):
$ var1=$[1 + 5]
$ echo $var1
6
$ var2=$[$var1 * 2]
$ echo $var2
12
$用方括号来执行数学运算要比expr命令方便得多。这种技术也适用于shell脚本:
$ cat test7
#!/bin/bash
var1=100
var2=50
var3=45
var4=$[$var1 * ($var2 - $var3)]
echo The final result is $var4
$十、结构化命令
10.1 使用if-then语句
最基本的结构化命令是if-then语句。if-then语句的格式如下:
if command
then
commands
fi如果之前用过其他编程语言的if-then语句,那么这种形式可能会让你有点儿困惑。在其他编程语言中,if语句之后的对象是一个等式,其求值结果为TRUE或FALSE。但bash shell的if语句并非如此。
bash shell的if语句会运行if之后的命令。如果该命令的退出状态码(参见第11章)为0(命令成功运行),那么位于then部分的命令就会被执行。如果该命令的退出状态码是其他值,则then部分的命令不会被执行,bash shell会接着处理脚本中的下一条命令。fi语句用来表示if-then语句到此结束。
下面用一个简单的例子来解释一下这个概念:
$ cat test1.sh
#!/bin/bash
# testing the if statement
if pwd
then
echo "it worked"
fi
$该脚本在if行中使用了pwd命令。如果命令成功结束,那么echo语句就会显示字符串。当你在命令行中运行该脚本时,会得到如下结果:
$ ./test1.sh
/home/christine/scripts
It worked
$shell执行了if行中的pwd命令。由于退出状态码是0,因此它也执行了then部分的echo语句。
注意 在有些脚本中,你可能看到过if-then语句的另一种形式:
if command; then
commands
fi通过把分号(;)放在待求值的命令尾部,可以将then语句写在同一行,这样看起来更像其他编程语言中的if-then语句。
能出现在then部分的命令可不止一条。你可以像脚本中其他地方一样在这里列出多条命令。bash shell会将这些命令视为一个代码块,如果if语句行命令的退出状态值为0,那么代码块中所有的命令都会被执行;否则,会跳过整个代码块:
$ cat test3.sh
#!/bin/bash
# testing multiple commands in the then block
#
testuser=christine
#
if grep $testuser /etc/passwd
then
echo "This is my first command in the then block."
echo "This is my second command in the then block."
echo "I can even put in other commands besides echo:"
ls /home/$testuser/*.sh
fi
echo "We are outside the if statement"
$10.2 if-then-else语句
在if-then语句中,不管命令是否成功执行,你都只有一种选择。如果命令返回一个非0退出状态码,则bash shell会继续执行脚本中的下一条命令。在这种情况下,如果能够执行另一组命令就好了。这正是if-then-else语句的作用。
if-then-else语句在语句中提供了另外一组命令:
if command
then
commands
else
commands
fi当if语句中的命令返回退出状态码0时,then部分中的命令会被执行,这跟普通的if-then语句一样。当if语句中的命令返回非0退出状态码时,bash shell会执行else部分中的命令。现在你可以复制并修改测试脚本,加入else部分:
$ cp test3.sh test4.sh
$
$ nano test4.sh
$
$ cat test4.sh
#!/bin/bash
# testing the else section
#
testuser=NoSuchUser
#
if grep $testuser /etc/passwd
then
echo "The script files in the home directory of $testuser are:"
ls /home/$testuser/*.sh
echo
else
echo "The user $testuser does not exist on this system."
echo
fi
echo "We are outside the if statement"
$
$ ./test4.sh
The user NoSuchUser does not exist on this system.
We are outside the if statement
$10.3嵌套if语句
$ cat test5.sh
#!/bin/bash
# testing nested ifs - using elif and else
#
testuser=NoSuchUser
#
if grep $testuser /etc/passwd
then
echo "The user $testuser account exists on this system."
echo
elif ls -d /home/$testuser/
then
echo "The user $testuser has a directory,"
echo "even though $testuser doesn't have an account."
else
echo "The user $testuser does not exist on this system,"
echo "and no directory exists for the $testuser."
fi
echo "We are outside the nested if statements."
$
$ ./test5.sh
/home/NoSuchUser/
The user NoSuchUser has a directory,
even though NoSuchUser doesn't have an account.
We are outside the nested if statements.
$
$ sudo rmdir /home/NoSuchUser/
[sudo] password for christine:
$
$ ./test5.sh
ls: cannot access '/home/NoSuchUser/': No such file or directory
The user NoSuchUser does not exist on this system,
and no directory exists for the NoSuchUser.
We are outside the nested if statements.
$10.4 test命令
格式
test condition$ cat test6.sh
#!/bin/bash
# testing the test command
#
if test
then
echo "No expression returns a True"
else
echo "No expression returns a False"
fi
$
$ ./test6.sh
No expression returns a False
$$ cat test6.sh
#!/bin/bash
# testing if a variable has content
#
my_variable="Full"
#
if test $my_variable
then
echo "The my_variable variable has content and returns a True."
echo "The my_variable variable content is: $my_variable"
else
echo "The my_variable variable doesn't have content,"
echo "and returns a False."
fi
$
$ ./test6.sh
The my_variable variable has content and returns a True.
The my_variable variable content is: Full
$由于变量my_variable中包含内容(Full),因此当test命令测试条件时,返回的退出状态码为0。这使得then语句块中的语句得以执行。如你所料,如果该变量中没有包含内容,就会出现相反的情况:
bash shell提供了另一种条件测试方式,无须在if-then语句中写明test命令:
if [ condition ]
then
commands
fitest可以用来做比较
1.字符串相等性
字符串的相等和不等条件不言自明,很容易看出两个字符串值是否相同:
$ cat string_test.sh
#!/bin/bash
# Using string test evaluations
#
testuser=christine
#
if [ $testuser = christine ]
then
echo "The testuser variable contains: christine"
else
echo "The testuser variable contains: $testuser"
fi
$
$ ./string_test.sh
The testuser variable contains: christine
$2.字符串顺序
要测试一个字符串是否大于或小于另一个字符串就开始变得棘手了。使用测试条件的大于或小于功能时,会出现两个经常困扰shell程序员的问题。·大于号和小于号必须转义,否则shell会将其视为重定向符,将字符串值当作文件名。·大于和小于顺序与sort命令所采用的不同。在编写脚本时,第一个问题可能会导致不易察觉的严重后果。下面的例子展示了shell脚本编程初学者不时会碰到的状况:
$ cat bad_string_comparison.sh
#!/bin/bash
# Misusing string comparisons
#
string1=soccer
string2=zorbfootball
#
if [ $string1 > $string2 ]
then
echo "$string1 is greater than $string2"
else
echo "$string1 is less than $string2"
fi
$
$ ./bad_string_comparison.sh
soccer is greater than zorbfootball
$
$ ls z*
zorbfootball
$这个脚本中只用了大于号,虽然没有出现错误,但结果不对。脚本把大于号解释成了输出重定向(参见第15章),因此创建了一个名为zorbfootball的文件。由于重定向顺利完成了,测试条件返回了退出状态码0,if语句便认为条件成立。要解决这个问题,需要使用反斜线(\)正确地转义大于号:
$ cat good_string_comparison.sh
#!/bin/bash
# Properly using string comparisons
#
string1=soccer
string2=zorbfootball
#
if [ $string1 \> $string2 ]
then
echo "$string1 is greater than $string2"
else
echo "$string1 is less than $string2"
fi
$
$ rm -i zorbfootball
rm: remove regular empty file 'zorbfootball'? y
$
$ ./good_string_comparison.sh
soccer is less than zorbfootball
$
$ ls z*
ls: cannot access 'z*': No such file or directory
$3.字符串大小
-n和-z可以很方便地用于检查一个变量是否为空:
$ cat variable_content_eval.sh
#!/bin/bash
# Testing string length
#
string1=Soccer
string2=''
#
if [ -n $string1 ]
then
echo "The string '$string1' is NOT empty"
else
echo "The string '$string1' IS empty"
fi
#
if [ -z $string2 ]
then
echo "The string '$string2' IS empty"
else
echo "The string '$string2' is NOT empty"
fi
#
if [ -z $string3 ]
then
echo "The string '$string3' IS empty"
else
echo "The string '$string3' is NOT empty"
fi
$
$ ./variable_content_eval.sh
The string 'Soccer' is NOT empty
The string '' IS empty
The string '' IS empty
$