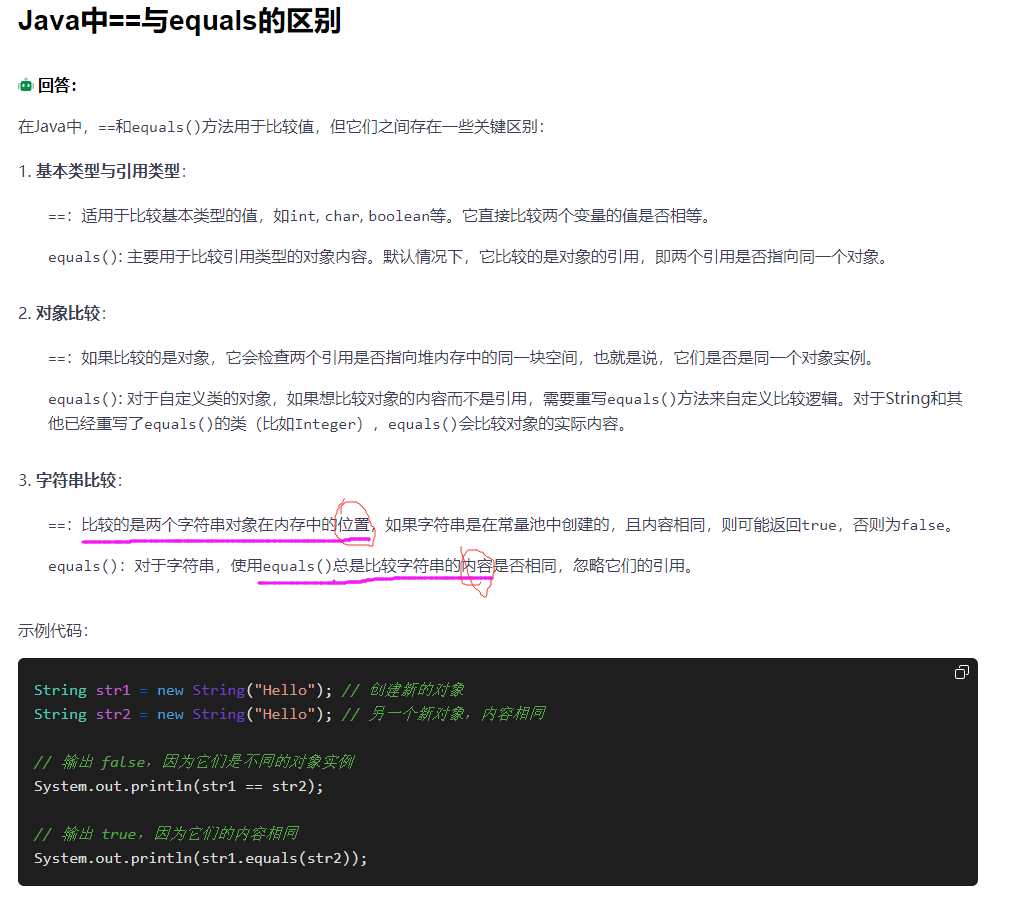
labelencoder
LabelEncoder将不连续的数字or文本进行编号
import numpy as np
import pandas as pd
data = pd.DataFrame({
"学号":[1001,1002,1003,1004],
"性别":["男","女","女","男"],
"学历":["本科","硕士","专科","本科"]})
data
学号 性别 学历
0 1001 男 本科
1 1002 女 硕士
2 1003 女 专科
3 1004 男 本科
## 选择object类型的变量
lis = list(data.select_dtypes(include='object').columns)
lis
['性别', '学历']
- 使用
LabelEncoder进行编码,每个变量单独进行多变量的编码
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
for m in lis:
data[m] = le.fit_transform(data[m])
data
学号 性别 学历
0 1001 1 1
1 1002 0 2
2 1003 0 0
3 1004 1 1
OneHotEncoder
OneHotEncoder对表示分类的数字进行编码
输入的应该是表示类别的数字,如果输入文本,会报错的。
from sklearn.preprocessing import OneHotEncoder
OHE = OneHotEncoder()
OHE.fit(data)
data3 = le.fit_transform(data["性别"])
OHE.fit(data3.reshape(-1,1))
OHE.transform(data3.reshape(-1,1)).toarray()
array([[0., 1.],
[1., 0.],
[1., 0.],
[0., 1.]])
get_dummies
get_dummies的效果和LabelEncoder一致
pd.get_dummies(data)
学号 性别 学历
0 1001 1 1
1 1002 0 2
2 1003 0 0
3 1004 1 1
LabelBinarizer
对因变量y不能用OneHotEncoder,要用LabelBinarizer。
from sklearn.preprocessing import LabelBinarizer
lab = LabelEncoder()
lab.fit_transform(data['学历'])
array([1, 2, 0, 1], dtype=int64)