目录
一、关系型数据库
1.什么是关系型数据库
关系型数据库是建立在关系模型基础上的数据库
简单来说,关系型数据库是由多张能互相连接的 二维表 组成的数据库
2.主要优点
都是使用表结构,格式一致,易于维护
使用通用的SQL语言操作,使用方便,可用于复杂查询
数据存储在磁盘中,安全
二、SQL语句
1.简介:
Structured Query Language,简称 SQL
结构化查询语言,一门操作关系型数据库的编程语言
定义操作所有关系型数据库的统一标准
对于同一个需求,每一种数据库操作的方式可能会存在一些不一样的地方,我们称为“方言”
2.SQL通用语法
SQL 语句可以单行或多行书写,以分号结尾
MySQL数据库的 SQL 语不区分大小写,关键字建议使用大写!(为了好辨识我用的小写,正常应该用大写)
注释
单行注释: --注释内容或#注释内容(MySQL 特有)
多行注释:/* 注释内容 */
3.SQL语法分类
DDL:(Data Definition Language)数据定义语言,用来定义数据库对象: 数据库,表,列等
操作数据的:库,表等
DML:(Data Manipulation Language)数据操作语言,用来对数据库中表的数据进行增删改
对表中数据进行增删改
DQL:(Data Query Language)数据查询语言,用来查询数据库中表的记录(数据)
对表中数据进行查询
DCL:(Data ControlLanguage)数据控制语言,用来定义数据库的访问权限和安全级别,以及创建用户
对数据库进行权限控制
4.DDL
(1)查询库
#查看所有数据库
show databases;(2)创建库
#创建数据库
create database 数据库名;
#创建数据库(加判断)
create database if not exists 数据库名;(3)删除库
#删除数据库
drop database 数据库名;
#删除数据库(加判断)
drop database if exists 数据库名;(4)使用库
#查看当前使用的数据库
select database();
#使用/进入指定数据库
use 数据库名;(5)查询表
#查看库中所有表
show tables;
#查看表结构
desc 表名;(6)创建表
#创建表,最后一行没有,
create table 表名(
字段名01 数据类型01,
字段名02 数据类型02,
字段名03 数据类型03,
...
字段名n 数据类型n
);
create table user(
id int,
name varchar(20),
password varchar(40)
);(7)删除表
#删除表
drop table 表名;
#删除表(带判断)
drop table if exists 表名;(8)修改表
#修改表名
alter table 表名 rename 新表名;
#表中添加一列(末尾插入)
alter table 表名 add 列名 数据类型;
#删除指定列
alter table 表名 drop 列名;
#修改数据类型
alter table 表名 modify 列名 新数据类型;
#修改列名和数据类型
alter table 表名 change 列名 新列名 新数据类型;
(9)SQL中的数据类型
分为三类,我举例只是常用的
数值类:
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 Bytes | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 Bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | 自查 | 自查 | 极大整数值 |
| FLOAT | 4 Bytes | 自查 | 自查 | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | 自查 | 自查 | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
double(数值总长度,小数点保留位数【0-100】)
日期和时间类:
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59' | YYYY-MM-DD hh:mm:ss | 混合日期和时间值 |
| TIMESTAMP | 4 | '1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07' UTC 结束时间是第 2147483647 秒 北京时间:2038-1-19 11:14:07 格林尼治时间: 2038年1月19日 凌晨 03:14:07 |
YYYY-MM-DD hh:mm:ss | 混合日期和时间值,时间戳 |
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串(高效但费空间) |
| VARCHAR | 0-65535 bytes | 变长字符串(低效但省空间) |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
5.DML
(1)添加数据
#给指定列添加数据
insert into 表名(列名01,列名02,列名03, ... ,列名n) value(值01,值02,值03, ... ,值n);
#给全部列添加数据
insert into 表名 values(值01,值02,值03, ... ,值n);
#批量添加数据
#方式一
insert into 表名(列名01,列名02,列名03, ... ,列名n) values(值01,值02,值03, ... ,值n),(值01,值02,值03, ... ,值n),(值01,值02 ... ,值n)...;
#方式二
insert into 表名 values(值01,值02,值03, ... ,值n),(值01,值02,值03, ... ,值n),(值01,值02,值03, ... ,值n)...;(2)修改数据
#修改表数据
#注意:如果不加条件判断,则为修改全部数据!
update 表名 set 列名1=值1,列名2=值2,...,列名n=值n [where 条件]
UPDATE user SET id = 10,num = 3, score = 99 WHERE name="张三";(3)删除数据
#删除表数据
#注意:如果不加条件,则为删除所有数据!
delete from 表名 [where条件]6.DQL(单表查询)
(1)基础查询
#查询表中所有数据
select * from 表名;
#查询表中多个字段中的数据【多个字段用,隔开】
select 字段列表 from 表名;
#去除重复记录
select distinct 字段列表 表名;
#起别名,AS可以省略
as 别名
#如
select name as 姓名 from user;
select name 姓名 from user;(2)条件查询
#基础查询+条件列表
select name from user where id = 3;(3)分组查询
#select 聚合函数(列名) from 表名;
#null 值不参与所有聚合函数运算
select avg(score) from user;
#分组查询
#基础查询+(条件)group by 分组字段名 (having 分组后条件)
#分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
#按性别分组,查询平均分
select sex,avg(score) from user group by sex;
#按性别分组,查询平均分和各自的人数
select sex,avg(score),count(*) from user group by sex;
#按性别分组,查询平均分和各自的人数,要求低于60分的不参与平均
select sex,avg(score),count(*) from user where score>60 group by sex;
#按性别分组,查询平均分和各自的人数,要求低于60分的不参与平均,分组后人数要大于2
select sex,avg(score),count(*) from user where score>60 group by sex having count(*) > 2;注意点:
分组之后,查询的字段应为聚合函数和分组字段,查询其他字段无任何意义
where 和 having的区别:
执行时机:where 是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤.
限定范围:where 不能对聚合函数进行判断,having可以对聚合函数进行判断
执行顺序:where > 聚合函数 > having
(4)排序查询
#基础查询+(条件查询)+order by 排序字段名1 排序方式,排序字段名2 排序方式...
#如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
select name,math,chinese from user order by math desc,chinese asc;(5)分页查询
#基础查询 + limit 起始索引,查询条目数
#起始索引:从0开始
#计算公式:起始索引 = (当前页面-1)*每页显示条数
select * from user limit 0,3;
#每页显示10条数据,查询第3页的数据
select * from user limit 20,10;分页查询在不同数据库的关键字
Mysql:limit
Oracle:rownumber
SQL Server:top
(6)条件列表(关键字推荐大写,为了好辨识写的小写)
| 符号 | 说明 |
|---|---|
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| = | 等于 |
| <>/!= | 不等于 |
| between...and... | 在[ ]区间,内容可为日期 |
| in(a,b,c,d...) | 多选一,满足其一即成立 |
| like 占位符 (_单个任意字符) (%多个任意字符) | 模糊查询 |
| is null | 是null |
| is not null | 不是null |
| and/&& | 并且(推荐and) |
| or/|| | 或(推荐or) |
| not/! | 非 |
(7)排序方式
| 排序方式 | 说明 |
|---|---|
| ASC(默认) | 升序 |
| DESC | 降序 |
(8)聚合函数
将一列数据作为一个整体,进行纵向计算。
| 函数名 | 说明 |
|---|---|
| count(列名) | 统计数量(不为null的值,一般推荐主键和*) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
三、图形化客户端工具-Navicat
Navicat for MysQL 是管理和开发MySQL或MariaDB 的理想解决方案
这套全面的前端工具为数据库管理、开发和维护提供了一款直观而强大的图形界面
官网: Navicat 中国 | 支持 MySQL、Redis、MariaDB、MongoDB、SQL Server、SQLite、Oracle 和 PostgreSQL 的数据库管理
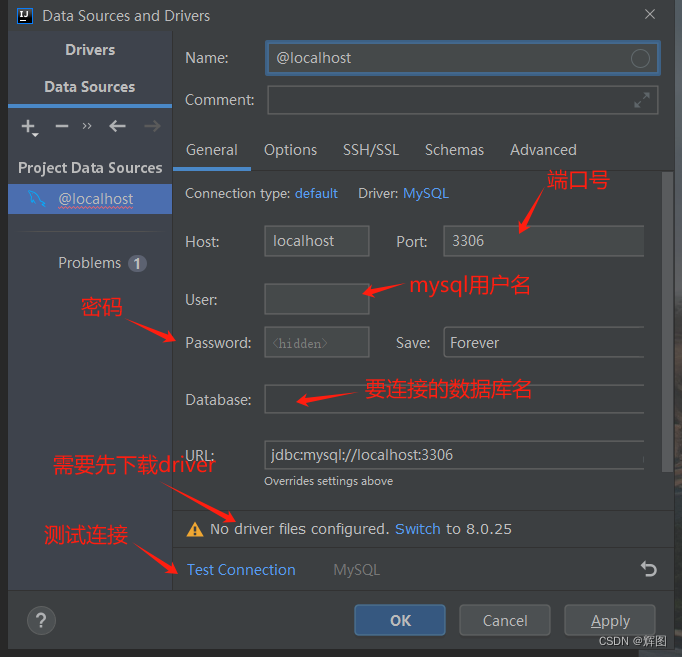
1.工具的使用
打开Navicat
文件
新建连接
选择mysql/MariaDB都可以

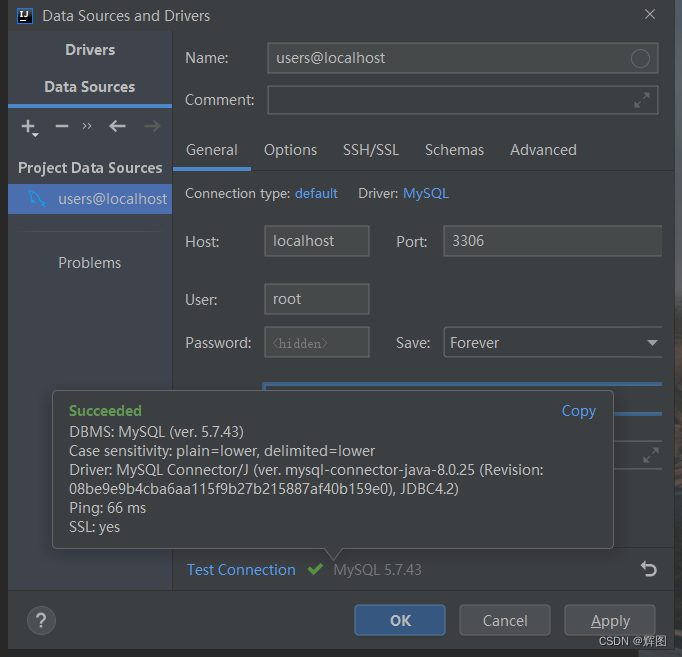
设置好连接名和密码即可进行连接
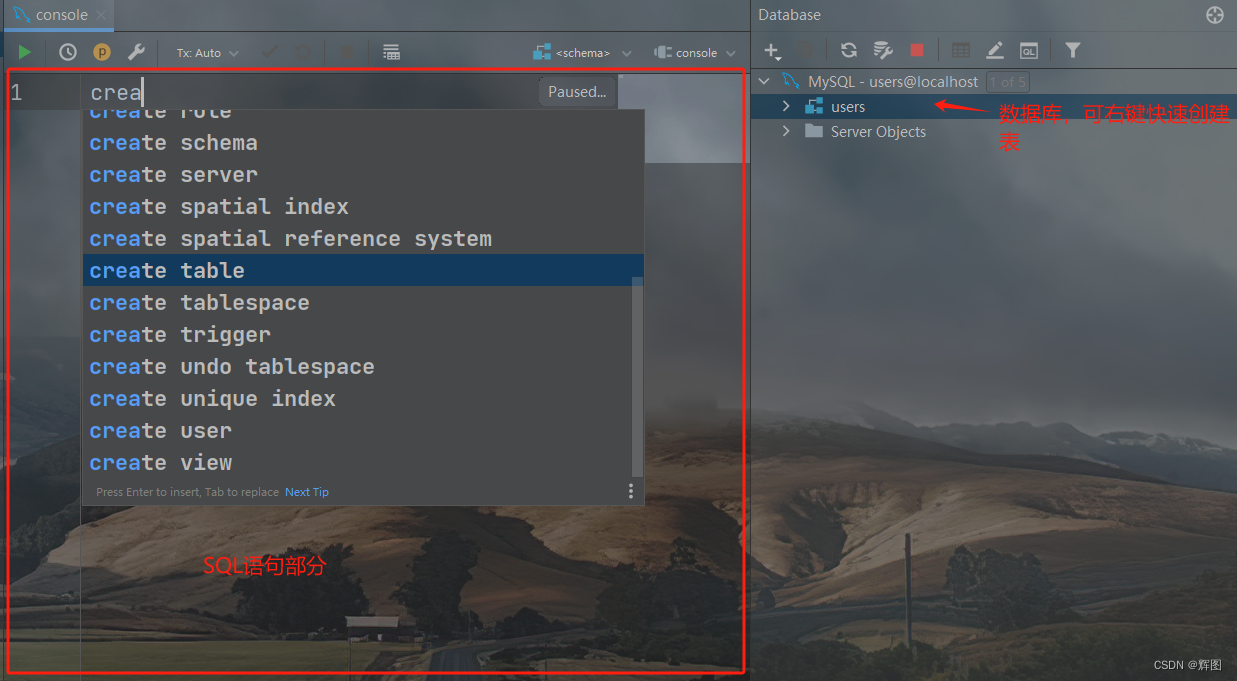
点击连接名,右键,新建数据库,之后自己玩吧~


![[<span style='color:red;'>MySQL</span>-<span style='color:red;'>基础</span>]<span style='color:red;'>SQL</span><span style='color:red;'>语句</span>](https://img-blog.csdnimg.cn/39276fbbf5d24d7f81115e234a3baec6.png)






















![[TCP协议]基于TCP协议的字典服务器](https://img-blog.csdnimg.cn/direct/9c998e9bb1df47158b3a621817dda29c.png)