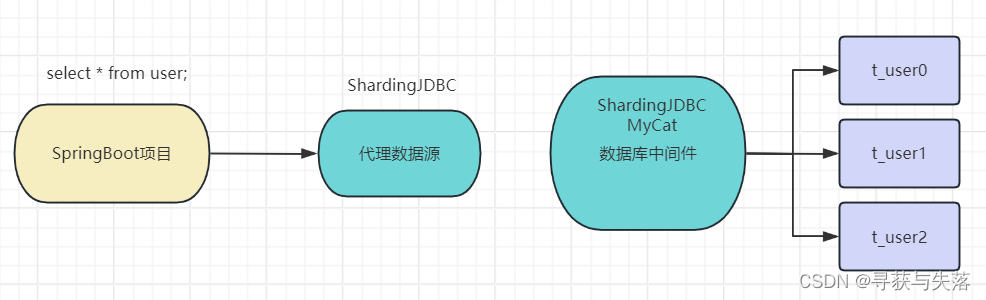
分库分表
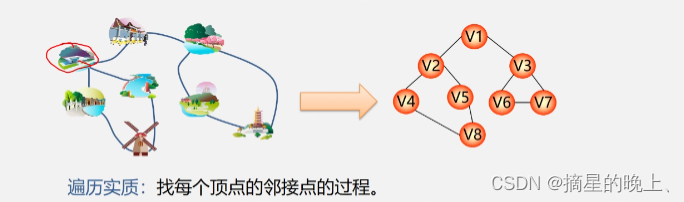
1. 分库分表相关概念
1.1. 为什么需要分库分表 ?
| 分库分表前面临的问题 | 产生的问题 | 解决办法 |
|---|---|---|
| 用户请求量太大 | 互相竞争 CPU、内存、文件 IO、网络 IO,连接数 | 分散请求到多个服务器 |
| 单库太大 | 单库处理能力有限、所在服务器上的磁盘空间不足、遇到 IO 瓶颈 | 切分成更多更小的库 |
| 单表太大 | 会导致 b + 树的层级变高,大于 3 层后影响索引的查询性能对于表结构的修改,会引起长时间的锁等待 ,进而撑爆线程数 | 切分成多个数据集更小的表 |
1.2. 什么是分库分表 ?
分库: 将一个库的数据拆分到多个相同的库中,访问的时候访问一个库
分表: 把一个表的数据放到多个表中,操作对应的某个表就行
2. 分库分表的方案
分库分表具体分为垂直拆分和水平拆分两种方式,我们应该遵循先垂直,后水平的拆分方案
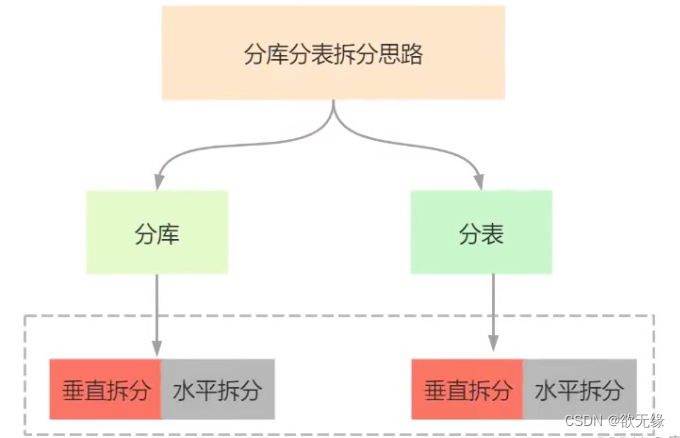
2.1. 垂直拆分
2.1.1 垂直分库
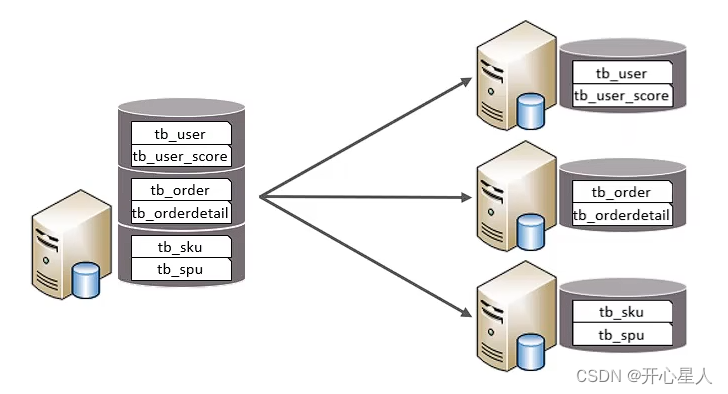
垂直分库指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
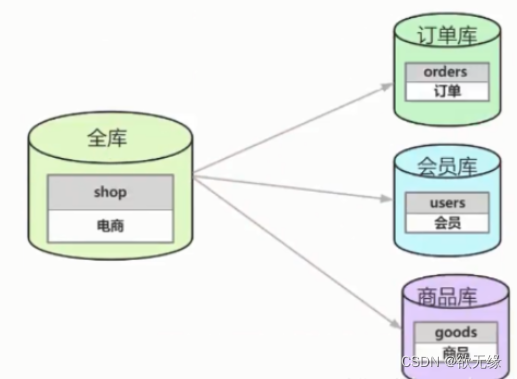
根据业务拆分,如图,电商系统,拆分成订单库,会员库,商品库
优点:
数据维护方便易行,容易定位
减轻了单个库的负载
2.1.2 垂直分表
垂直分表指将一个表按照字段分成多表,每个表存储其中一部分字段
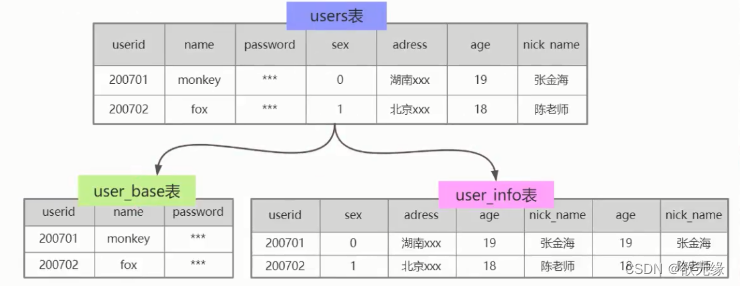
根据业务去拆分表,如图,把 user 表拆分成 user_base 表和 user_info 表,use_base 负责存储登录,user_info 负责存储基本用户信息
优点:
- 业务划分明确,类似微服务思想职责清晰
- 针对不同的数据,可以实现冷热分离,动静分离
- 有了对应的拆分,我们可以根据业务热度,考虑成本,适配不同配置的机器,方便扩展与维护
2.2. 水平拆分
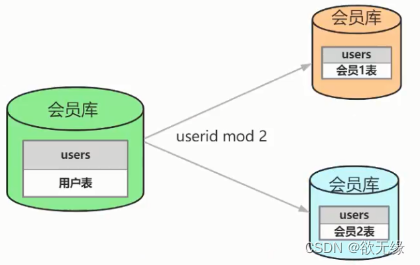
2.2.1 水平分库
水平分库指将一个数据库中的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上
优点:
- 解决了单库大数据,高并发的性能瓶颈
- 提高了系统的稳定性及可用性
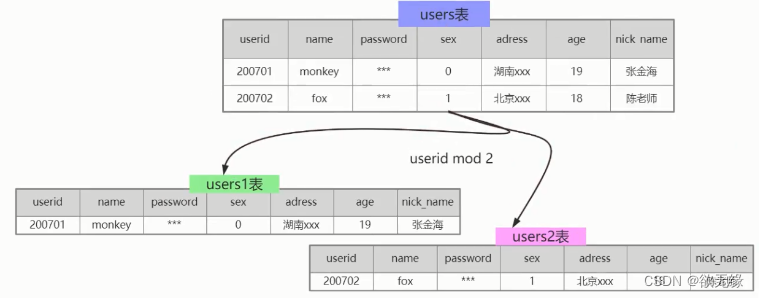
2.2.2 水平分表
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中
优点:
- 优化单一表数据量过大而产生的性能问题
- 水平分表的表结构一致,横向扩展时,业务端可以做到无感知无改动
3. 操作实践
接下来,我们就以水平分表为例,展开讨论其中会遇到的问题,及解决办法。
3.1. 指导思想
分表时,什么是我们需要考虑的内容?怎么样才能制定一个完善的分库分表方案?
3.1.1. 方案可持续性
前期业务数据量级不大,流量较低的时候,我们无需分库分表,也不建议分库分表。
但是一旦我们要对业务进行分库分表设计时,就一定要考虑到分库分表方案的可持续性。
那何为可持续性?其实就是:业务数据量级和业务流量未来进一步升高达到新的量级的时候,我们的分库分表方案可以持续使用。
一个通俗的案例,假定当前我们分库分表的方案为 10 库 100 表,那么未来某个时间点,若 10 个库仍然无法应对用户的流量压力,或者 10 个库的磁盘使用即将达到物理上限时,我们的方案能够进行平滑扩容。
在后文中我们将介绍下目前业界常用的翻倍扩容法和一致性 Hash 扩容法。
3.1.2. 数据偏斜问题
一个良好的分库分表方案,它的数据应该是需要比较均匀的分散在各个库表中的。
如果我们进行一个拍脑袋式的分库分表设计,很容易会遇到以下类似问题:
某个数据库实例中,部分表的数据很多,而其他表中的数据却寥寥无几,业务上的表现经常是延迟忽高忽低,飘忽不定。
数据库集群中,部分集群的磁盘使用增长特别块,而部分集群的磁盘增长却很缓慢。每个库的增长步调不一致,这种情况会给后续的扩容带来步调不一致,无法统一操作的问题。
这边我们定义分库分表最大数据偏斜率为:(数据量最大样本 - 数据量最小样本)/ 数据量最小样本。
一般来说,如果我们的最大数据偏斜率在 5% 以内是可以接受的。
3.2. 常见路由策略
水平分表的方案不同,主要来源于路由策略的不同。接下来讨论一下几种不同的路由策略
3.2.1 Range 分库分表
顾名思义,就是通过一定的范围,将表数据分配到不同的库中。
比如:
通过 uid,1-1000,1001-2000 为范围分不同的库
根据地区,华南,华中,华东分别在不同的库
根据时间,每个季度的数据都在新库
这样的分库分表看似简单,但也存在一些致命的缺陷,比如:
数据热点问题,如果根据时间分表,我们可以认为最新的数据被查询的概率也最大,那么大量的查询都会落在最新的那张表上,没有均匀的分布查询流量
新表追加问题,一般我们线上运行的应用程序是没有数据库的建库建表权限的,故我们需要提前将新的库表提前建立,防止线上故障。这点非常容易被遗忘,尤其是稳定跑了几年没有迭代任务,或者人员又交替频繁的模块。
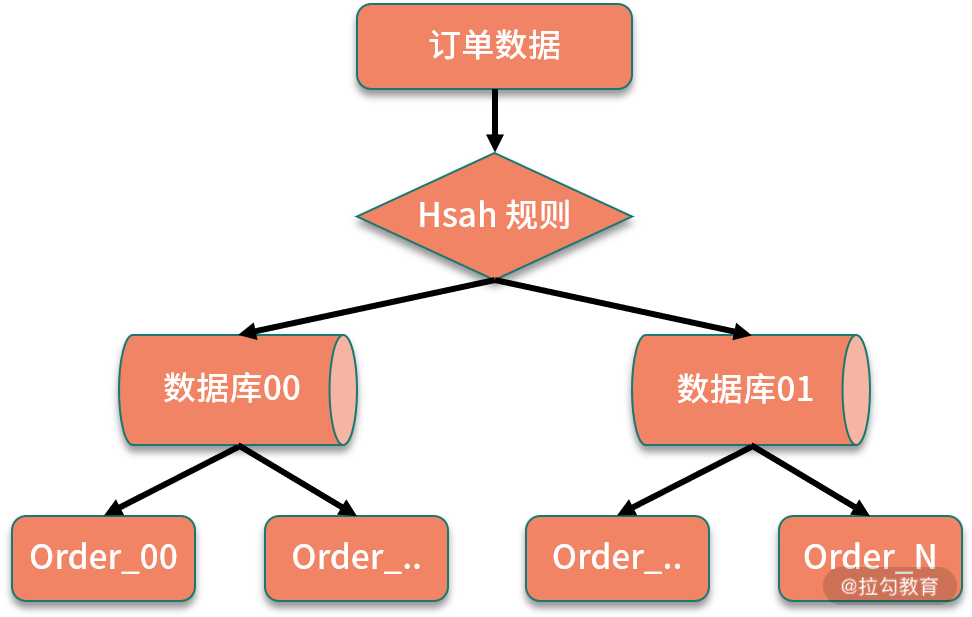
3.2.2 Hash 取模分库分表
虽然分库分表的方案众多,但是 Hash 分库分表是最大众最普遍的方案,也是本文花最大篇幅描述的部分。
标准的二次分片法
这是最经典的 hash 分片规则,并且能够兼容后期的扩容方案。
public static ShardCfg shard2(String userId){
// ① 算Hashint
hash = userId.hashCode();
// ② 总分片数int
sumSlot = DB_CNT * TBL_CNT;
// ③ 分片序号
int slot = Math.abs(hash % sumSlot);
// ④ 重新修改二次求值方案int
dbIdx = slot / TBL_CNT ;
int tblIdx = slot % TBL_CNT ;
return new ShardCfg(dbIdx, tblIdx);
}
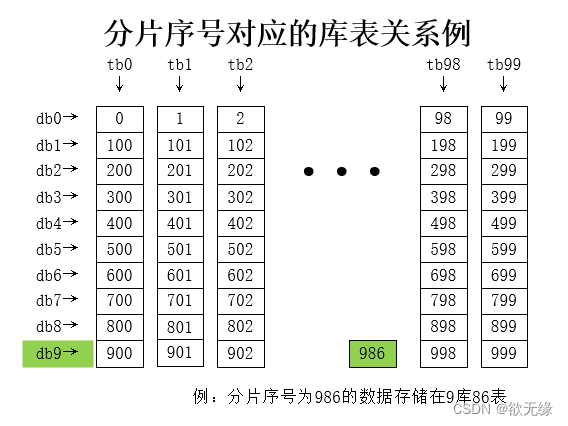
根据以上算法,假设我们分 10 个库 100 张表,他的分配情况如下:
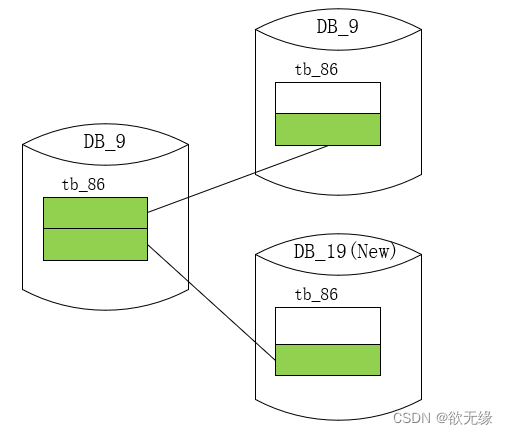
通过翻倍扩容后,我们的表序号一定维持不变,库序号可能还是在原来库,也可能平移到了新库中 (原库序号加上原分库数),完全符合我们需要的扩容持久性方案。
方案缺点:
翻倍扩容法前期操作性高,但是后续如果分库数已经是大几十的时候,每次翻倍扩容都非常耗费资源。
连续的分片键 Hash 值大概率会散落在相同的库中,某些业务可能容易存在库热点(例如新生成的用户 Hash 相邻且递增,且新增用户又是高概率的活跃用户,那么一段时间内生成的新用户都会集中在相邻的几个库中)。
路由关系记录表
该方案还是通过常规的 Hash 算法计算表序号,而计算库序号时,则从路由表读取数据。
因为在每次数据查询时,都需要读取路由表,故我们需要将分片键和库序号的对应关系记录同时维护在缓存中以提升性能。
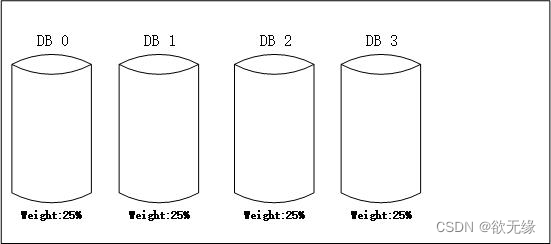
优点:
我们可以给每个库设置权重,根据库数据的负载动态调整权重。
理论上后续进行扩容的时候,仅需要挂载上新的数据库节点,将权重配置成较大值即可,无需进行任何的数据迁移即可完成。
缺点:
每次读取数据需要访问路由表,虽然使用了缓存,但是还是有一定的性能损耗。
路由关系表的存储方面,有些场景并不合适。例如上述案例中用户 id 的规模大概是在 10 亿以内,我们用单库百表存储该关系表即可。但如果例如要用文件 MD5 摘要值作为分片键,因为样本集过大,无法为每个 md5 值都去指定关系(当然我们也可以使用 md5 前 N 位来存储关系)。
3.3. 拆分后遇到的问题
3.3.1. 分布式事务问题
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难
3.3.2 跨库跨表的 join 问题
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法 join 位于不同分库的表
3.3.3. 主键生成问题
由于我们一般用主键作为分片键,在不同表中,如果用主键 id 自增的方式,会导致主键重复的问题。所以需要引入全局 id 生成器,具体的 id 生成器方案,大家感兴趣可自行查阅资料。
3.3.4. 非分片键查询问题
大多数场景,我们都是用主键作为分片键,这样路由的规则只和主键相关。我们通过主键查询,很容易就路由到对应的表查询要想要的数据。像这样
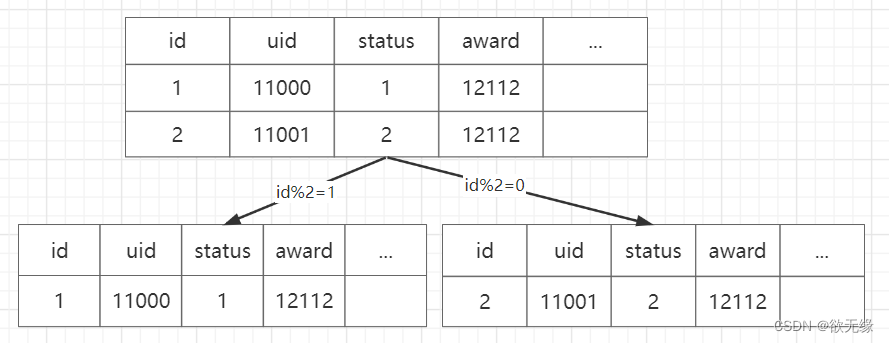
但还有百分之 20 的请求,可能需要查询 uid 下的所有所有任务数据。而相同 uid 可能被分到了不同的库,我们需要聚合所有库的查询,然后返回给前端,这样多次数据库连接非常麻烦,且低效。
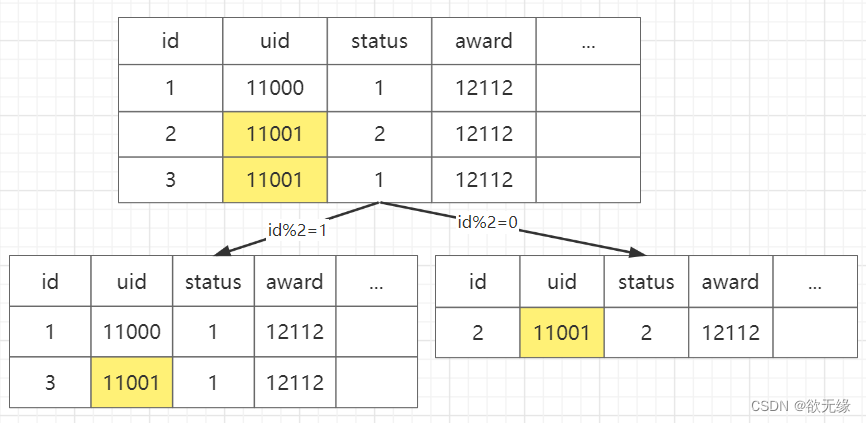
我们可能会尝试用 uid 作为分片键,这样相同 uid 肯定会在同一个库。我们只需要查询一个库就能获取想要的所有数据,看起来很棒,像这样
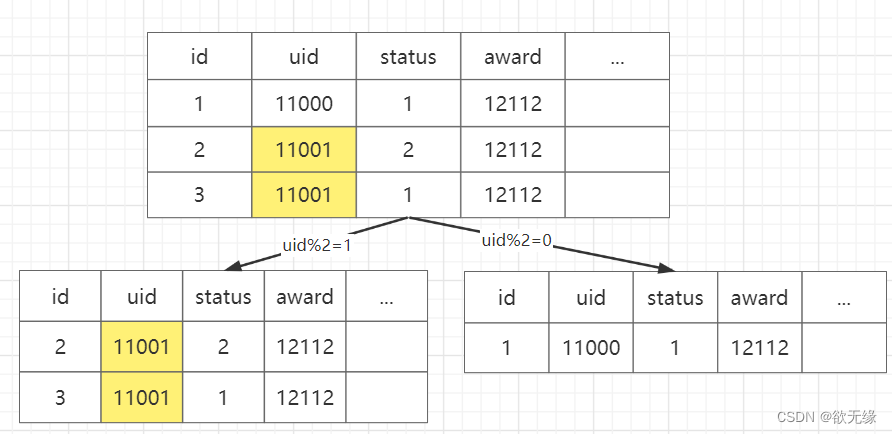
但是这样会导致我们用主键查询的时候,完全找不到对应的路由关系了。这样的改造就是因小失大,得不偿失。那么怎么同时能够查询主键,又能够根据 uid 查询呢?
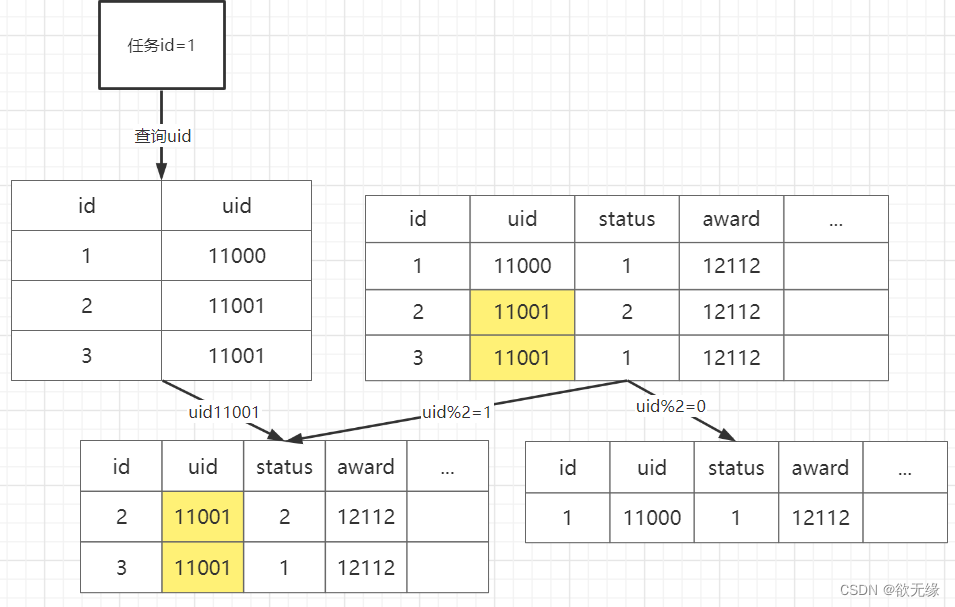
3.3.4.1. 映射关系表
还是用 uid 进行分片,将主键和需要查询的 uid 做一个映射关系表,这样需要查询主键的时候,先去映射表找到对应的 uid,再通过 uid,就能路由到对应的表了。
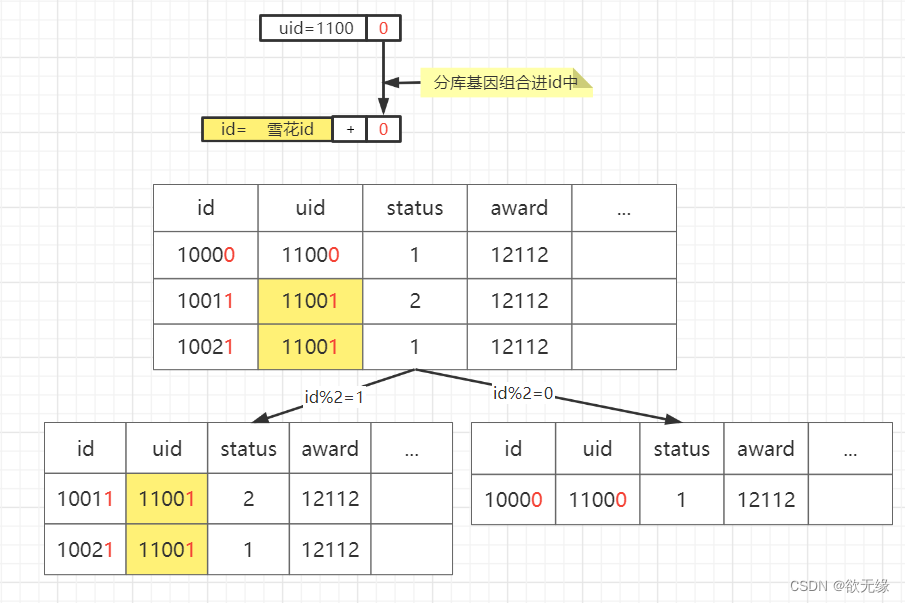
3.3.4.2. 基因法
或者我们可以截取 uid 的尾部几位作为特征基因,嵌入主键中。用主键的这部分基因进行分片。这样就像 uid 寄生了主键一样。看似用主键分片,实际上还是用 uid 分片。两者都能通过路由规则查询的方式路由到对应的表。
3.3.4.3. ES 查询
那么在传统的商品表中,我们不仅需要查询商户 id,还会查询 sku,spu,这么多的查询条件,基因法还能有效么?这样的情况下,我们最好是能通过 canal,将所有数据聚合进 es 数据库中,整理出 olap 供业务端多条件,多场景的查询功能。
3.4. 扩容方案
扩容方案,是在我们最初做分库分表就该思考好的问题。如果当初没有一个合理的规划,那么当数据量又一次达到负荷,这个锅就会被传递给下一位接手的同事。
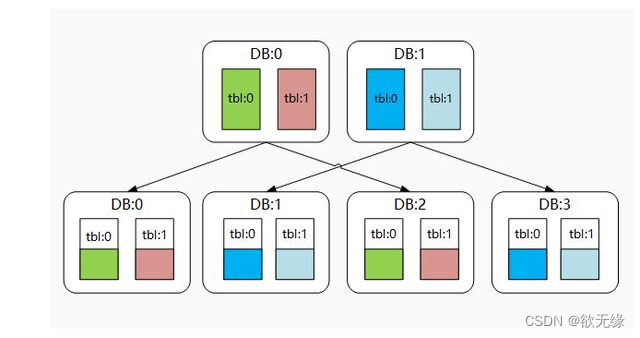
3.4.1. 翻倍扩容法
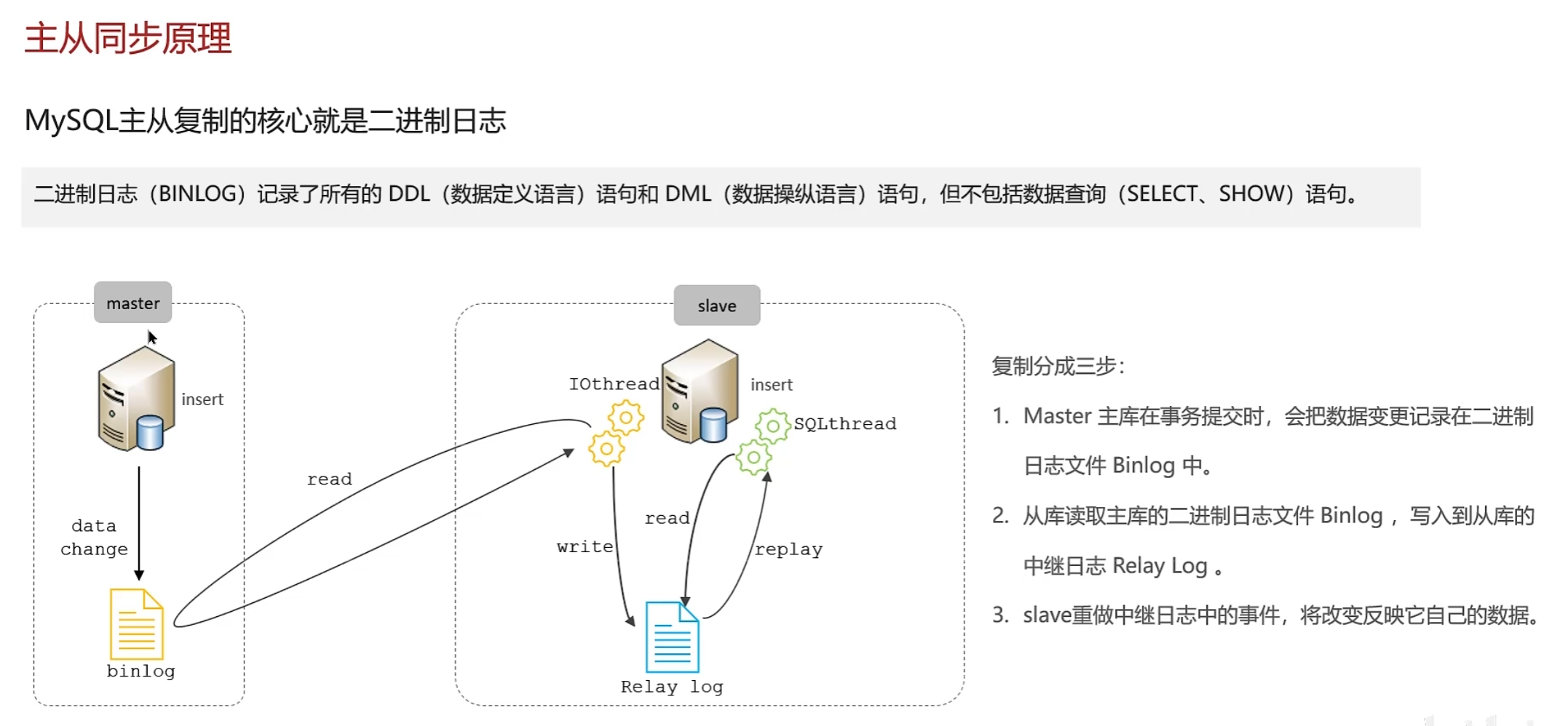
翻倍扩容法的主要思维是每次扩容,库的数量均翻倍处理,而翻倍的数据源通常是由原数据源通过主从复制方式得到的从库升级成主库提供服务的方式。故有些文档将其称作 “从库升级法”。
理论上,经过翻倍扩容法后,我们会多一倍的数据库用来存储数据和应对流量,原先数据库的磁盘使用量也将得到一半空间的释放。
如下图所示:
时间点 t1: 为每个节点都新增从库,开启主从同步进行数据同步。
时间点 t2: 主从同步完成后,对主库进行禁写。
此处禁写主要是为了保证数据的正确性。若不进行禁写操作,在以下两个时间窗口期内将出现数据不一致的问题:
断开主从后,若主库不禁写,主库若还有数据写入,这部分数据将无法同步到从库中。
应用集群识别到分库数翻倍的时间点无法严格一致,在某个时间点可能两台应用使用不同的分库数,运算到不同的库序号,导致错误写入。
时间点 t3: 同步完全完成后,断开主从关系,理论上此时从库和主库有着完全一样的数据集。
时间点 t4: 从库升级为集群节点,业务应用识别到新的分库数后,将应用新的路由算法。
一般情况下,我们将分库数的配置放到配置中心中,当上述三个步骤完成后,我们修改分库数进行翻倍,应用生效后,应用服务将使用新的配置。
这里需要注意的是,业务应用接收到新的配置的时间点不一定一致,所以必定存在一个时间窗口期,该期间部分机器使用原分库数,部分节点使用新分库数。这也正是我们的禁写操作一定要在此步完成后才能放开的原因。
时间点 t5: 确定所有的应用均接受到库总数的配置后,放开原主库的禁写操作,此时应用完全恢复服务。
启动离线的定时任务,清除各库中的约一半冗余数据。
缺点也很明显,就是每次扩容都是翻倍,多次翻倍后,会浪费不少数据库资源。
3.4.2. 一致性 Hash 扩容
一致性 hash 的原理可以参考网上的资料,或者参考笔者的其他文章。
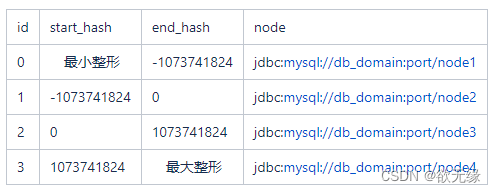
我们一般会有个配置,将一部分虚拟节点映射到对应的真实的库里。当某个库压力过大时,我们只需要针对需要扩容的库,把这一部分虚拟节点分给另一个新的库,灵活的进行扩容。

主要步骤如下:
时间点 t1: 针对需要扩容的数据库节点增加从节点,开启主从同步进行数据同步。
时间点 t2: 完成主从同步后,对原主库进行禁写。此处原因和翻倍扩容法类似,需要保证新的从库和原来主库中数据的一致性。
时间点 t3: 同步完全完成后,断开主从关系,理论上此时从库和主库有着完全一样的数据集。
时间点 t4: 修改一致性 Hash 范围的配置,并使应用服务重新读取并生效。
时间点 t5: 确定所有的应用均接受到新的一致性 Hash 范围配置后,放开原主库的禁写操作,此时应用完全恢复服务。启动离线的定时任务,清除冗余数据。
4. 总结
本文主要描述了我们进行水平分库分表设计时的一些常见方案。
我们在进行分库分表设计时,可以选择例如范围分表,Hash 分表,路由表,或者一致性 Hash 分表等各种方案。进行选择时需要充分考虑到后续的扩容可持续性,最大数据偏斜率等因素。