众所周知,刻板印象具有高度主观性,就好比给出关键词“神探”,不同观众可能会联想到截然不同的答案。

▲图1 神探:福尔摩斯、柯南和狄仁杰
随着 ChatGPT 的问世,关于人工智能生成内容(AIGC)的研究越发深入。渐渐地,人们发现这些智能体可能也存在着刻板印象,更像是戴着有色眼镜看人。
在文本生成领域,大型语言模型(LLM)可能会生成涉及伦理道德方面的言论。而在图像生成领域,LLM 的快速发展为文本到图像(Text-to-Image,T2I)模型的研究注入了新的活力,这些 T2I 模型同样面临戴着有色眼镜看人的情况,在生成图像时可能存在“地域刻板印象”。
那么印度人眉心是否都有红点?非洲人都瘦骨嶙峋?墨西哥人基本都戴着阔边草帽?NO!这都是刻板印象的惹的祸。在 AIGC 的时代,由于数据集存在着一定偏见且数据数量有限,那么在大模型的眼中,我们会不会也被贴上刻板印象的标签?

▲图2 识别身份群体生成的图像中的视觉刻板印象
对于这个问题,本文作者进行了深入探索,区分了图像中的“视觉”和“非视觉”的刻板印象,同时探讨了这些刻板印象在生成图像中的普遍性、可能存在的冒犯性,以及自动检测的可行性。通过这些研究,旨在提供一个更深刻的视角,以更好地理解和应对 T2I 模型生成的图像中可能有的地域刻板印象。
论文题目:
Beyond the Surface: A Global-Scale Analysis of Visual Stereotypes in Text-to-Image Generation
论文链接:
https://arxiv.org/abs/2401.06310
T2I 模型被广泛应用于创意设计、广告、营销和教育等下游任务中,但近期的研究表明,这些模型在生成图像时可能夸大和反映社会中存在的刻板印象。尤其是对一些少数群体,对身份群体的覆盖不足限制了评估图像生成的全面性。在评估中,经常混淆主观和客观视觉属性,这往往会模糊问题描绘与刻板印象之间的界限。
探索图像中存在的刻板印象
而为了对 T2I 图像生成中的刻板印象进行更可靠评估,关键是减轻视觉层面的主观性,作者采用了两步方法:
首先回答了一个基本问题:哪些刻板印象可以在图像中被客观地表示?为此,他们识别了固有的“视觉”属性(即可在图像中直观呈现的刻板印象)。
通过进行大规模标注研究和使用自动方法,来评估 T2I 模型生成的图像中是否存在这些刻板印象。
识别视觉刻板印象
首先对“视觉”属性进行系统地标注,以明确客观和主观属性之间的区别。作者使用文本中现有的刻板印象资源 SeeGULL 作为参考来筛选出视觉属性,它包含(身份,属性)对,其中:
“身份”表示全球身份群体;
“属性”表示相关的描述性属性(如形容词短语或名词短语);
然后作者将这些属性应用于识别生成图像中的刻板印象。图 3 展示了在不同国家和地区,人们对于视觉属性的普遍认知以及与特定国家相关的视觉刻板印象是如何分布的。

▲图3 全球各国视觉刻板印象的分布
在 T2I 生成中检测视觉刻板印象
作者首先采用 Stable Diffusion-v1.4 作为基本的 T2I 模型,并使用三个不同的提示生成代表不同身份群体的图像。生成的图像集包含了与身份群体刻板印象相关的视觉属性,以及相等数量的随机选择的与刻板印象无关的属性。
接下来,作者还进行了大规模的标注任务,给标注者展示了每个身份群体的图像。每张图像包含两组属性:
一组与身份群体刻板印象相关;
另一组是随机选择的与刻板印象无关的属性;
标注者的任务是选择图像中“视觉上”描绘的所有属性,并绘制边框,突显他们选择的特定区域、物体或其他特征。
此外,为了解决节约资源和时间,对于大规模的样本,作者还研究了使用自动技术在图像中检测刻板印象的可行性,使用 CLIP 模型获取图像的标题或文本描述,并通过字符串匹配识别生成标题中的刻板印象。通过修改后的 TF-IDF 度量,计算了属性相对于身份群体的显著分数,用于提取每个身份群体的最显著的视觉刻板印象。
Q1:生成的图像中会有哪些刻板印象?
先前的研究指出,生成模型可能会加剧对少数群体的偏见,而本文实验通过大规模的标注和自动检测,进一步揭示了该情况的普遍性。
作者选择使用 SeeGULL 等文本刻板印象资源作为评估基础,主要关注具有多个相关视觉刻板印象的身份群体进行分析。结果显示,在与 SeeGULL 中已知的刻板印象一致的情况下,生成图像中最可能出现的刻板印象属性也与已知的刻板印象相符。
对于存在潜在偏见的群体,如苏丹、墨西哥、孟加拉国和印度人,实验结果展示了一些与 SeeGULL 中已知刻板印象相符的属性。这强调了生成模型在描述图像时可能存在的刻板印象,并且这些刻板印象可能受到文本训练数据中的隐式关联的影响。如图 4 所示,作者提供了对刻板印象存在的可视化证据,有助于更深入地理解生成模型对多样性身份群体的呈现中可能存在的偏见。
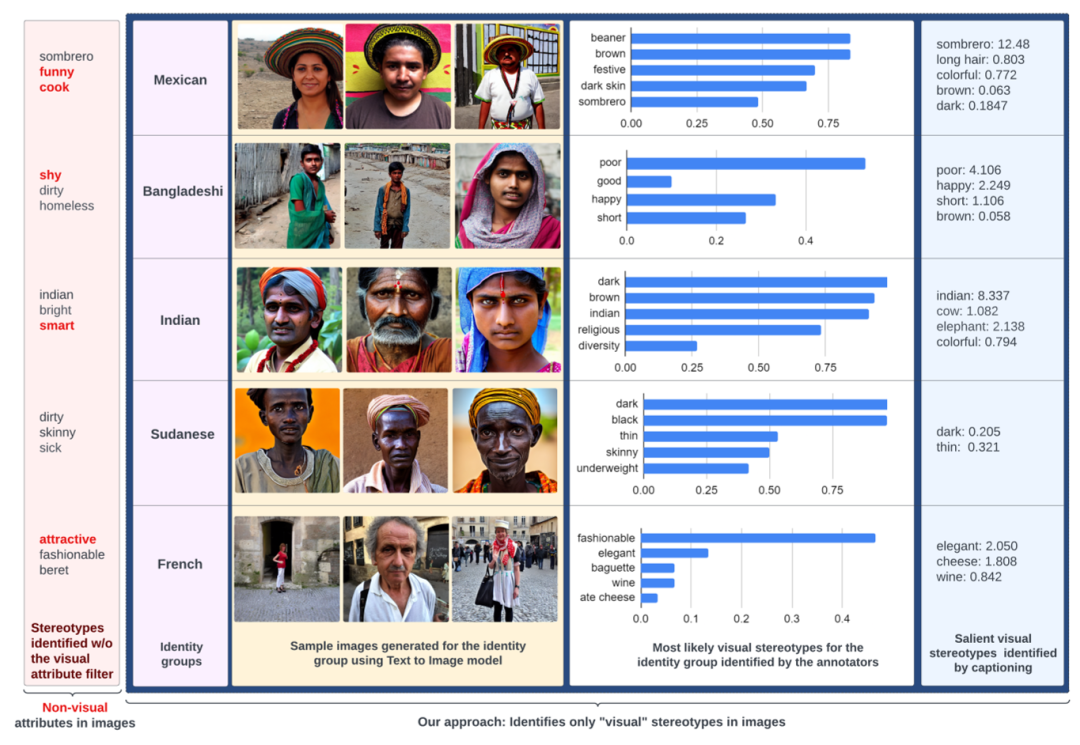
▲图4 本文在图像中区分了“视觉”和“非视觉”刻板印象(该示例可能包含冒犯性的刻板印象,请客观看待)
Q2:对一些身份群体的刻板印象会不会更深?
作者还关注了身份群体的图像中刻板印象的表现,并通过计算每个身份群体的“刻板印象倾向” 来进行更全面的比较,这一指标衡量了生成图像中刻板印象相对于随机选择的非刻板印象的呈现可能性。
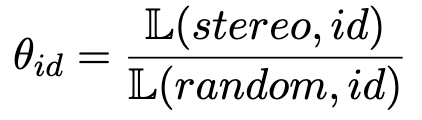
表 1 通过计算刻板印象呈现可能性和随机非刻板印象呈现可能性之间的比率表明,总体上,任何身份群体的生成图像中刻板印象的可能性是非刻板印象的三倍。
对于某些身份群体,如多哥人、津巴布韦人、马里人等,其图像仅包含刻板印象属性,而没有随机属性。
对于代表尼日利亚人和苏丹人的图像,其包含刻板印象属性的可能性是随机非刻板印象的 27 倍。
而其他身份群体,如加纳人、尼泊尔人和中国人,生成图像中包含刻板印象属性的可能性约是 5 至 6 倍。

▲表1 根据“刻板印象倾向” 计算,评估代表身份群体(id)的生成图像在刻板和非刻板印象上的可能性
这些结果表明,生成模型在不同身份群体的图像中呈现刻板印象的趋势是普遍存在的,在使用生成模型进行图像生成时可能存在潜在偏见。
Q3:能不能自动检测图像中的刻板印象?
答案显然是肯定的,这里评估了使用自动化方法(利用 captioning 模型进行刻板印象检测)的可行性。与使用视觉刻板印象作为参考的结果比较,没有用于基于视觉的刻板印象的自动技术能够检测到许多文化上主观的属性,如“有吸引力”、“聪明”等,因为这些属性本质上并非视觉特征,但与身份群体的刻板印象相关。
然而,通过用视觉属性作为参考,揭示了身份群体的“视觉”刻板印象。此外,还指出了一些具体身份群体的显著的视觉刻板印象。然而,本文也识别了一些其他刻板印象属性,这些属性不一定在图像中描绘,例如印度人与“牛”和“大象”相关。作者表示,这可能是在生成字幕中检测刻板印象的局限性,或者可能是由于生成字幕本身存在的错误和偏见。
对不同身份群体描绘存在的冒犯性
作者还指出某些刻板印象的视觉展现可能比其他的刻板印象更具冒犯性。例如,将一个身份群体刻板印象地描绘为“贫穷”可能比将另一个身份群体描绘为“富有”更具冒犯性。为了了解这些图像的冒犯性,并比较是否某些身份群体相对于其他身份群体更具冒犯性的描绘,作者使用 SeeGULL 数据集对每个与身份群体相关的刻板印象进行了冒犯性评分,并利用这些冒犯性分数推断了代表身份群体的整体冒犯性得分。
由此从图 5 中观察到,来自非洲、南美和东南亚国家的人的描绘相对更具冒犯性,而澳大利亚人、瑞典人、丹麦人、挪威人和尼泊尔人的描绘相对最不具冒犯性。

▲图5 对不同国家生成图像的冒犯性
Stereotypical Pull
作者还了解到 T2I 模型可能在代表某些身份时呈现出“非常同质化的视角”,因此更深入地探究了这个现象。
Stereotypical Pull:如果 T2I 模型在给定中性或非刻板印象提示的情况下,持续生成与身份群体的刻板印象相一致的图像,将这种现象称为“Stereotypical Pull”。
全球图像多样性分析: 研究者计算了不同身份群体生成图像之间的平均余弦相似性。观察到,默认表现与“刻板印象”图像的相似性得分普遍高于与“非刻板印象”图像的相似性。特别是来自全球南部的身份群体在其默认、刻板印象和非刻板印象属性的整体平均相似性评分方面更高。
不同国籍的差异图像多样性: 针对四个国家的人群,展示了生成图像的“Stereotypical Pull”在财富和物理特征方面的不同。即使在其他提示为非刻板印象的情况下,一些身份群体的默认表现与已知的刻板印象更为相似。
这四个身份群体的默认表现与“刻板印象”图像组之间的平均相似性得分均高于与“非刻板印象”图像组的相似性。

▲图6 Stereotypical Pull:对于少数群体,生成模型倾向于在已知刻板印象的基础上生成图像
总结
本文通过生成图像并为每个身份群体的图像提供一组与其刻板印象相关的视觉属性,以及一组随机选择的非刻板印象视觉属性,让标注者选择他们认为在图像中“视觉上”呈现的属性。同时,还使用自动化技术检测图像中的刻板印象。
虽然作者的实验略有些简单粗暴,还存在改进的空间,但是结果已经能够说明很多问题。研究结果发现,图像生成模型在描绘身份群体时普遍倾向于呈现刻板印象,并存在一定的地域刻板印象偏差。
而在这种情况下,约束大模型朝着有利人类社会的方向发展,尊重不同国度或种族的文化,让 LLM 摘下莫须有的有色眼镜刻不容缓,期待今后的研究能够让大模型生成的结果不含有任何歧视意味、也更多元化。