在上一篇文章中,我初步介绍了什么是逻辑回归模型,从它能解决什么问题开始介绍,并讲到了它长什么样子的。如果有需要的小伙伴可以回顾一下,链接我放在下面啦:
【机器学习300问】15、什么是逻辑回归模型?
在这篇文章中,我们深入了解一下逻辑回归模型是怎么实现分类的?我想我可以分成三个层次,层层递进的为大家介绍。
一、找到决策边界便能轻松分类
我想试着从直观的图表入手,反过来推我们需要做些什么才能实现如图的效果。
(1)什么是决策边界?
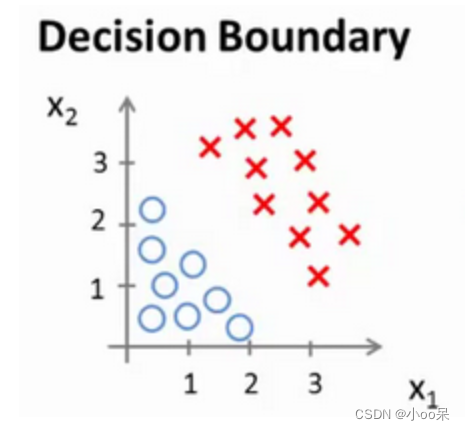
大家看到这图的一瞬间,就能想到画一条从左上到右下的线便可以将圈圈数据和叉叉数据分开,这一条线就决策边界。
用更加通用的语句定义一下,在逻辑回归模型中,我们通常通过设置一个阈值,比如0.5,来决定预测的分类。当预测的概率大于等于这个阈值时,我们将其分类为正类,反之则分类为负类。这个阈值就形成了一个决策边界。
(2)这个决策边界和逻辑回归模型什么关系?
首先复习一下逻辑回归模型长什么样子的,它是一个函数由两个部分组成,样子如下:
长相有点吓人!我来解释一下:
| 式子 | 解释 |
| 这是逻辑回归模型的预测值,也可以理解为 |
|
| 这是sigmoid函数,只不过在上一篇文章中写作 |
|
| P表示给定特征 x 的条件下,样本属于正类y=1的概率 |
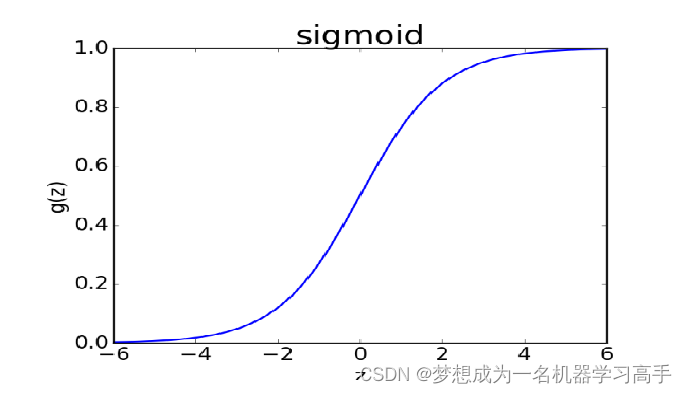
可以看到,逻辑回归模型本质是一个多项式套在sigmoid函数里面,那么我们就可以从sigmoid函数图像中看出些许端倪。
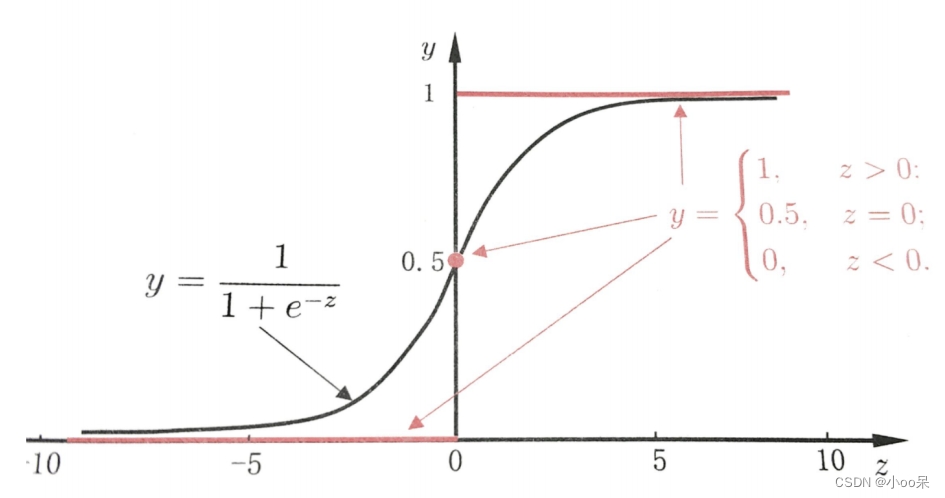
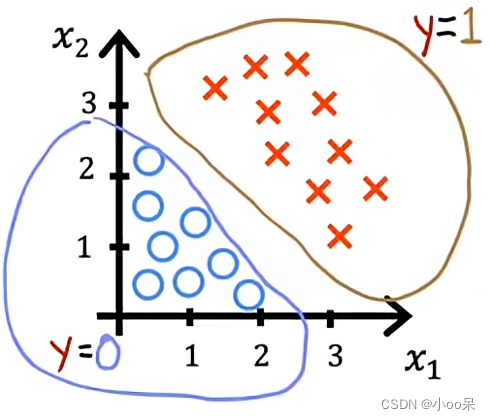
我们以sigmoid函数y=0.5为一个阈值,这里的y只是一个符号,为了与上文统一也可以写成=0.5或者g=0.5都是一个意思,当y>0.5的时候我们认为预测结果是正类,当y<0.5的时候我们认为预测结果是负类。
当y=0.5的时候z=0,又因为,所以决策边界就出来了!即:
我们还是拿这个图举例说明,在图中z=0的方程可以写作 ,这里只有两个特征量所以就直接写而不是向量形式书写了。
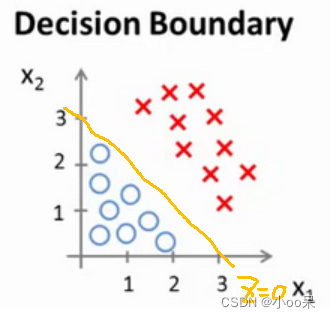
从图中可以看出,能让z=0的线有很多条,我随便画了一条,这条线的 你能感觉到w和b的不同对应了不同z决策边界,而能让训练集分成合适的两个部分的决策边界不止一条。在这里我是凭借经验或者说直觉找的一对w和b确定了一个决策边界。
(3)当样本无法用直线来区分时

决策边界的形状取决于特征和参数的选择。如果引入的特征是一组线性的,那么得到的决策边界是线性的;如果引入的特征是非线性的,那么得到的决策边界是非线性的。
比如这个图中,就可以用 来做决策边界,令z=0就可以得到
画出图像来的话就是一个圆,如下图

二、如何找到决策边界?
决策边界的作用是尽可能完美的把正类和负类分开,那么我们就可以用分的准不准作为评判标准。回到逻辑回归模型所解决的问题——二分类问题,真实值y只有可能是0或者1。那么说明我的预测值也只可能是0或者1。
(1)逻辑回归模型的损失函数
在线性回归模型中,介绍了一种叫做MSE均方误差的代价函数,来评价预测值与真实值之间的差距,进而判断模型是否尽可能的拟合数据。
在逻辑回归模型中,也存在一种Loss损失函数,来判断预测值与真实值之间的差距。它长这样:
这里暂不讨论它为什么是长这样,只是简单说一下,长这样有一个好处,那就是这是一个凸函数,没有局部最小值,可以很方便的使用梯度下降算法来求得最佳的w和b参数,进而确定决策边界,当决策边界定了就意味着逻辑回归模型也训练完成了。
另外补充说,上面这种形式的损失函数叫做交叉熵误差,它有如下的特点:
- 当模型预测的概率分布与真实分布完全一致时,交叉熵损失取得最小值0,当预测结果完全错误时,交叉熵误差趋近于无穷大。取值范围[0, 1]
- 它惩罚了模型预测概率远离真实概率的程度,鼓励模型学习更加准确的概率分布。
- 便于通过梯度下降等优化算法更新模型参数。
(2)从图像中简单理解损失函数
写的太复杂了我还是写成
。这样构建的
函数的特点是:当实际的
且预测值
也为 1 时误差为 0,当
但
不为1时误差随着
变小而变大;当实际的
且
也为 0 时误差为 0,当
但
不为 0时误差随着
的变大而变大。
三、逻辑回归模型中的梯度下降算法
(1)梯度下降算法的目的
梯度下降算法在逻辑回归中的目的是为了找到决策边界,找决策边界其实就是来确定w和b的值,故梯度下降算法就是为了寻找最佳的w和b。
在逻辑回归模型中的梯度下降算法的目标函数是损失函数J,那么梯度下降算法具体目标就变成了找到损失函数J的最小值,在上面我们介绍的是针对某一个点的损失,现在我们计算所有点的损失,也就是整体损失后得到损失函数的终极形态:
先将损失函数写成一行
在计算整体损失
(2)梯度下降算法的步骤
重复如下步骤即可

























![[SpingBoot] 3个扩展点](https://img-blog.csdnimg.cn/direct/e05cd483296548b9a669a525755ac404.png)




![[ESP32]在Thonny IDE中,如何將MicroPython firmware燒錄到ESP32開發板中?](https://img-blog.csdnimg.cn/direct/5867689746cb4bf386066a0e800b6e94.png)