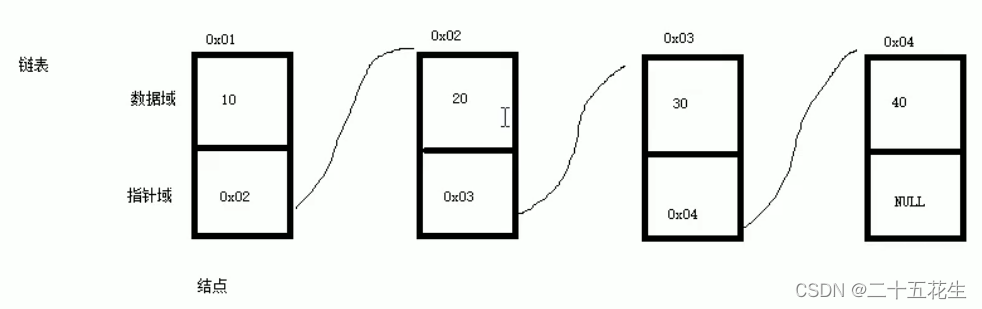
文章目录
前言
本文翻译自官方文档。
概述
MySQL包含字符集支持,使您能够使用各种字符集存储数据,并根据各种排序执行比较。默认的MySQL服务器字符集和排序规则是utf8mb4和utf8mb4_0900_ai_ci,但是您可以在服务器、数据库、表、列和字符串字面量级别指定字符集。
字符集问题不仅影响数据存储,还影响客户端程序与MySQL服务器之间的通信。如果希望客户机程序使用不同于默认字符集的字符集与服务器通信,则需要指明是哪一个。例如,要使用utf8mb4 Unicode字符集,在连接到服务器后发出以下语句:
SET NAMES 'utf8mb4';
什么是字符集和排序规则
字符集是一组符号和编码。排序规则是一组用于比较字符集中的字符的规则。让我们以一个虚构的字符集为例来明确区分。
假设我们有一个有四个字母的字母表:A,B,a,b。我们给每个字母一个数字:A = 0, B = 1, a= 2, b= 3。字母A是一个符号,数字0是A的编码,所有四个字母及其编码的组合是一个字符集。
假设我们要比较两个字符串值A和B,最简单的方法是查看编码:A为0,B为1。因为0小于1,我们说A小于B。我们刚刚做的是对字符集应用排序。排序规则是一组规则:“比较编码”。我们称这种最简单的排序为二进制排序。
但是如果我们想说小写字母和大写字母是相等的呢?那么我们将至少有两个规则:①将小写字母a和b视为等同于A和B;②然后比较编码。我们称之为不区分大小写的排序。它比二进制排序法稍微复杂一些。
在现实生活中,大多数字符集都有很多字符:不仅是A和B,而是整个字母表,有时是多个字母表或包含数千个字符的东方书写系统,以及许多特殊符号和标点符号。同样在现实生活中,大多数排序规则都有许多规则,不仅包括是否区分字母,还包括是否区分重音,以及多字符映射。
MySQL可以为你做这些事情:
- 使用不同的字符集存储字符串
- 使用不同的排序规则比较字符串
- 在同一服务器、同一数据库甚至同一表中混合使用具有不同字符集或排序规则的字符串。
- 在任何级别启用字符集和排序规范。
要有效地使用这些特性,您必须知道哪些字符集和排序是可用的,如何更改默认值,以及它们如何影响字符串操作符和函数的行为。
MySQL中的字符集和排序规则
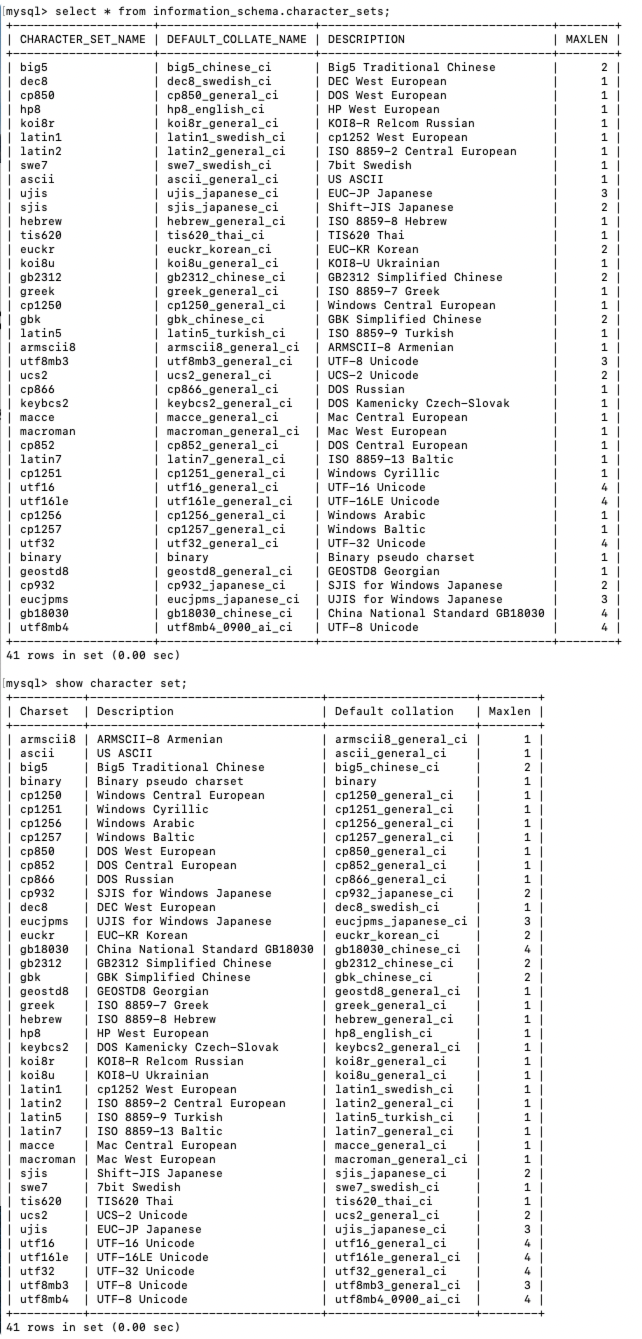
MySQL服务器支持多种字符集,包括多个Unicode字符集。要显示可用的字符集,请使用SHOW CHARACTER SET语句:
mysql> SHOW CHARACTER SET;
+----------+---------------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+---------------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| binary | Binary pseudo charset | binary | 1 |
...
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
...
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
...
| utf8mb3 | UTF-8 Unicode | utf8mb3_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
...
默认情况下,SHOW CHARACTER SET语句显示所有可用的字符集。它接受一个可选的LIKE或WHERE子句,指示要匹配的字符集名称。下面的例子显示了一些Unicode字符集:
mysql> SHOW CHARACTER SET LIKE 'utf%';
+---------+------------------+--------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+------------------+--------------------+--------+
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
| utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
| utf8mb3 | UTF-8 Unicode | utf8mb3_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
+---------+------------------+--------------------+--------+
给定的字符集总是至少有一个排序规则,大多数字符集有几个。若要列出字符集的显示排序规则,请使用SHOW COLLATION语句。
默认情况下,SHOW COLLATION语句显示所有可用的排序规则。它接受一个可选的LIKE或WHERE子句,指示要显示哪些排序规则名称。例如,要查看默认字符集utf8mb4的排序规则,请使用以下语句:
mysql> SHOW COLLATION WHERE Charset = 'utf8mb4';
+----------------------------+---------+-----+---------+----------+---------+---------------+
| Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute |
+----------------------------+---------+-----+---------+----------+---------+---------------+
| utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD |
| utf8mb4_0900_as_ci | utf8mb4 | 305 | | Yes | 0 | NO PAD |
| utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD |
| utf8mb4_0900_bin | utf8mb4 | 309 | | Yes | 1 | NO PAD |
| utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE |
| utf8mb4_croatian_ci | utf8mb4 | 245 | | Yes | 8 | PAD SPACE |
| utf8mb4_cs_0900_ai_ci | utf8mb4 | 266 | | Yes | 0 | NO PAD |
| utf8mb4_cs_0900_as_cs | utf8mb4 | 289 | | Yes | 0 | NO PAD |
| utf8mb4_czech_ci | utf8mb4 | 234 | | Yes | 8 | PAD SPACE |
| utf8mb4_danish_ci | utf8mb4 | 235 | | Yes | 8 | PAD SPACE |
| utf8mb4_da_0900_ai_ci | utf8mb4 | 267 | | Yes | 0 | NO PAD |
| utf8mb4_da_0900_as_cs | utf8mb4 | 290 | | Yes | 0 | NO PAD |
| utf8mb4_de_pb_0900_ai_ci | utf8mb4 | 256 | | Yes | 0 | NO PAD |
| utf8mb4_de_pb_0900_as_cs | utf8mb4 | 279 | | Yes | 0 | NO PAD |
| utf8mb4_eo_0900_ai_ci | utf8mb4 | 273 | | Yes | 0 | NO PAD |
| utf8mb4_eo_0900_as_cs | utf8mb4 | 296 | | Yes | 0 | NO PAD |
| utf8mb4_esperanto_ci | utf8mb4 | 241 | | Yes | 8 | PAD SPACE |
| utf8mb4_estonian_ci | utf8mb4 | 230 | | Yes | 8 | PAD SPACE |
| utf8mb4_es_0900_ai_ci | utf8mb4 | 263 | | Yes | 0 | NO PAD |
| utf8mb4_es_0900_as_cs | utf8mb4 | 286 | | Yes | 0 | NO PAD |
| utf8mb4_es_trad_0900_ai_ci | utf8mb4 | 270 | | Yes | 0 | NO PAD |
| utf8mb4_es_trad_0900_as_cs | utf8mb4 | 293 | | Yes | 0 | NO PAD |
| utf8mb4_et_0900_ai_ci | utf8mb4 | 262 | | Yes | 0 | NO PAD |
| utf8mb4_et_0900_as_cs | utf8mb4 | 285 | | Yes | 0 | NO PAD |
| utf8mb4_general_ci | utf8mb4 | 45 | | Yes | 1 | PAD SPACE |
| utf8mb4_german2_ci | utf8mb4 | 244 | | Yes | 8 | PAD SPACE |
| utf8mb4_hr_0900_ai_ci | utf8mb4 | 275 | | Yes | 0 | NO PAD |
| utf8mb4_hr_0900_as_cs | utf8mb4 | 298 | | Yes | 0 | NO PAD |
| utf8mb4_hungarian_ci | utf8mb4 | 242 | | Yes | 8 | PAD SPACE |
| utf8mb4_hu_0900_ai_ci | utf8mb4 | 274 | | Yes | 0 | NO PAD |
| utf8mb4_hu_0900_as_cs | utf8mb4 | 297 | | Yes | 0 | NO PAD |
| utf8mb4_icelandic_ci | utf8mb4 | 225 | | Yes | 8 | PAD SPACE |
| utf8mb4_is_0900_ai_ci | utf8mb4 | 257 | | Yes | 0 | NO PAD |
| utf8mb4_is_0900_as_cs | utf8mb4 | 280 | | Yes | 0 | NO PAD |
| utf8mb4_ja_0900_as_cs | utf8mb4 | 303 | | Yes | 0 | NO PAD |
| utf8mb4_ja_0900_as_cs_ks | utf8mb4 | 304 | | Yes | 24 | NO PAD |
| utf8mb4_latvian_ci | utf8mb4 | 226 | | Yes | 8 | PAD SPACE |
| utf8mb4_la_0900_ai_ci | utf8mb4 | 271 | | Yes | 0 | NO PAD |
| utf8mb4_la_0900_as_cs | utf8mb4 | 294 | | Yes | 0 | NO PAD |
| utf8mb4_lithuanian_ci | utf8mb4 | 236 | | Yes | 8 | PAD SPACE |
| utf8mb4_lt_0900_ai_ci | utf8mb4 | 268 | | Yes | 0 | NO PAD |
| utf8mb4_lt_0900_as_cs | utf8mb4 | 291 | | Yes | 0 | NO PAD |
| utf8mb4_lv_0900_ai_ci | utf8mb4 | 258 | | Yes | 0 | NO PAD |
| utf8mb4_lv_0900_as_cs | utf8mb4 | 281 | | Yes | 0 | NO PAD |
| utf8mb4_persian_ci | utf8mb4 | 240 | | Yes | 8 | PAD SPACE |
| utf8mb4_pl_0900_ai_ci | utf8mb4 | 261 | | Yes | 0 | NO PAD |
| utf8mb4_pl_0900_as_cs | utf8mb4 | 284 | | Yes | 0 | NO PAD |
| utf8mb4_polish_ci | utf8mb4 | 229 | | Yes | 8 | PAD SPACE |
| utf8mb4_romanian_ci | utf8mb4 | 227 | | Yes | 8 | PAD SPACE |
| utf8mb4_roman_ci | utf8mb4 | 239 | | Yes | 8 | PAD SPACE |
| utf8mb4_ro_0900_ai_ci | utf8mb4 | 259 | | Yes | 0 | NO PAD |
| utf8mb4_ro_0900_as_cs | utf8mb4 | 282 | | Yes | 0 | NO PAD |
| utf8mb4_ru_0900_ai_ci | utf8mb4 | 306 | | Yes | 0 | NO PAD |
| utf8mb4_ru_0900_as_cs | utf8mb4 | 307 | | Yes | 0 | NO PAD |
| utf8mb4_sinhala_ci | utf8mb4 | 243 | | Yes | 8 | PAD SPACE |
| utf8mb4_sk_0900_ai_ci | utf8mb4 | 269 | | Yes | 0 | NO PAD |
| utf8mb4_sk_0900_as_cs | utf8mb4 | 292 | | Yes | 0 | NO PAD |
| utf8mb4_slovak_ci | utf8mb4 | 237 | | Yes | 8 | PAD SPACE |
| utf8mb4_slovenian_ci | utf8mb4 | 228 | | Yes | 8 | PAD SPACE |
| utf8mb4_sl_0900_ai_ci | utf8mb4 | 260 | | Yes | 0 | NO PAD |
| utf8mb4_sl_0900_as_cs | utf8mb4 | 283 | | Yes | 0 | NO PAD |
| utf8mb4_spanish2_ci | utf8mb4 | 238 | | Yes | 8 | PAD SPACE |
| utf8mb4_spanish_ci | utf8mb4 | 231 | | Yes | 8 | PAD SPACE |
| utf8mb4_sv_0900_ai_ci | utf8mb4 | 264 | | Yes | 0 | NO PAD |
| utf8mb4_sv_0900_as_cs | utf8mb4 | 287 | | Yes | 0 | NO PAD |
| utf8mb4_swedish_ci | utf8mb4 | 232 | | Yes | 8 | PAD SPACE |
| utf8mb4_tr_0900_ai_ci | utf8mb4 | 265 | | Yes | 0 | NO PAD |
| utf8mb4_tr_0900_as_cs | utf8mb4 | 288 | | Yes | 0 | NO PAD |
| utf8mb4_turkish_ci | utf8mb4 | 233 | | Yes | 8 | PAD SPACE |
| utf8mb4_unicode_520_ci | utf8mb4 | 246 | | Yes | 8 | PAD SPACE |
| utf8mb4_unicode_ci | utf8mb4 | 224 | | Yes | 8 | PAD SPACE |
| utf8mb4_vietnamese_ci | utf8mb4 | 247 | | Yes | 8 | PAD SPACE |
| utf8mb4_vi_0900_ai_ci | utf8mb4 | 277 | | Yes | 0 | NO PAD |
| utf8mb4_vi_0900_as_cs | utf8mb4 | 300 | | Yes | 0 | NO PAD |
| utf8mb4_zh_0900_as_cs | utf8mb4 | 308 | | Yes | 0 | NO PAD |
+----------------------------+---------+-----+---------+----------+---------+---------------+
排序规则具有以下特征:
- 两个不同的字符集不能有相同的排序规则。
- 每个字符集都有一个默认的排序规则。
- 排序规则的名称通常是其排序字符集名称后跟几个表示排序特点的字母构成的。
当一个字符集有多个排序规则时,可能不清楚哪个排序规则最适合给定的应用程序。为避免选择不适当的排序,请对具有代表性的数据值执行一些比较,以确保给定的排序按您期望的方式对值进行排序。
指定字符集和排序规则
有四个级别的字符集和排序的默认设置:服务器、数据库、表和列。下面几节的描述可能看起来很复杂,但实践发现,多级默认的结果是自然而明显的。
CHARACTER SET用于指定字符集的子句中。CHARSET可以用作CHARACTER SET的同义词。
服务器的字符集和排序规则
MySQL服务器有一个服务器字符集和一个服务器排序。默认情况下,它们是utf8mb4和utf8mb4_0900_ai_ci,但是可以在服务器启动时在命令行或选项文件中显式设置它们,并在运行时更改。
最初,服务器字符集和排序规则取决于启动mysqld时使用的选项。可以对字符集使用--character-set-server。除此之外,您还可以为排序添加--collation-server选项。如果不指定字符集,就相当于说--character-set-server=utf8mb4。如果只指定字符集而不指定排序规则,这就相当于说--character-set-server=utf8mb4--collation-server=utf8mb4_0900_ai_ci,因为utf8mb4_0900_ai_ci是utf8mb4`的默认排序规则。因此,以下三个命令的效果相同:
mysqld
mysqld --character-set-server=utf8mb4
mysqld --character-set-server=utf8mb4 \
--collation-server=utf8mb4_0900_ai_ci
如果未在CREATE DATABASE语句中指定数据库字符集和排序规则,则使用服务器字符集和排序规则作为默认值。
当前服务器的字符集和排序可以从character_set_server和collation_server系统变量的值确定。这些变量可以在运行时更改。
数据库的字符集和排序规则
每个数据库都有数据库字符集和数据库排序。CREATE DATABASE和ALTER DATABASE语句有可选的子句来指定数据库字符集和排序规则。
CREATE DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name]
ALTER DATABASE db_name
[[DEFAULT] CHARACTER SET charset_name]
[[DEFAULT] COLLATE collation_name]
CHARACTER SET和COLLATE子句使得在同一个MySQL服务器上创建具有不同字符集和排序规则的数据库成为可能。
MySQL选择数据库字符集和数据库排序方式如下:
- 如果同时指定了
CHARACTER SET charset_name和COLLATE collation_name,则使用字符集charset_name和排序规则collation_name。 - 如果指定
CHARACTER SET charset_name而不指定COLLATE,则使用字符集charset_name及其默认排序规则。要查看每个字符集的默认排序规则。 - 如果指定
COLLATE collation_name而不指定CHARACTER SET,则使用与collation_name和排序规则collation_name关联的字符集。 - 否则,将使用服务器字符集和服务器排序规则。
默认数据库的字符集和排序规则可以从character_set_database和collation_database系统变量的值确定。每当默认数据库更改时,服务器就设置这些变量。如果没有默认数据库,则变量与相应的服务器级系统变量character_set_server和collation_server具有相同的值。
要查看给定数据库的默认字符集和排序规则,请使用以下语句:
USE db_name;
SELECT @@character_set_database, @@collation_database;
数据库字符集和排序影响服务器运行的这些方面:
- 对于
CREATE TABLE语句,如果未指定表字符集和排序规则,则使用数据库字符集和排序规则作为表定义的默认值。要覆盖这一点,请提供显式的CHARACTER SET和COLLATE表选项。 - 对于不包含
CHARACTER SET子句的LOAD DATA语句,服务器使用character_set_database系统变量指示的字符集来解释文件中的信息。要覆盖这个,提供一个显式的字符集子句。
表的字符集和排序规则
每个表都有一个表字符集和一个表排序。CREATE TABLE和ALTER TABLE语句有可选的子句来指定表的字符集和排序规则:
CREATE TABLE tbl_name (column_list)
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name]]
ALTER TABLE tbl_name
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name]
MySQL选择表的字符集和排序方式如下:
- 如果同时指定了
CHARACTER SET charset_name和COLLATE collation_name,则使用字符集charset_name和排序规则collation_name。 - 如果指定
CHARACTER SET charset_name而不指定COLLATE,则使用字符集charset_name及其默认排序规则。要查看每个字符集的默认排序规则。 - 如果指定
COLLATE collation_name而不指定CHARACTER SET,则使用与collation_name和排序规则collation_name关联的字符集。 - 否则,将使用数据库字符集和排序规则。
列的字符集和排序规则
每个字符列(即CHAR、VARCHAR、TEXT类型或任何同义词类型的列)都有一个列字符集和一个列排序规则。CREATE TABLE和ALTER TABLE的列定义语法有用于指定列字符集和排序规则的可选子句:
col_name {
CHAR | VARCHAR | TEXT} (col_length)
[CHARACTER SET charset_name]
[COLLATE collation_name]
这些子句也可以用于ENUM和SET列:
col_name {
ENUM | SET} (val_list)
[CHARACTER SET charset_name]
[COLLATE collation_name]
MySQL选择列字符集和排序方式如下:
- 如果同时指定了
CHARACTER SET charset_name和COLLATE collation_name,则使用字符集charset_name和排序规则collation_name。 - 如果指定
CHARACTER SET charset_name而不指定COLLATE,则使用字符集charset_name及其默认排序规则。 - 如果指定
COLLATE collation_name而不指定CHARACTER SET,则使用与collation_name和排序规则collation_name关联的字符集。 - 否则,将使用表字符集和排序规则。
如果使用ALTER TABLE将一列从一个字符集转换为另一个字符集,MySQL会尝试映射数据值,但如果字符集不兼容,可能会导致数据丢失。
字符串字面量的字符集和排序规则
每个字符串字面值都有一个字符集和一个排序规则。对于简单语句SELECT 'string',字符串具有由character_set_connection和collation_connection系统变量定义的连接默认字符集和排序规则。
字符串字面值可以有一个可选的字符集引入器和COLLATE子句,将其指定为使用特定字符集和排序规则的字符串:
[_charset_name]'string' [COLLATE collation_name]
_charset_name表达式称为引入器。它告诉解析器,“后面的字符串使用字符集charset_name。”引入器不会像CONVERT()那样将字符串更改为引入器字符集。它不会改变字符串值,尽管可能会出现填充。
MySQL以以下方式确定字符串字面值的字符集和排序:
- 如果同时指定了
_charset_name和COLLATE collation_name,则使用字符集charset_name和排序规则collation_name。collation_name必须是charset_name允许的排序规则。 - 如果指定了
_charset_name但未指定COLLATE,则使用字符集charset_name及其默认排序规则。要查看每个字符集的默认排序规则。 - 如果未指定
_charset_name,但指定了COLLATE collation_name,则使用character_set_connection系统变量和collation_name给出的连接默认字符集。collation_name必须是连接默认字符集允许的排序规则。 - 否则,将使用
character_set_connection和collation_connection系统变量给出的连接默认字符集和排序规则。
引入器指示字符串的字符集,但不改变解析器在字符串中执行转义处理的方式。解析器总是根据character_set_connection给出的字符集解释转义。
下面的示例显示,即使在存在引入器的情况下,也会使用character_set_connection进行转义处理。
mysql> SET NAMES latin1;
mysql> SELECT HEX('à\n'), HEX(_sjis'à\n');
+------------+-----------------+
| HEX('à\n') | HEX(_sjis'à\n') |
+------------+-----------------+
| E00A | E00A |
+------------+-----------------+