强化学习算法如Q学习的确有一些局限性,比如状态和动作空间过大或过复杂的问题。针对这些问题,有一些解决方案,比如:
使用函数逼近来近似Q函数,而不是用表格存储。函数逼近可以是线性的,也可以是非线性的,比如神经网络。这样可以减少存储空间,也可以处理连续的状态和动作空间。
使用分层强化学习来将复杂的任务分解为子任务,每个子任务有自己的状态和动作空间,以及奖励函数。这样可以降低问题的复杂度,也可以提高学习效率。
使用深度强化学习来结合深度学习和强化学习,利用深度神经网络来表示策略或值函数,从高维的原始输入(比如图像)中提取特征,学习复杂的环境和任务。深度强化学习已经在许多领域取得了令人瞩目的成果,比如AlphaGo,Atari游戏,机器人控制等。


五、深度强化学习

5.1 深度 Q 网络
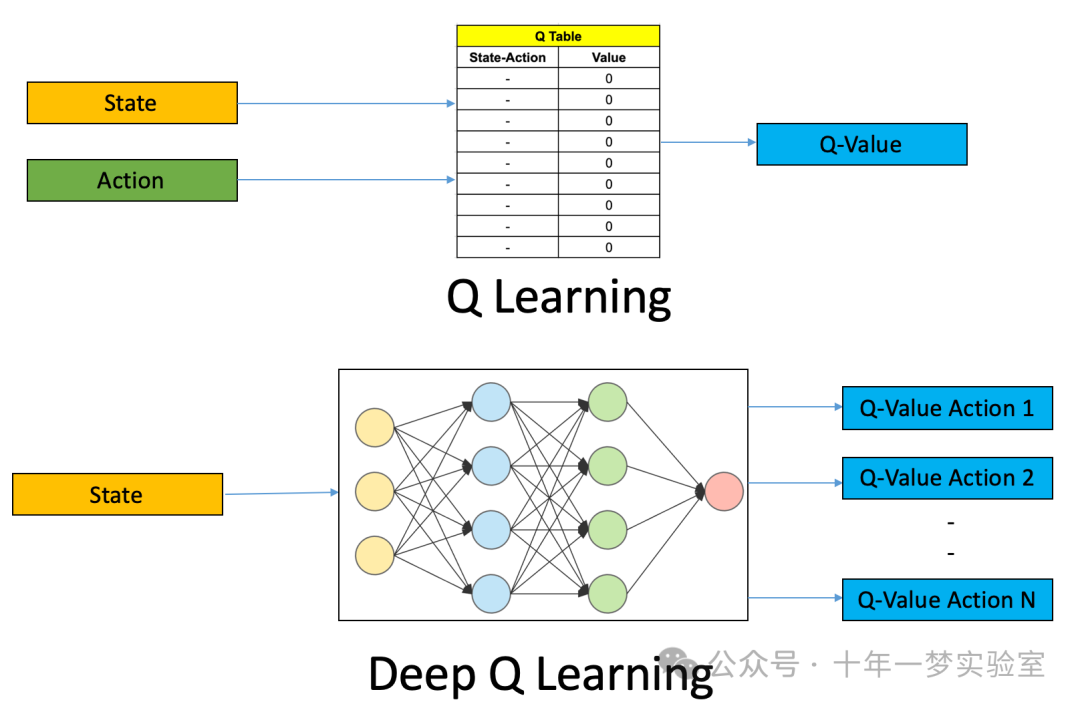

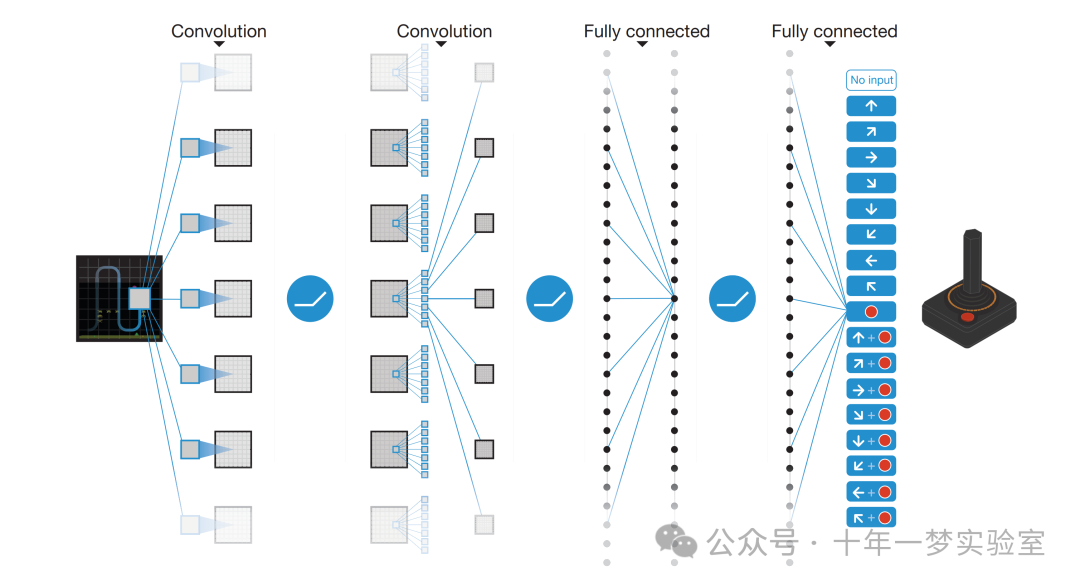
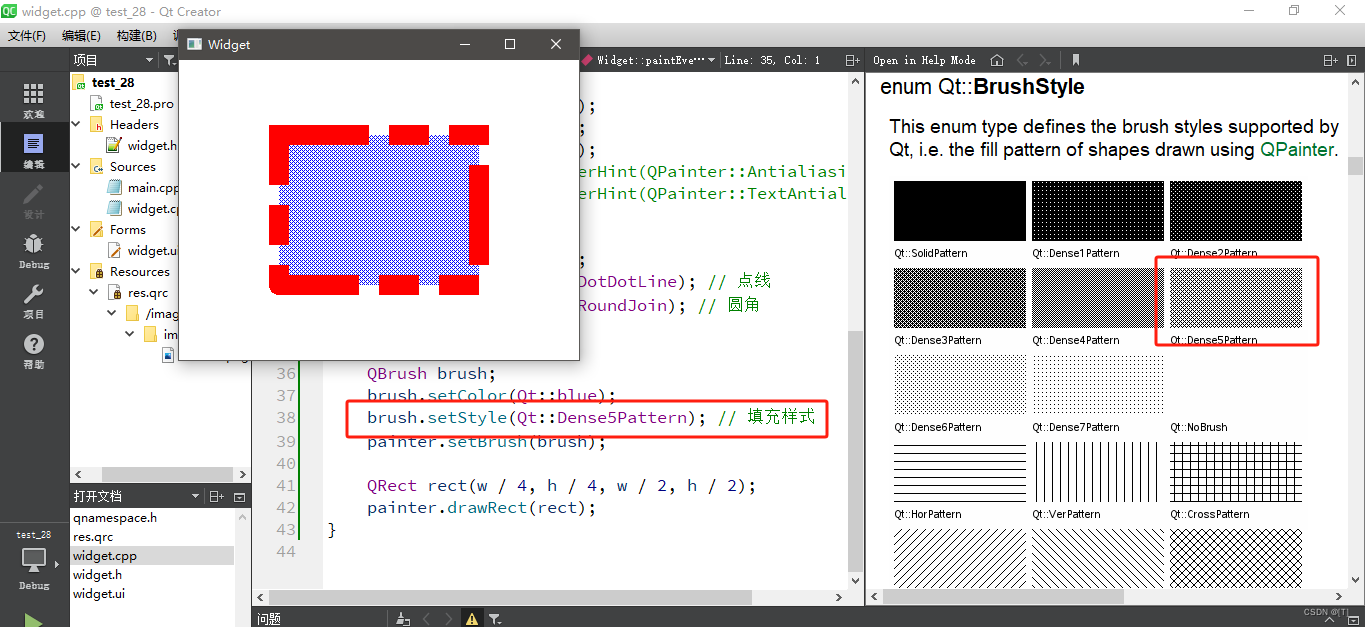
图:深度 Q 学习中,使用神经网络来逼近 Q 值函数
(2个卷积层,2个全连接层)
DQN的网络结构
深度 Q 网络的网络结构是指用于近似 Q 函数的深度神经网络的结构。深度 Q 网络的网络结构可以根据不同的输入和输出的类型和维度来设计,但是一般都包括以下几个部分:
输入层:输入层是用于接收环境的状态信息的,它可以是一个向量,一个矩阵,或者一个张量。例如,如果输入是图像,那么输入层可以是一个三维的张量,表示图像的高度,宽度和通道数。
隐藏层:隐藏层是用于提取状态信息的特征的,它可以有多个,每个隐藏层都由若干个神经元组成。每个神经元都有一个激活函数,用于增加网络的非线性。隐藏层可以是全连接层,卷积层,循环层,或者其他类型的层。例如,如果输入是图像,那么隐藏层可以是若干个卷积层,用于提取图像的局部特征。
输出层:输出层是用于输出每个动作的 Q 值的,它的神经元的个数等于动作空间的大小。输出层一般是一个全连接层,没有激活函数。输出层的每个神经元都对应一个动作,其输出的值就是该动作的 Q 值。例如,如果动作空间是离散的,有四个动作,那么输出层就有四个神经元,分别表示上,下,左,右的 Q 值。

DQN概述1

DQN概述2


算法: 具有经验回放的深度 Q 学习



DQN的改进算法

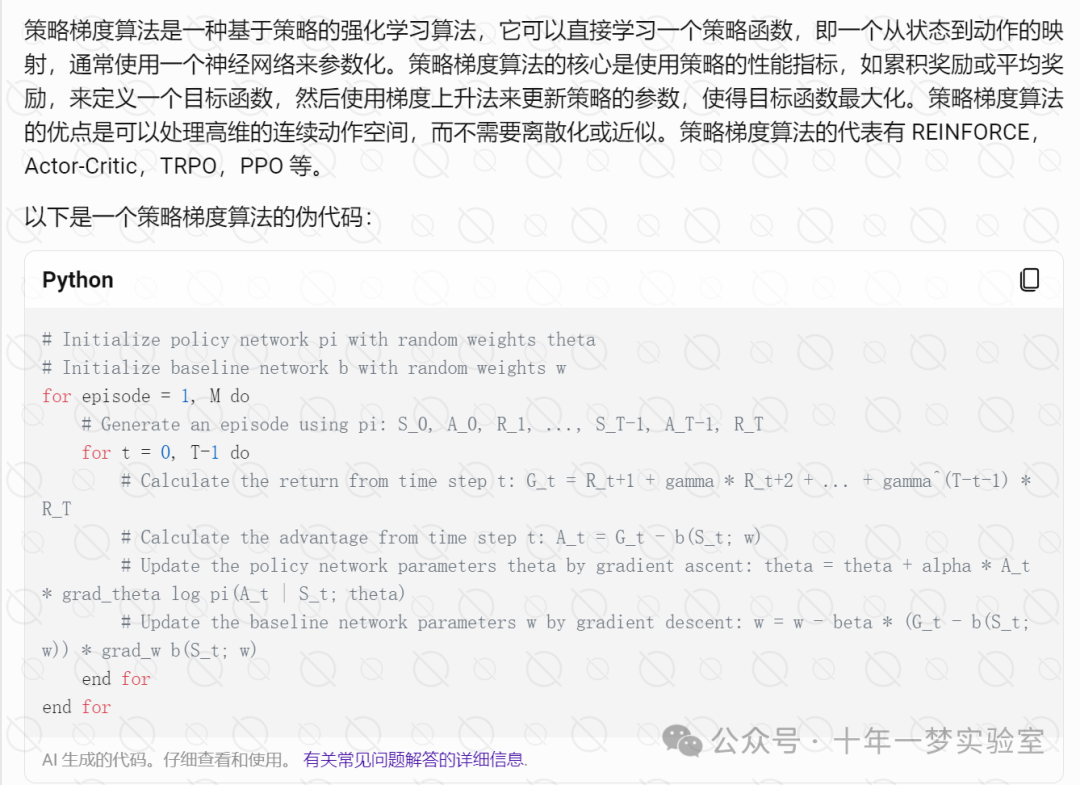
5.2 策略梯度算法

策略梯度算法处理离散动作和连续动作的区别


策略梯度算法与深度Q网络算法的区别


目标函数的构造方法



目标函数对策略参数的梯度形式



策略梯度定理的证明

REINFORCE 算法流程

对于连续动作空间强化学习路径规划问题,有哪些求解方法



参考网址:
- [DQN论文](https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf)
- [DQN 的改进算法的综述](https://arxiv.org/abs/1710.02298)
- [DQN 的改进算法的论文解读](https://zhuanlan.zhihu.com/p/32817711)
- [DQN 的改进算法的代码实现](https://github.com/higgsfield/RL-Adventure-2)




























![P4769 [NOI2018] 冒泡排序 洛谷黑题题解附源码](https://img-blog.csdnimg.cn/img_convert/323dd164e2dd3ad46800446b78d7ada2.png)