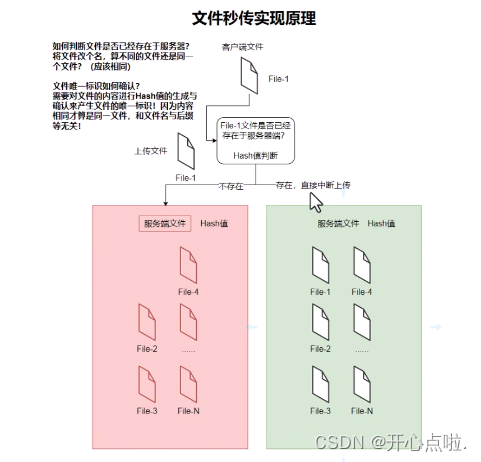
1.给定能随机生成整数1~5的函数rand5(),写出能随机生成整数1~7的函数rand7()
解:通过rand5()*5+rand5()产生6、7、8、9、…、26、27、28、29、30这25个整数,每个整数x出现的概率相等,取前面3*7=21个整数,舍弃后面的4个整数,将{6,7,8}转化成1,将{9,10,11}转化成2,依此类推,即有
![]()
为最终结果。以下为c++代码:
#include<iostream>
#include<stdlib.h>
#include<time.h>
using namespace std;
int rand5()
{
int a=1,b=5;
return rand()%(b-a+1)+a;
}
int rand7()
{
int x;
do
{
x=rand5()*5 + rand5();
}
while(x>26);
int y = (x - 3) / 3;
return y;
}
int main()
{
srand((unsigned)time(NULL));
for(int i=1;i<20;i++)
cout<<rand7()<<" ";
cout<<"\n";
}
2.给定一个含n个整数的a,编写一个实验程序随机打乱数组a的程序。
解:首先从所有元素中选取一个元素与a[0]交换,然后在a[1……n-1]中选择一个元素与a[1]交换,依此类推,对应程序如下:
#include<iostream>
#include<stdlib.h>
#include<time.h>
using namespace std;
void swap(int &x,int &y) //交换
{
int tmp;
tmp=x;x=y;y=tmp;
}
void random(int a[],int n)
{
for(int i=0;i<n;i++)
{
int j=rand()%(n-i)+i;
if(j!=i)swap( a[i],a[j]);
}
}
int main()
{
int n=5;
int a[n]={1,2,3,4,5};
srand((unsigned)time(NULL)); //随机种子
for(int num=1;num<=10;num++) //产生10个随机序列
{
random(a,5);
cout<<"随机序列"<<num<<":";
for(int i=0;i<n;i++)
cout<<a[i]<<" ";
cout<<"\n";
}
}
3.用分治法设计的合并排序算法描述,其中A[low:high]存放的待排序序列,部分代码如下:
void MergeSort (int A[],int low,int high)
{ int middle;
if (low<high)
{
middle=(low+high)/2;
MergeSort(A,low,middle);
MergeSort(A,middle+1,high);
Merge(A,low,middle,high);
}
}
4.有一个三位数,个位数字比百位数字大,百位数字又比十位数字大,并且各位数字之和等于各位数字相乘之积,设计一个算法用蛮力法求此三位数。
#include<iostream>
#include<stdlib.h>
#include<time.h>
using namespace std;
void solve()
{
int a,b,c;
for(a=1;a<=9;a++)
for(b=0;b<=9;b++)
for(c=0;c<=9;c++)
{
if(c>a&&a>b&&a+b+c==a*b*c)
cout<<a<<b<<c<<endl;
}
}
int main()
{
cout<<"求解结果是:"<<solve()<<endl;
solve();
}
5.埃拉托色尼筛法简称埃氏筛法,基本思想是,假定区间[1, n]内的所有数都是素数,再去掉所有合数,剩下的就是所有素数。判断合数的方法是从 2 开始依次过筛,如果是 2 的倍数则该数不是素数,进行标记处理,直至将 n/2 过筛,将所有合数打上标记。
解:设函数EratoSieve实现埃拉托色尼筛法,程序如下:
#include<iostream>
#include<stdlib.h>
#include<time.h>
using namespace std;
void EratoSieve(int A[ ], int n)
{
int i, j;
for (i = 2; i <= n/2; i++)
{
if (A[i] != 0) continue;
else
{
for (j = 2; i * j <= n; j++)
A[i*j] = 1;
}
}
}
6.(单选题)分支限界法在问题的解空间树中按( )策略从根节点出发搜索解空间树。
- A. 广度优先
- B. 活结点优先
- C. 扩展节点优先
- D. 深度优先
答案: A:广度优先
7.常见的两种分支限界法为( )。
- A. 广度优先分支限界法与深度优先分支限界法
- B. 队列式(FIFO)分支限界法与堆栈式分支限界法
- C. 排列树法与子集树法
- D. 队列式(FIFO)分支限界法与优先队列式分支限界法
答案: D:队列式(FIFO)分支限界法与优先队列式分支限界法;
8.优先队列式分支限界法选取扩展节点的原则是( )。
- A. 先进先出
- B. 后进先出
- C. 节点的优先级
- D. 随机
答案: C:节点的优先级
9.在用分支限界法求解0/1背包问题时活结点表的组织形式是( )。
- A. 小根堆
- B. 大根堆
- C. 栈
- D. 数组
答案: B:大根堆;
10.蒙特卡罗算法是( )的一种。
- A. 分支限界算法
- B. 贪心算法
- C. 概率算法
- D. 回溯算法
答案: C
11.目前可以采用( )在多项式级时间内求出旅行商问题的一个近似最优解。
- A. 回溯法
- B. 蛮力法
- C. 近似算法
- D. 都不可能
答案: C:近似算法;
12.下列叙述错误的是( )。
- A. 数值概率算法一般是求数值计算问题的近似解
- B. Monte Carlo算法总能求得问题的一个解,但该解未必正确
- C. Las Vegas算法一定能求出问题的正确解
- D. Sherwood算法的主要作用是减少或消除好的和坏的实例之间的差别
答案: C
13.下列叙述错误的是( )。
- A. 概率算法的期望执行时间是指反复解同一个输入实例所花的平均执行时间
- B. 概率算法的平均期望时间是指所有输入实例上的平均期望执行时间
- C. 概率算法的最坏期望时间是指最坏输入实例上的期望执行时间
- D. 概率算法的期望执行时间是指所有输入实例上所花的平均执行时间
答案: D
14.有这样一个数学问题,x 和y 是两个正实数,求x+y=3的所有解,请问____(1)____(相应空填写“能”或“否”)采用回溯法求解,如果改为x 和y 是两个均小于或等于10的正整数,又____(2)____(相应空填写“能”或“否”)采用回溯法求解。
答案:(1) 否(2) 能
15.对于n 皇后问题,请回答在n=3时是否有解____________(填写“是”或者“否”)。
答案:(1) 否
16.对于n 皇后问题,有人认为当n 为偶数时其解具有对称性,即n 皇后问题的解个数恰好为n/2皇后问题的解个数的两倍,这个结论正确吗?
- A. 对
- B. 错
答案: 错
17.回溯法是在问题的解空间中按__________策略从根结点出发搜索的。
- A. 广度优先
- B. 活结点优先
- C. 扩展节点优先
- D. 深度优先
答案: D:深度优先
18. 下列算法中________通常以深度优先方式搜索问题的解。
- A. 回溯法
- B. 动态规划
- C. 贪心法
- D. 分支限界法
答案: A:回溯法;
19. 关于回溯法以下叙述中不正确的是__________。
- A. 回溯法有通用解题法之称,可以系统地搜索一个问题的所有解或任意解
- B. 回溯法是一种既带系统性又带跳跃性的搜索算法
- C. 回溯法算法需要借助队列来保存从根结点到当前扩展结点的路径
- D. 回溯法算法在生成解空间的任一结点时,先判断该结点是否可能包含问题的解,如果肯定不包含,则跳过对以该结点为根的子树的搜索,逐层向祖先结点回溯
答案: C:回溯法算法需要借助队列来保存从根结点到当前扩展结点的路径;
20. 回溯法的效率不依赖于下列因素____________。
- A. 确定解空间的时间
- B. 满足显式约束的值的个数
- C. 计算约束函数的时间
- D. 计算限界函数的时间
答案: A:确定解空间的时间;
21. 下面___________是回溯法中为避免无效搜索采取的策略。
- A. 递归函数
- B. 剪枝函数
- C. 随机数函数
- D. 搜索函数
答案: B:剪枝函数;
22. 对于含n 个元素的子集树问题(每个元素二选一),最坏情况下解空间树的叶子结点个数是__________。
- A. n!
- B.
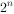
- C.
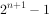
- D.
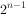
答案: B
23. 用回溯法求解0/1背包问题时的解空间是___________。
- A. 子集树
- B. 排列树
- C. 深度优先生成树
- D. 广度优先生成树
答案: A:子集树;
24. 用回溯法求解TSP问题时的解空间是____________。
- A. 子集树
- B. 排列树
- C. 深度优先生成树
- D. 广度优先生成树
答案: B:排列树;
25. 用回溯法求解0/1背包问题时最坏时间复杂度是_______。
- A. O(n)
- B. O(
)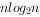
- C. O(
)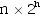
- D. O(
)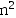
答案: C
26. 求中国象棋中马从一个位置到另外一个位置的所有走法,采用回溯法求解时对应的解空间是__________。
- A. 子集树
- B. 排列树
- C. 深度优先生成树
- D. 广度优先生成树
答案: A
27.一棵哈夫曼数共有215个节点,对其进行哈夫曼编码共能得到( )个不同的码字。
- A. 107
- B. 108
- C. 214
- D. 215
答案: B:108;
28.备忘录法是( )的变形。
- A. 分治法
- B. 回溯法
- C. 贪心法
- D. 动态规划法
答案: D:动态规划法;
29.下列( )是动态规划算法的基本要素之一。
- A. 定义最优解
- B. 构造最优解
- C. 算出最优解
- D. 子问题重叠性质
答案: D:子问题重叠性质;
30.一个问题可用动态规划法或贪心法求解的关键特征是问题的( )。
- A. 贪心选择性质
- B. 重叠子问题
- C. 最优子结构性质
- D. 定义最优解
答案: C:最优子结构性质;
31.0-1背包问题:n=6,W=10,v(1:6)=(15,59,21,30,60,5),w(1:6)=(1,5,2,3,6,1)。该问题的最大价值为( )。
- A. 101
- B. 110
- C. 115
- D. 120
答案: B:110;
32.求解哈夫曼编码中如何体现贪心思路?
答案:
在构造哈夫曼树时每次都是将两棵根节点最小的树合并,从而体现贪心的思路。
33.对于下列二分查找算法,正确的是( )。
- A.
int BinarySearch(int a[], int n, int x)
{
int low = 0, high = n - 1;
while (low <= high)
{
int mid = (low + high) / 2;
if (x == a[mid]) return mid;
if (x > a[mid]) low = mid;
else
high = mid;
}
return -1;
}
- B.
int BinarySearch(int a[], int n, int x)
{
int low = 0, high = n - 1;
while (low+1 != high)
{
int mid = (low + high) / 2;
if (x >= a[mid]) low = mid;
else high = mid;
}
if (x == a[low]) return low;
else
return -1;
}
- C.
int BinarySearch(int a[], int n, int x)
{
int low = 0, high = n - 1;
while (low < high-1)
{
int mid = (low + high) / 2;
if (x < a[mid]) high = mid;
else low = mid;
}
if (x == a[low]) return low;
else
return -1;
}
- D.
int BinarySearch(int a[], int n, int x)
{
if(n>0&&x>=a[0])
{
int low = 0, high = n - 1;
while (low < high)
{
int mid = (low + high+1) / 2;
if (x < a[mid]) high = mid-1;
else low = mid;
}
if (x == a[low]) return low;
}
return -1;
}
答案: D:int BinarySearch(int a[], int n, int x) { if(n>0&&x>=a[0]) { int low = 0, high = n - 1; while (low < high) { int mid = (low + high+1) / 2; if (x < a[mid]) high = mid-1; else low = mid; } if (x == a[low]) return low; } return -1; };
34. 在寻找n个元素中第k小的元素的问题中,如采用快速排序算法思想,运用分治法对n个元素进行划分,如何选择划分基准?下面( )答案最合理。
- A. 随机选择一个元素作为划分基准
- B. 取子序列的第一个元素作为划分基准
- C. 用中位数的中位数方法寻找划分基准
- D. 以上皆可行,但不同方法的算法复杂度上界可能不同
答案: D:以上皆可行,但不同方法的算法复杂度上界可能不同;
35.分治法所能解决的问题应具有的关键特征是( )。
- A. 该问题的规模缩小到一定的程度就可以容易地解决
- B. 该问题可以分解为若干个规模较小的相同问题
- C. 利用该问题分解出的子问题的解可以合并为该问题的解
- D. 该问题所分解出的各个子问题是相互独立的
答案: C:利用该问题分解出的子问题的解可以合并为该问题的解;
36.下面( )是贪心算法的基本要素之一。
- A. 重叠子问题
- B. 构造最优解
- C. 贪心选择性质
- D. 定义最优解
答案: C:贪心选择性质;
37.关于0/1背包问题,以下描述正确的是( )。
- A. 可以使用贪心算法找到最优解
- B. 能找到多项式时间的有效算法
- C. 使用教材介绍的动态规划方法可求解任意0/1背包问题
- D. 对于同一背包和相同的物品,做背包问题取得的总价值一定大于等于做0/1背包问题
答案: D:对于同一背包和相同的物品,做背包问题取得的总价值一定大于等于做0/1背包问题;
38.用贪心法解决背包问题时所用的贪心策略是( )
- A. 重量小的物品优先装入背包
- B. 价值大的物品优先装入背包
- C. 单位重量的价值大的物品优先装入背包
- D. 单位重量的价值小的物品优先装入背包
答案: C:单位重量的价值大的物品优先装入背包;
39.用贪心策略设计算法的关键是( )。
- A. 将问题分解为多个子问题来分别处理
- B. 选好贪心策略
- C. 获取各阶段间的递推关系式
- D. 满足最优性原理
答案: B:选好贪心策略;
40.以下哪些算法采用分治策略:
(1)选择排序算法;
(2)二路归并排序算法;
(3)折半查找算法;
(4)顺序查找算法。
答案:(2)二路归并排序算法(3)折半查找算法
41.随机快速排序算法中,选取基准元素的方法是( );
- A. 选择序列的第一个元素作为基准元素;
- B. 选择序列的最后一个元素作为基准元素;
- C. 选择序列的中间位置的元素作为基准元素;
- D. 随机选择序列中的一个元素作为基准元素;
答案: D:随机选择序列中的一个元素作为基准元素;;
42.归并排序法是( )算法策略的应用。
- A. 枚举算法
- B. 贪婪算法
- C. 分治算法
- D. 动态规划
答案: C:分治算法;
43. 蛮力搜索子集树,算法的复杂度为( )。
- A. O(n2)
- B. O(2n)
- C. O(n!)
- D. O(nlogn)
答案: B:O(2n) ;
44.分治法中,将规模大的问题分解为多个规模较小的子问题,子问题必须满足的条件是( )。
- A. 一般不相互独立
- B. 相互独立
- C. 与原问题不相同
- D. 以上都不对
答案: B:相互独立;
45.采用蛮力法求解时在什么情况下使用递归?
答:如果用蛮力法求解的问题可以分解为若干个规模较小的相似子问题,此时可以采用递归来实现算法。
46.算法复杂性是指算法在计算机上运行时所消耗的计算机资源的量。最重要的计算机资源是______资源和_______资源。
答案:
(1) 时间;时间复杂性
(2) 空间;空间复杂性
47. 在使用递推法进行问题求解时,关键是要找到____________。
答案:(1) 递推关系式
48. 算法分析中,记号O表示( ),记号Ω表示( )。
- A. 渐进上界、渐进下界
- B. 非紧上界、紧渐进界
- C. 渐进下界、渐进上界
- D. 紧渐进界、非紧上界
答案: A:渐进上界、渐进下界;
49. 直接或间接调用自身的算法称为( )。
- A. 模拟算法
- B. 递归算法
- C. 迭代算法
- D. 回溯法
答案: B:递归算法;
50.Fibonacci数列中,第4个和第11个数分别是( )。
- A. 5,89
- B. 3,89
- C. 5,144
- D. 3,144
答案: B:3,89;
51. 下面程序段的所需要的计算时间为( )。
int MaxSum(int n, int *a, int &besti, int &bestj)
{
int sum=0;
for(int i=1;i<=n;i++){
int thissum=0;
for(int j=i;j<=n;j++){
thissum+=a[j];
if(thissum>sum) {
sum=thissum;
besti=i;
bestj=j;
}
}
}
return sum;
- A. O(n)
- B. O(nlogn)
- C. O(
) - D. O(
)
答案: C:
52.简述模拟法的设计思想。
答案:
用模拟法求解问题的基本思想是对问题进行抽象
(1)将现实世界的问题映射成计算机能够识别的符号表示
(2)将事物之间的关系映射成运算或逻辑控制




















![二叉树的最大深度[简单]](https://img-blog.csdnimg.cn/direct/5703486b9f0e4fa6ab24d078e83f1dde.jpeg)