Pandas 是一个强大的 Python 数据分析库,它提供了快速、灵活、直观的数据结构,旨在使“关系”或“标签”数据的操作既简单又直观。其中,Series 是 Pandas 的一个基本数据结构,可以看作是一个一维的标签化数组,能够保存任何数据类型(整数、字符串、浮点数、Python 对象等)。Series 提供了轴标签(即索引),使得它能够实现自动或显式的数据对齐,这是其强大功能之一。
架构
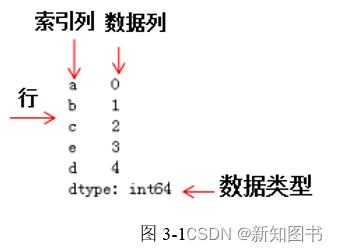
Series 对象由两部分组成:
- 数据:存储数据的 NumPy ndarray,可以是任意类型。
- 索引:数据对应的标签,每一个数据点都可以通过索引进行访问。
Series的索引是具有唯一性的,这意味着它可以用来快速定位数据。如果未指定索引,Pandas 会自动创建一个从 0 到 N-1(N 为数据长度)的整数索引。
基本语法
创建一个 Series 对象的基本语法如下:
import pandas as pd
# 通过列表创建 Series
data = [1, 2, 3, 4, 5]
s = pd.Series(data)
# 通过字典创建 Series,键作为索引
data = {
'a': 1, 'b': 2, 'c': 3}
s = pd.Series(data)
内容
下面将通过具体的代码案例来详细讲解 Series 的使用。
创建 Series
import pandas as pd
# 创建一个简单的 Series
s = pd.Series([1, 2, 3, 4, 5])
print(s)
# 输出:
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# dtype: int64
在上面的例子中,我们没有指定索引,所以 Pandas 使用了默认的整数索引。
使用自定义索引
# 使用自定义索引创建 Series
index = ['a', 'b', 'c', 'd', 'e']
s = pd.Series([1, 2, 3, 4, 5], index=index)
print(s)
# 输出:
# a 1
# b 2
# c 3
# d 4
# e 5
# dtype: int64
通过自定义索引,我们可以更方便地通过标签来访问数据。
访问和修改数据
# 通过索引访问数据
print(s['a']) # 输出:1
# 通过位置访问数据
print(s.iloc[0]) # 输出:1
# 修改数据
s['a'] = 100
print(s)
# 输出:
# a 100
# b 2
# c 3
# d 4
# e 5
# dtype: int64
Series 支持多种方式的数据访问和修改,包括标签索引和位置索引。
Series 的算术运算
# 创建另一个 Series
s2 = pd.Series([10, 20, 30, 40, 50], index=index)
# 进行算术运算
print(s + s2)
# 输出:
# a 110
# b 22
# c 33
# d 44
# e 55
# dtype: int64
Series 之间的算术运算会根据索引自动对齐数据。
缺失值处理
# 创建包含缺失值的 Series
s3 = pd.Series([1, 2, None, 4, None])
# 检查缺失值
print(s3.isnull())
# 输出:
# 0 False
# 1 False
# 2 True
# 3 False
# 4 True
# dtype: bool
名称属性
Series 对象可以有名字,索引也有名字。
# 给 Series 和索引设置名称
s.name = 'My Series'
s.index.name = 'Index'
print(s)
# 输出:
# Index
# a 100
# b 2
# c 3
# d 4
# e 5
# Name: My Series, dtype: int64
这些名称在绘图或转换为 DataFrame 时非常有用。
排序
Series 可以根据索引或值进行排序。
# 对 Series 进行排序
sorted_s = s.sort_index()
print(sorted_s)
# 输出:
# Index
# a 100
# b 2
# c 3
# d 4
# e 5
# Name: My Series, dtype: int64
# 按值排序
sorted_s = s.sort_values()
print(sorted_s)
# 输出:
# Index
# b 2
# c 3
# d 4
# e 5
# a 100
# Name: My Series, dtype: int64
描述性统计
Series 提供了许多描述性统计方法。
# 计算描述性统计
print(s.describe())
# 输出:
# count 5.000000
# mean 34.000000
# std 48.619243
# min 2.000000
# 25% 4.000000
# 50% 5.000000
# 75% 100.000000
# max 100.000000
# dtype: float64
应用函数
可以向 Series 应用自定义函数。
# 定义一个函数
def square(x):
return x ** 2
# 应用函数
s_squared =