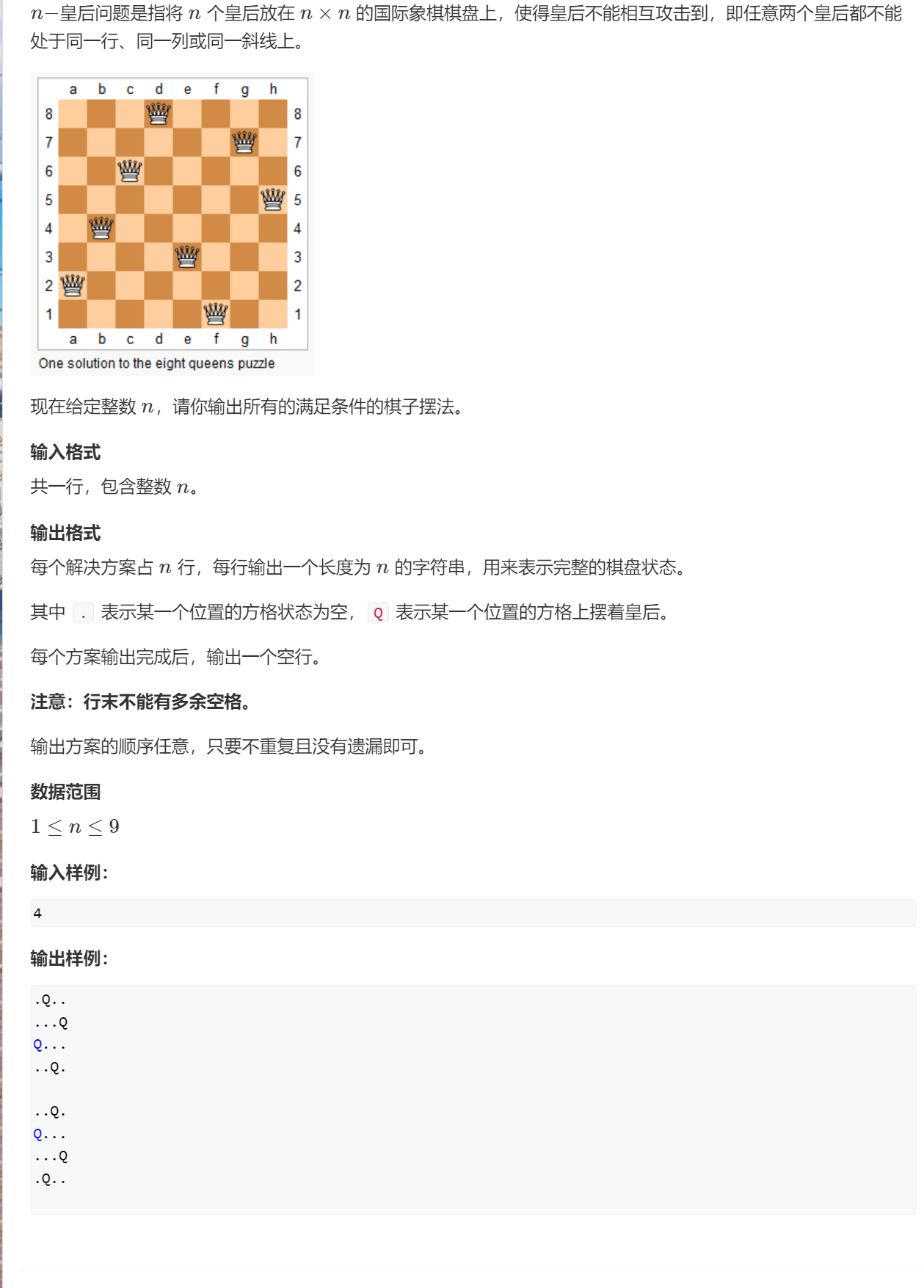
在中文文本处理中,分词是基础且关键的一步。不同于英文的空格分隔,中文文本的分词对于理解整个句子或段落的意义至关重要。jieba是一个非常流行的中文分词工具,为Python开发者提供了强大的分词支持。
一、jieba分词的安装与导入
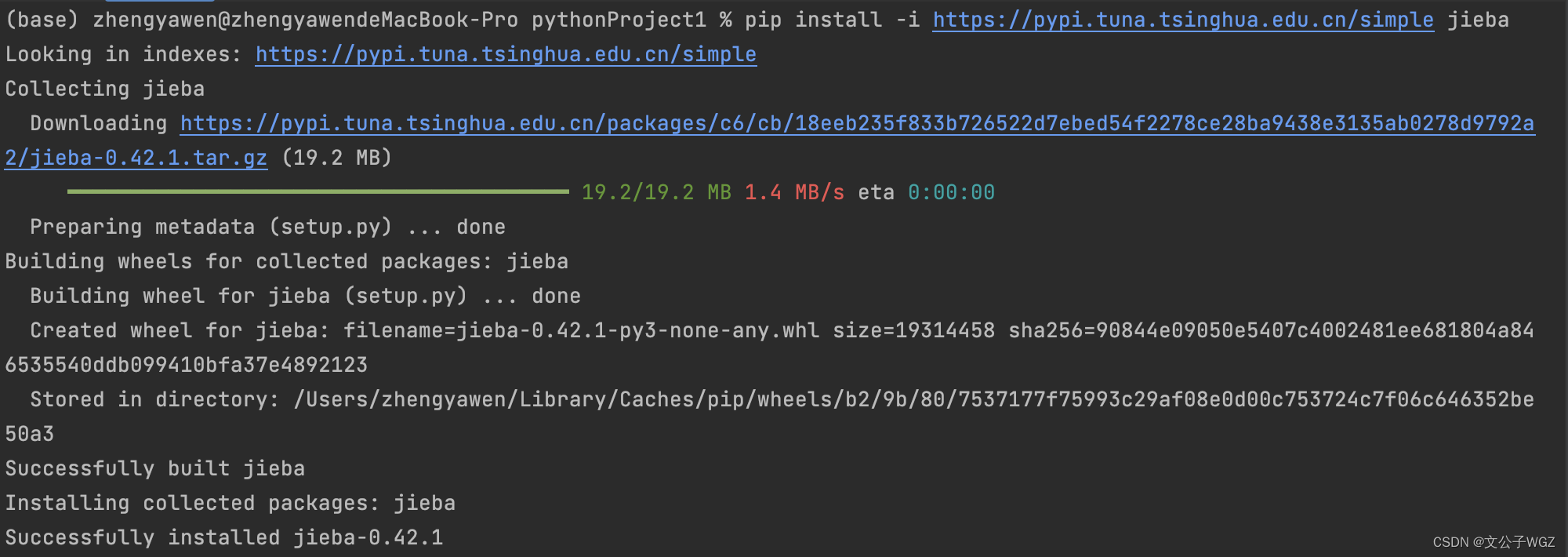
首先,你需要安装jieba库。可以通过pip进行安装:
pip install jieba安装完成后,你可以在Python代码中导入它:
import jieba二、使用jieba进行分词
以下是一个简单的例子,展示如何使用jieba对中文文本进行分词:
import jieba
# 中文文本
text = "我爱北京天安门"
# 使用jieba进行分词
seg_list = jieba.cut(text, cut_all=False)
print(" ".join(seg_list)) # 输出: 我 爱 北京 天安门三、jieba的高级功能
1、自定义词典:jieba支持自定义词典,对于特定的领域或术语,你可以创建一个自定义词典,以提高分词的准确性。例如,创建一个自定义词典文件(custom_dict.txt),内容如下:
北京天安门
清华大学
然后,使用以下代码加载自定义词典:
import jieba.posseg as pseg
import jieba.dict as jdict
jieba.load_userdict('custom_dict.txt') # 加载自定义词典
2、关键词提取:除了基本的分词功能,jieba还提供了关键词提取的功能。这对于从大量文本中快速提取关键信息非常有用。例如:
keywords = pseg.extract_tags("这台机器性能很好", topK=5) # 提取5个关键词:这台、机器、性能、很、好
print(keywords) # 输出: ['这台', '机器', '性能', '很', '好']四、jieba的运用场景
- 搜索引擎:在构建搜索引擎时,对用户查询进行分词是必不可少的步骤。通过jieba,你可以更准确地理解用户的查询意图。
- 文本挖掘和数据分析:在进行文本挖掘和数据分析时,分词是预处理的关键步骤。通过jieba,你可以将原始文本转化为结构化的数据,便于进一步的分析和处理。
- 社交媒体监控和分析:在社交媒体上,大量的文本数据需要被处理和分析。使用jieba,可以快速地处理这些数据,提取关键信息,了解用户的观点和情绪。
- 机器翻译和语音识别:在这些领域中,jieba可以与其他工具结合使用,提高系统的整体性能。例如,机器翻译系统可以先使用jieba进行分词,然后再进行翻译。

























![[BSidesCF 2020]Had a bad day](https://img-blog.csdnimg.cn/img_convert/f7f13479c5340742ba8f0ab493fd2985.png)