目录
前言
A.建议
1.学习算法最重要的是理解算法的每一步,而不是记住算法。
2.建议读者学习算法的时候,自己手动一步一步地运行算法。
tips:文中的对数均以2为底数
B.简介
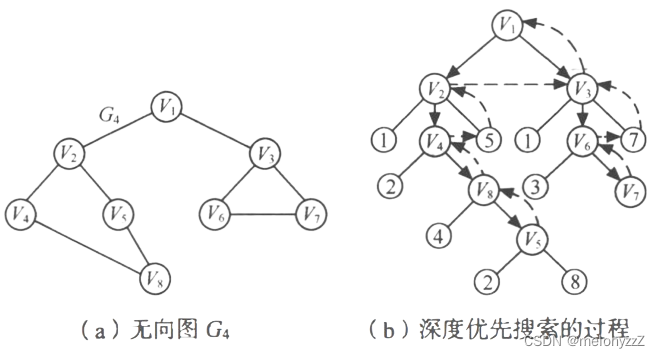
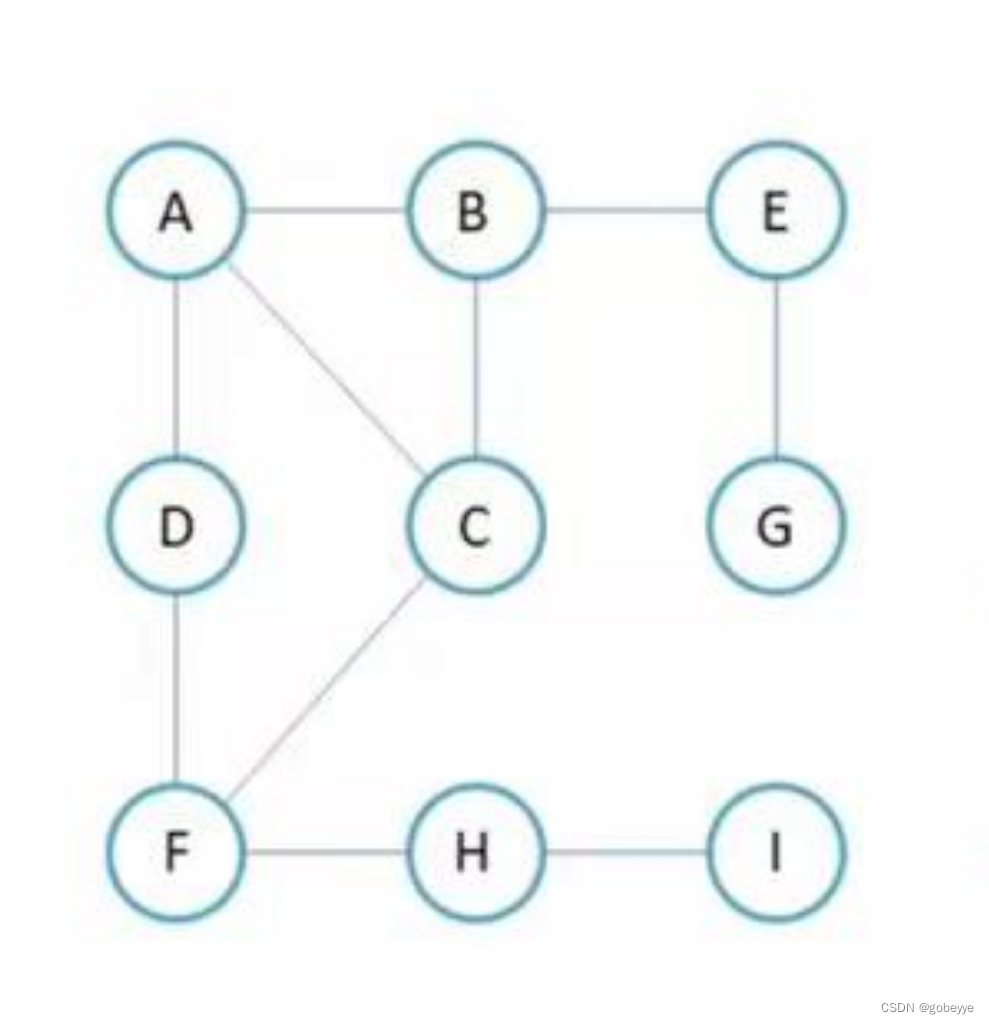
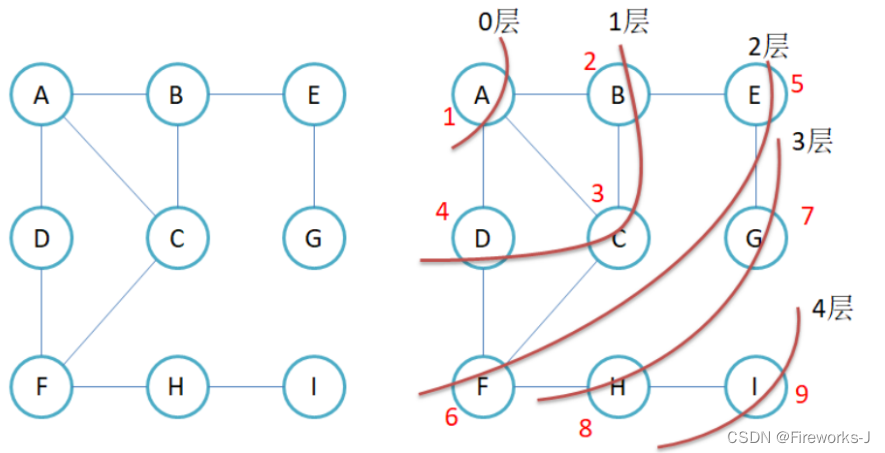
深度优先遍历(DFS)是处理图节点的算法,选择起始节点,标记为已访问并加入遍历路径。通过递归访问邻接节点,深入直到无法继续,然后回溯至上一个节点,重复步骤直到遍历完整个图。
一 代码实现
#include <stdio.h>
#include <stdlib.h>
// 定义图的最大节点数
#define MAX_NODES 100
// 定义图的邻接表节点
struct Node {
int data;
struct Node* next;
};
// 定义图
struct Graph {
int numNodes;
struct Node* adjacencyList[MAX_NODES];
int visited[MAX_NODES];
};
// 初始化图
void initGraph(struct Graph* graph, int numNodes) {
graph->numNodes = numNodes;
for (int i = 0; i < numNodes; ++i) {
graph->adjacencyList[i] = NULL;
graph->visited[i] = 0;
}
}
// 添加边
void addEdge(struct Graph* graph, int src, int dest) {
// 创建邻接表节点
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = dest;
newNode->next = graph->adjacencyList[src];
graph->adjacencyList[src] = newNode;
}
// 深度优先遍历
void DFS(struct Graph* graph, int node) {
// 标记当前节点为已访问
graph->visited[node] = 1;
printf("%d ", node);
// 遍历当前节点的邻接节点
struct Node* current = graph->adjacencyList[node];
while (current != NULL) {
if (!graph->visited[current->data]) {
// 递归调用DFS
DFS(graph, current->data);
}
current = current->next;
}
}
int main() {
// 创建一个图并初始化
struct Graph graph;
initGraph(&graph, 6);
// 添加图的边
addEdge(&graph, 0, 1);
addEdge(&graph, 0, 2);
addEdge(&graph, 1, 3);
addEdge(&graph, 2, 4);
addEdge(&graph, 3, 5);
// 执行深度优先遍历
printf("Depth-First Traversal: ");
DFS(&graph, 0);
return 0;
}
这个例子中,首先通过initGraph函数初始化了一个图,然后通过addEdge函数添加了图的边。最后,通过DFS函数执行深度优先遍历,并输出遍历结果。这只是一个简单的例子,实际应用中可能需要根据具体情况进行调整和扩展。
二 时空复杂度
图的深度优先遍历(DFS)的时间和空间复杂度取决于图的大小、结构和实现方式。
A.时间复杂度:
最好情况时间复杂度:对于DFS,最好情况是图中的节点和边都很少,此时时间复杂度可能接近。
最坏情况时间复杂度:对于DFS,最坏情况是每个节点和边都需要被访问,此时时间复杂度为。
平均情况时间复杂度:平均情况时间复杂度通常较难确定,因为它需要考虑对所有可能输入的平均情况。在一般情况下,对于随机图,平均情况下DFS的时间复杂度仍然为。
B.空间复杂度分析:
邻接表: 如果使用邻接表表示图,空间复杂度为,其中V是节点数,E是边数。这是因为邻接表存储了所有的节点和边关系。
邻接矩阵: 如果使用邻接矩阵表示图,空间复杂度为,其中V是节点数。这是因为邻接矩阵存储了所有可能的边关系。
三 优缺点
A.深度优先遍历算法的优点:
简单易实现: DFS的递归或迭代实现相对简单,易于理解和实现,适合初学者学习图算法。
内存消耗相对较小: 与广度优先遍历相比,DFS使用栈(或递归调用栈)的空间消耗较小,对于内存有限的情况更有优势。
发现连通分量: DFS能够有效地发现图中的连通分量,对于解决一些连通性问题很有用。
适用于路径查找: DFS可以用于查找从一个节点到另一个节点的路径,对于路径查找问题非常有效。
B.深度优先遍历算法的缺点:
非最短路径: DFS找到的路径不一定是最短路径,因为它会继续深入直到达到叶子节点,而不是一旦找到目标就停止。
对环的处理: 在有向图中,如果存在环,DFS可能陷入无限循环。需要使用标记或其他方法来避免。
对于非连通图: 如果图是非连通的,需要对每个连通分量单独进行DFS,增加了处理的复杂性。
依赖递归或栈: 递归调用或使用栈来实现DFS,对于图很大的情况下可能导致栈溢出或递归深度过大的问题。
可能不适用于最优化问题: 在某些最优化问题中,深度优先搜索可能需要遍历大量的状态空间,效率较低。
四 现实中的应用
网络路由和路径规划: 在计算机网络中,深度优先遍历用于查找最短路径或确定网络中的节点连接性。这对于路由算法和路径规划非常重要。
社交网络分析: 在社交网络中,深度优先遍历可用于查找用户之间的关系,发现社交圈子,或者进行推荐系统。
连通性检测: 深度优先遍历可以用于检测图中的连通分量,判断一个图是否是强连通图,或者找到图中的孤立子图。
迷宫和棋盘问题: 在迷宫或棋盘类问题中,深度优先搜索用于寻找路径,解决如何从起点到达目标点的问题。
编译器和解释器: 在编译器和解释器中,深度优先遍历被用于遍历语法树,执行语法分析,或者进行变量的作用域分析。
图像处理: 在图像处理中,深度优先遍历可以用于图像分割、对象提取和区域填充等任务。
数据库查询: 在关系数据库中,深度优先遍历可以用于查询与某个节点相关的数据,如数据库中的树结构或层次关系。
游戏开发: 在游戏开发中,深度优先搜索可用于寻找游戏地图中的路径、解决迷宫问题或实现图的状态转换。



















![[极客大挑战 2019]BabySQL1](https://img-blog.csdnimg.cn/direct/e8a1269f609146108a23009842fedc59.png)