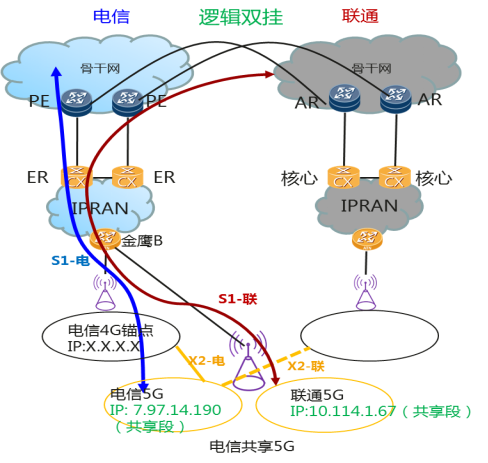
本次我们的目标是抓取全本的《三国演义》原著并按照章节分别保存到本地的爬虫。

一共120回的原著文章分别抓取到本地保存成文件。

代码非常简单,因为你会发现整个网站是一个CSS静态页面,因此抓取分分钟搞定。
代码设定了存储文件的目录(《三国演义》)并检查这个目录是否已存在。如果不存在,它会自动创建这个目录,以便存储下载的章节内容。这一步骤确保了存储数据的位置是预先准备好的。利用 requests 库向指定的 URL(《三国演义》的网页)发送HTTP请求,并获取整个页面的HTML内容。利用 BeautifulSoup 库,代码解析了HTML数据,有效地提取出了每个章节的标题和链接。这一部分是从网页中获取所需数据的关键环节。
代码进入一个循环,遍历网页中提取的每个章节链接。对于每个链接,它再次发送HTTP请求,抓取具体章节的内容。每获取一个章节,代码便暂停3秒,这样做是为了防止请求频率过高导致被服务器封禁。每个章节的文本内容被提取出来后,代码按照章节顺序和标题生成文件名,并将内容写入以该名称命名的文本文件中。这样,每个章节的内容都被整齐地保存在单独的文件里,方便阅读和管理。
import