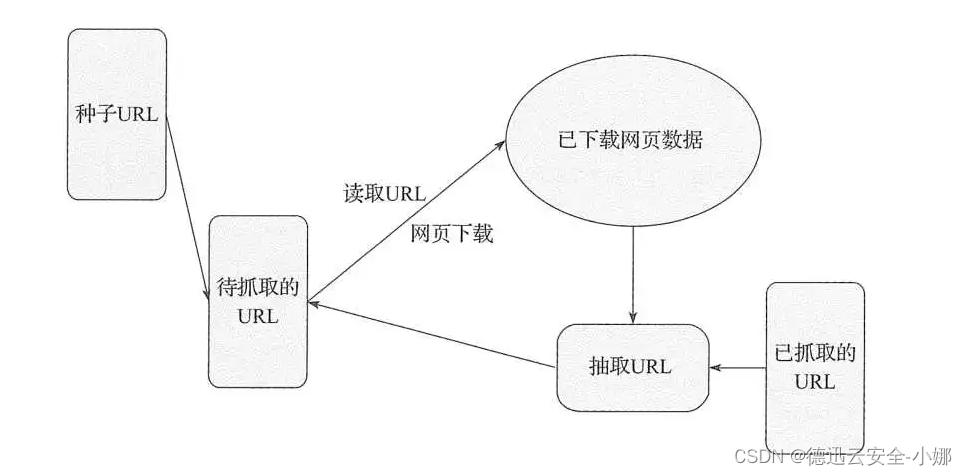
第一:给大家推荐一个爬虫的网课哈,码起来
第二:今夜主题:通过xpath爬取58二手房的title信息,也就是标红的位置~
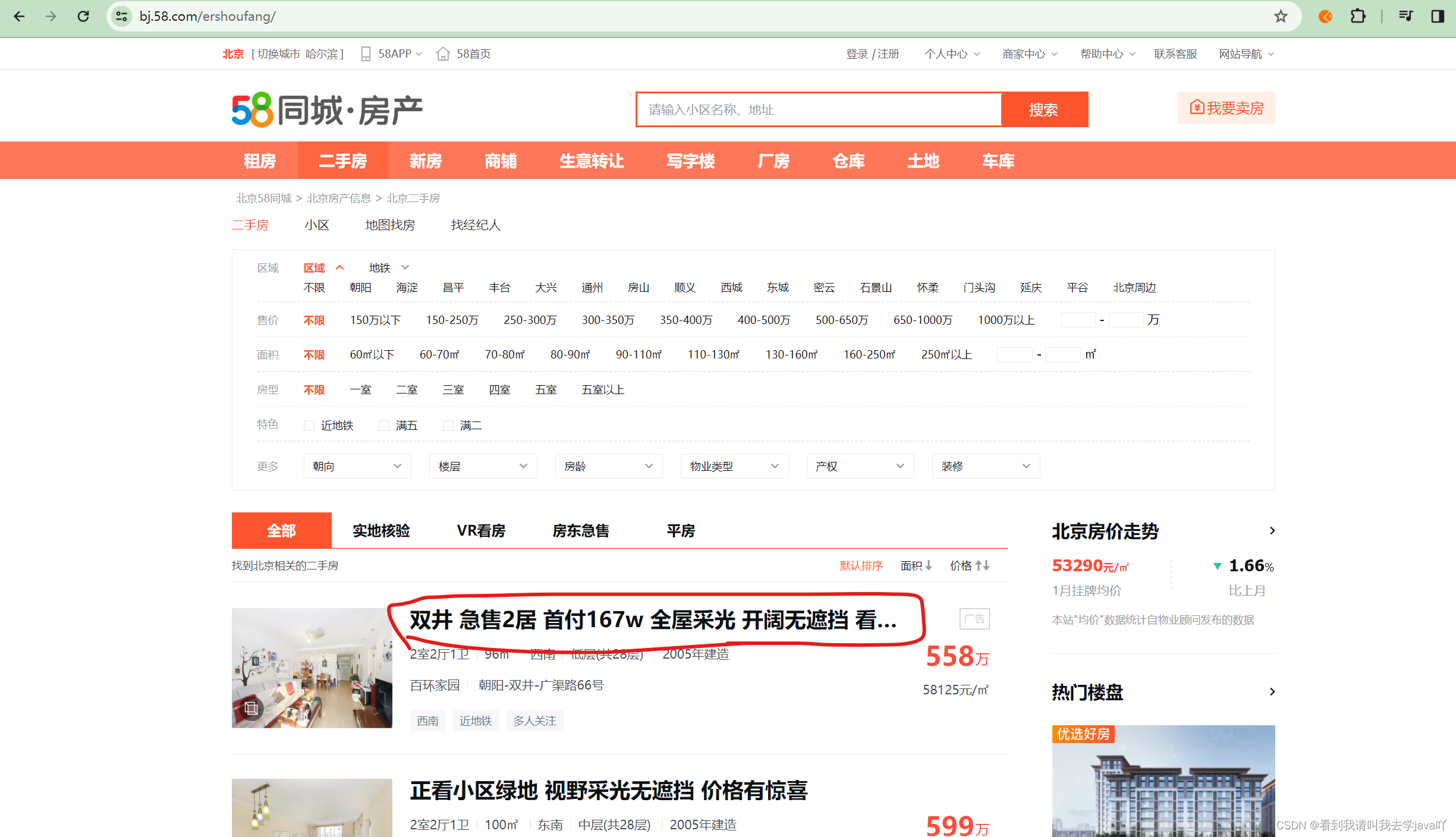
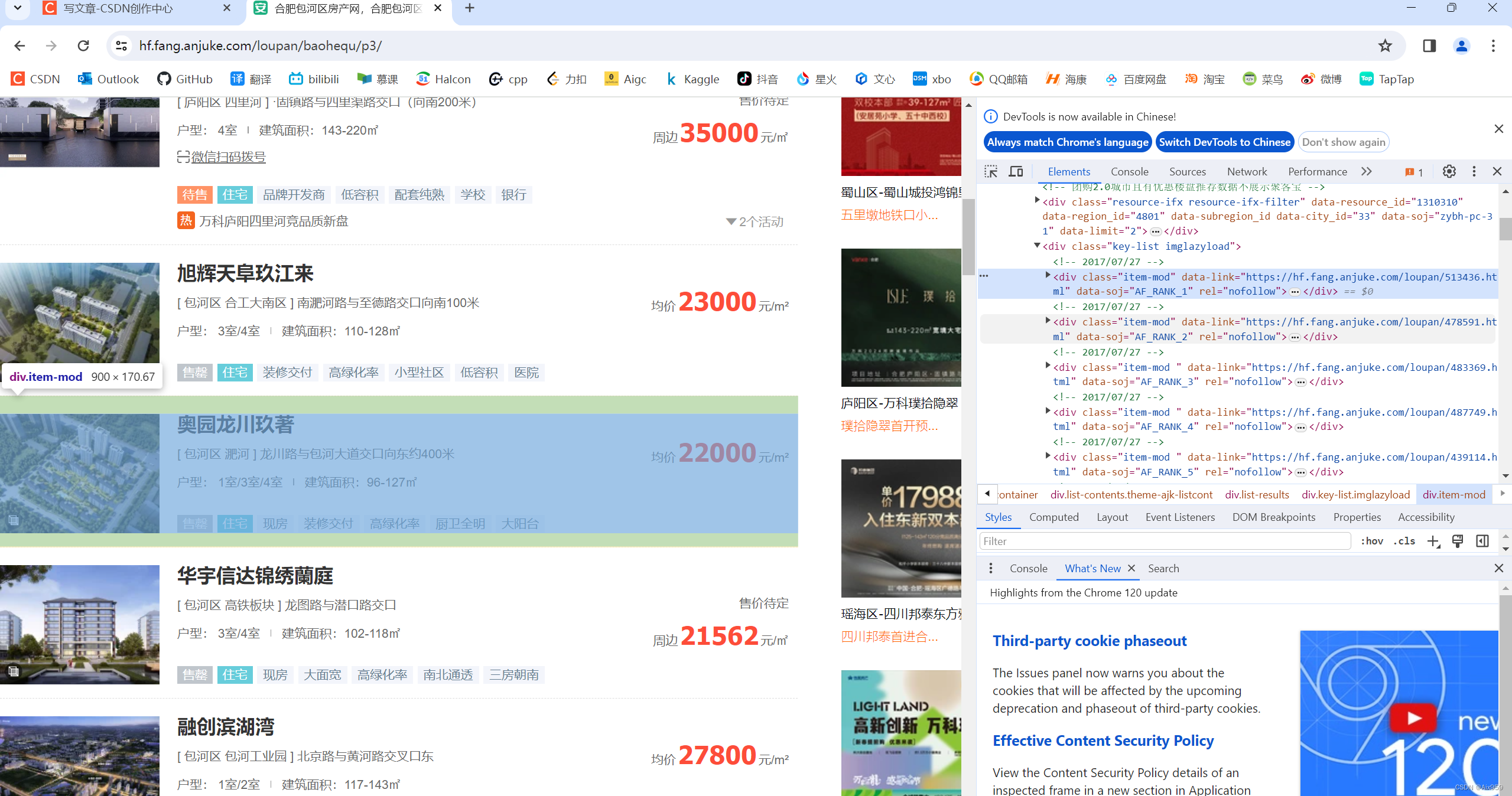
第三:先分析一波title所在的位置
- 打开按下
f12打开抓包工具,即可看到网站的源码,逐步定位至房子信息的部分
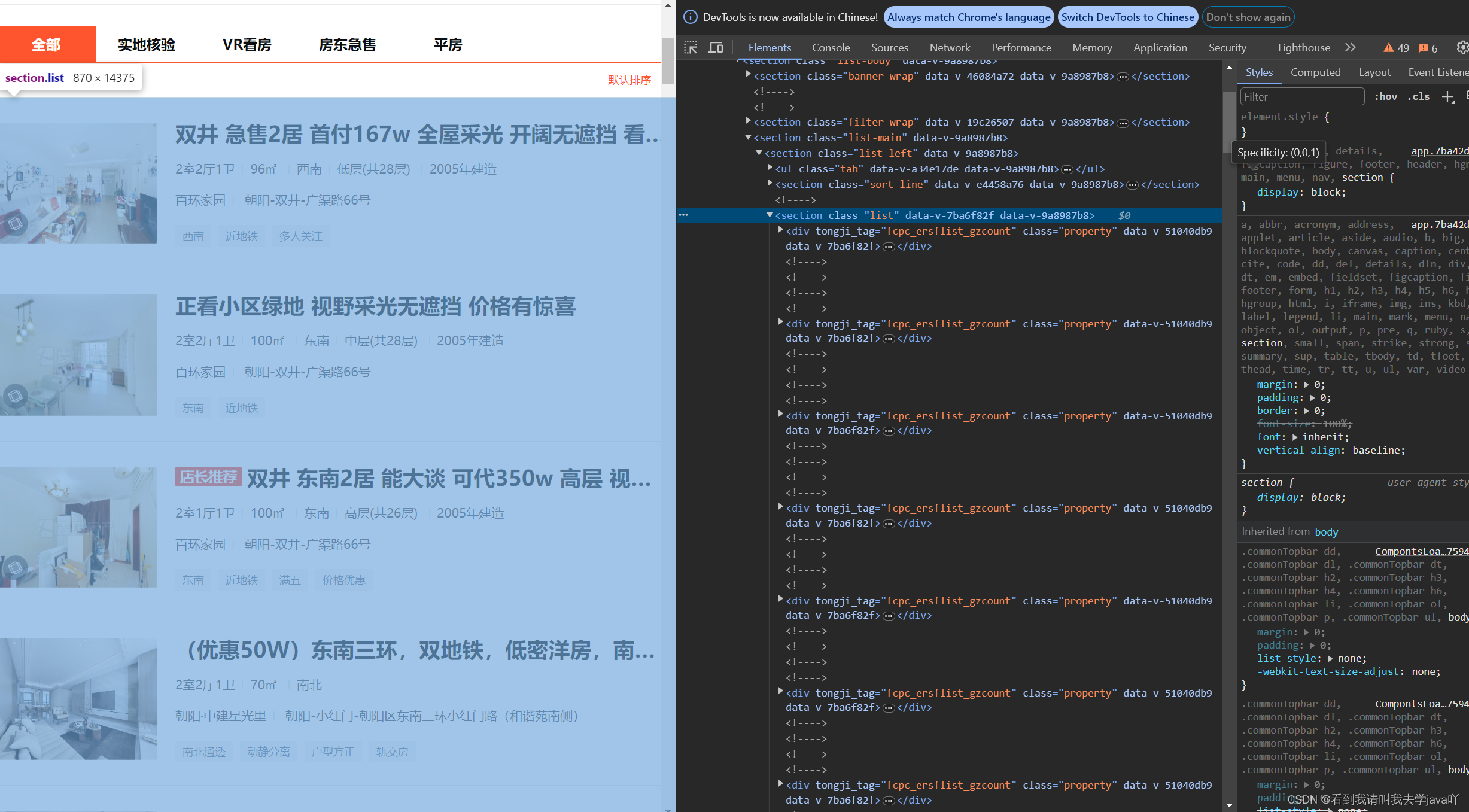
- 我们以第一个房子信息为例,找到它的
title位置,最终发现它在<h3>这个位置~
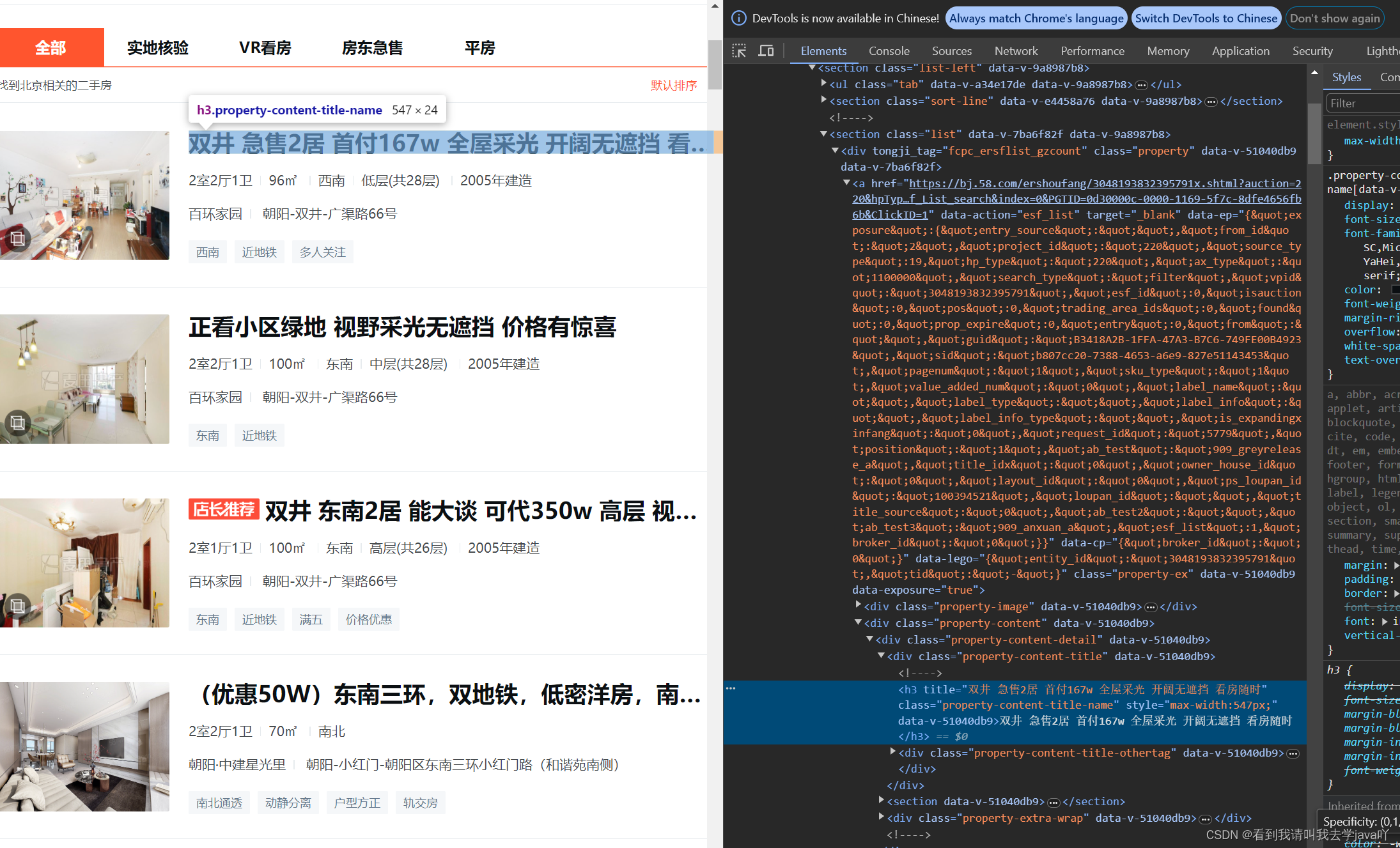
- 目前,我们就需要在网页的源码上获取到
<section class="list">下的<h3>里的文本信息
第四:想要获取某个标签下的文本信息或是属性信息,我们就要借助xpath啦,当然在网课里,老师讲了用正则表达式或bs4也可以,但是由于时间有限,我就直接学xpath啦
至于xpath是啥呢,简而言之,就是在网页的源码中定位至某一标签,并且获取标签内容或是属性的解析工具
# 使用xpath,首先,需要安装lxml的包
from lxml import etree
# 第二,实例化etree对象
# 2.1 解析本地的html文件
page_etree = etree.parse('本地html地址')
# 2.2 直接加载网页的源码
page_etree = etree.HTML(page_text)
# 通过xpath表达式定位至某一标签,当然获得是列表哈
list = page_etree.xpath('xpath表达式')
至于xpath表达式怎么码嘞,记住以下几点~
咱们以下面这个html->head标签下的title为例哈
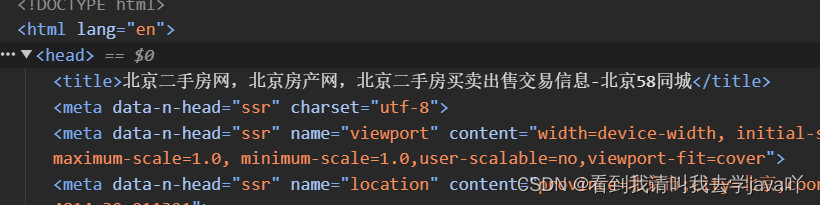
# 通过/html/head/title可以逐步定位至<html><head><title></title></head></html>的位置,而/text()则可以获取title标签内的文本内容
list = page_etree.xpath('/html/head/title/text()')
print(list)
# 但是如果这样逐步定位,实在太麻烦了
# 比如说咱们现在需要定位的房子信息的title,需要写好多级的section和div,总不能一个个数叭
# 通过"//"就搞定啦,"//"就可以直接跨越多个标签层级,直接定位到符合条件的那一个标签啦
list = page_etree.xpath('//title/text()')
print(list)
如果说,有多个title,例如下面这个情况,但是我们只想获得特定的title的内容,只需要加入class即可
<html>
<head>
<title class="t1">xxxxxxx</title>
<title class="t2">xxxxxxx</title>
<title class="t3">xxxxxxx</title>
</head>
</html>
# 这样就可以获取<title class="t3">xxxxxxx</title>里的文本内容啦
list = page_etree.xpath('//title[@class="t2"]/text()')
那如果要获取某一标签内的属性,例如说<a href="网站链接" />中的链接怎么办嘞,以咱们房子信息中的这个<a>标签为例哈
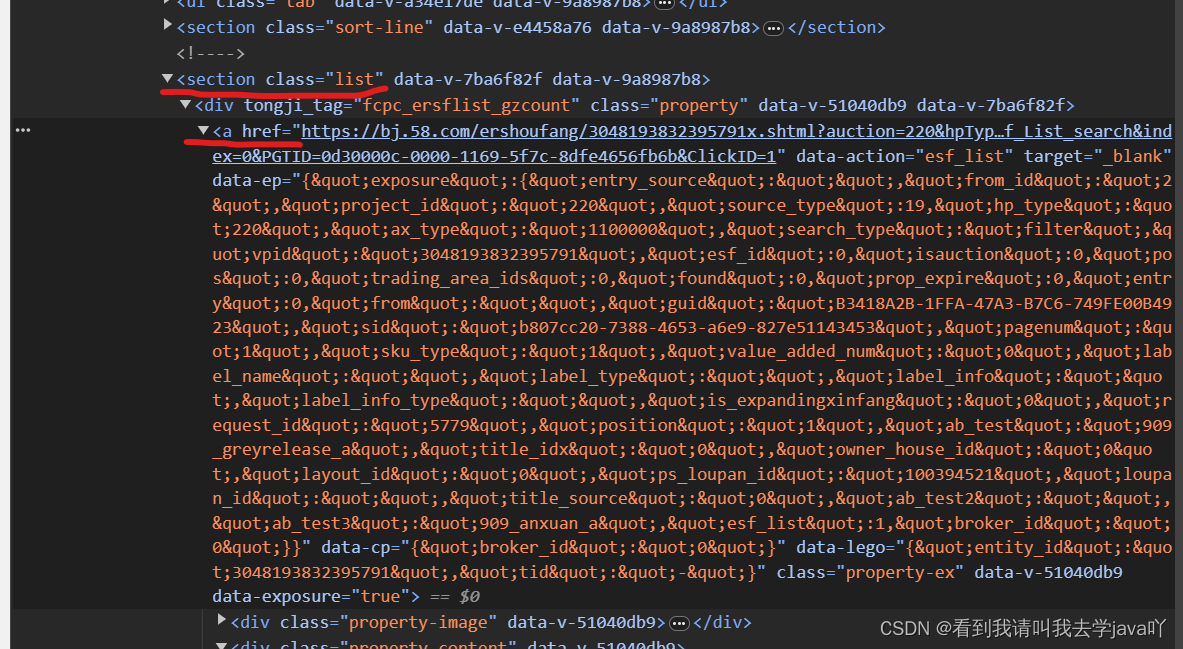
# 这里可以注意两处用了"//"的地方
list = page_etree.xpath('//section[@class="list"]//a/@href')
第五:开码,码完就睡
import requests
from lxml import etree
if __name__ == "__main__":
headers = {
'User-Agent': 'xxxxx',
}
url = 'https://bj.58.com/ershoufang/'
# 发送get请求
page_text = requests.get(url=url, headers=headers).text
# 实例化对象
page_etree = etree.HTML(page_text)
# 根据xpath表达式获取信息
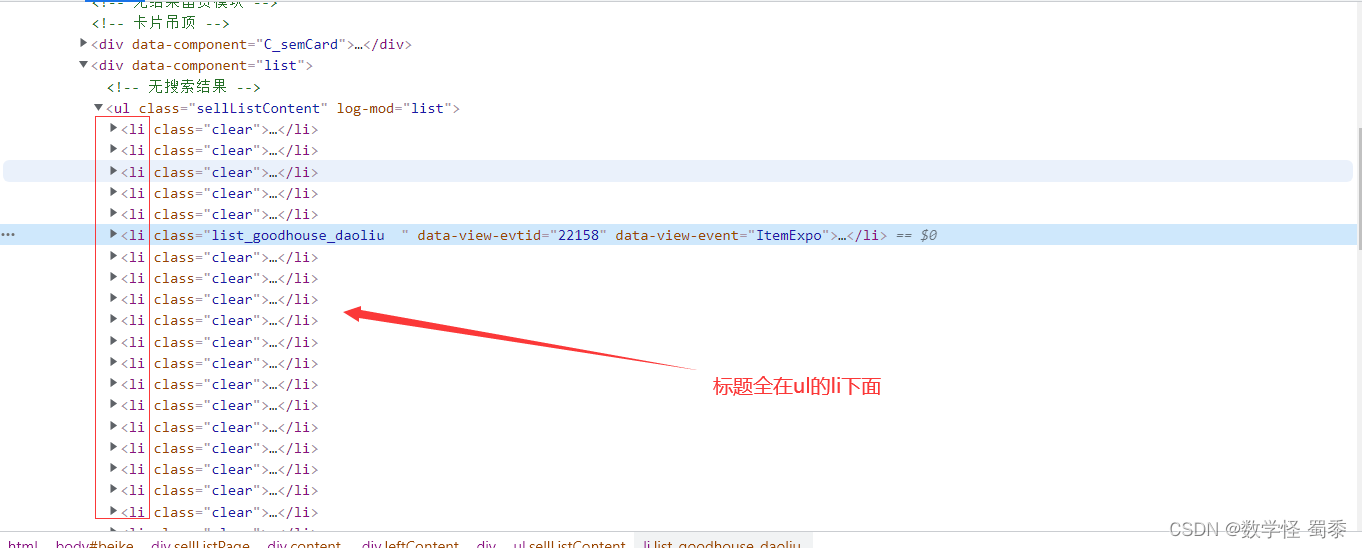
# 注意这里获取的是这个房子一整个信息的div标签,其中包含左侧的房子图片,title和详细信息及价钱
list = page_etree.xpath('//section[@class="list"]/div')
f = open('page/58_1.txt', 'w', encoding='utf-8')
for item in list:
# 在这里,将div标签中的title标签抽出来,保存在txt文件里就完事啦
# 因为xpath获取的结果是一个列表,所以需要在后面加上索引[0]
title = item.xpath('./a/div[@class="property-content"]/div/div/h3/text()')[0]
f.write(title + '\n')
一开始,我为了方便,也采用了下面这个写法
# 在section标签下直接获取h3标签下的内容,貌似也行~
list = page_etree.xpath('//section[@class="list"]//h3/text()')
f = open('page/58.txt', 'w', encoding='utf-8')
for item in list:
f.write(item + '\n')
注意:如果返回的结果为空,回到58二手房的页面刷新一下,点击按钮验证一下即可