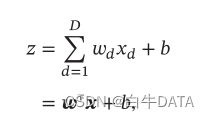源码地址:https://gitee.com/guojialiang2023/gpt2
模型

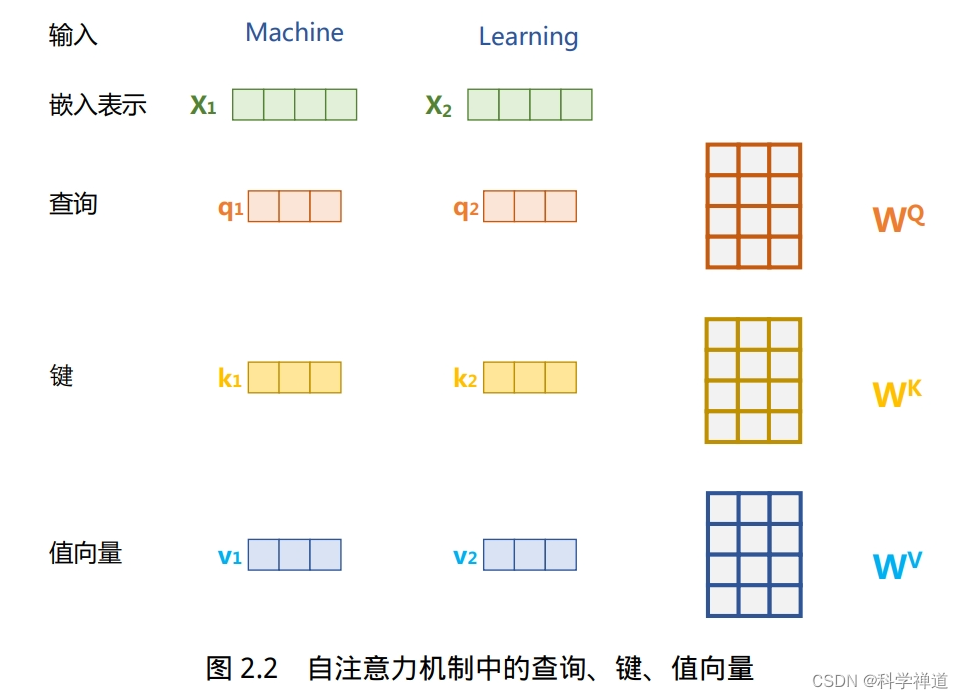
注意力机制
实现了基于多头注意力机制的神经网络层,它定义了三个主要的类:BaseAttention, MultiHeadAttention, 和 AttentionLayer。
BaseAttention类:- 是一个基础的注意力机制实现。
- 输入包括查询 (
q), 键 (k), 值 (v) 张量和一个可选的掩码 (mask)。 - 输出是经过注意力计算后的张量。
- 这个类首先通过对
q和k的点积,然后除以k的最后一个维度的平方根来计算注意力分数。如果提供了掩码,它会在计算中应用。 - 然后应用Softmax函数和dropout,最后返回通过注意力加权的
v值。
MultiHeadAttention类:- 继承自
BaseAttention,实现了多头注意力机制。 - 输入与
BaseAttention相同。 - 它首先将查询 (
q), 键 (k), 值 (v) 张量拆分成多个头,然后在每个头上独立计算注意力。 - 最后,它将这些头的输出合并回一个单一的张量。
- 继承自
AttentionLayer类:- 一个封装了
MultiHeadAttention和额外线性层的神经网络模块。 - 它接受查询 (
q), 键 (k), 值 (v) 张量以及可选的过去状态 (past) 和掩码 (mask)。 - 它首先通过三个线性层对
q,k,v进行投影,然后将它们传递给MultiHeadAttention层。 - 如果提供了过去的状态,它会将这个状态和当前的键、值张量结合起来,以便重复利用以前的计算。
- 最终,它通过另一个线性层对注意力机制的输出进行处理,并返回最终的输出以及更新的过去状态。
- 一个封装了
import math
import torch
import torch.nn as nn
from typing import Optional, Tuple
Past = Tuple[torch.Tensor, torch.Tensor]
class BaseAttention(nn.Module):
"""
Tensor Type Shape
===========================================================================
q float (..., query_len, dims)
k float (..., kv_len, dims)
v float (..., kv_len, dims)
mask bool (..., query_len, kv_len)
---------------------------------------------------------------------------
output float (..., query_len, dims)
===========================================================================
"""
def __init__(self, dropout: float = 0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
def forward(self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
mask: Optional[torch.Tensor] = None) -> torch.Tensor:
x = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(k.size(-1))
if mask is not None:
x += mask.type_as(x) * x.new_tensor(-1e4)
x = self.dropout(x.softmax(-1))
return torch.matmul(x, v)
class MultiHeadAttention(BaseAttention):
"""
Tensor Type Shape
===========================================================================
q float (..., query_len, dims)
k float (..., kv_len, dims)
v float (..., kv_len, dims)
mask bool (..., query_len, kv_len)
---------------------------------------------------------------------------
output float (..., query_len, dims)
===========================================================================
"""
def __init__(self, heads: int, dropout: float = 0.1):
super().__init__(dropout)
self.heads = heads
def forward(self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
mask: Optional[torch.Tensor] = None) -> torch.Tensor:
# Split the tensors to multi-heads.
q = q.view(q.size()[:-1] + (self.heads, q.size(-1) // self.heads))
k = k.view(k.size()[:-1] + (self.heads, k.size(-1) // self.heads))
v = v.view(v.size()[:-1] + (self.heads, v.size(-1) // self.heads))
q = q.transpose(-3, -2)
k = k.transpose(-3, -2)
v = v.transpose(-3, -2)
if mask is not None:
mask = mask.unsqueeze(-3)
# Calculate multi-headed attentions and merge them into one.
return (super().forward(q, k, v, mask)
.transpose(-3, -2)
.contiguous()
.view(q.size()[:-3] + (q.size(-2), v.size(-1) * self.heads)))
class AttentionLayer(nn.Module):
"""
Tensor Type Shape
===========================================================================
q float (..., query_len, dims)
k float (..., kv_len, dims)
v float (..., kv_len, dims)
past (*) float (..., past_len, dims)
mask bool (..., query_len, past_len + kv_len)
---------------------------------------------------------------------------
output 1 float (..., query_len, dims)
output 2 (*) float (..., past_len + kv_len, dims)
===========================================================================
"""
def __init__(self, heads: int, dims: int, dropout: float = 0.1):
super().__init__()
self.attn = MultiHeadAttention(heads, dropout)
self.proj_q = nn.Linear(dims, dims)
self.proj_k = nn.Linear(dims, dims)
self.proj_v = nn.Linear(dims, dims)
self.linear = nn.Linear(dims, dims)
def forward(self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
past: Optional[Past] = None,
mask: Optional[torch.Tensor] = None
) -> Tuple[torch.Tensor, Past]:
q, k, v = self.proj_q(q), self.proj_k(k), self.proj_v(v)
# Reuse attention keys and values by concatenating to the current ones.
if past is not None:
k = torch.cat((past[0], k), dim=-2)
v = torch.cat((past[1], v), dim=-2)
x = self.linear(self.attn(q, k, v, mask))
return x, (k, v)
嵌入层
定义了两个用于GPT-2模型中的嵌入层:PositionalEmbedding 和 TokenEmbedding,都是继承自 PyTorch 的 nn.Embedding 类。
PositionalEmbedding类:- 这个类用于生成位置嵌入,它为序列中的每个位置生成一个唯一的嵌入,这有助于模型理解词语的顺序。
- 在
reset_parameters方法中,它使用标准差为 0.02 的正态分布初始化权重。 _load_from_state_dict方法允许模型在加载预训练权重时调整嵌入层的大小,以适应不同长度的序列。这是通过裁剪或扩展权重矩阵来实现的。forward方法接受一个输入张量x和一个可选的偏移量offset。它创建一个与输入序列长度相同的位置索引,并将这些索引传递给父类的forward方法来获取对应的位置嵌入。
TokenEmbedding类:- 这个类用于生成词语嵌入,它为序列中的每个词语生成一个嵌入,这有助于模型理解词语的含义。
- 在
reset_parameters方法中,它也使用标准差为 0.02 的正态分布初始化权重。 forward方法有一个可选参数transposed。如果transposed为真,它会将输入张量x与权重矩阵的转置进行矩阵乘法,这通常用于特定类型的嵌入或解码操作。如果transposed为假,它就简单地调用父类的forward方法来获取对应的词语嵌入。
import torch
import torch.nn as nn
from typing import Dict
class PositionalEmbedding(nn.Embedding):
"""
Tensor Type Shape
===========================================================================
input long (..., seq_len)
---------------------------------------------------------------------------
output float (..., seq_len, embedding_dim)
===========================================================================
"""
def reset_parameters(self):
nn.init.normal_(self.weight, std=0.02)
def _load_from_state_dict(self,
state_dict: Dict[str, torch.Tensor],
prefix: str,
*args,
**kwargs):
weight = state_dict[f'{
prefix}weight']
# Reduce or expand the positional embedding matrix to increase or decrease the total sequence length.
if weight.size(0) < self.num_embeddings:
weight = torch.cat((weight, self.weight[weight.size(0):]), dim=0)
elif weight.size(0) > self.num_embeddings:
weight = weight[:self.num_embeddings]
state_dict[f'{
prefix}weight'] = weight
super()._load_from_state_dict(state_dict, prefix, *args, **kwargs)
def forward(self, x: torch.Tensor, offset: int = 0) -> torch.Tensor:
position = torch.arange(offset, offset + x.size(-1),
dtype=torch.long, device=x.device)
position = position.view((1,) * (x.ndim - 1) + (-1,)).expand_as(x)
return super().forward(position)
class TokenEmbedding(nn.Embedding):
"""
Tensor Type Shape
===========================================================================
input long or float (..., seq_len)
or (..., seq_len, embedding_dim)
---------------------------------------------------------------------------
output float (..., seq_len, embedding_dim)
or (..., seq_len, num_embeddings)
===========================================================================
"""
def reset_parameters(self):
nn.init.normal_(self.weight, std=0.02)
def forward(self,
x: torch.Tensor,
transposed: bool = False) -> torch.Tensor:
if transposed:
return torch.matmul(x, self.weight.transpose(0, 1))
else:
return super().forward(x)
前馈神经网络
代码实现了 GPT-2 中的两个重要组件:Swish 激活函数和 PositionwiseFeedForward 网络。
Swish类:- 这是一个自定义的神经网络模块,实现了 Swish 激活函数。
- Swish 函数由
x * sigmoid(x)定义,其中sigmoid是 S 形激活函数。这个函数是由 Google Brain 团队提出的,被发现在某些情况下比传统的激活函数(如 ReLU)性能更好。 - 在
Swish类中,sigmoid函数是通过 PyTorch 的nn.Sigmoid模块实现的。 - 在
forward方法中,输入张量x被传递给sigmoid函数,然后与原始输入x相乘。这就是 Swish 激活函数的计算方式。
PositionwiseFeedForward类:- 这是一个继承自 PyTorch
nn.Sequential的类,实现了 Transformer 模型中的位置前馈网络(positionwise feedforward network)。 - 它由两个线性层和一个 Swish 激活函数层组成,中间还包括了一个 dropout 层以减少过拟合。
- 第一个线性层将输入维度从
dims扩展到dims * rate。rate是一个扩展因子,通常设置为 4。 - 紧接着是 Swish 激活函数层和 dropout 层。
- 最后,第二个线性层将维度从扩展后的
dims * rate缩减回原始的dims。 - 这个前馈网络在 Transformer 模型的每个位置都独立地应用相同的操作,因此称为“位置前馈网络”。它可以帮助网络学习输入序列中每个位置的复杂特征。
- 这是一个继承自 PyTorch
Swish 作为一种有效的激活函数,帮助模型捕捉非线性关系;而 PositionwiseFeedForward 网络则增强了模型在处理序列数据时的能力,使其能够在每个位置学习高级特征。这些特性共同使 GPT-2 成为处理各种复杂自然语言处理任务的强大工具。
import torch
import torch.nn as nn
class Swish(nn.Module):
"""
Tensor Type Shape
===========================================================================
input float (..., dims)
---------------------------------------------------------------------------
output float (..., dims)
===========================================================================
"""
def __init__(self):
super().__init__()
self.sigmoid = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x * self.sigmoid(x)
class PositionwiseFeedForward(nn.Sequential):
"""
Tensor Type Shape
===========================================================================
input float (..., dims)
---------------------------------------------------------------------------
output float (..., dims)
===========================================================================
"""
def __init__(self, dims: int, rate: int = 4, dropout: float = 0.1):
super().__init__(
nn.Linear(dims, dims * rate),
Swish(),
nn.Dropout(dropout),
nn.Linear(dims * rate, dims))