最近要租房,写了一个豆瓣租房小组的爬虫,直接上代码
from lxml import etree
import requests
import time
import pandas as pd
import tqdm
def get_code(start, group_url):
url = group_url
headers = {
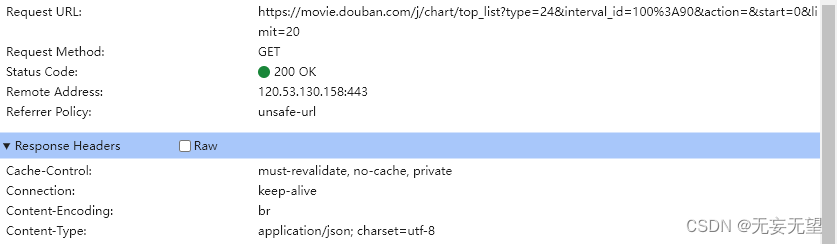
#填自己登录之后的cookie 参考教程https://blog.csdn.net/weixin_41666747/article/details/80315002
}
data = {
'start': start,
'type': 'new'
}
request = requests.get(url=url, params=data, headers=headers)
response = request.text
return response
def list_posts(response, page, titles, urls, dates, authors, replies):
tree = etree.HTML(response)
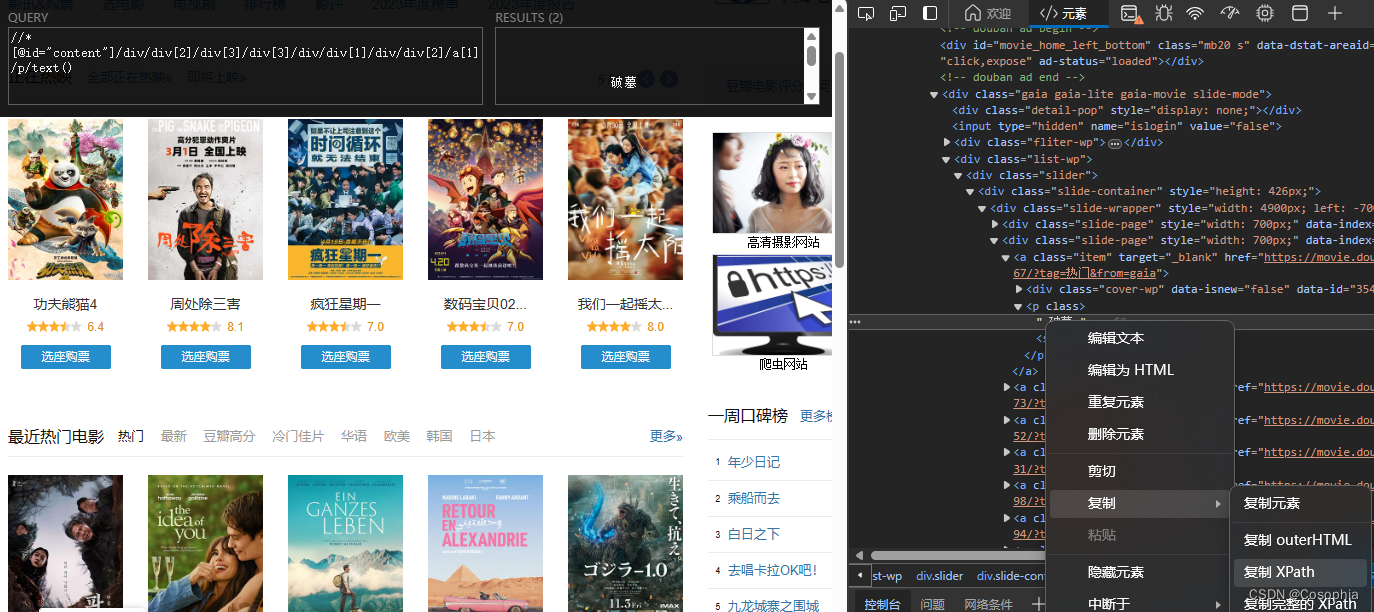
titles_arr = tree.xpath('//table[@class="olt"]/tr//td/a/@title')
for t in range(len(titles_arr)):
titles[page].append(titles_arr[t])
urls_arr = tree.xpath('//table[@class="olt"]/tr//td[@class="title"]//a/@href')
for u in range(len(urls_arr)):
urls[page].append(urls_arr[u])
dates_arr = tree.xpath('//table[@class="olt"]/tr//td[@class="time"]/text()')
for d in range(len(dates_arr)):
dates[page].append(dates_arr[d])
authors_arr = tree.xpath('//table[@class="olt"]/tr//td[@nowrap="nowrap"]/a/text()')
for a in range(len(authors_arr)):
authors[page].append(authors_arr[a])
replies_arr = tree.xpath('//table[@class="olt"]/tr//td[@class="r-count "]/text()')
for r in range(len(replies_arr)):
replies[page].append(replies_arr[r])
return titles, urls, dates, authors, replies
def get_page(all_page, group_url):
titles = [[] for i in range(all_page)]
urls = [[] for i in range(all_page)]
dates = [[] for i in range(all_page)]
authors = [[] for i in range(all_page)]
replies = [[] for i in range(all_page)]
for i in tqdm.tqdm(range(all_page)):
start = i * 25
time.sleep(0.05)
response = get_code(start, group_url)
titles, urls, dates, authors, replies = list_posts(response, i, titles, urls, dates, authors, replies)
return titles, urls, dates, authors, replies
#北京租房 100万+ 个成员 在此聚集
group_url = 'https://www.douban.com/group/beijingzufang/discussion'
# 北京租房 481519 个成员 在此聚集
group_url = 'https://www.douban.com/group/sweethome/discussion'
all_page = 100
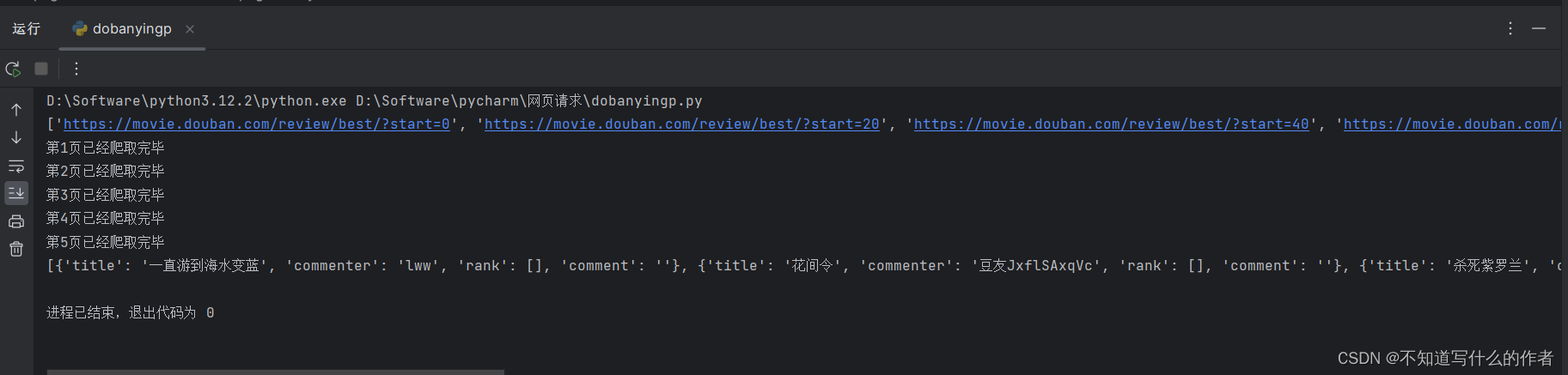
print('正在爬取' + str(int(all_page) * 25) + '篇帖子,请稍后...')
titles, urls, dates, authors, replies = get_page(int(all_page), group_url)
data = []
for i in range(int(all_page)):
for j in range(len(titles[i])):
data.append({
"Title": titles[i][j], "Author": authors[i][j], "Date": dates[i][j], "Url": urls[i][j]})
# print("【查找成功!第%d页】" % (i + 1))
# print("标题:" + titles[i][j])
# print("作者:" + authors[i][j])
# # print("回复数:" + replies[i][j])
# print("最后回复时间:" + dates[i][j])
# print("链接:" + urls[i][j])
# print('-----------------------------------------------------')
df = pd.DataFrame(data)
# 将表格写入Excel文件
df.to_excel("output.xlsx", index=True)
print('爬取完成!')