string.h主要定义了字符串处理函数和内存操作函数。
字符串处理函数
strlen()
功能:strlen()函数返回字符串的字节长度,不包括末尾的空字符\0。
函数原型:size_t strlen(const char* s);
返回值:返回的是size_t类型的无符号整数(%zd),除非是极长的字符串,一般情况下当作int类型处理即可(%d)。
参数:字符串指针
注意:
区分字符串长度
strlen()与字符串变量长度sizeof()char s[50] = "hello"; printf("%d\n", strlen(s)); // 5 printf("%d\n", sizeof(s)); // 50
my_strlen
int my_strlen(const char *s){ int count = 0; while (*s++) // 终止条件 '\0' count++; return count; }
strcpy()
功能:用于将源字符串的内容复制到目标字符串,相当于字符串赋值,两者地址均未改变。
函数原型:char *strcpy(char dest[], const char source[])
参数:
- 第一个参数是目标字符串数组
- 第二个参数是源字符串(
const说明符,表示strcpy函数不会修改第二个字符串)
返回值:返回一个字符串指针(即char*),指向第一个参数
注意:
- 复制字符串之前,必须要保证第一个参数的长度大于等于第二个参数的长度,否则虽然不会报错,但会溢出第一个字符串变量的边界,发生难以预料的结果。容易发生缓冲区溢出!
- 复制时会将字符串中的 ’\0’ 也一同复制进去
strcpy()也可以用于字符数组的赋值。
char str[10];
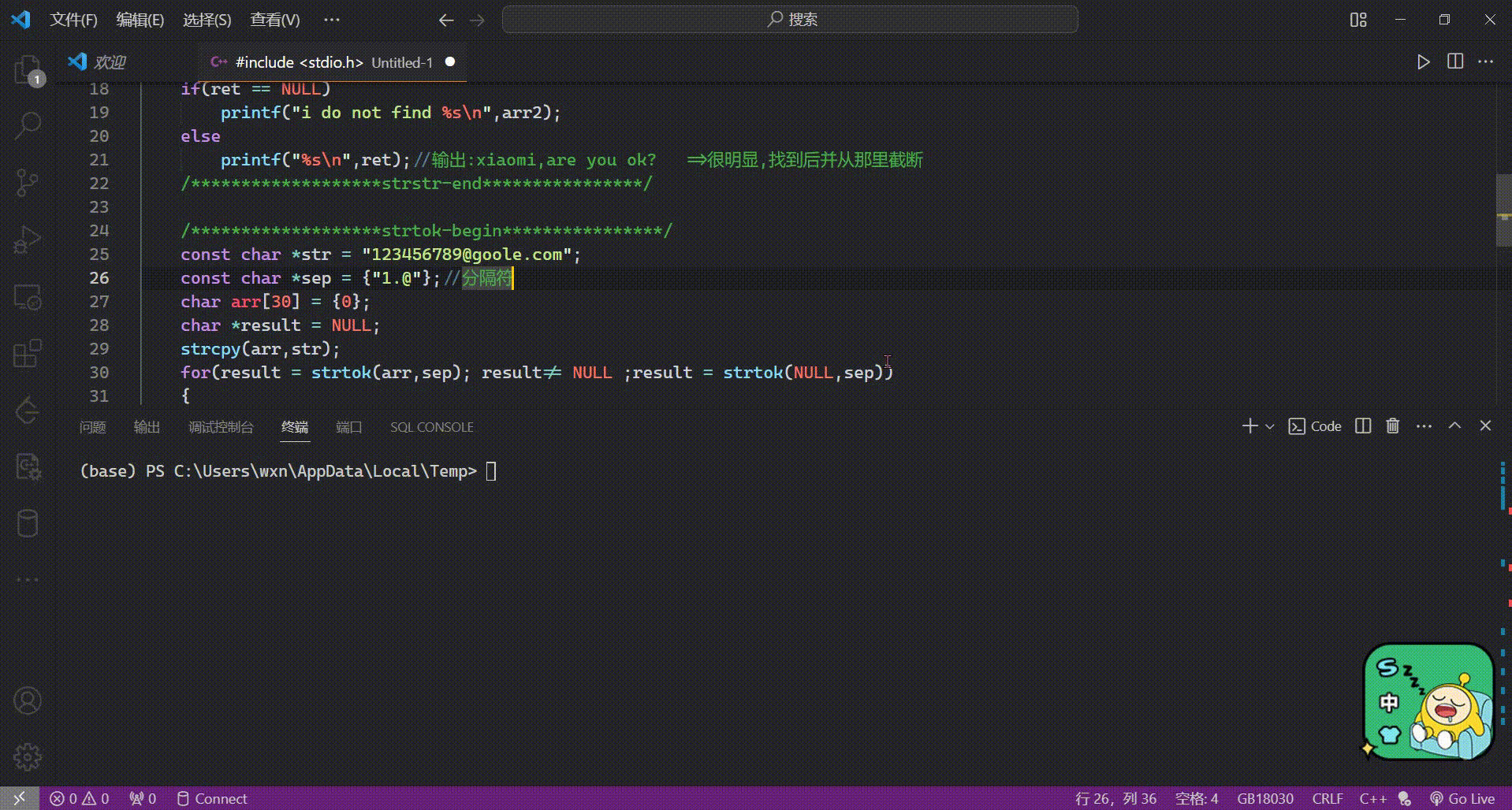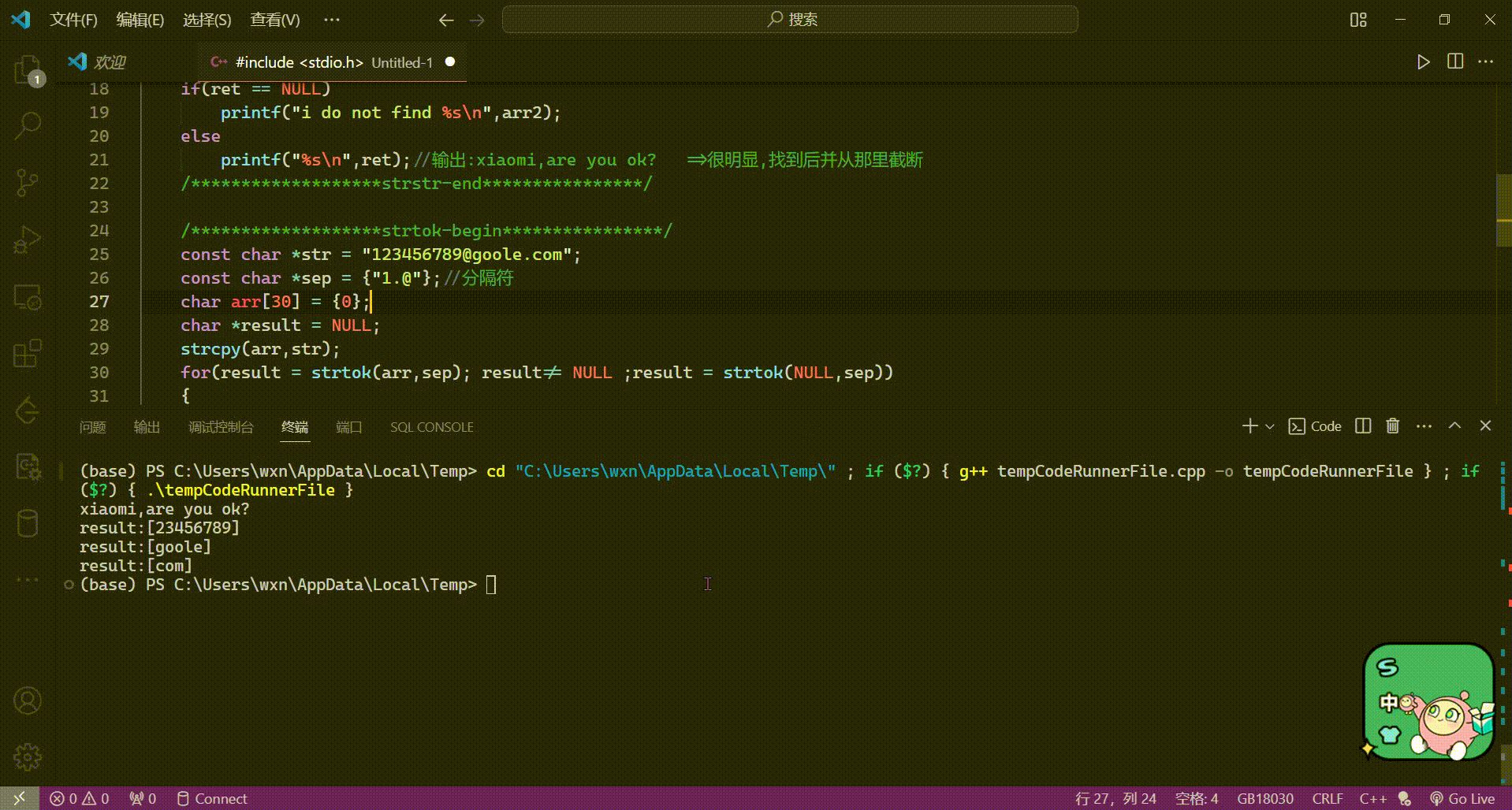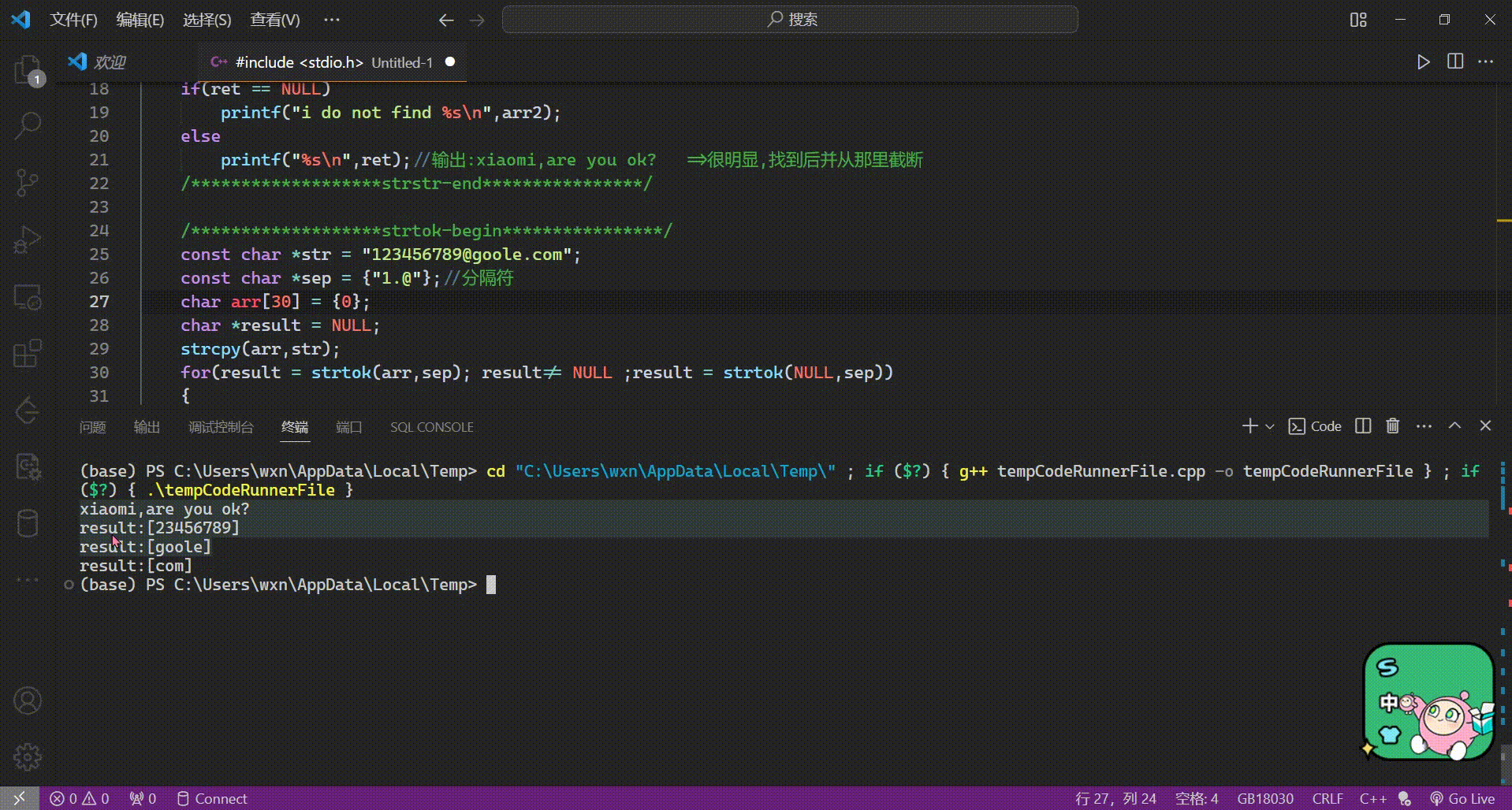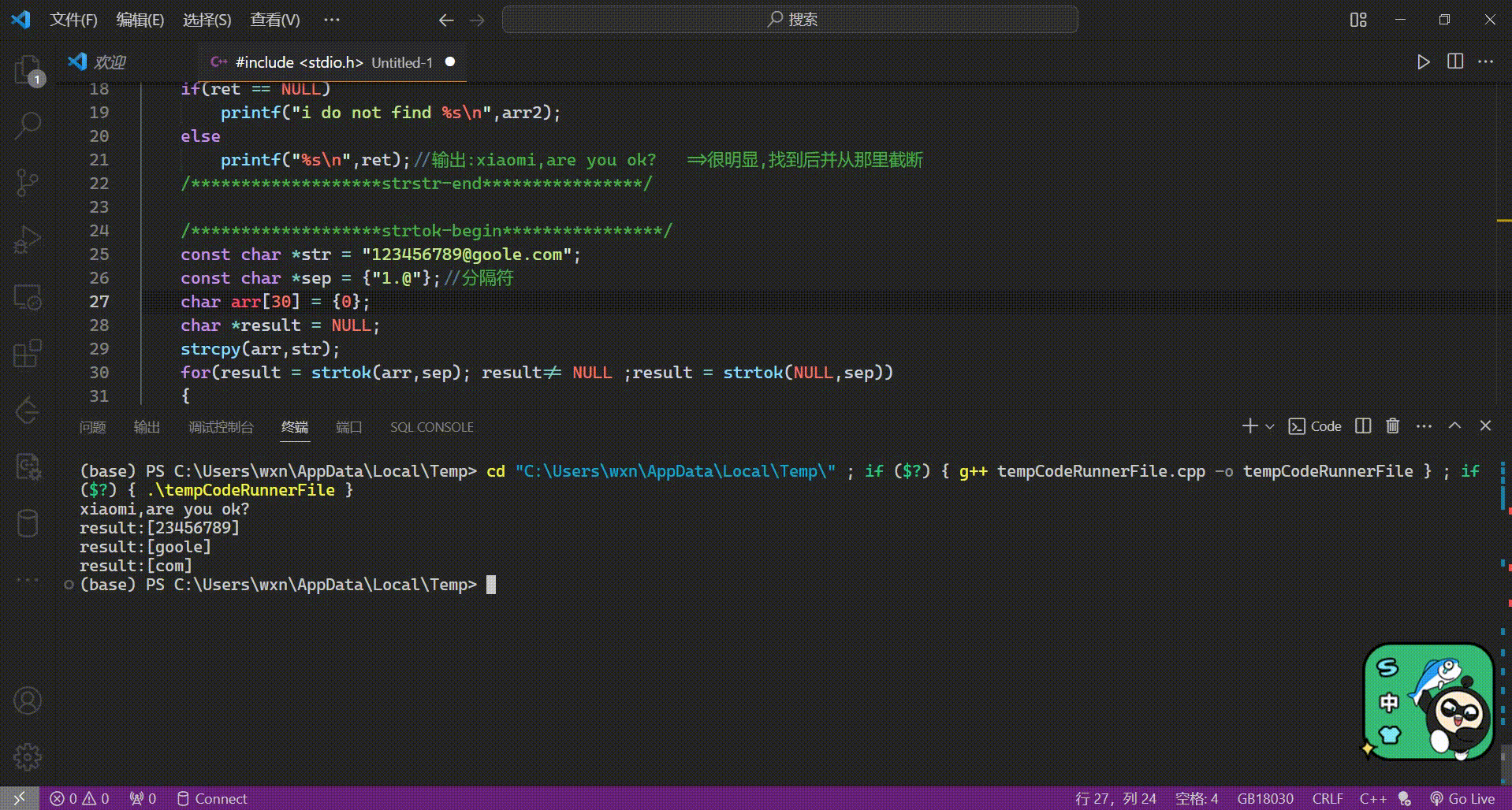
strcpy(str, “abcd”);
strcpy()返回值的用途,连续为多个字符数组赋值。
strcpy(str1, strcpy(str2, “abcd”));
strcpy()的第一个参数最好是一个已经声明且初始化的数组。目标字符串若没有进行初始化,指向的是一个随机的位置,因此字符串可能被复制到任意地方。(初始化是指手动为指针开辟空间,而不是使用字符串赋值初始化)
char* str; // char *str = “ERROR”; 字符串赋值初始化
strcpy(str, “hello world”); // 错误
my_strcpy
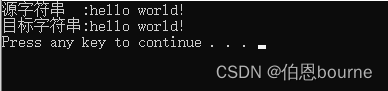
char* my_strcpy(char* dest, const char* source) { char* ptr = dest; while (*dest++ = *source++); // 不是 == return ptr; } int main(void) { char str[25]; strcpy(str, "hello world"); printf("%s\n", str); return 0; }
strncpy()
功能:strncpy()跟strcpy()的用法完全一样,只是多了第3个参数,用来指定复制的最大字符数,防止溢出目标字符串变量的边界。
函数原型:char* strncpy(char *dest, char *src, **size_t n)**;
参数:第三个参数n定义了复制的最大字符数。如果达到最大字符数以后,源字符串仍然没有复制完,就会停止复制,这时目的字符串结尾将没有终止符\0,这一点务必注意。如果源字符串的字符数小于n,则strncpy()的行为与strcpy()完全一致。
返回值:返回一个字符串指针(即char*),指向第一个参数
疑问:dest与src的长度比较,src与n的比较,dest与n的长度比较
- 如果src字符串比dest长会有什么结果?
- 排除疑问1,如果src字符串比指定的n短怎么样?
- 如果src字符串比指定的n短怎么样?
my_strncpy()
char *my_strncpy(char *dest, char *src, int n) { char *ret = dest; for (int i = 0; i < n && *src != '\0'; i++) { *dest++ = *src++; if (*dest == '\0'){ break; } } // 添加终止符 if (*src == '\0'){ *dest = '\0'; } return ret; }
strcat()(缓冲区溢出)
功能:strcat()函数用于连接字符串。即将源字符串s2拼接在目标字符串s1后面。
函数原型:char* strcat(char *s1, const char *s2);
参数:它接受两个字符串作为参数,把第二个字符串的副本添加到第一个字符串的末尾。这个函数会改变第一个字符串,但是第二个字符串不变。
返回值:strcat()的返回值是一个字符串指针,指向第一个参数。
注意:
- 要确保两字符串长度之和小于源字符串的容量长度,否则可能会导致缓冲区溢出。
一个错误代码例子
#include <stdio.h> #include <time.h> #include <string.h> int main () { char s1[8] = "test"; char *s2 = "hello"; // sizeof = 8, strlen = 4 test printf("sizeof = %d, strlen = %d %s\n", sizeof(s1), strlen(s1), s1); strcat(s1, s2); // sizeof = 8, strlen = 9 testhello printf("sizeof = %d, strlen = %d %s\n", sizeof(s1), strlen(s1), s1); return 0; }
strncat()
功能:与strcat()完全一致,strncat()用于连接两个字符串。
函数原型:char* strncat(const char *dest, const char *src, size_t n);
参数:增加了第三个参数,指定最大添加的字符数。在添加过程中,一旦达到指定的字符数,或者在源字符串中遇到空字符\0,就不再添加了。
返回值:strncat()返回第一个参数,即目标字符串指针。
为了保证连接后的字符串,不超过目标字符串的长度,strncat()通常会写成下面这样。
strncat(
str1,
str2,
sizeof(str1) - strlen(str1) - 1
);
strncat()总是会在拼接结果的结尾,自动添加空字符\0,所以第三个参数的最大值,应该是str1的变量长度减去str1的字符串长度,再减去1
strcmp()
功能:strcmp()函数用于比较两个字符串的内容(从左到右比较字符串中的ASCII码值)。
函数原型:int strcmp(const char* s1, const char* s2);
参数:需要比较的两个字符串
返回值:按照字典顺序,如果两个字符串相同,返回值为0;如果s1小于s2,strcmp()返回值小于0;如果s1大于s2,返回值大于0。
// s1 = Happy New Year
// s2 = Happy New Year
// s3 = Happy Holidays
strcmp(s1, s2) // 0
strcmp(s1, s3) // 大于 0
strcmp(s3, s1) // 小于 0
注意:
- strcmp()只用来比较字符串,不用来比较字符。字符直接用相等运算符(
==)就能比较。
my_strcmp.c
int my_strcmp(const char *s1, const char *s2){ while( (*s1) && (*s2) && (*s1 == *s2)){ s1++; s2++; } return (*s1 - *s2); }
strncmp()
功能:strncmp()只比较到指定位置的字符串(从左到右比较字符串中字符的ASCII码值)。
函数原型:int strncmp( const char* s1, const char* s2, **size_t n**);
参数:该函数增加了第三个参数,指定了比较的字符数。
返回值:与strcmp()一样。如果两个字符串相同,返回值为0;如果s1小于s2,strcmp()返回值小于0;如果s1大于s2,返回值大于0。
my_strncmp
int my_strncmp(const char *s1, const char *s2, size_t n){ int num = 0; while( (*s1) && (*s2) && (*s1 == *s2)){ num++; if (num == n) { break; } s1++; // 偏移量增加要放在判断后面 s2++; } return (*s1 - *s2); }
strchr(),strrchr()
功能:strchr()和strrchr()都用于在字符串中查找指定字符。不同之处是,strchr()从字符串开头开始查找,strrchr()从字符串结尾开始查找,函数名中多出来的r表示 reverse(反向)。
函数原型:
char* strchr(char* str, int c);char* strrchr(char *str, int c);
参数:第一个参数是字符串指针,第二个参数是所要查找的字符。
返回值:一旦找到该字符,它们就会停止查找,并返回指向该字符的指针。如果没有找到,则返回 NULL。
my_strchr和my_strrchr
// 正向搜索 char *my_strchr(char *str, int c){ while (*str) { if (*str == c) { return str; } else { str++; } } } // 反向搜索 char *my_strrchr(char *str, int c){ int size = strlen(str); for (int i = size; i >= 0; i--) { if (*(str + i - 1) == c) { return str + i - 1; } } return NULL; }确定二维字符串(以NULL结尾)中是否含有某个字符(还是不能区分二者版本的区别)
#include <stdio.h> #include <assert.h> int main() { char *strings[] = { "Hello", "World","Test", NULL}; char value = 'l'; int result = find_char(strings, value); if (result == 1) { printf("The character '%c' is found in one of the strings.\n", value); } else { printf("The character '%c' is not found in any of the strings.\n", value); } return 0; }// 版本一,没有副作用,将原来的字符串指针拷贝一份 int find_char(char **strings, char value){ char *string; while((string = *strings++) != NULL){ while(*string != '\0'){ if (*string++ == value) { return 1; } } } return 0; }需要注意的是,虽然 *strings++ 表达式不会直接修改原始字符串指针数组,但是它会将 strings 指向下一个字符串指针。这意味着,如果我们在循环外部还需要访问原始字符串指针数组,那么在循环结束后,副本strings 指针已经指向了最后一个字符串指针的下一个位置,可能导致访问越界。因此,在使用这个版本的函数时,需要注意循环结束后 strings 指针的位置。
// 版本二,仅仅只能检测一次,因为有副作用 int find_char(char **strings, char value) { assert(strings != NULL); // 这本不是函数的事情,strings建立时,就应检查是否为空 while(*strings != NULL){ while(**strings != '\0'){ if (*(*strings)++ == value){ // 副作用在这里,对传递进来的参数进行解引用后更改 return 1; } } strings++; } return 0; }当我们传递一个字符串数组
char **strings给函数find_char时,我们有两种处理方式来查找指定字符value。在第一个版本中,我们使用了一个新的指针string来拷贝原始字符串指针*strings的值。这意味着我们在函数内部操作的是拷贝后的指针,而不是原始字符串指针。因此,在这个版本中,无论我们对string进行任何修改,都不会影响到原始字符串指针。这样的好处是,我们可以多次调用find_char函数,每次都会在拷贝的字符串指针上进行查找,而不会影响到其他调用。同时,由于没有修改原始字符串指针,这个版本更加安全。在第二个版本中,我们直接操作原始字符串指针
*strings。这意味着对原始指针的任何修改都会影响到其他调用find_char函数的地方。具体到这个例子中,我们在内层循环中对*strings进行自增操作,即(*strings)++,这会导致*strings指向下一个字符。因此,如果我们需要多次调用find_char函数,就会在每次调用之后改变原始字符串指针的位置,从而导致错误的结果或者不可预期的行为。这种副作用的存在可能会对程序的正确性和可维护性造成严重影响。总结起来,第一个版本通过拷贝字符串指针来避免副作用,确保了代码的安全性和可维护性。第二个版本虽然更加节省内存,但是具有副作用,可能会引发错误,因此使用时需要格外小心。选择哪个版本取决于具体的需求和场景。























![[EMV]一文读懂GAC](https://img-blog.csdnimg.cn/direct/ca86cf0277e8408ca94ca867e49aa5da.png)