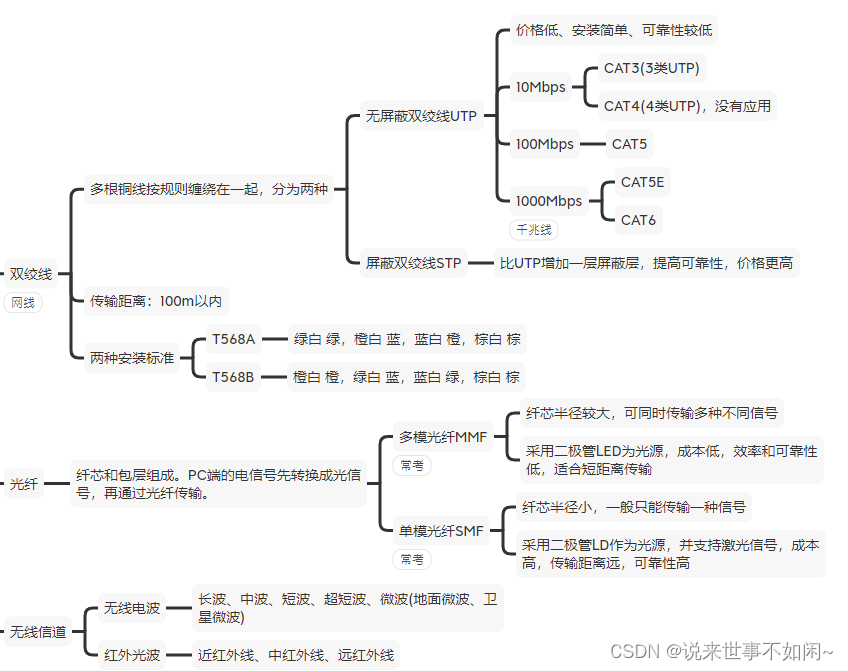
索引的管理
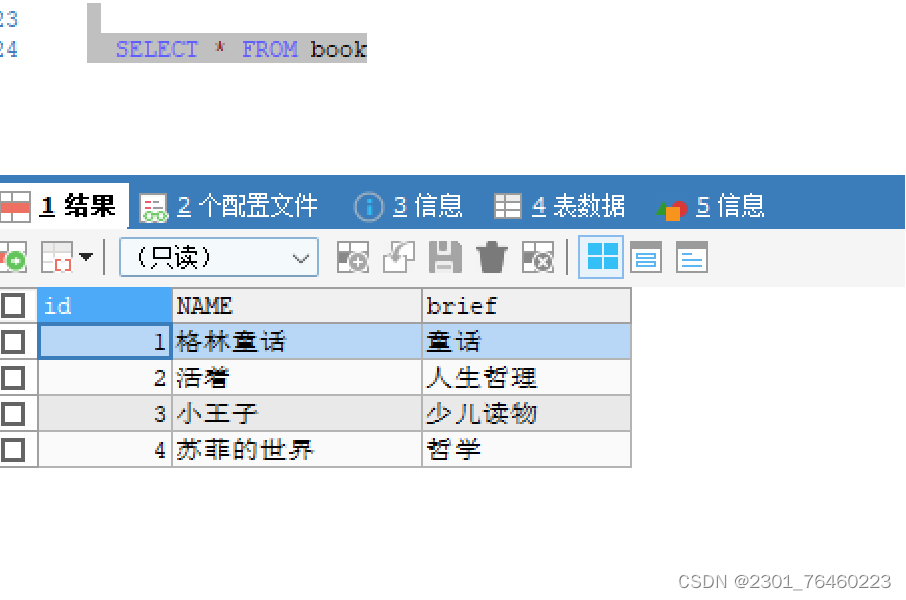
查看索引
SHOW INDEX(或KEYS) FROM 表名;
删除索引
ALTER TABLE 表名 DROP PRIMARY KEY;
DROP INDEX 索引名 ON 表名;
ALTER TABLE 表名 DROP INDEX 索引名;
修改索引
ALERT TABLE 表名 ADD 索引类型(数据列名);
ALTER TABLE <表名> add FULLTEXT INDEX <索引名>(字段名1,字段2,,) [ WITH PARSERngram];
索引的使用原则
索引的使用原则(1)
最左前缀匹配原则,非常重要的原则!!!
对于联合索引,总是从索引的最前面字段开始,接着往后,中间不能跳过。
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
如果建立(a,b,c,d)顺序的索引,d是用不到索引的,
如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
索引的使用原则(2)
尽量选择区分度高的列作为索引
区分度的公式是count(distinct col)/count(*)
表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,
使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。(比如,我们会选择学号做索引,而不会选择性别来做索引。)
索引的使用原则(3)
=和in可以乱序
比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
索引的使用原则(4)
索引列不能参与计算,保持列“干净”
比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
例如:select * from users where YEAR(adddate)<2007,将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成:select * from users where adddate<'2007-01-01'。
比如:Flistid+1>‘2000000608201108010831508721‘。原因很简单,假如索引列参与计算的话,那每次检索时,都会先将索引计算一次,再做比较,显然成本太大。
索引的使用原则(5)
尽量的扩展索引,不要新建索引
比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
索引的使用原则(6)
索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL
索引的使用原则(7)
使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
索引的使用原则(8)
索引列排序
MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
索引的使用原则(9)
like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
使用索引的场景
1、匹配全值:对索引中所有列都指定具体值,即对索引中的所有列都有等值匹配的条件。
2、匹配值的范围查询:对索引的值能够进行范围查找
3、匹配最左前缀:仅仅使用索引中的最左边列进行查询。比如组合索引(col1,col2,col3)能够被col1,col1+col2,col1+col2+col3的等值查询利用到的。
4、仅对索引进行查询:当查询列都在索引字段中。即select中的列都在索引中。
5、匹配列前缀:仅仅使用索引的第一列,并且只包含索引第1列的开头部分进行查找。例如:WHERE title LIKE ‘xxx%’
6、索引部分等值匹配,部分范围匹配
7、若列名是索引,则使用column_name is null就会使用索引
索引存在但不能使用索引的场景
1、以%开头的like查询
2、数据类型出现隐式转化,不会使用索引
3、组合索引,不满足最左原则,不使用符合索引
4、估计使用索引比全表扫描还慢,则不要使用索引
5、用or分割条件,若or前后只要有一个列没有索引,就都不会用索引
6、使用 != 或 <> 操作符时 :尽量避免使用!= 或 <>操作符,否则数据库引擎会放弃使用索引而进行全表扫描。使用>或<会比较高效。
7、对字段进行null值判断:应尽量避免在where子句中对字段进行null值判断,否则将导致引擎放弃使用索引而进行全表扫描
8、避免select * : 在解析的过程中,会将'*' 依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间
SQL优化原则
1. 建议使⽤预编译语句进⾏数据库操作
2. 避免数据类型的隐式转换
3. 充分利⽤表上已经存在的索引
4. 禁⽌使⽤ SELECT * 必须使⽤ SELECT 查询
5. 禁⽌使⽤不含字段列表的 INSERT 语句
6. 避免使⽤⼦查询,可以把⼦查询优化为 join 操作
7. 避免使⽤ JOIN 关联太多的表
8. 对应同⼀列进⾏ or 判断时,使⽤ in 代替 or
9. WHERE 从句中禁⽌对列进⾏函数转换和计算
10. 在明显不会有重复值时使⽤ UNION ALL ⽽不是 UNION
11. 拆分复杂的⼤ SQL 为多个⼩ SQL




















![如何实现指定列值排序? ------ MySQL中的field()函数 [让排序更简单]](https://img-blog.csdnimg.cn/direct/fbc207519e1541658d4a4e04f40ac79d.png)