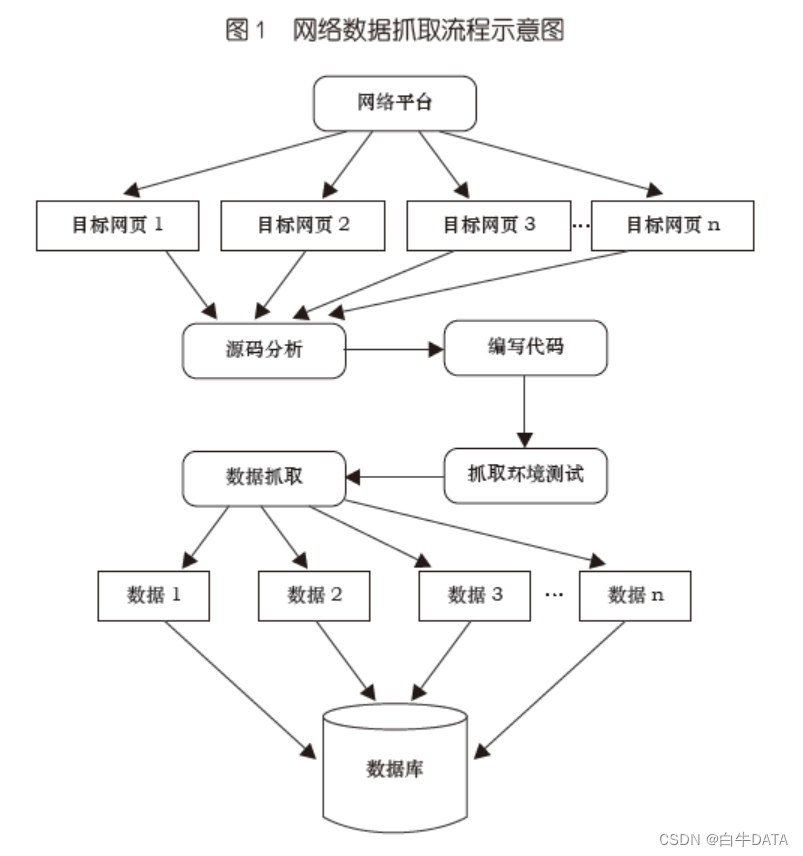
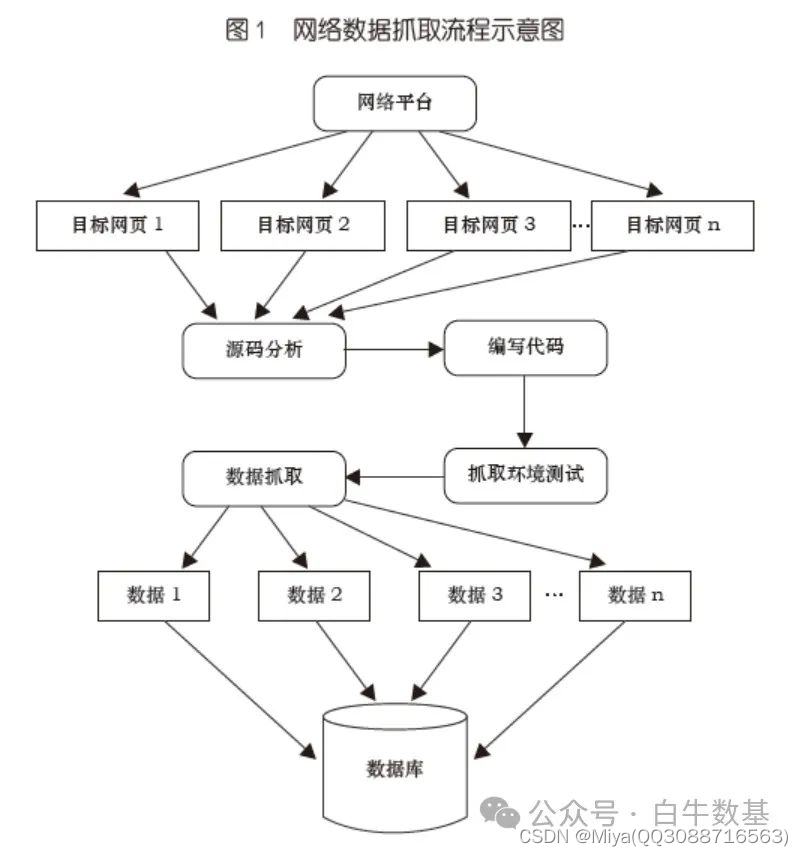
您是否曾经想同时比较多个网站上同一件商品的价格?或者自动提取您最喜欢的博客中的信息?网络抓取可以实现这一切。
在数据时代,越来越多的企业开始增加 SaaS 服务的预算,其中网络抓取作为 SaaS 服务的基本类型,为许多企业提供数据支持和便利,那么您真的了解网络抓取吗?
什么是网络抓取?
网络抓取是指使用 Octoparse 等软件从网站中提取内容和数据。在某种程度上,它是一种用于数字营销和研究等不同领域的技术,用于从网页中提取有价值的信息。
有不同的方法可以尝试获取网络数据抓取,最简单的方法是使用付费或免费的数据抓取工具,例如 Octoparse,或编写您自己的抓取代码(复杂且繁琐)。网络数据抓取使您可以获取最新且相关的数据,以便您可以改进策略并做出明智且有支持的决策。
网络抓取合法吗?
归根结底,在当今互联网时代,数据和信息非常敏感。幸运的是,互联网搜索本质上并不违法。当网站发布数据时,这些数据通常是公开的或可以自由查看,因此可以自由地“抓取”。
例如,亚马逊公布了其产品清单的价格,因此搜索价格并提取数据完全合法。此外,还有许多流行的购物应用程序和浏览器扩展程序使用网络抓取来实现此目的,以便用户知道自己获得了正确价格。
但是,并非所有网络数据都是公开的,这意味着并非所有网络数据都是合法的。当涉及到个人数据和知识产权时,“网络抓取”行为可能会变成恶意“网络抓取”,这可能会导致收到 DMCA 侵权通知等处罚。因此,Octoparse 在进行数据收集时通常只收集公开可用的数据。
什么是网络爬虫,它是如何工作的?
说到网络爬虫 (web crawler),你会想到什么?一只在蜘蛛网上爬行的蜘蛛?这正是网络爬虫所做的事情。它像蜘蛛一样在网络上爬行。
要给网络爬虫一个准确的定义,它是一种互联网机器人,也称为网络蜘蛛、自动索引器、网络机器人,它会自动扫描网络上的信息,以创建数据的索引。这个过程称为网络抓取。之所以称之为“网络爬虫”,是因为“爬虫”一词用来描述自动访问网站并通过抓取工具获取数据的行为。
网络爬虫通常由搜索引擎(如 Google 和 Yahoo)运营。最著名的网络爬虫是 Googlebot。你有没有想过是什么让搜索引擎发挥作用?有了网络爬虫,搜索引擎就可以根据用户的搜索输入,呈现相关的网页结果。
现在,您对网络爬虫是什么有了一个基本的概念。您可能还会想知道网络爬虫是如何工作的。总的来说,网络爬虫就像一个在线图书管理员,它对网站进行索引,以更新网络信息并评估网页内容的质量。
我们以搜索引擎爬虫为例。爬虫将遍历许多网页,以检查页面中的单词以及这些单词在其他地方的使用情况。爬虫将创建一个包含所有结果的大型索引。简而言之,索引是一个单词列表,以及与这些单词相关的网页。当您在某个搜索引擎中搜索“大数据”时,搜索将检查其索引,并将结果返回给您。
通过持续访问,网络爬虫可以发现新页面或 URL,更新现有页面并标记那些死链接。当网络爬虫访问某个页面时,它会查看该页面的所有内容,然后将其传输到其数据库。在捕获页面中的数据后,页面中的单词将被放入搜索引擎的索引中。您可以将索引视为一个巨大的数据库,其中包含单词以及它们在不同页面中出现的位置。
您知道,存在无数个网页,并且每天每分钟都会创建和更新许多新页面,因此您可以想象网络爬虫正在做多么艰苦的工作。因此,搜索引擎已经制定了一些有关要抓取的内容、抓取的顺序和频率等的政策。例如,定期更新的网页可能会比不经常更新的网页更频繁地被抓取。拥有所有这些规则可以帮助提高整个过程的效率,并且还有更多有关网络抓取的选项。
网络爬虫示例
每个搜索引擎都有自己的网络爬虫(或我们可以称之为数据蜘蛛)来帮助他们更新网页数据。这里有一些常见的例子:
- Bingbot 适用于 Bing
- Baiduspider 适用于百度
- Slurp Bot 适用于 Yahoo!
- DuckDuckBot 适用于 DuckDuckGo
- Yandex Bot 适用于 Yandex
网络抓取工具
在这样一个快速发展和基于数据的世界中,人们对数据有着巨大的需求。然而,并非所有人都对爬取某个网站以获取所需数据有很好的了解。在本节中,我想介绍一些有用的、功能强大的网络爬虫工具来帮助您克服它。
如果您是一名程序员或熟悉网络爬虫或网络抓取,那么开源网络爬虫可能更适合您操作。例如,Scrapy 是网络上最著名的开源网络爬虫之一,它是一个用 Python 编写的免费网络爬虫框架。

Kinsta 为我们总结了一些市场上最常见的抓取数据程序。为了改善低效的学习时间,Octoparse 推出了新的 Octoparse 101 教程,并且教程中心已经过全面更新,为新手提供更多资源和机会。如果您是网络抓取的新手,并且没有任何编码知识,那么请允许我向您介绍一个强大的网络抓取工具,即 Octoparse。
Octoparse 可以快速抓取来自不同网站的网络数据。无需编码,您可以通过非常简单的步骤将网页转换为结构化的电子表格。Octoparse 最突出的特点是任务模板和云服务。
Octoparse 为许多流行且常见的网站(如亚马逊、Instagram、Twitter、沃尔玛和 YouTube 等)集成了许多任务模板。使用这些模板,您无需设置爬虫即可获取所需数据。您只需输入要搜索的网址或关键字。然后,您只需等待数据出来即可。
此外,我们知道一些网站可能会应用严格的反抓取技术来阻止网络抓取行为。在这种情况下,Octoparse 云服务是一个不错的解决方案。使用 Octoparse 云服务,您可以使用我们的自动 IP 轮换功能来运行任务,以最大程度地降低被阻止的可能性。此外,您可以将爬虫程序设置为在预定时间运行,这样您就无需监视整个抓取过程。Octoparse 是一款不错的工具,因此,如果您有网络抓取需求,您应该点击此处进行试用。
结论
总之,网络抓取在互联网时代发挥着非常重要的作用。如果没有网络爬虫,你无法想象在信息海洋中找到想要的信息是多么困难。