本文旨在对高飞老师移动机器人规划课程做学习记录,方便日后回顾。
(1)图搜索基础
(2)Dijstra和A*算法
(3)JPS
(4)作业
1 图搜索基础
1.1 配置空间(Configuration pace)
Robot configuration: 对机器人上所有点的描述
Robot degree of freedom (DOF): 表示机器人配置所需的最小坐标数
Robot configuration space: 一个包含所有可能机器人配置的n维空间,记为C空间
每个机器人姿势都是C空间中的一个点
配置空间障碍
在工作空间Planning
机器人具有不同的形状和大小,碰撞检测需要了解机器人的几何形状,这样的话耗时、困难
在配置空间Planning
(1)机器人在C空间由一个点来表示,例如位置( R 3 R^3 R3中的一个点),姿态( S O ( 3 ) SO(3) SO(3)中的一个点)
(2)障碍物需要在配置空间中表示,运动规划前的一次性工作,成为配置空间障碍物(C-obstacle)
(3)C-space = (C-obstacle) U (C-free)
(4)路径规划是在C-free中寻找起点 q s t a r t q_{start} qstart和终点 g g o a l g_{goal} ggoal

工作空间和配置空间障碍物
(1)在工作空间
机器人有形状和大小,但难以运动规划
(2)在配置空间:C-space
机器人是一个点(易于运动规划)
在运动规划之前,障碍物在C空间中表示
(3)在C-space中表示障碍物可能非常复杂,因此,近似的表示经常在实践中使用

如果保守地将机器人建模为半径为 δ r \delta_r δr的球,则可以通过在障碍物上各个方向膨胀 δ r \delta_r δr来构造C空间
1.2 图搜索方法

状态空间图:一种搜索算法的数学表示

(1)对于每个搜索问题,都有一个对应的状态空间图
(2)图中节点之间的连通性由(有向或无向)边表示

1.3 图搜索概述
搜索始终从起始状态 X S X_S XS开始

(1)搜索图会产生一个搜索树
(2)回溯搜索树中的一个节点会给我们一条从起始状态到该节点的路径
(3)对于许多问题,我们永远无法真正构建整个树,因为它太大或效率低下-我们只想尽快到达目标节点。
维护一个容器来存储所有要访问的节点
容器初始化为起始状态 X S X_S XS
开始循环:
(1)移除:根据一些预定义的评分函数从容器中删除一个节点
(2)扩展:获取节点的所有邻居
(3)Push:把这些邻居推到容器里
结束循环
Tip:
(1)结束循环:可能的选项:当容器为空时结束循环
(2)如果图是循环的:当一个节点从容器中移除(展开/访问)时,它不应该再被添加回容器中
(3)以何种方式删除正确的节点,使目标状态可以尽快达到,从而导致图节点的扩展较少
1.4 图遍历
BFS VS DFS
BFS使用先进先出的队列,DFS使用后进先出的栈

深度优先搜索 DFS
1.策略:移除/扩展容器中最深的节点

2.实现:维护后进先出容器(stack)

(1)初始化容器
(2)移除具有最大树级别的节点
(3)扩展
(4)将扩展节点的子节点添加到容器中
(5)删除具有最大树级别的节点
广度优先搜索 BFS
1.策略:移除/扩展容器中最浅的节点

2.实现:维护先进先出容器(队列queue)

(1)初始化容器
(2)删除具有最小树级别的节点
(3)扩展
(4)将扩展节点的子节点添加到容器中
(5)删除具有最小树级别的节点
1.5 启发式搜索
贪心BFS
Greedy Best First根据某种规则(称为启发式规则)选择“最佳”节点。
定义:启发式是离目标有多近的猜测
(1)启发式指引正确的方向
(2)启发式算法应该易于计算

1.6 行为代价(一个节点到另一个节点需要的代价)
一个实际的搜索问题有一个成本“C”:从一个节点到它的邻居
当所有的权重都为1时,BFS找到最优解
对于一般的情况,如何找到最少成本的路径?(A* / Dijstra)

2 Dijkstra和A*
2.1 Dijstra算法
策略:扩展/访问累积成本最低的节点 g ( n ) g(n) g(n)
g ( n ) g(n) g(n):从起始状态到节点“n”的累积成本的当前最佳估计
保证已扩展/访问的节点从开始状态起具有最小的成本

算法流程:
(1)维护优先级队列存储所有要扩展的节点
(2)优先级队列以起始状态 X S X_S XS初始化
(3)对于图中的其他节点: g ( X S ) = 0 g(X_S)=0 g(XS)=0, g ( n ) = ∞ g(n)=\infty g(n)=∞
(4)开始循环
- 如果队列空,返回false;break;
- 从优先级队列中删除具有最低 g ( n ) g(n) g(n)的节点“n”
- 标记节点n为已展开
- 如果节点n是目标状态,则返回True;break;
- 对于节点n所有未扩展的邻居m(遍历)
- 如果 g ( m ) = ∞ g(m)=\infty g(m)=∞
- g ( m ) = g ( n ) + C n m g(m)=g(n)+C_{nm} g(m)=g(n)+Cnm
- 将节点 m m mpush到队列里
- 如果 g ( m ) > g ( n ) + C n m g(m)>g(n)+C_{nm} g(m)>g(n)+Cnm
- g(m)=g(n)+C_{nm}
(5)结束循环

2.2 Dijkstra算法的优缺点
好处:完备和最优性
坏处:
(1)只能看到到目前为止累积的成本(即统一成本),在每个“方向”上探索下一个状态
(2)没有关于目标位置的信息

2.3 启发式搜索
回顾Greedy Best First Search中引入的启发式算法
(1)通过推断目标的最小成本(即目标成本)来克服统一成本搜索的缺点
(2)专为特定搜索问题而设计
例子:曼哈顿距离和欧几里得距离

2.4 A*:Dijstra算法上面加上启发式
累积成本:
g ( n ) g(n) g(n):从起始状态到节点n的累积成本的当前最佳估计
启发式成本:
h ( n ) h(n) h(n):从节点n到目标状态的估计最小成本(即目标成本)
通过节点n从起始状态到目标状态的最小估计成本为f(n)=g(n)+h(n)
策略:扩展成本 f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n)最小的节点
(1)更新节点n所有未扩展邻居 m m m的累积成本 g ( m ) g(m) g(m)
(2)已扩展的节点保证从起始状态开始具有最小的成本
2.5 A*算法流程
算法流程:
(1)维护优先级队列存储所有要扩展的节点
(2)所有节点的启发式函数 h ( n ) h(n) h(n)是预定义的
(2)优先级队列以起始状态 X S X_S XS初始化
(3)对于图中的其他节点: g ( X S ) = 0 g(X_S)=0 g(XS)=0, g ( n ) = ∞ g(n)=\infty g(n)=∞
(4)开始循环
- 如果队列空,返回false;break;
- 从优先级队列中删除具有最低成本 f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n)的节点“n”
- 标记节点n为已展开
- 如果节点n是目标状态,则返回True;break;
- 对于节点n所有未扩展的邻居m(遍历)
- 如果 g ( m ) = ∞ g(m)=\infty g(m)=∞
- g ( m ) = g ( n ) + C n m g(m)=g(n)+C_{nm} g(m)=g(n)+Cnm
- 将节点 m m mpush到队列里
- 如果 g ( m ) > g ( n ) + C n m g(m)>g(n)+C_{nm} g(m)>g(n)+Cnm
- g(m)=g(n)+C_{nm}
优先级队列:open_list
没有被扩展的节点,对它进行更新,发现它加入到open_list;已经扩展过的节点放到close_list中
(5)结束循环

2.6 A* 最优性

启发式函数 h ( n ) < c o s t ( n , g o a l ) h ( n ) < c o s t ( n , g o a l ) h(n)<cost(n,goal)
只要启发式函数提供了小于实际成本的估计,A*将始终找到最优路径,并且通常比Dijstra快
可允许的启发式

启发式函数设计
一个可接受的启发式函数必须慎重设计

2.7 Dijkstra VS A*
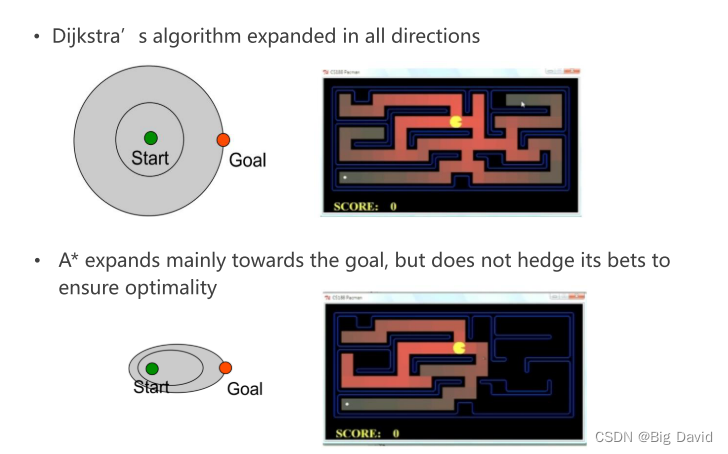
2.8 次优解
如果我们打算使用高估启发式

接受一个次优的结果,但是会更快。这种算法就叫做权重A*
权重A*:
(1)用最优性换取了速度
(2) ε − \varepsilon- ε−次优, c o s t ( s o l u t i o n ) < = ε c o s t ( o p t i m a l s o l u t i o n ) cost(solution)<=\varepsilon cost(optimal solution) cost(solution)<=εcost(optimalsolution)
(3)相比A*可能速度上有几十倍的提升
2.9 Greedy Best First Search vs. Weighted A* vs. A*

3 工程上面的考虑
3.1 基于网格的路径搜索
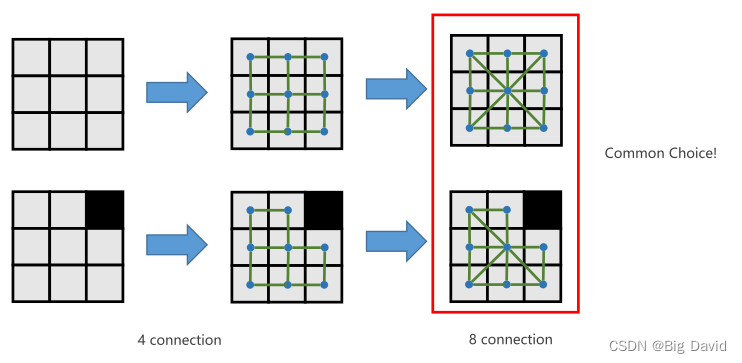
3.2 实现
(1)创建一个密集图
(2)连接存储在网格地图中的占用状态
(3)通过网格索引发现邻居
(4)A*搜索
C++中的优先级队列
• std::priority_queue
• std::make_heap
• std::multimap
3.3 最佳启发式

它们都是有用的,但没有一个是最好的选择,为什么?
因为他们都不tight,tight意味着靠近真正的最短距离

如图所示欧氏距离的启发式函数,为什么扩展了如此多的节点,就是因为欧式距离离真正的理论最优解还很远。
如何得到真正的理论最优解?,幸运的是,The grid map是高度结构化的。
不需要搜索路径;它有闭式解!
dx = abs(node.x - goal.x);
dy = abs(node.y - goal.y);
h = (dx + dy) + (sqrt(2)- 2) * min(dx, dy);

3.4 Tie Breaker
许多路径有相同的f值;
他们之间没有差异,使得他们被A*平等地搜索。
(1)操作 f f f值打破僵局
(2)使相同的f值不同
(3)稍微干涉一下h值
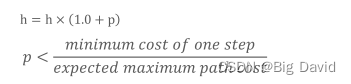

Tie Breaker的核心观点:在相同成本的path中找到首选项
(1)如果节点有同样的f,比较他们的h
(2)添加确定性随机数到启发式或边界成本(A hash of the coordinates)
(3)最好选择从起点到终点的沿着直线的路径

右图是最短的路径,但对轨迹生成(平滑)有害。

(4)其他定制方式
一个比较系统打破路径平衡解决问题的方法:跳点搜索JPS
4 JPS
系统性彻底消除对称性路径的方法
核心思想:找到路径中的对称性,并且打破它。

JPS智能地探索,因为它总是基于规则向前看。
4.1 预瞄规则
根据父节点来的方向以及障碍物存在的位置,智能判断哪些节点需要扩展哪些不需要扩展
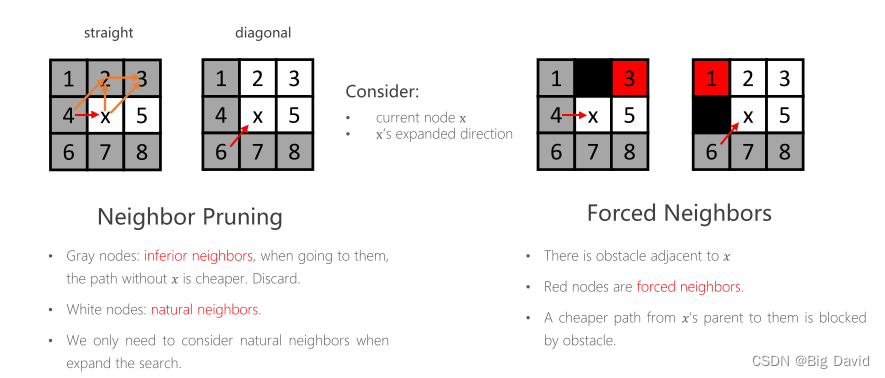
(1)灰色节点:劣邻居,当去他们的时候,没有x会更加便宜,丢弃他们
(2)白色节点:自然邻居
(3)在扩展搜索时,我们只需要考虑自然邻居。
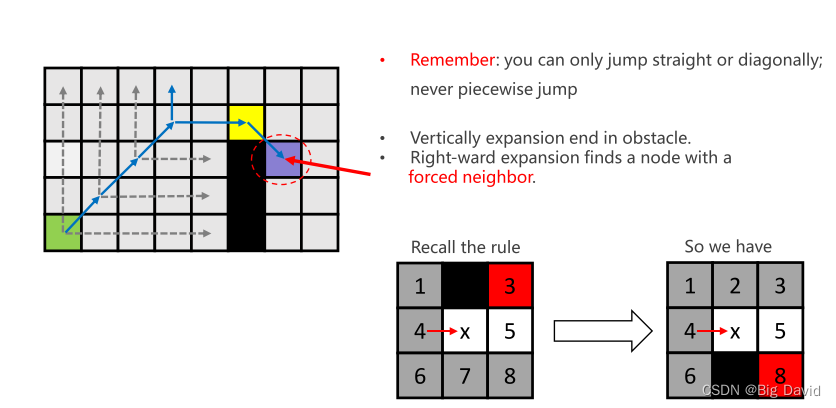
(4)如果附近有障碍物,红色节点就是强制邻居
比如上图左侧的九宫格中,灰色的叫做劣性节点,放弃扩展,因为这些节点“从父节点出发走到该节点的路径会小于等于(straight情况是小于等于、diagonal情况是小于)经过x再到该节点走的路径的长度”,因此就没有必要从父节点经过x节点再到这些劣性节点的位置。特别地,如果存在障碍物,如上图右侧的九宫格中的黑色格子,某些节点(红色,强迫邻居)会因为障碍物变为也需要考虑扩展的节点。
4.2 跳跃规则

其实就是递归地执行上述的look ahead rule,在各个“跳跃点”之间的节点被忽略,
跳跃点的判定:
(1)如果点 y 是起点或目标点,则 y 是跳点
(2)如果 y 有邻居且是强迫邻居则 y 是跳点,从上文强迫邻居的定义来看 neighbor 是强迫邻居,current 是跳点,二者的关系是伴生的
(3)如果 parent到 y 是对角线移动,并且 y 经过水平或垂直方向移动可以到达跳点,则 y 是跳点。(不会出现折线跳跃)
Tip:
注意对每一个节点判断时一定是先straight在diagonal,straight如果撞到边界或墙之前没有跳点的话就转而去diagonal jump,如上图最右侧的地图中,从出发点出发,找到x后,出发点弹出,x是第一个跳点,因为有w这个强制邻居(w也是跳点),而后y是跳点(父节点对角线移动到y,y可以水平移动到z,z有强制邻居)。至此,x被弹出,进入close list。
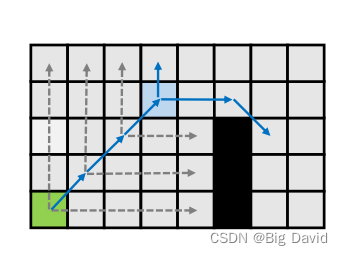
4.3 JPS
绿色是出发点,沿对角线到蓝色格子,蓝色格子经过水平跳跃后可以到特殊点,所以蓝色格子是跳点,放入open list,绿色点弹出,进入close list
(1)横向和纵向扩展;
(2)两次跳跃都以障碍物结束;
(3)沿对角线移动
下面是完整的探索过程,所有带颜色的格子都是加入openlist的节点
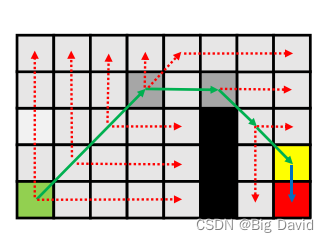

算法流程和A大差不差,只是A找的是几何上的邻居,JPS找的是上述的后继跳点。扩展到3D,原理是一样的,只是进行维度上的扩展
Planning Dynamically Feasible Trajectories for Quadrotors using Safe Flight Corridors in 3-D Complex Environments, Sikang Liu, RAL 2017
JPS的缺陷:
正常情况下,JPS都会比A*更高效,因为省略了两个跳点之间的很多点,不必加入到open_list。但是,在很大的地图中很少的障碍物的情况,JPS甚至会比 A *慢很多倍,原因就是在进行水平、垂直的跳点搜索时,每一个都要判断撞到障碍物或者边界才结束,而边界又很远。而且JPS只能用于uniform grid map,对于更广义的图来讲,A *是可以的,但是JPS就不行了。
详细JPS算法参考知乎:
基于图搜索的方法 - JPS跳点搜索算法
github.com/silmerusse/fudge_pathfinding