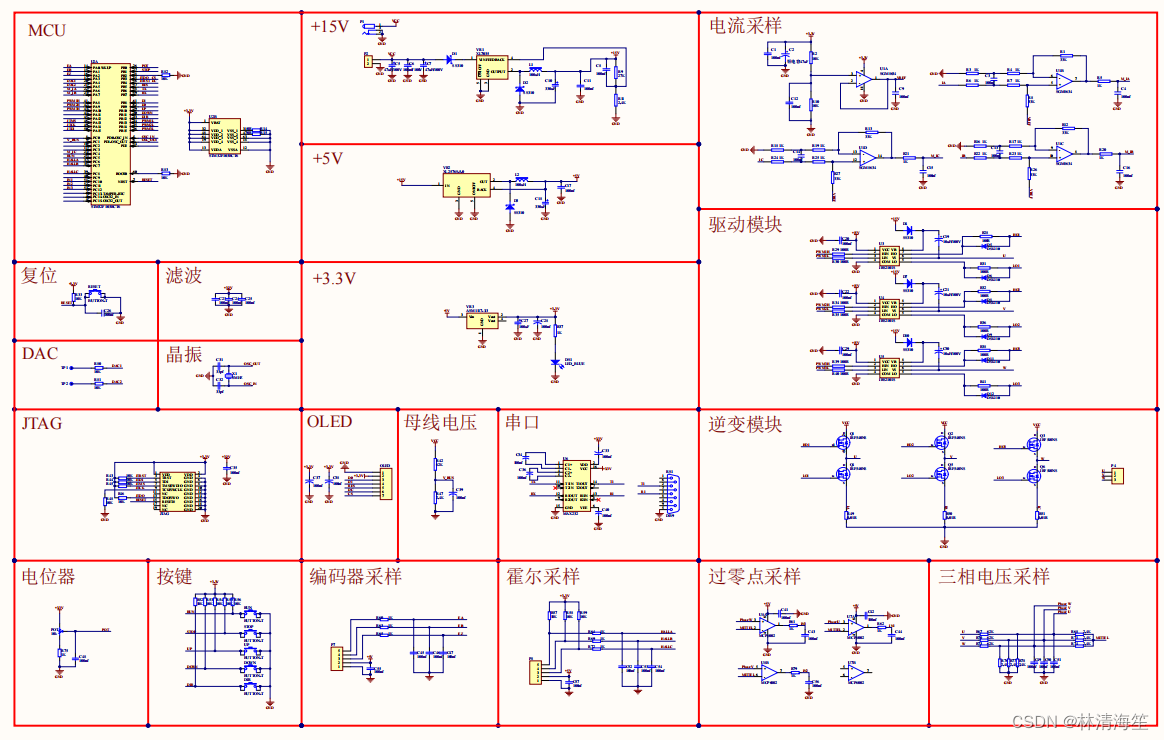
Rust防范“内存不安全”代码的原则极其清晰明了。
如果你对同一块内存存在多个引用,就不要试图对这块内存做修改;如果你需要对一块内存做修改,就不要同时保留多个引用。
只要保证了这个原则,我们就可以保证内存安全。
它在实践中发挥了强大的作用,可以帮助我们尽早发现问题。这个原则是Rust的立身之本、生命之基、活力之源。
这个原则是没问题的,但是,初始的实现版本有一个主要问题,那就是它让借用指针的生命周期规则与普通对象的生命周期规则一样,是按作用域来确定的。
所有的变量、借用的生命周期就是从它的声明开始,到当前整个语句块结束。
这个设计被称为Lexical Lifetime,因为生命周期是严格和词法中的作用域范围绑定的。
这个策略实现起来非常简单,但它可能过于保守了,某些情况下借用的范围被过度拉长了,以至于某些实质上是安全的代码也被阻止了。
在某些场景下,限制了程序员的发挥。
因此,Rust核心组又决定引入Non Lexical Lifetime,用更精细的手段调节借用真正起作用的范围。
这就是NLL。
NLL希望解决的问题
首先,我们来看几个简单的示例。

这段代码是没有问题的。我们的关注点是foo()这个函数,它在调用capitalize函数的时候,创建了一个临时的&mut型引用,在它的调用结束后,这个临时的借用就终止了,因此,后面我们就可以再用data去修改数据。
注意,这个临时的&mut引用存在的时间很短,函数调用结束,它的生命周期就结束了。
但是,如果我们把这段代码稍作修改,问题就出现了:
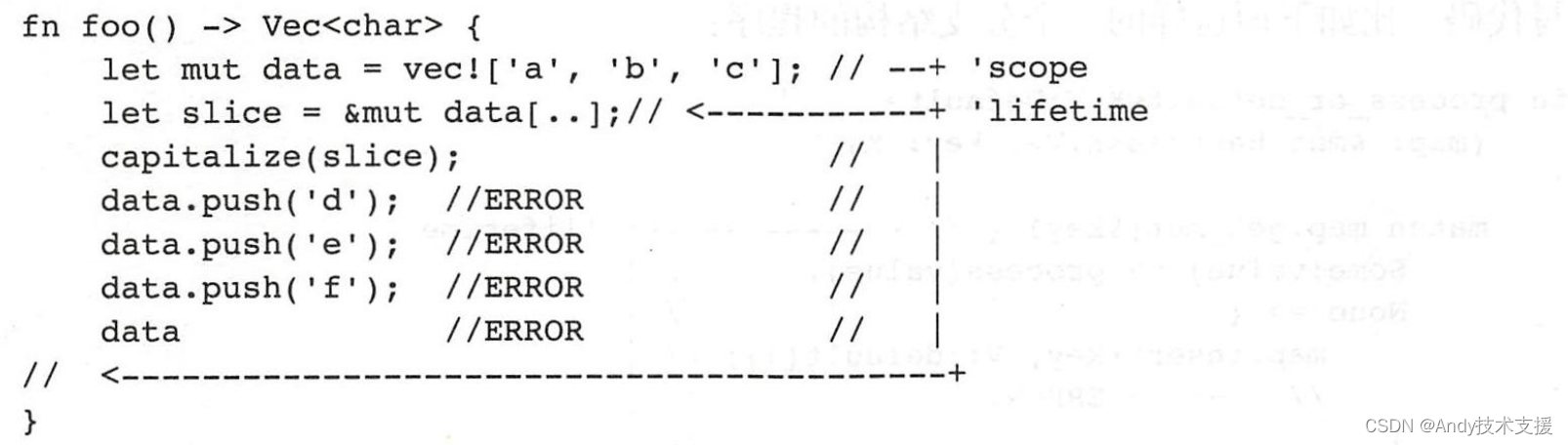
在这段代码中,我们创建了一个临时变量slice,保存了一个指向data的smut型引用,然后再调用capitalize函数,就出问题了。编译器提示为:
error[E0499]:cannot borrow `data’as mutable more than once at a time
这是因为,Rust规定“共享不可变,可变不共享”,同时出现两个&mut型借用是违反规则的。
在编译器报错的地方,编译器认为slice依然存在,然而又使用data去调用fnpush(&mut self,value:T)方法,必然又会产生一个&mut型借用,这违反了Rust的原则。
在目前这个版本中,如果我们要修复这个问题,只能这样做:

我们手动创建了一个代码块,让slice在这个子代码块中创建,后面就不会产生生命周期冲突问题了。
这是因为,在早期的编译器内部实现里面,所有的变量,包括引用,它们的生命周期都是从声明的地方开始,到当前语句块结束(不考虑所有权转移的情况)。
这样的实现方式意味着每个引用的生命周期都是跟代码块(scope)相关联的,它总是从声明的时候被创建,在退出这个代码块的时候被销毁,因此可以称为Lexical lifetime。
而所说的Non-Lexical lifetime,意思就是取消这个关联性,引用的生命周期,我们用另外的、更智能的方式分析。
有了这个功能,上例中手动加入的代码块就不需要了,编译器应该能自动分析出来,slice这个引用在capitalize函数调用后就再没有被使用过了,它的生命周期完全可以就此终止,不会对程序的正确性有任何影响,后面再调用push方法修改数据,其实跟前面的slice并没有什么冲突关系。
看了上面这个例子,可能有人还会觉得,显式的用一个代码块来规定局部变量的生命周期是个更好的选择,Non-Lexical-Lifetime的意义似乎并不大。
那我们再继续看看更复杂的例子。我们可以发现,Non-Lexical-Lifetime可以打开更多的可能性,让用户有机会用更直观的方式写代码。比如下面这样的一个分支结构的程序:
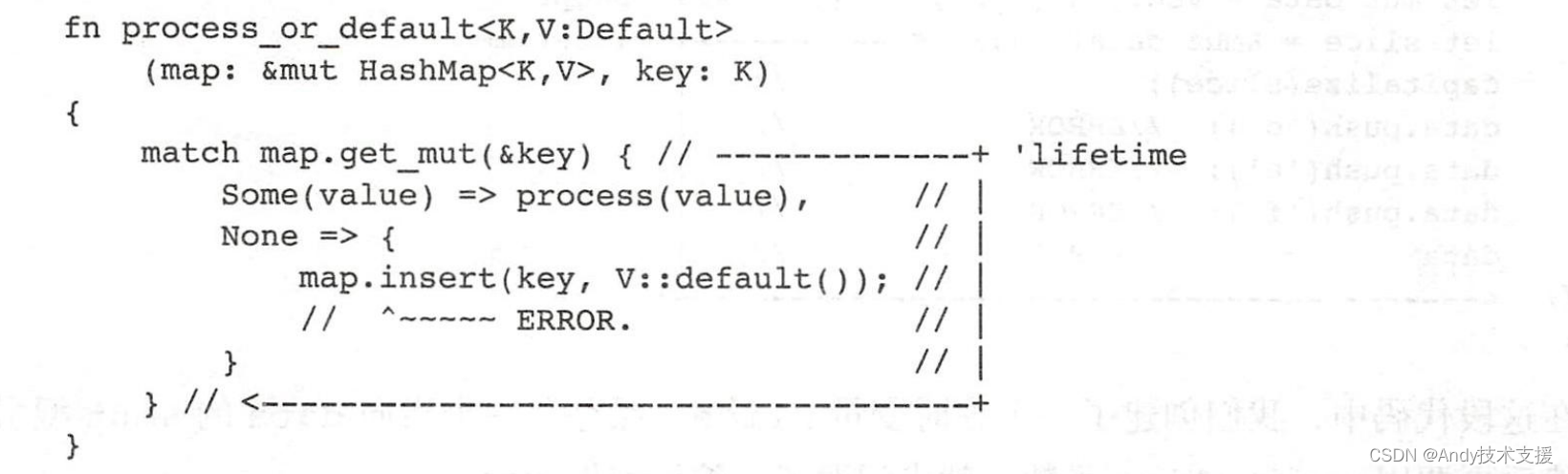
这段代码从一个HashMap中查询某个key是否存在。
如果存在,就继续处理,如果不存在,就插入一个新的值。
目前这段代码是编译不过的,因为编译器会认为在调用getmut(&key)的时候,产生了一个指向map的amut型引用,而且它的返回值也包含了一个引用,返回值的生命周期是和参数的生命周期一致的。
这个方法的返回值会一直存在于整个match语句块中,所以编译器判定,针对map的引用也是一直存在于整个match语句块中的。
于是后面调用insert方法会发生冲突。
当然,如果我们从逻辑上来理解这段代码,就会知道,这段代码其实是安全的。
因为在None分支,意味着map中没有找到这个key,在这条路径上自然也没有指向map的引用存在。
但是可惜,在老版本的编译器上,如果我们希望让这段代码编译通过,只能绕一下。我们试一下做如下的修复:

实际上这个改动依然会编译失败。
原因就在于return语句,get_mut时候对map的借用传递给了Some(value),在Some这个分支内存在一个引用,指向map的某个部分,而我们又把value返回了,这意味着编译器认为,这个借用从match开始一直到退出这个函数都存在。因此后面的insert调用依然发生了冲突。
接下来我们再做一次修复:

这次的区别在于,get_mut发生在一个子语句块中。
在这种情况下,编译器会认为这个借用跟if外面的代码没什么关系。
通过这种方式,我们终于绕过了borrow checker。
但是,为了绕过编译器的限制,我们付出了一些代价。
这段代码,我们需要执行两次hash查找,一次在contains方法,一次在get_mut方法,因此它有额外的性能开销。
这也是为什么标准库中的HashMap设计了一个叫作entry的api,如果用entry来写这段逻辑,可以这么做:

这个设计既清晰简洁,也没有额外的性能开销,而且不需要Non-Lexical-Lifetime的支持。
这说明,虽然老版本的生命周期检查确实有点过于严格,但至少在某些场景下,我们其实还是有办法绕过去的,不一定要在“良好的抽象”和“安全性”之间做选择。
但是它付出了其他的代价,那就是设计难度更高,更不容易被掌握。
标准库中的entry API也是很多高手经过很长时间才最终设计出来的产物。
对于普通用户而言,如果在其他场景下出现了类似的冲突,恐怕大部分人都没有能力想到一个最佳方案,可以既避过编译器限制,又不损失性能。
所以在实践中的很多场景下,普通用户做不到“零开销抽象”。
让编译器能更准确地分析借用指针的生命周期,不要简单地与scope相绑定,不论对普通用户还是高阶用户都是一个更合理、更有用的功能。如果编译器能有这么聪明,那么它应该能理解下面这段代码其实是安全的:
 这段代码既符合用户直观思维模式,又没有破坏Rust的安全原则。
这段代码既符合用户直观思维模式,又没有破坏Rust的安全原则。
以前的编译器无法编译通过,实际上是对正确程序的误伤,是一种应该修复的缺陷。
NLL的设计目的就是让Rust的安全检查更加准确,减少误报,使得编译器对程序员的掣肘更少。
打开NLL功能,以下代码就可以编译通过了:

NLL的原理
NLL的设计目的是让“借用”的生命周期不要过长,适可而止,避免不必要的编译错误,把实际上正确的代码也一起拒绝掉。
但是实现方法不能是简单地在AST上找以下某个引用最后一次在哪里使用,就让它的生命周期结束算了。
我们用例子来说明:

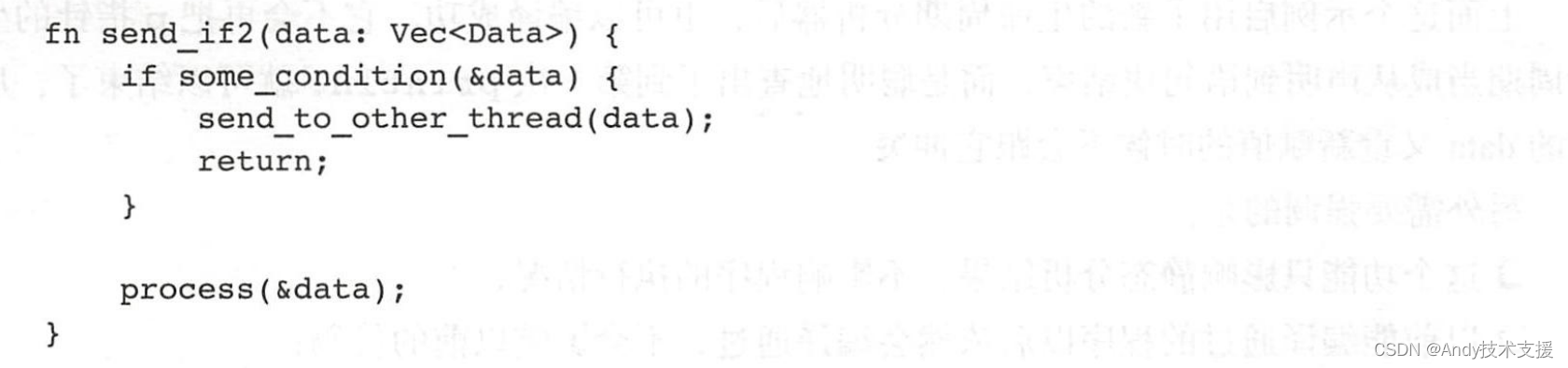
在这个示例中,我们引入了一个循环结构。如果我们只是分析AST的结构的话,很可能会觉得capitalize函数结束后,slice的生命周期就结束了,因此data.push()方法调用是合理的。
但这个结论是错误的,因为这里有一个循环结构。大家想想看,如果执行了push()方法后,引发了vec数据结构的扩容,它把以前的空间释放掉,申请了新的空间,进入下一轮循环的时候,slice就会指向一个非法地址,会出现内存不安全。
以上这段代码理应出现编译错误。
因此,新版本的借用检查器将不再基于AST的语句块来设计,而是将AST转换为另外一种中间表达形式MIR(middle-level intermediate representation)之后,在MIR的基础上做分析。
这是因为前面已经分析过了,对于复杂一点的程序逻辑,基于AST来做生命周期分析是费力不讨好的事情,而MIR则更适合做这种分析。
可以用以下编译器命令打印出MIR的文本格式:
rustc --emit=mir test.rs
不过在一般情况下,MIR在编译器内部的表现形式是内存中的一组数据结构。
这些数据结构描述的是一个叫作“控制流图”(control flow graph)的概念。
所谓控制流图,就是用“图”这种数据结构,描述程序的执行流程。每个函数都有一个MIR来描述它,比如对于以下这段代码:
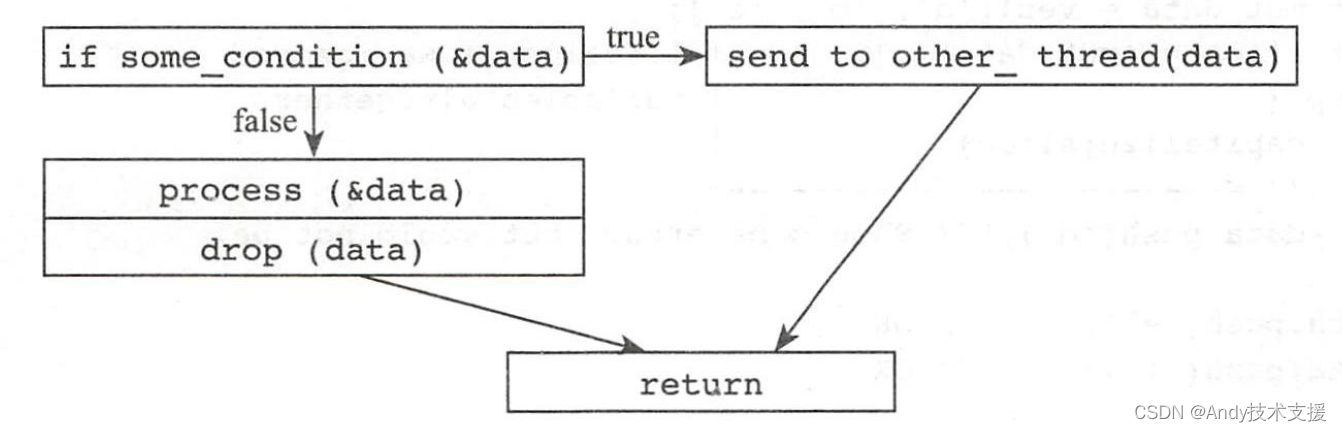
图上面有节点,也有边。节点代表一条或者一组语句,边代表分支跳转。有了这个图,引用的生命周期就可以用这个图上的节点来表示了。
编译器最后会分析出来,引用在这个图上的哪些节点上还是活着的,在哪些节点上可以看作已经死掉了。
相比于以前,一个引用的生命周期直接充满整个语句块,现在的表达方式明显要精细得多,这样我们就可以保证引用的生命周期不会被过分拉长。
这个新版的借用分析器,会允许下面的代码编译成功,比如:

另外需要强调的是:
- 这个功能只影响静态分析结果,不影响程序的执行情况;
- 以前能编译通过的程序以后依然会编译通过,不会影响以前的代码;
- 它依然保证了安全性,只是将以前过于保守的检查规则适当放宽;
- 它依赖的依然是静态检查规则,不会涉及任何动态检查规则;
- 它只影响“引用类型”的生命周期,不影响“对象”的生命周期,即维持现有的析构。
- 它不会影响RAⅡ语义。