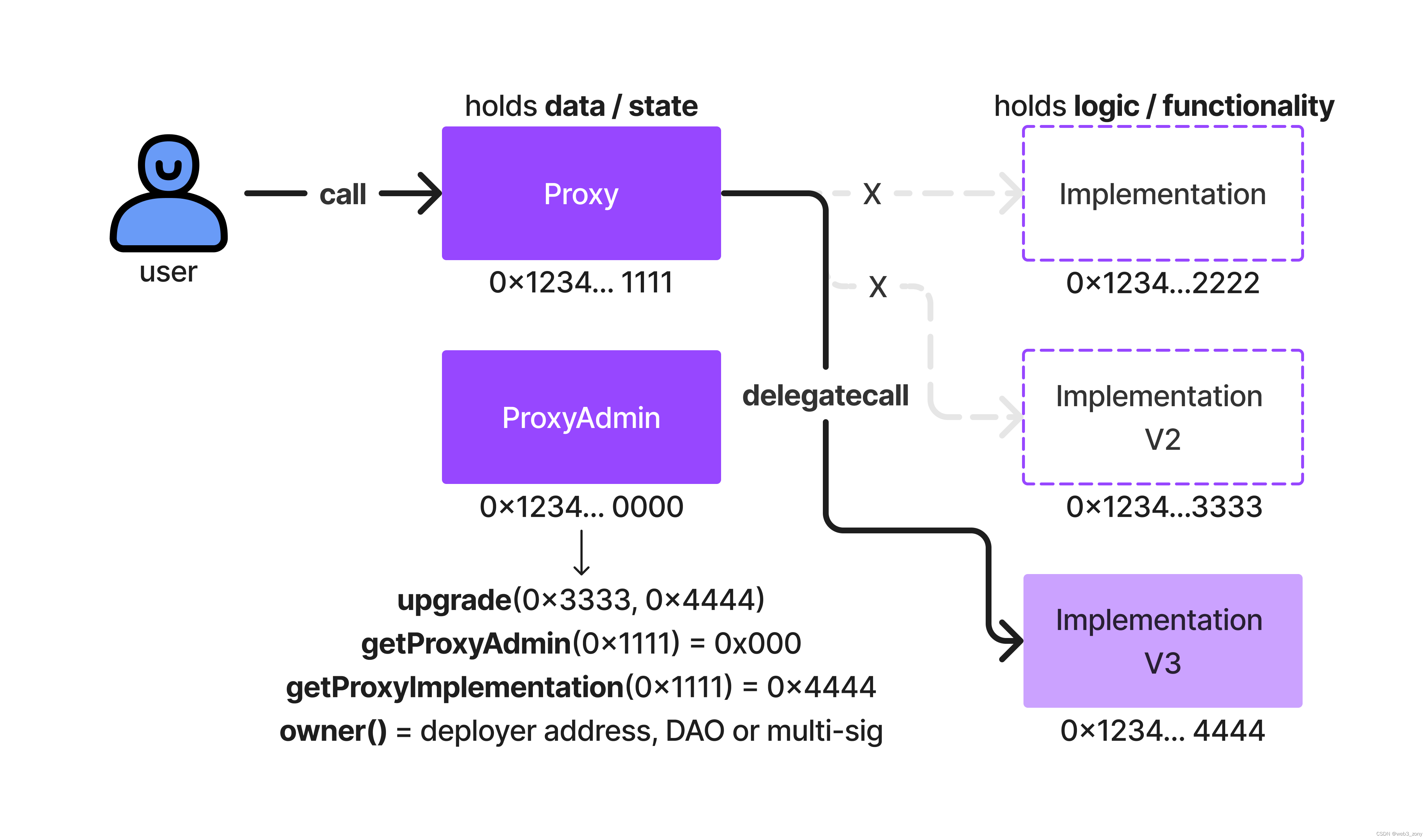
AutoGPTQ的工作原理具体如下:
一.量化技术:
通过量化技术,将模型中的浮点数参数转换为低精度的整数,从而减少模型大小和推理时间。例如把权重为F32(单精度浮点数)映射为Int4(4字节整数)。
常见的量化方法:
线性量化: 定义一个量化范围和一个量化步长(scale factor),将浮点数减去最小值(对于非对称量化,可能还要加上偏移量),然后除以量化步长,得到的结果向下取整即得到相应的整数值。
二.知识蒸馏:
大型复杂模型(被称为“教师模型”,Teacher Model)中的知识转移给小型简洁模型(被称为“学生模型”,Student Model),从而使学生模型在保持或接近教师模型性能的同时,拥有更小的模型体积和更快的运算速度。
具体过程:
使用教师模型对训练集进行前向传播(实际上就是输入一次训练集),并记录下softmax后的输出概率分布。
让学生模型在同一训练集上进行训练,除了常规的交叉熵损失外,还添加一项额外的损失项,该损失项基于学生模型的输出与教师模型的软目标之间的差异。
通过联合优化这两项损失,学生模型逐渐逼近教师模型的预测行为。
此外,知识蒸馏还可以扩展到特征级别的蒸馏,即不仅匹配输出的概率分布,还可以让学生模型学习模仿教师模型内部某几层的特征表示
三.直方图方法:
在量化过程中,采用直方图方法来估计低精度权重的分布。这种方法通过对浮点数权重进行直方图统计,将权重分为多个区间,每个区间对应一个低精度值。
计算过程:
- 直方图计算: 在准备量化模型时,会首先收集训练或校准数据集中每个层的权重值的分布,通过计算每个值出现的频率来构建直方图。直方图反映了数据,在整个数值范围内的分布状况。
- 量化边界确定: 根据直方图确定量化区间的边界(量化bins)。
- 量化映射: 利用直方图统计信息,确定量化表(LUT),该表提供了从浮点值到整数表示的映射关系。在量化过程中,每个浮点数会被映射到与其最接近的,量化边界所对应的整数值上。
- 饱和度处理: 对于超出量化范围的极端值,需要采取特定策略处理,如截断(clipping)、溢出保护或者其他饱和度处理机制,以防止量化过程中的信息丢失过大。
四.梯度下降:
使用梯度下降方法优化超参数,以最小化量化误差并提高模型性能。