“SkipList 的索引过程,能否越两级搜索?”
昨天,一个工作 7 年的粉丝,去某外包公司面试,被问到这个问题不知道该怎么回答。
今天正好有空,给大家分享一下这个问题的回答思路。
对了,这个问题在我之前整理的 50 万字的大厂面试指南 里面,有标准的回答,大家可以去文章结尾中领取。
一、问题解析
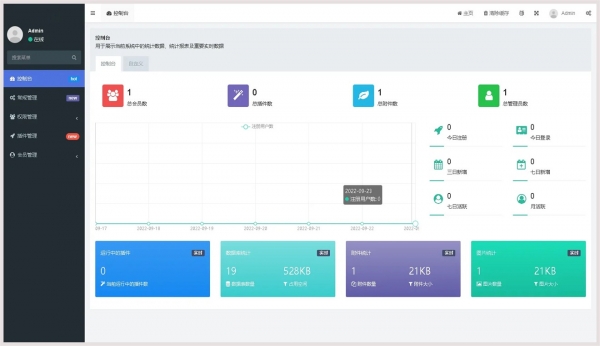
SkipList,很多人可能没听过,它还有另外一个名字叫跳跃表(如图)。
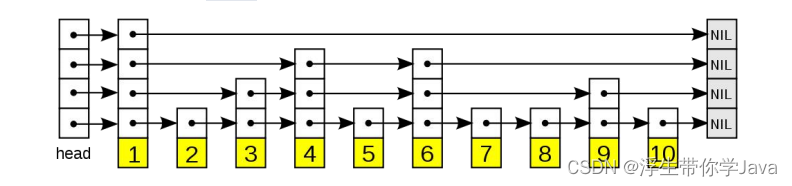
跳跃表主要由以下部分构成:
表头(head):负责维护跳跃表的节点指针。
跳跃表节点:保存着元素值,以及多个层。
层:保存着指向其他元素的指针。
高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。
表尾:全部由 NULL 组成,表示跳跃表的末尾。
我这样说,大家理解起来觉得有点复杂,简单来说,就是在一个链表的基础上,增加了多层索引,这个层数是随机的。每一层索引都是原始链表的一个子集,并且索引元素的间隔逐层增大,这样就可以在较高的层级上进行快速搜索,从而减少搜索的时间复杂度。
比如,在(如图)这样一个跳跃表中,想要查找 88 这个数字的位置,它可以通过逐层跳跃快速找到,相比于链表来说,查找性能要快很多。

理解了这样一个背景,再来看一下这个问题的回答。
二、问题总结
在一般情况下,跳表的查找过程,是从最高层开始逐层向下查找的,每次查找都是在当 前层中找到小于目标元素的最大元素,然后跳转到下一层,继续进行查找。如果最后找到了目标元素,就返回这个元素所在的节点,否则返回空。所以,对于跳跃表中的索引过程,并没有直接跳跃两层检索的情况,也是逐层进行判断最终获得查找的结果。
以上就是我的理解。
三、粉丝福利
最近很多同学问我有没有java学习资料,我根据我从小白到架构师多年的学习经验整理出来了一份50W字面试解析文档、简历模板、学习路线图、java必看学习书籍 、 需要的小伙伴 可以关注我
公众号:“ 灰灰聊架构 ”, 回复暗号:“ 321 ”即可获取