使用介绍
Hazelcast是一个开源的分布式数据结构库,主要用于在Java应用程序中提供高可用性、数据分布、缓存等功能。它支持多种分布式数据结构,如分布式映射、分布式队列、分布式缓存等。
Hazelcast的历史可以追溯到2011年,当时它作为一个开源项目在GitHub上发布。Hazelcast是由一群志愿者创建的,他们希望开发一个高性能、可扩展的分布式内存数据库,以满足他们在构建应用程序时对内存存储和分布式计算的需求。
从那时起,Hazelcast一直作为一个开源项目不断发展。它的核心开发团队一直在积极维护和改进项目,同时也有许多社区贡献者为其做出贡献。随着时间的推移,Hazelcast的功能和性能得到了不断增强和优化,同时它也吸引了越来越多的用户和公司使用它作为其应用程序的基础。
目前,Hazelcast已经成为一个流行的开源项目,被广泛应用于各种行业和场景,包括缓存、数据网格、分布式计算等。它被许多知名的公司和组织所采用,如Nissan、JPMorgan、Tmobile等。
在发展过程中,Hazelcast一直秉承着开放、社区驱动的价值观,与用户和社区紧密合作,共同推动其发展。未来,随着云计算、大数据和微服务技术的不断发展,Hazelcast有望继续发挥其分布式内存计算的优势,为更多的应用程序提供高性能、可扩展的解决方案。
以下是Hazelcast的一些主要特性和应用场景:
- 分布式数据结构:支持多种分布式数据结构,如分布式映射、分布式队列、分布式缓存等。
- 高可用性:利用自我组织网络构建分布式集群,以实现高可用性。
- 数据复制:支持数据复制,以保证数据安全。
- 自动扩展:支持自动扩展,以适应动态数据增长。
- 多语言支持:支持多种语言,如Java、C++、.NET等。
- 简单易用:提供简单易用的API,以方便开发人员使用。
- 可扩展性:支持插件扩展,以适应多种特定需求。
- 社区支持:拥有广泛的社区支持,以帮助开发人员解决问题。
主要优缺点
Hazelcast是一个高性能、可扩展的分布式数据结构库,主要用于在Java应用程序中提供高可用性、数据分布、缓存等功能。以下是Hazelcast的一些优点:
- 高性能:Hazelcast基于内存存储数据,提供快速的数据访问速度。它还支持分布式计算,可以在集群中进行并行处理,提高应用程序的性能。
- 高可靠性:Hazelcast使用分布式复制和故障转移机制,确保数据的可靠性和高可用性。它具有自动故障检测和恢复机制,可以在节点故障时自动迁移数据和任务。
- 可扩展性:Hazelcast可以方便地进行水平扩展,通过添加更多的节点来增加集群的处理能力。它支持动态添加和移除节点,而无需停止应用程序。
- 多语言支持:Hazelcast不仅仅支持Java,还支持C++、.NET、Python、Go等多种编程语言。
- 模块化设计:Hazelcast拆分成多个模块,可以根据需要选择需要的模块,避免不必要的资源浪费。
Hazelcast也存在一些缺点:
序列化方案:Hazelcast的序列化方案需要实现一个特定接口,这可能会增加开发人员的工作量。
数据迁移问题:当集群里有一个应用下线或上线时,会引起数据的迁移。尽管迁移是自动的,但也是一个不可控的风险。另外,在某些情况下,如配置不当或版本升级后,可能会出现网络流量超高的情况,甚至超过了100Mbps。
脏读问题:使用Hazelcast可能会产生大量脏读的问题,并且会消耗大量的资源来传递数据。从数据源频繁读写数据会耗费额外资源,当数据量增长或创建的主从服务越来越多时,这个消耗呈指数级增长。
Hazelcast在性能、可靠性和可扩展性方面表现出色,但在使用过程中需要注意其可能存在的问题和风险。
应用场景
应用场景包括但不限于:
- 分布式数据缓存:Hazelcast可用于缓存分布式数据,以提高应用程序的性能。
- 集群管理:Hazelcast可用于管理分布式集群,以实现高可用性。
- 分布式数据存储:Hazelcast可用于存储分布式数据,以便在多个节点间共享数据。
- 分布式队列:Hazelcast可用于管理分布式队列,以实现任务分配。
- 分布式消息传递:Hazelcast可用于实现分布式消息传递,以支持应用程序间的通信。
- 分布式消息通知:Hazelcast可用于实现分布式消息通知,以推送数据更新信息。
- 分布式锁:Hazelcast可用于实现分布式锁,以保证数据安全。
- 分布式计数器:Hazelcast可用于实现分布式计数器,以支持统计功能。
- 一致性低延迟查询、聚合和有状态计算:它可以快速构建高效、实时的应用程序,并将一组网络化和集群化的计算机上的内存(RAM)连接在一起用于处理数据。
此外,Hazelcast的设计使其足够灵活,可以作为开箱即用的数据和计算平台,也可以作为自己的云原生应用程序和微服务框架。它被设计为可扩展到数百个成员和数千个客户端,并提供了简单的可扩展性、分区(分片)和重新平衡功能。
Hazelcast是一个强大且灵活的开源工具,可以用于各种不同的应用场景中。
Java使用案例
以下是使用Java和Hazelcast实现分布式Map的示例代码:
import com.hazelcast.config.Config;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import java.util.concurrent.ConcurrentMap;
public class DistributedMap {
public static void main(String[] args) {
Config config = new Config();
HazelcastInstance h = Hazelcast.newHazelcastInstance(config);
ConcurrentMap<String, String> map = h.getMap("myMap");
map.put("key1", "value1");
map.put("key2", "value2");
System.out.println(map.get("key1"));
System.out.println(map.get("key2"));
}
}
在这个示例中,我们首先创建了一个Config对象来配置Hazelcast实例。然后,我们使用Hazelcast类的静态方法newHazelcastInstance来创建一个新的Hazelcast实例。接下来,我们使用get方法获取一个名为“myMap”的分布式Map,并使用put方法将两个键值对添加到Map中。最后,我们使用get方法从Map中获取键对应的值并打印输出。
请注意,这个示例仅适用于单节点环境。如果要在集群环境中使用Hazelcast,需要将每个节点配置为集群成员,并确保它们之间的网络连接正常。此外,还需要注意并发和数据一致性的问题,以确保数据的正确性和可靠性。
安装部署
单节点部署
要部署Hazelcast单节点,可以按照以下步骤进行操作:
- 下载并解压Hazelcast的压缩包。
- 修改Hazelcast的配置文件(例如,hazelcast.xml),设置合适的参数,例如节点名、网络配置等。
- 启动Hazelcast节点,可以使用命令行或者脚本来启动。
- 如果需要与其他应用程序集成,可以通过Hazelcast提供的API来实现。
需要注意的是,单节点部署适用于测试和开发环境,而在生产环境中应该使用集群部署来提高可用性和性能。
集群部署
Hazelcast的集群部署主要涉及修改配置文件、设置节点发现机制以及调整网络配置等步骤。
首先,需要修改配置文件,包括设置集群中的每个节点的group信息、集群发现机制等。在Hazelcast的配置文件(例如,hazelcast.xml)中,需要设置每个节点的group信息,并确保集群中每个节点的group信息都统一和唯一。此外,还需要设置集群发现机制,包括TCP/IP和Multicast等机制,以确保新启动的节点能够发现集群。
其次,需要调整网络配置,包括设置合适的网络接口和端口等。在配置文件中,需要设置合适的网络接口和端口号,以确保节点之间的通信畅通。此外,还需要配置防火墙和网络策略等安全设置,以确保节点之间的通信安全。
最后,需要启动集群中的每个节点,并确保它们能够相互通信和协作。可以使用命令行或者脚本来启动每个节点,并检查它们的日志文件以确保没有错误或异常出现。
需要注意的是,在生产环境中应该使用集群部署来提高可用性和性能。同时,还需要注意数据一致性和并发控制等问题,以确保数据的安全和可靠。
最新版本特性介绍
当前最新的Hazelcast版本是3.6。这个版本的主要特征是巨大的性能提升和新增的云管理和容器部署选项。其中,“热重启存储(Hot Restart Store)”是该版本的一个显著特性,它提升了持久化性能,写性能达到310,000次/秒/节点。
此外,这个版本还新增了内存网格和缓存软件,提供了高性能的分布式数据结构和计算能力。同时,它还支持多种分布式数据结构,如分布式映射、分布式队列、分布式缓存等,并提供了高可用性、数据分布和缓存等功能。
总的来说,Hazelcast 3.6版本在性能、功能和可用性方面都有所提升,可以更好地满足用户的需求。
架构设计
Hazelcast的架构设计非常简单,它基于Java语言编写,没有任何其他依赖。Hazelcast基于熟悉的Java util包对外暴露相同的API和接口,只要将Hazelcast的jar包添加到classpath中,便可以快速使用JVM集群,并开始构建可扩展的应用程序。
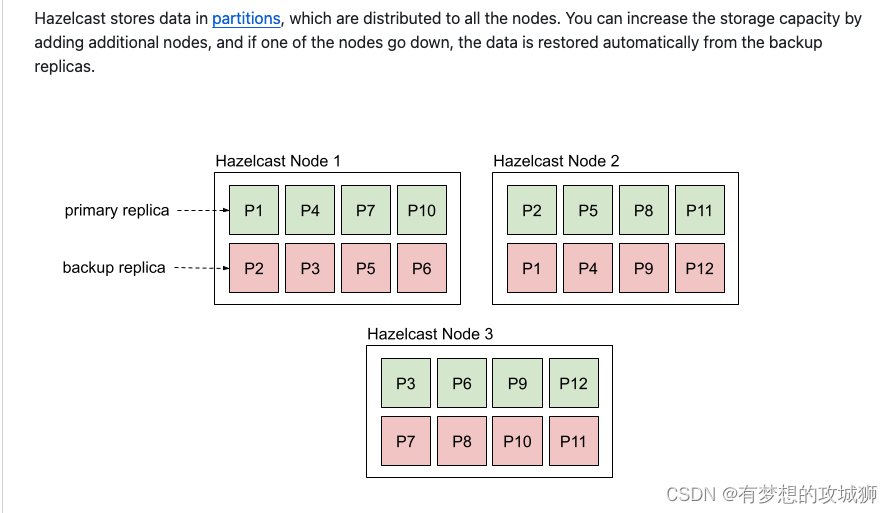
在集群架构方面,Hazelcast的节点是平等的,集群中没有主备角色之分,因此没有单点故障问题。集群内所有节点存储和计算同量数据,这使得Hazelcast具有很高的扩展性和可用性。此外,Hazelcast还提供了很多通用数据结构的分布式实现,例如Map、Queue、Ringbuffer、Set、List、Multimap等,以及并发工具FencedLock、ISemaphore、IAtomicLong等。
此外,Hazelcast还提供了灵活的插件扩展机制,以适应各种特定需求。同时,Hazelcast的设计使其足够灵活,可以作为开箱即用的数据和计算平台,也可以作为自己的云原生应用程序和微服务框架。总之,Hazelcast的架构设计简单、灵活、高效,能够满足各种分布式计算和存储的需求。
作为集群管理器的使用示例
在集群中使用Hazelcast时,通常需要进行以下步骤:
- 配置集群环境:包括设置每个节点的group信息、集群发现机制等。在配置文件中,需要设置每个节点的group信息,并确保集群中每个节点的group信息都统一和唯一。此外,还需要设置集群发现机制,包括TCP/IP和Multicast等机制,以确保新启动的节点能够发现集群。
- 创建Hazelcast实例:在应用程序中,需要创建Hazelcast实例,以便与集群进行交互。可以使用Hazelcast提供的API来创建实例,并传递必要的配置参数。
- 实现分布式数据结构:可以使用Hazelcast提供的分布式数据结构,如Map、Queue、Ringbuffer、Set、List、Multimap等,来存储和管理数据。这些数据结构可以在集群中的所有节点之间共享和同步数据,确保数据的一致性和可靠性。
- 处理并发和分布式事务:在集群环境中,需要考虑并发和分布式事务的问题。Hazelcast提供了并发和分布式事务的支持,可以通过使用相关的API来处理这些问题。
- 监控和管理:需要监控和管理Hazelcast集群的运行状态和性能。可以使用Hazelcast提供的监控和管理工具来获取集群的状态信息和性能指标,以便及时发现和解决问题。
需要注意的是,在生产环境中应该使用集群部署来提高可用性和性能。同时,还需要注意数据一致性和并发控制等问题,以确保数据的安全和可靠。另外,还需要根据实际需求和环境条件进行适当的配置和优化,以确保集群的稳定性和性能。
监控管理工具
集群的监控和管理工具可以帮助您监控和管理Hazelcast集群的运行状态和性能。以下是一些常用的监控和管理工具:
- Management Center :这是Hazelcast提供的官方管理工具,可以用来查看集群的状态、配置、性能指标等。您可以使用浏览器访问管理中心,查看实时的集群信息,并执行一些管理操作,如添加或删除节点、查看日志等。
- JMX(Java Management Extensions) :JMX是Java提供的一种标准的管理和监控技术。通过JMX,您可以查看集群中的节点信息、监控数据结构和操作统计数据等。您可以使用JConsole、VisualVM等工具来连接到集群并进行监控和管理。
- 命令行工具 :Hazelcast提供了一些命令行工具,如hzcli和hzadmin,用于与集群进行交互和监控。您可以使用这些工具执行一些常见的操作,如查看节点状态、查看集群大小等。
- 第三方工具 :除了Hazelcast提供的工具外,还有一些第三方工具可以帮助您监控和管理Hazelcast集群。例如,Prometheus和Grafana等开源监控系统可以用来收集集群的性能数据,并提供可视化的图表和报表。
选择适合您的工具可以帮助您更好地管理和监控Hazelcast集群,确保其稳定性和性能。
Hazelcast与Spring Boot整合
Hazelcast与Spring Boot的整合非常简单,只需要在Spring Boot项目中引入相应的依赖,并配置必要的属性即可。下面是一个简单的步骤:
- 在Spring Boot项目的pom.xml文件中添加Hazelcast的依赖。
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-spring-boot-starter</artifactId>
<version>最新版本</version>
</dependency>
- 在Spring Boot的application.properties或application.yml文件中添加Hazelcast的配置属性。例如:
hazelcast.cluster.name=my-cluster
hazelcast.group.name=my-group
hazelcast.group.password=my-password
hazelcast.initial.min.cluster.size=3
hazelcast.initial.max.cluster.size=5
- 在Spring Boot应用程序中使用@EnableHazelcast和@EnableDiscoveryManager注解开启Hazelcast和集群发现管理器。例如:
@SpringBootApplication
@EnableHazelcast
@EnableDiscoveryManager
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}
- 在需要使用Hazelcast的地方注入相应的Bean,例如:
@Autowired
private HazelcastInstance hazelcastInstance;
这样就可以在Spring Boot应用程序中使用Hazelcast了。需要注意的是,为了确保集群的正常运行,需要确保集群中的节点使用相同的配置和属性,并保持网络连接畅通。
Hazelcast与Vert.x的整合
Hazelcast与Vert.x的整合可以通过以下步骤实现:
- 在Vert.x项目中引入Hazelcast的依赖。您可以在Vert.x的build.gradle或pom.xml文件中添加相应的依赖,并配置所需的版本号。
- 创建一个Verticle来使用Hazelcast。Verticle是Vert.x应用程序的基本单元,可以用来实现特定的功能。在Verticle中,您可以使用Hazelcast的API来创建分布式数据结构、处理并发和分布式事务等操作。
- 在Verticle中使用Hazelcast的EventBus与其它Verticle通信。Vert.x的事件总线允许Verticle之间进行异步通信。您可以使用Hazelcast的EventBus来实现Verticle之间的通信,以便共享数据和协调操作。
- 在Vert.x应用程序中使用Hazelcast的事件驱动架构。事件驱动架构是Vert.x的核心特性之一,它允许应用程序以事件为中心进行构建。您可以使用Hazelcast的事件驱动架构来处理事件,并使用其数据结构和并发工具来提高应用程序的性能和可靠性。
在整合Hazelcast和Vert.x时,需要确保集群中的节点使用相同的配置和属性,并保持网络连接畅通。此外,还需要根据实际需求和环境条件进行适当的配置和优化,以确保集群的稳定性和性能。
Hazelcast作为Vert.x的集群管理器的使用案例
将Hazelcast作为Vert.x的集群管理器可以提供以下使用案例:
分布式数据存储:使用Hazelcast的分布式数据结构,如Map、Queue、Set等,可以在Vert.x应用程序中实现分布式数据存储。这些数据结构可以在集群中的所有节点之间共享和同步数据,确保数据的一致性和可靠性。
事件驱动架构:结合Vert.x的事件驱动架构和Hazelcast的事件驱动架构,可以实现高度可扩展和可靠的事件处理系统。通过使用Hazelcast的事件驱动架构,可以处理大量事件,并利用其数据结构和并发工具提高性能和可靠性。
分布式锁和事务:Hazelcast提供了分布式锁和分布式事务的支持,可以在Vert.x应用程序中使用这些工具来处理并发和分布式事务的问题。通过使用这些工具,可以确保在多个Verticle之间进行协调操作时的数据一致性和可靠性。
集群管理和监控:Hazelcast提供了集群管理和监控工具,可以帮助您监控和管理Vert.x集群的运行状态和性能。您可以使用这些工具来查看集群的状态、配置、性能指标等,以便及时发现和解决问题。
将Hazelcast作为Vert.x的集群管理器可以帮助您构建高性能、可靠和可扩展的Vert.x应用程序。通过结合使用Vert.x的事件驱动架构和Hazelcast的事件驱动架构、分布式数据结构、锁和事务等工具,可以实现复杂的应用程序逻辑和协调操作。同时,通过监控和管理集群,可以确保其稳定性和性能。













![打卡信奥刷题(282)用Scratch图形化工具信奥P1182[普及组/提高]数列分段 Section II](https://i-blog.csdnimg.cn/direct/b4baf88bfe314bfe819361ec89a6b4e4.png)