1. 音频评估的背景及意义
音频质量评估,就是通过专家或自动化的方法评估语音质量。在实践中,有很多主观和客观的方法评价语音质量。
主观方法就是通过人类对语音进行打分,比如MOS、CMOS和ABX Test。客观方法即是通过算法评测语音质量,在实时语音通话领域,这一问题研究较多,出现了诸如如PESQ和P.563这样的有参考和无参考的语音质量评价标准。
有参考和无参考质量评估,取决于该方法是否需要标准信号。有参考除了待评测信号,还需要一个音质优异的,没有损伤的参考信号;而无参考则不需要,直接根据待评估信号,给出质量评分。近些年也出现了MOSNet、VisQAL等基于深度网络的自动语音质量评估方法。
1.1 音频质量界定
音频和语音是电声学下面两个不同的学科分支,属于两个不同的应用,两者在应用目的、使用场景、行业和用户认知统一度三方面存在差异,所以对于来说,首先要界定一下评估对象是音频还是语音。
1、应用目的:语音交互、沟通 VS 个性化呈现音乐
语音质量关注交互和沟通,其最终目的是尽量保真传输语音,保证交互效率与可懂度;音频质量关注音乐表达,如何个性化呈现音乐,其目的是让人感受到所播放音乐的听感效果是好的,这里音乐听感是不是和录制时现场并不一样,对音质的要求更高。
2、使用场景:双向、主动交互 VS 单向、被动聆听
语音质量需要考虑双向沟通过程中用户的体验,音频则是被动的聆听,质量评估更多关注音乐提供者让用户感受到的音乐质量。
3、行业、用户认知统一度:标准程度较好 VS 分裂不统一
经过这么多年的技术发展,语音通信质量评估在行业里有很多标准,但评估音乐播放的标准并不多。
1.2 语音质量主观感受因素
用户在使用语音通信应用时,能感知到的语音质量受很多因素影响。
1.2.1. 外部因素
1)硬件设备:硬件设备本身会导致语音受到恶化或者激变,包括麦克风性能、扬声器性能等,都会有一些失真,不能完全无损的采集和恢复声音。除了失真、频率响应,还有一些指向性特点,一些新型超新型麦克风能采集到的声音在不同位置下会有区别较大。
语音质量还受其它电路布置的影响,比如手机接入,手机麦克风到 DSP 中间,是模拟电路的话,会受到无线信号的干扰。此外,声音输出环节,音腔设计和扬声器结构共振导致的非线性,也都是回声难以处理的影响因素。
2)语音处理算法:语音处理算法主要包括:多级滤波、回声处理算法、噪声抑制算法、自动增益控制算法、频带扩展算法、啸叫控制算法、丢包补偿算法、音频编解码等。相同类型的处理算法可能会经过 N 次级联处理,硬件和软件都会进行处理,每一步处理都会对语音造成损伤。
算法层面外,软件跟操作系统中间的协作中存在的设备启动异常,包括麦克风没正常打开、或打开滞后,线程同步异常导致的声音卡顿、音频缓冲区管理、计算资源管理等,这些都是可能影响语音质量的因素。
3)网络条件:如果网络不好,实际听到的声音会有卡顿;传输是通信的基石,如果传输质量无法保证,那么质量会受到很大影响。首先是信道质量方面,受到流量拥塞影响,WiFi 丢包、无线通信效果不好、信号强度低等情况会出现。其次受接入调度影响,应用客户端接入了更远位置的服务器经过更长更多段的 IP 传输路径,发生流量拥塞和丢包的概率也会提升。
4)环境和场景:如果周围环境嘈杂,对方会听到很多噪音,不管用什么算法,都可能会感受到残留的噪音;如果在封闭房间通信,房间的混响条件也会让语音听起来很浑浊,影响对方的听感。因此,房间的噪声、混响、拾音距离、多设备同地入会造成啸叫现象等也都是影响语音质量的因素。
5)个体的听觉差异:不同人的听力曲线不同,耳朵对不同频段的声音反应也就不一样,这个和年龄段有关系,不同年龄段听域范围不一样。
6)用户期望:用户在使用 APP 或终端时,自然而然会对所使用的产品表现出的质量产生期望,这些期望也跟用户的经验有关系。同时,在一些场景,应用若提供了额外信息,也会影响到用户对该次通信质量的期望。
1.2.2 语音本身
(1)单听或单说:语音特性会影响语音质量,有人本身音色不好,或者对非母语的语言熟悉程度特性,也会让对方觉得通话质量不高,此外,语音可懂度、声音质量、自然度也和对方能感知的语音质量有密切关系。
(2)双方交互:最主要的主观感受因素是回声,如果听到回声,那么通话质量不好,如果两人同时说话产生语音剪切,通话质量也会不好。
2. 语音评估方法
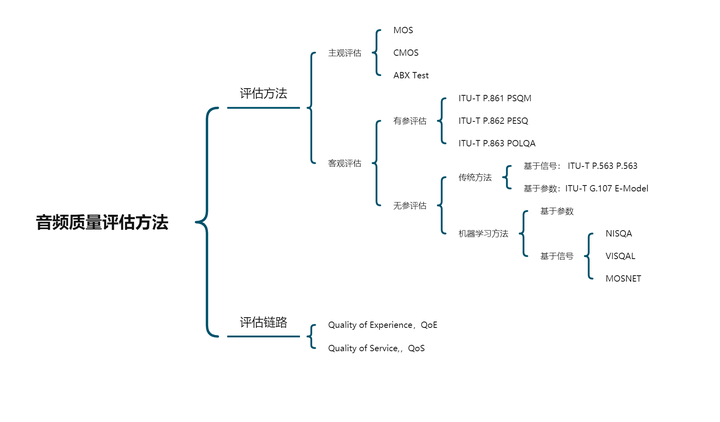
2.1 QoS与QoE
当语音通话出现时,还没有 QoS (Quality of Service)和QoE(Quality of Experience)。人们只能靠“喂喂喂”或”1 2 3“来判断通话质量的好坏。
QoS (Quality of Service),其目的是针对各种业务的需求特征,提供端到端的服务质量保证。QoS 的机制主要是面向运营商、网络建立的,关注的是网络性能、流量的管理等,而不是终端用户体验。后来基于网络的语音互动面对着同样的问题。
QoE(Quality of Experience),随着技术的不断发展,以 QoS 为核心构建的传统评价体系,始终难以与用户的体验相匹配。于是,更加关注用户体验的 QoE(Quality of Experience)被提了出来。在此后很长一段时间里,基于 QoE 的评价体系开始逐渐发展。在实时通信领域,逐渐出现了若干种与 QoE 强相关的评价方法,这些评价方法可以分为主观评价方法、客观评价方法。这些方法都会通过 MoS 分来表达目前用户体验的高低的。

2.2 主观评价与客观评价
主观评价就是通过专家(听声人员) 对语音进行打分,比如MOS、CMOS和ABX Test。
主观评价方法是基于大量听音人对原始声音信号和失真声音信号进行对比测听的基础上,根据某种预先规定的尺度对失真信号进行质量等级划分,它反映了听音人员对声音质量好坏程度的一种主观印象,这种评价是用户对音频质量的真实反映。
平均意见得分(Mean Opnion Score, MOS)
MOS评测实际是一种很宽泛的说法。由于给出评测分数的是人类,因此可以灵活的测试语音的不同方面。比如在语音合成领域,常见的有自然度MOS(MOS of naturalness),相似度MOS(MOS of similarity)。在实时通讯领域,有收听质量(Listening Quality)评价和对话质量(Conversational Quality)评价。但是人类给出的评分结果受到的干扰因素特别多,一般不同论文给出的MOS不具有非常明确的可比性,同一篇文章中的MOS才可以比较不同系统的优劣。谷歌在SSW10发表的Evaluating Long-form Text-to-Speech: Comparing the Ratings of Sentences and Paragraphs对若干种多行文本合成语音的评估方法进行了比较,在评估较长文本中的单个句子时,音频样本的呈现形式会显著影响被测人员给出的结果。比如仅提供单个句子而不提供上下文,与相同句子给出语境相比,被测人员给出的评分结果差异显著。
在实时通讯领域,国际电信联盟(ITU)将语音质量的主观评价方法做了标准化处理,代号为ITU-T P.800.1。其中收听质量的绝对等级评分(Absolute Category Rating, ACR) 是目前比较广泛采用的一种主观评价方法。在使用ACR方法对语音质量评价时,参与评测的人员对语音整体质量进行打分,分值范围为1-5分,分数越大表示语音质量最好。
| 音频级别 | MOS值 | 评价标准 |
| 优 | 4.0~5.0 | 很好,听得清楚;延迟小,交流流畅 |
| 良 | 3.5~4.0 | 稍差,听得清楚;延迟小,交流欠流畅,有点杂音 |
| 中 | 3.0~3.5 | 还可以,听不太清;有一定延迟,可以交流 |
| 差 | 1.5~3.0 | 勉强,听不太清;延迟较大,交流需要重复多遍 |
| 劣 | 0~1.5 | 极差,听不懂;延迟大,交流不通畅 |
一般MOS应为4或者更高,这可以被认为是比较好的语音质量,若MOS低于3.6,则表示大部分被测不太满意这个语音质量。
MOS测试一般要求:
- 足够多样化的样本(即试听者和句子数量)以确保结果在统计上的显著;
- 控制每个试听者的实验环境和设备保持一致;
- 每个试听者遵循同样的评估标准。
除了绝对等级评分,其它常用的语音质量主观评价有失真等级评分(Degradation Category Rating, DCR)和相对等级评分(Comparative Category Rating, CCR),这两种方式不仅需要提供失真语音信号还需要原始语音信号,通过比较失真信号和原始信号获得评价结果(类似于ABX Test),比较适合于评估背景噪音对语音质量的影响,或者不同算法之间的直接较量。语音合成论文中计算的MOS分,不仅强调MOS值,并且要求95%的置信区间内的分数:
客观评价即是通过算法评测语音质量,在实时语音通话领域,这一问题研究较多,出现了诸如如PESQ和P.563这样的有参考和无参考的语音质量评价标准。
客观评价方法多采用某个特定的参数去表征声音通过数字音频系统后的失真程度,并以此来评估处理系统的性能优劣。
在大多数情况下,主观评价相对于客观评价而言,更能全面、有效地反映音频处理技术的性能,而客观评价多用于声音信号相关参数的性能评测。
语音质量的感知评估(Perceptual evaluation of speech quality, PESQ)
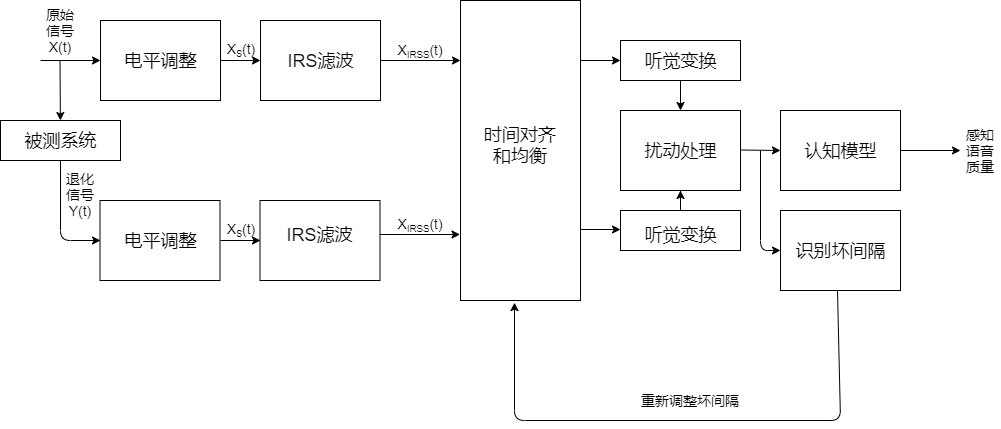
PESQ在国际电信联盟的标注化代号为ITU-T P.862。总的想法是:
- 对原始信号和通过被测系统的信号首先电平调整到标准听觉电平,再利用IRS(Intermediate Reference System)滤波器模拟标准电话听筒进行滤波;
- 对通过电平调整和滤波之后的两个信号在时间上对准,并进行听觉变换,这个变换包括对系统中线性滤波和增益变化的补偿和均衡;
- 将两个听觉变化后的信号之间的谱失真测度作为扰动(即差值),分析扰动曲面提取出的两个退化参数,在频率和时间上累积起来,映射到MOS的预测值。
3. 基于参数的无参考评估方法
通过FEC丢包率、PLC补包参数、Jitter调速等参数,拟合出MOS分。建模mos分的方法为机器学习中的集成树的方法
3.1 数据采集
数据采集共分为两个部分,首先是参数的模拟仿真,然后是MOS分的获取。
参数部分使用NetEQ部分模拟仿真丢包及补偿相关参数。在接收端接收到的音频与发送端的标准音频使用POLAQ机器测试得到MOS分。
3.2 特征提取
无参评估中所用到的特征,经过相关性分析与降维、压缩后,所使用的特征14维,主要为OP次数和时序相关稳定性。
3.3 建模方法
XGBoost是2014年2月诞生的专注于梯度提升算法的机器学习函数库,此函数库因其优良的学习效果以及高效的训练速度而获得广泛的关注。仅在2015年,在Kaggle竞赛中获胜的29个算法中,有17个使用了XGBoost库,而作为对比,近年大热的深度神经网络方法,这一数据则是11个。在KDDCup 2015 竞赛中,排名前十的队伍全部使用了XGBoost库。
XGBoost不仅学习效果很好,而且速度也很快,相比梯度提升算法在另一个常用机器学习库scikit-learn中的实现,XGBoost的性能经常有十倍以上的提升。XGBoost综合了前人关于梯度提升算法的众多工作,并在工程实现上做了大量优化,是目前最成功的机器学习算法之一。
3.4 分析评估
3-15收集的728条数据对其进行分析发现音频时长的值存在异常,正常应该是在300-400个解码包之间,但是时长中有部分音频小于300个解码包;
对比不同特征之间对结果的影响:
| 特征 | MAE | p-corr |
| 一阶差分 | 0.261573752 | 0.903332 |
| 一阶差分的平方 | 0.268612833 | 0.899949 |
| 动态一阶差分 | 0.280147463 | 0.890673 |
| 连续补偿op2 | 0.267677514 | 0.899949 |
| 能量区分(20000) + adf | 0.26720511 | 0.900579 |

从对比实验中可以看出,使用不同的特征对最终的结果(MAE越小越好,代表损失小)影响不大,最终选定一阶差分作为评估稳定性的特征。
特征筛选:
通过对特征之间的相关性分析:
- 目前网络没有触发op4快加速的操作;
- 特征之间有冗余,如一阶差分与动态一阶差分;

特征筛选后
mae: 0.27323379275335025
cor: 0.890884
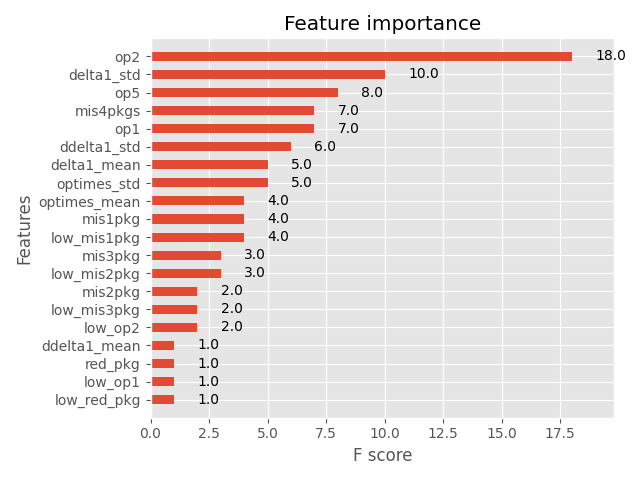
特征重要性分析:

可解释性机器学习:


走势相关性:

结论:
- 总体偏差mae: 0.26,rmse: 0.3448,相关性较高PCC:0.89。43%的样本预测偏差在0.1以内。15%样本预测偏差在0.6分以上。
- 异常数据对结果影响较大。728个样本中存在一定数量的异常音频,当使用polqa标准音频(252个样本)训练,性能提升幅度较大:MAE 0.45 -> 0.26, 相关系数corr 0.69 -> 0.90;
- 一阶差分,以及一阶动态差分、ADF检验值等对性能提升有帮助,但效果不显著;
- 通过特征重要性分析,低音量处的op操作对结果的影响较小,通过特征筛选去掉以后性能下降可以控制在1%以内;
- 补偿次数(op2)对mos分的影响最大,其次为解码包的时序稳定性和连续丢包次数。
- 验证了方法的有效性。针对此次的无参评估所使用的特征提取方法和建模方法,验证使用提升回归树的建模方法去拟合polqa mos分是一种有效的方式。
风险点:
- 当前所用数据较少(325个样本),分析及建模、挖掘得到的信息存在偏差;
- 特征设计方面值得继续探索,捕获其他维度的特征;
4. 算法对比
4.1 ConferencingSpeech 2022
此次大赛仅设置了一个任务:会议场景的非侵入式的客观语音质量评估任务。为此,此次挑战赛开源了一个包含主观质量分数的语料库,总计超过 86,000 条。其中,涵盖了实时语音通信过程可能遭受的各种语音质量损伤场景。希望参赛队伍通过所提供的数据集设计相应的算法评估语音质量以达到更接近人主观感受的目的。此次挑战赛关注于前沿算法研究,不设置任何算法限制。
比赛结果:


NOTE: about 86000 speech clips for training and development, and 4372 clips for the evaluation test in this challenge. They are composed of Chinese, English, and German, and consider background noise, speech enhancement system, reverberation, codecs, packet-loss and other possible online conference voice impairment scenarios.
4.2 NISAQ
使用深度学习提取音频失真的相关特征,将提取到的特征映射到mos分上,可以根据不同的任务和训练数据集,评估TTS、VC和声码器等语音合成类方法的自然度、失真度;也可以根据PLC,超分等任务评估生成音频的质量。

NISQA[6], NOTICE:dataset:totally:more than 90k, 59 training datasets (72,903 files), 18 validation sets (9,567 files), and 4 test sets (952 files) , The datasets NISQA TRAIN SIM and NISQA VAL SIM contain simulated speech distortions, such as packet-loss, bandpass filter, different codecs, and clipping. To simulate real background noises, the noise clips from the DNS-Challenge datasets were used
4.3 对比总结
- 总体来看,针对音频质量评分主要为采集到听众的端到端评价方式,有些系统可能会涉及到多个维度(如响度、噪音等),但暂无针对网络传输模块的评估;
- 仅从评价指标来看,基于参数的无参评估方法是可靠的。相对误差(MAE、RMSE,数值越低越好)和相关系数(PCC,数值越高越好)均比基于音频的无参评估性能要好,基于参数的无参评估PCC ->0.89,MAE -> 0.26, RMSE -> 0.34,而conference speech 2022中基于音频的无参评估排名第一的队伍LCN为 PCC -> 0.81, RMSE -> 0.34;
- 相较基于音频的无参评估,基于参数的无参评估由于没有使用神经网络因此计算量更小,模型更小,准确率更高,但评估维度单一(只能评估netEQ方面);