前言:寒武纪显卡是国产GPU公司开发的显卡,相比于英伟达(nvidia)公司的A100,V100,Geforce RTX显卡来说,不仅性能上有大量的不同,使用过程也有非常大的差异,本文尝试解读一些寒武纪显卡的基本使用情况。寒武纪公司官网参考链接添加链接描述以及寒武纪显卡使用文档参考链接添加链接描述和添加链接描述
下面假设已经买好了寒武纪显卡并且配置了相关的服务器,本人仍然使用Mobaxterm和vscode连接远程服务器。
寒武纪编程实现add运算
在 Cambricon BANG 异构并行编程模型中,在 MLU 上执行的程序称作 Kernel。每个 Task 都执行一次对应的 Kernel 函数。在 MLU 上可以同时执行多个并行的 Kernel。在 Cambricon BANG C 语言中,设备侧的 Kernel 是一个带有mlu_entry属性的函数,该函数描述一个 Task 需要执行的所有操作。在 Kernel 内部还可以通过taskId等内建变量获得每个 Task 唯一的 ID,从而实现不同 Task 的差异化处理。此外,类似的内建变量还包括clusterId、taskIdX、taskIdY等(这句话我个人理解是:Kernel函数绑定taskId,如果有多个任务,那么可以根据taskId来指定不同任务具体工作的差异)
下面代码里面的函数Kernel则是一个任务,这个任务要完成1024个加法,但是这个任务里面也是并行的,具体的并行体现在__bang_add这个计算函数以及__memcpy这个数据转移函数内部。(一个任务并不是对应一个kernel)
nram float dest[LEN]则是在NRAM上开辟一片内存来存储临时数组dest,上面我们提到NRAM是一个MLU Core私有内存,并且延迟低,带宽高,即访存速度更快,相比于参数里的dst数组(位于GDRAM)来说,读取速度更快。但是注意后面我们使用__memcpy将dst数据搬运到NRAM,这个过程还是读取了一次GDRAM,个人猜测__bang_add函数会涉及多次dest的访问,或者__bang_add只能接受NRAM上的数组,要不然不可能做这一步数据搬运。这个Kernel计算过程总结如下:先把GDRAM上的向量source1和source2内容赋值给NRAM上的向量src1和src2,然后调用__bang_add函数把加法结果存储到NRAM上的dest向量(这个是寒武纪内置函数,具体如何操作后续需要调研),最后把NRAM上dest向量的信息赋值给GDRAM上的dst向量。
在主函数main里面涉及到setDevice,这些概念暂时跳过,针对这个代码我们主要介绍一下调用kernel时候使用的<<<dim, ktype, queue>>>三个参数。在主机侧使用<<<dim,ktype,queue>>>语法糖启动的 Kernel 会异步执行,主机侧不需要等待 Kernel 执行完毕即可继续执行后续的代码
queue翻译为队列,表示kernel放到哪个队列执行(有点像排队打饭),如果kernel1和kernel3在同一个执行队列,那么kernel1和kernel3需要串行执行,如果kernel2和这两个kernel不在一个执行队列,那么kernel2可以和另外两个kernel并行执行,参考下图

dim表示任务规模,一个完成的计算任务可以拆分成一系列并行的task(一个task绑定一个kernel),所有的 Task 构成一个三维网格。这个三维网络的维度信息由用户做任务拆分时确定。在由 Task 构成的三维网格中,每个 Task 都有唯一的坐标。每个任务除了一个三维坐标以外,还有一个全局唯一的线性 ID。在实际执行时,每个 Task 会映射到一个物理 MLU Core 上执行。MLU Core 在执行一个 Task 的过程中不会发生切换,只有一个 Task 执行完毕,另一个 Task 才能开始执行(如果只用一个MLU Core,不管如何拆分任务,任务之间都是串行的,为此必须要使用多个MLU Core)
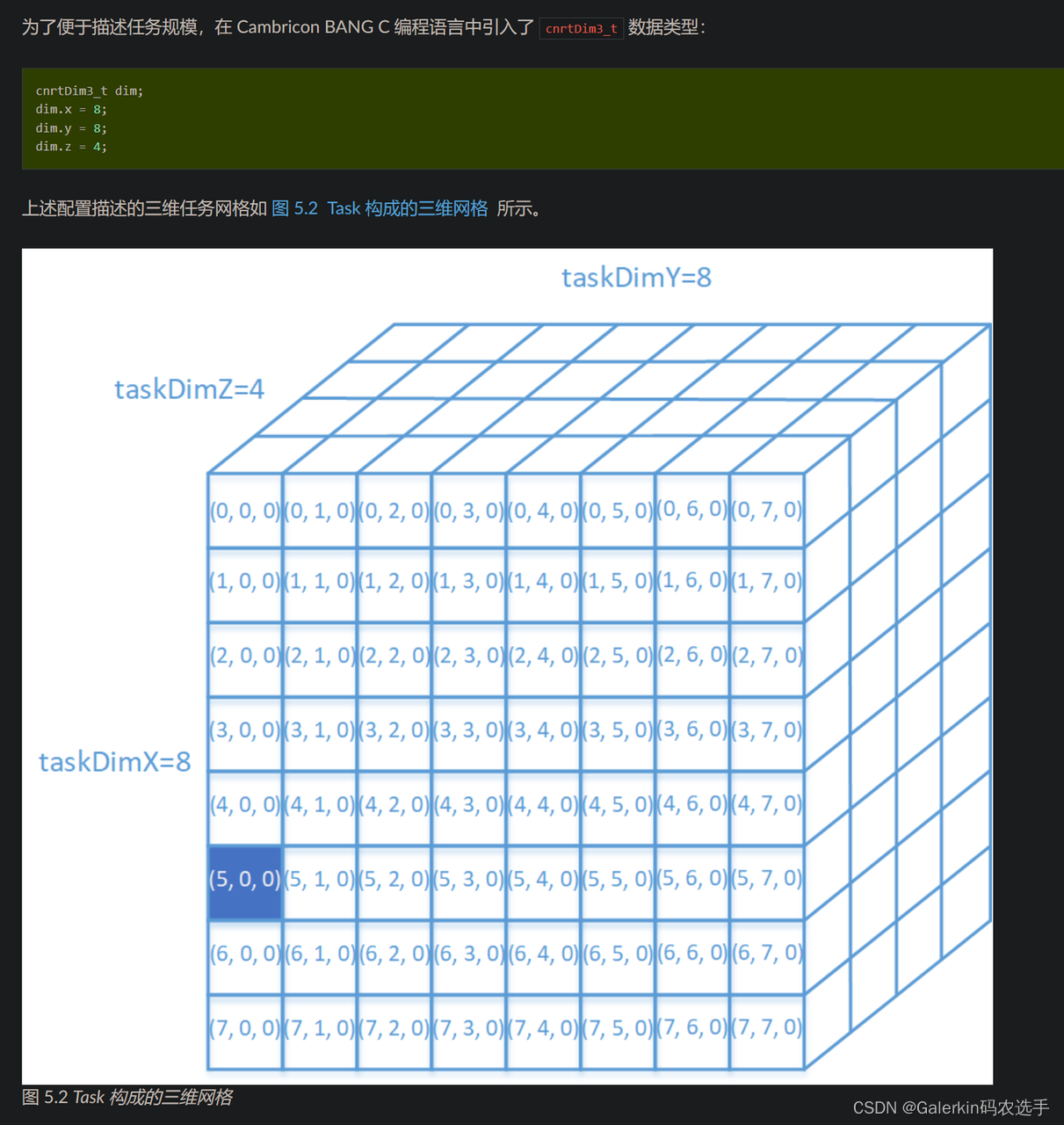 Cambricon BANG C 语言为用户提供了一系列内置变量来显式并行编程。其中,与任务规模相关的内置变量包括: taskDim 、 taskDimX 、 taskDimY 以及 taskDimZ 。
Cambricon BANG C 语言为用户提供了一系列内置变量来显式并行编程。其中,与任务规模相关的内置变量包括: taskDim 、 taskDimX 、 taskDimY 以及 taskDimZ 。
- taskDimX、taskDimY 和 taskDimZ 分别对应任务规模的三个维度: dim.x 、 dim.y 和 dim.z 。
- taskIdX、taskIdY 和 taskIdZ 的取值范围分别是 [0, taskDimX-1] , [0, taskDimY-1] , [0, taskDimZ-1] 。
- taskDim 等于 taskDimX、taskDimY 和 taskDimZ 三者的乘积。
上图所示的任务规模配置为 taskDimX=8,taskDimY=8,taskDimZ=4, taskDim = 256 。
对于每个任务, 可以通过内置变量 taskIdX、taskIdY 和 taskIdZ 获得本任务在 X 方向、Y 方向和 Z 方向的坐标。也可以通过 taskId 获得本任务在整个三维任务块中的线性编号, 即 taskId = taskIdZ * taskDimY * taskDimX + taskIdY * taskDimX + taskIdX。taskId 的取值范围是 [0, taskDim -1] 。
任务类型ktype指定了一个 Kernel 所需要的硬件资源数量,即一个 Kernel 在实际执行时会启动多少个物理 MLU Core 或者 Cluster。在 Cambricon BANG 异构并行编程模型中支持两种任务类型:Block 任务和 Union 任务
Block 任务代表一个 Kernel 在执行时至少需要占用一个 MLU Core。对于 Block 类型的任务,不支持共享 SRAM,不支持不同 Cluster 之间的通信。Block 任务是所有寒武纪硬件都支持的任务类型。当任务规模大于1时,由 Cambricon BANG 异构并行计算平台根据硬件资源占用情况决定所有任务占用的 MLU Core 数量:如果只有一个 MLU Core 可用,那么所有任务在同一个 MLU Core 上串行执行;如果有多个物理 MLU Core 可用,那么所有任务会被平均分配到所有可用的 MLU Core 上分批次执行。
UnionN (N=1, 2, 4, 8, …) 任务表示一个 Kernel 在执行时至少需要占用 N 个 Cluster,其中,N 必须为2的整数次幂。MLU 硬件对 Union 任务的支持与硬件的具体配置有关。例如,一些终端侧或者边缘侧的单核设备不支持 Union 任务,而一个拥有8个 Cluster 的硬件只能够支持 Union1、Union2、Union4 和 Union8 类型的 Union 任务,无法支持 Union16 类型的任务。

add.mlu
#include <bang.h>//CUDA代码是加载cuda.h头文件
#define EPS 1e-7
#define LEN 1024
__mlu_entry__ void Kernel(float* dst, float* source1, float* source2) {
//CUDA的关键词是__global__
__nram__ float dest[LEN];
__nram__ float src1[LEN];
__nram__ float src2[LEN];
__memcpy(src1, source1, LEN * sizeof(float), GDRAM2NRAM);
__memcpy(src2, source2, LEN * sizeof(float), GDRAM2NRAM);
__bang_add(dest, src1, src2, LEN);//寒武纪编程没有threadIdx.x概念
__memcpy(dst, dest, LEN * sizeof(float), NRAM2GDRAM);
}
int main(void)
{
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));//应该是指定代码执行设备
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {
1, 1, 1};
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_BLOCK;
cnrtNotifier_t start, end;//计算kernel执行时间,类似于cudaEvent_t
CNRT_CHECK(cnrtNotifierCreate(&start));//初始化时间,类似于cudaEventCreate(&start);
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(LEN * sizeof(float));//CPU端开辟向量内存
float* host_src1 = (float*)malloc(LEN * sizeof(float));
float* host_src2 = (float*)malloc(LEN * sizeof(float));
for (int i = 0; i < LEN; i++) {
host_src1[i] = i;
host_src2[i] = i;//初始化CPU端向量元素
}
float* mlu_dst;
float* mlu_src1;
float* mlu_src2;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, LEN * sizeof(float)));//在设备端开辟内存,类似于CUDA代码的cudaMalloc
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, LEN * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src2, LEN * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, LEN * sizeof(float), cnrtMemcpyHostToDev));//类似于cudaMemcpy函数
CNRT_CHECK(cnrtMemcpy(mlu_src2, host_src2, LEN * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));//正式计时,类似于cudaEventRecord(start,0);
Kernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, mlu_src2);//调用kernel函数
CNRT_CHECK(cnrtPlaceNotifier(end, queue));//结束计时,类似于cudaEventRecord(stop,0);
cnrtQueueSync(queue);//同步,任务内部的并行需要同步
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, LEN * sizeof(float), cnrtMemcpyDevToHost));//把数据从设备转移回CPU
for (int i = 0; i < LEN; i++) {
if (fabsf(host_dst[i] - 2 * i) > EPS) {
printf("%f expected, but %f got!\n", (float)(2 * i), host_dst[i]);
}
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));//计算kernel时间,类似于cudaEventElapsedTime(&ker_time, start, stop);
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(mlu_src2);
free(host_dst);
free(host_src1);
free(host_src2);
return 0;
}
编译命令为
cncc add.mlu -o add --bang-mlu-arch=mtp_372 -O3
上面这个代码任务类型是Block,一个任务对应一个kernel,占用一个MLU Core,任务规模dim={1,1,1},一共1一个任务,因此一次迭代即可结束。
上面这个是官网上找到的一个完整代码,主要实现简单的向量加法,我们以这个代码来举例子介绍寒武纪编程的细节
编译使用的cncc编译器可以对标CUDA的nvcc,这种代码必须要使用.mlu作为后缀,编译出现的mtp_372表示当前使用的寒武纪显卡架构,我们使用的显卡是寒武纪370,因此架构为mtp_372,除此之外还有mtp_270和mtp_290对应不同版本的寒武纪显卡。
taskId,任务,任务规模dim,任务类型ktype,kernel之间关系
对于Block任务,如果dim = {4,2,1},总共8个任务,但是Block任务至少占用一个MLU Core,如果此时硬件只有一个MLU Core,那么需要串行迭代8次才能结束,如果此时硬件有两个MLU Core空闲,那么需要串行迭代4次结束,具体迭代多少次,跟当前硬件空闲的MLU Core数目有关。一个任务对应一个kernel
对于上面这个代码计算长度为1024的两个向量之间的加法,我们设置每个kernel计算64个加法,那么一共需要16个任务,即设置dim={16,1,1},修改代码如下所示,计算结果仍然正确。
#include <bang.h>//CUDA代码是加载cuda.h头文件
#define EPS 1e-7
#define LEN 1024
#define N 64
__mlu_entry__ void Kernel(float* dst, float* source1, float* source2) {
//CUDA的关键词是__global__
__nram__ float dest[N];
__nram__ float src1[N];
__nram__ float src2[N];
__memcpy(src1, source1 + taskId * N, N * sizeof(float), GDRAM2NRAM);
__memcpy(src2, source2 + taskId * N, N * sizeof(float), GDRAM2NRAM);
__bang_add(dest, src1, src2, N);//寒武纪编程没有threadIdx.x概念
__memcpy(dst + taskId * N, dest, N * sizeof(float), NRAM2GDRAM);
}
int main(void)
{
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));//应该是指定代码执行设备
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {
16, 1, 1};
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_BLOCK;
cnrtNotifier_t start, end;//计算kernel执行时间,类似于cudaEvent_t
CNRT_CHECK(cnrtNotifierCreate(&start));//初始化时间,类似于cudaEventCreate(&start);
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(LEN * sizeof(float));//CPU端开辟向量内存
float* host_src1 = (float*)malloc(LEN * sizeof(float));
float* host_src2 = (float*)malloc(LEN * sizeof(float));
for (int i = 0; i < LEN; i++) {
host_src1[i] = i;
host_src2[i] = i;//初始化CPU端向量元素
}
float* mlu_dst;
float* mlu_src1;
float* mlu_src2;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, LEN * sizeof(float)));//在设备端开辟内存,类似于CUDA代码的cudaMalloc
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, LEN * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src2, LEN * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, LEN * sizeof(float), cnrtMemcpyHostToDev));//类似于cudaMemcpy函数
CNRT_CHECK(cnrtMemcpy(mlu_src2, host_src2, LEN * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));//正式计时,类似于cudaEventRecord(start,0);
Kernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, mlu_src2);//调用kernel函数
CNRT_CHECK(cnrtPlaceNotifier(end, queue));//结束计时,类似于cudaEventRecord(stop,0);
cnrtQueueSync(queue);//同步,任务内部的并行需要同步
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, LEN * sizeof(float), cnrtMemcpyDevToHost));//把数据从设备转移回CPU
for (int i = 0; i < LEN; i++) {
if (fabsf(host_dst[i] - 2 * i) > EPS) {
printf("%f expected, but %f got!\n", (float)(2 * i), host_dst[i]);
}
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));//计算kernel时间,类似于cudaEventElapsedTime(&ker_time, start, stop);
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(mlu_src2);
free(host_dst);
free(host_src1);
free(host_src2);
return 0;
}
对于UnionN类型,比如说Union1类型,一个任务对应4个kernel,需要占用一个cluster(包括4个MLU Core),如果dim = {4,2,1}(注意dim.x%4=0),总共4×2×1/4=2个任务,如果硬件有1个cluster空闲,串行迭代2次,如果硬件有2个cluster空闲,则迭代1次结束。
进一步,我们修改任务类型为Union1,一个任务4个kernel,假设仍然一个任务计算64个加法,那么一个kernel处理16个加法,此时dim={4,16,1}表示一共16个任务,修改代码如下:
#include <bang.h>//CUDA代码是加载cuda.h头文件
#define EPS 1e-7
#define LEN 1024
#define N 16
__mlu_entry__ void Kernel(float* dst, float* source1, float* source2) {
//CUDA的关键词是__global__
__nram__ float dest[N];
__nram__ float src1[N];
__nram__ float src2[N];
__memcpy(src1, source1 + taskId * N, N * sizeof(float), GDRAM2NRAM);
__memcpy(src2, source2 + taskId * N, N * sizeof(float), GDRAM2NRAM);
__bang_add(dest, src1, src2, N);//寒武纪编程没有threadIdx.x概念
__memcpy(dst + taskId * N, dest, N * sizeof(float), NRAM2GDRAM);
}
int main(void)
{
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));//应该是指定代码执行设备
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {
4, 16, 1};
//cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtFunctionType_t ktype = cnrtFuncTypeUnion1;
cnrtNotifier_t start, end;//计算kernel执行时间,类似于cudaEvent_t
CNRT_CHECK(cnrtNotifierCreate(&start));//初始化时间,类似于cudaEventCreate(&start);
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(LEN * sizeof(float));//CPU端开辟向量内存
float* host_src1 = (float*)malloc(LEN * sizeof(float));
float* host_src2 = (float*)malloc(LEN * sizeof(float));
for (int i = 0; i < LEN; i++) {
host_src1[i] = i;
host_src2[i] = i;//初始化CPU端向量元素
}
float* mlu_dst;
float* mlu_src1;
float* mlu_src2;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, LEN * sizeof(float)));//在设备端开辟内存,类似于CUDA代码的cudaMalloc
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, LEN * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src2, LEN * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, LEN * sizeof(float), cnrtMemcpyHostToDev));//类似于cudaMemcpy函数
CNRT_CHECK(cnrtMemcpy(mlu_src2, host_src2, LEN * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));//正式计时,类似于cudaEventRecord(start,0);
Kernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, mlu_src2);//调用kernel函数
CNRT_CHECK(cnrtPlaceNotifier(end, queue));//结束计时,类似于cudaEventRecord(stop,0);
cnrtQueueSync(queue);//同步,任务内部的并行需要同步
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, LEN * sizeof(float), cnrtMemcpyDevToHost));//把数据从设备转移回CPU
for (int i = 0; i < LEN; i++) {
if (fabsf(host_dst[i] - 2 * i) > EPS) {
printf("%f expected, but %f got!\n", (float)(2 * i), host_dst[i]);
}
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));//计算kernel时间,类似于cudaEventElapsedTime(&ker_time, start, stop);
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(mlu_src2);
free(host_dst);
free(host_src1);
free(host_src2);
return 0;
}
如果是Union4任务,一个任务对应16个kernel,占用4个cluster,如果dim={32,2,1},那么一共32×2/16=4个任务,如果硬件有4个cluster空闲,迭代4次结束。
Queue介绍
Queue是用来管理并行操作的一种方式。在同一个Queue中所下发的操作顺序是依次按照下发顺序执行的,在不同Queue中的执行操作则是乱序的。Queue所支持的操作不仅包括Kernel(在设备上的执行程序),还包括Notifier、内存拷贝、设备与主机的数据传输等一系列操作,所有需要按序执行的操作都可以下发至同一个Queue,Queue在当前操作满足执行条件后会依次按照进入顺序执行操作;而不同Queue的操作则不保证顺序,这些操作的顺序是无法预测的。Queue的查询操作可以查看当前Queue的任务执行是否完成,而同步操作在执行成功的时候则可以确保所有的任务执行完成。
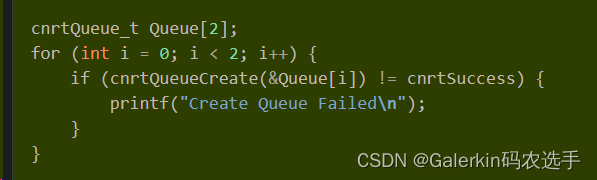

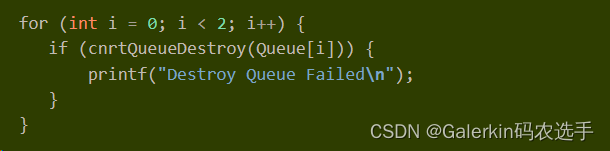
上面这两段代码,第一部分创建了2个queue,第二部分首先创建了cpu端的输入向量hostAddr和设备端的输入向量inputAddr以及输出向量outputAddr,这三个向量的长度是偶数,然后做了一个for循环分别处理向量前一半的Kernel计算以及后一半的向量计算(这个Kernel应该类似于add,必须要保证前一半计算结果和后一半计算结果互不影响,如果是softmax这种计算肯定会结果报错,因为softmax计算过程中需要计算全局max和全局sum)。理论上来说,i=0,i=1应该是串行执行的,但是根据寒武纪资料“上面的样例代码将输入数据拷贝到设备的拷贝操作放入Queue[i]中,并紧接着在同一个Queue中放入了Kernel操作,再放入了将输出数据传输到主机的拷贝操作,放入同一个Queue的这三个操作是依次执行的。而创建的两个Queue均放入了三个同样的操作,两个Queue中的操作则可以并行执行。两个不同的Queue的拷贝操作与Kernel执行操作,可以并行执行相互覆盖其中的执行延迟”,推测循环体里面只是启动作用,i=1的时候,相信前面i=0的那三个步骤还没有结束执行,所以才能起到覆盖延迟的效果。
性能测试
和CUDA代码类似,MLU也有监测性能的工具,编译命令为:
cncc add.mlu -o add --bang-mlu-arch=mtp_372 -O3 -fbang-instrument-kernels
编译结束以后运行命令为:
cnperf-cli record --kernel_profiling ./add
执行结束以后,当前目录会生成一个子文件夹dltrace_data存放获取的性能数据,继续在当前目录键入命令:
cnperf-cli parse
此时生成文件cnperf_ipu_perf_data.csv和cnperf_mpu_perf_data.csv,分别对应 MLU Core 和 Memory Core 的性能数据。当任务类型为BLOCK时,cnperf_mpu_perf_data.csv文件数据无效
常用BANG C向量接口函数
__bang_add(dst_nram, src0_nram, src1_nram, CHANNELS);向量加法,其中dst_nram, src0_nram, src1_nram位于NRAM存储空间,CHANNELS表示一次处理的向量长度(不见得是总向量长度,可能只是某一小段)
__bang_active_relu(dst_nram, src_nram, CHANNELS);RELU函数
__bang_maxequal(dst, src0, src1, LEN);表示dst[i] = src0[i] > src1[i] ? src0[0] : src1[i]
寒武纪kernel实现向量除法
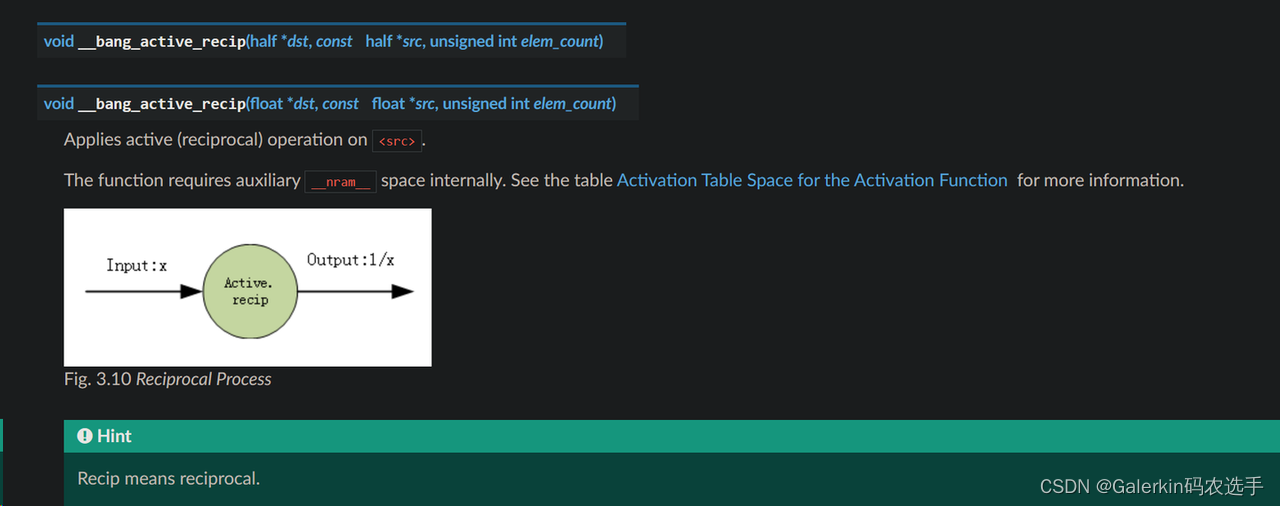
上面的例子过于简单了,下面我们以两个向量之间的除法来做一个具体的介绍,将会用到寒武纪内置的两个函数:
__bang_active_recip(src2, src2, remainNram);//计算倒数,这个函数特别要注意的是,计算结果并不是精确的1/x,结果精度相差在3e-4左右,比如说传进去2,输出的结果不是0.5,而是 0.500003
__bang_mul(dest, src1, src2, remainNram);这个函数将两个向量对应元素做乘法,结果存储到另一个向量
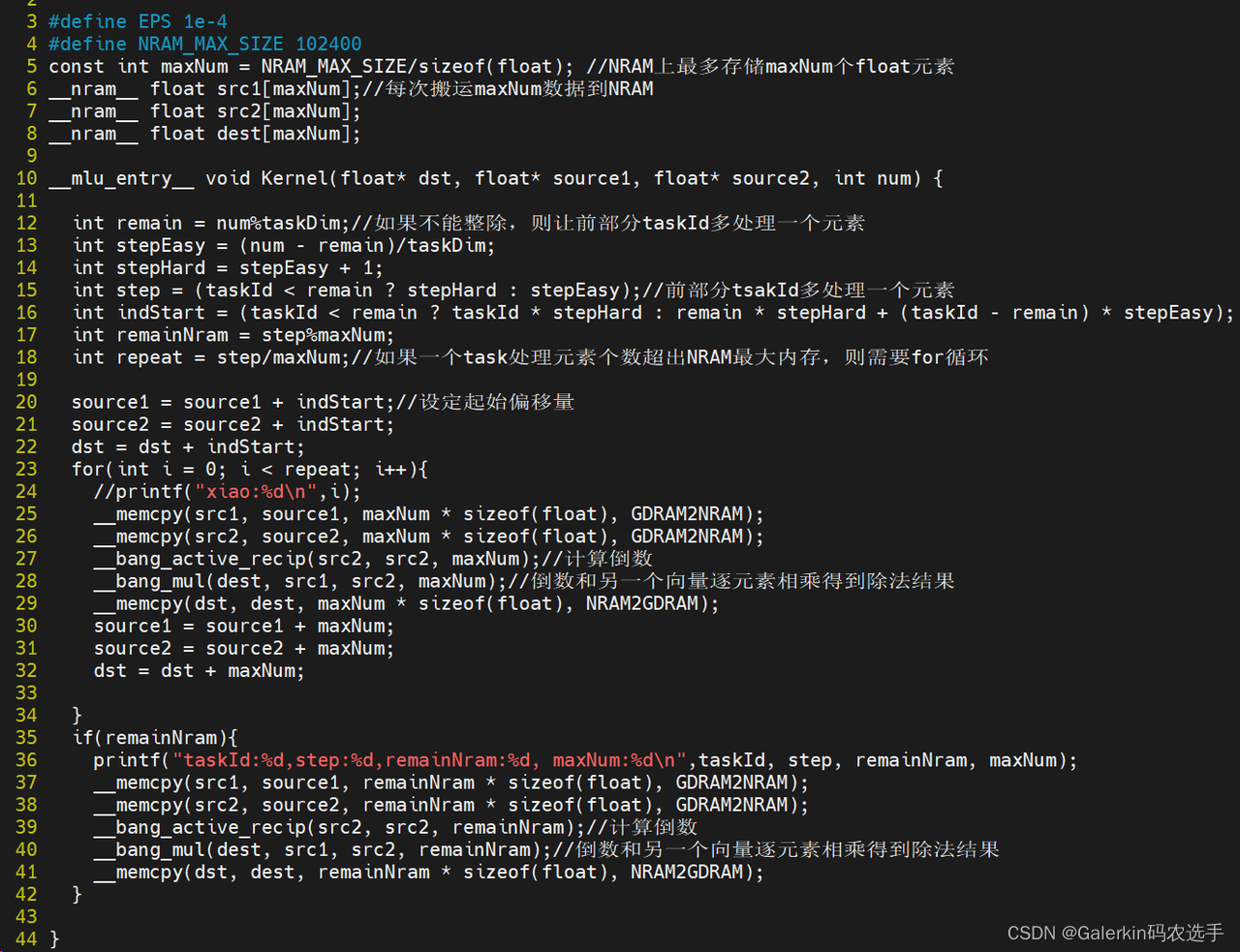
参考上面这段代码,首先我们要确定NRAM到底有多少内存空间,经过查找资料,我们设定102400字节作为最大存储空间,根据最大存储空间和数据类型,我们可以计算出maxNum为NRAM上一个向量最多能放的元素个数,为此我们提前在代码开头申明三个位于NRAM上的向量src1,src2,dest,这三个向量也可以在函数体内部申明。
Kernel函数内部:
代码12行定义了remain,最初设想是向量长度num刚好整除taskDim,但是考虑到一般情况不能整除,为此定义remain来保存余数
代码13行-15行记录不同taskId需要处理的数据量,如果taskId小于remain,那么这部分taskId就多处理一个数据
代码16行记录不同taskId对应的数组起始位置,方便后面偏移
代码17行-18行,现在已经知道每个taskId处理数据量,如果这个数据量太大,超出了NRAM存储空间,那么我们就需要使用for循环来迭代处理这部分数据,repeat指代for循环次数,但是step也不一定能够和maxNum构成整除关系,为此和上面类似也需要计算余数,后面针对这部分多余数据特殊处理
代码23行-34行,循环体前面部分和之前类似,都是搬运数据到NRAM,计算结果,保存结果,但是30行-32行这里需要根据每次处理的数据向后偏移数组
代码35行-43行则是针对多余的那部分数据做特殊处理
最后注意EPS不要设置太小,因为__bang_active_recip(src2, src2, remainNram);误差太大,完整代码如下:
#include <bang.h>
#define EPS 1e-4
#define NRAM_MAX_SIZE 102400
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float src2[maxNum];
__nram__ float dest[maxNum];
__mlu_entry__ void Kernel(float* dst, float* source1, float* source2, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
source1 = source1 + indStart;//设定起始偏移量
source2 = source2 + indStart;
dst = dst + indStart;
for(int i = 0; i < repeat; i++){
//printf("xiao:%d\n",i);
__memcpy(src1, source1, maxNum * sizeof(float), GDRAM2NRAM);
__memcpy(src2, source2, maxNum * sizeof(float), GDRAM2NRAM);
__bang_active_recip(src2, src2, maxNum);//计算倒数
__bang_mul(dest, src1, src2, maxNum);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst, dest, maxNum * sizeof(float), NRAM2GDRAM);
source1 = source1 + maxNum;
source2 = source2 + maxNum;
dst = dst + maxNum;
}
if(remainNram){
printf("taskId:%d,step:%d,remainNram:%d, maxNum:%d\n",taskId, step, remainNram, maxNum);
__memcpy(src1, source1, remainNram * sizeof(float), GDRAM2NRAM);
__memcpy(src2, source2, remainNram * sizeof(float), GDRAM2NRAM);
__bang_active_recip(src2, src2, remainNram);//计算倒数
__bang_mul(dest, src1, src2, remainNram);//倒数和另一个向量逐元素相乘得到除法结果
__memcpy(dst, dest, remainNram * sizeof(float), NRAM2GDRAM);
}
}
int main(void)
{
int num = 1020000;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {
4, 1, 1};
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(num * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
float* host_src2 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = 0.5;
host_src2[i] = 2.0;
}
float* mlu_dst;
float* mlu_src1;
float* mlu_src2;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src2, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtMemcpy(mlu_src2, host_src2, num * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
Kernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, mlu_src2, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, num * sizeof(float), cnrtMemcpyDevToHost));
for (int i = 0; i < num; i++) {
if (fabsf(host_dst[i] - float(0.25)) > EPS) {
printf("%f expected, but %f got!\n", float(0.25), host_dst[i]);
}
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
cnrtFree(mlu_src2);
free(host_dst);
free(host_src1);
free(host_src2);
return 0;
}
寒武纪显卡实现sum规约
sum规约V1
利用__bang_reduce_sum函数,该函数详细用法参考链接添加链接描述
关于__bang_reduce_sum(dest,source,N)有几个重点注意的地方:
1:该函数每隔128字节做一个sum规约,对于float数据来说就是32个元素,也就是说对于source数组,031这些元素被规约成一个,3263这些元素被规约成一个,…
2:dest和source的长度是相等的,虽然source每隔32个float数据规约成一个,但是并不意味着dest的长度是N/32,该函数调用以后导致dest索引为0,32,64,…的地方是规约结果,即dest[0]=sum(source[0:32]),dest[32]=sum(source[32:64]),dest[64]=sum(source[64:96]),…,dest其他位置的元素需要自己初始化。
3:dest占用的字节数至少是128,即至少是32个float元素的数组,这样才能规约,以及N×sizeof(type)必须是128的倍数。
4:如果source的长度是N,但是后面一部分元素是0,只有前n个元素非0,按照正常理解来说,使用__bang_reduce_sum(dest,source,n)可以获得结果,但是实际编码发现这样不行,这样设置结果仍然会报错,保险的方法是始终把第三个参数设置为向量的全部长度。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
#define NRAM_MAX_SIZE 102400
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float dest[maxNum];
__nram__ float destFinal[maxNum];
__mlu_entry__ void Kernel(float* dst, float* source1, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
source1 = source1 + indStart;//设定起始偏移量
__bang_write_zero(destFinal, maxNum);//初始化destFinal全部元素为0
__bang_write_zero(dest, maxNum);//初始化dest全部元素为0
for(int i = 0; i < repeat; i++){
//__bang_printf("xiao:%d\n",i);
__memcpy(src1, source1, maxNum * sizeof(float), GDRAM2NRAM);
__bang_reduce_sum(dest, src1, maxNum);
source1 = source1 + maxNum;
//__bang_printf("old,taskId:%d,iteration:%d,maxNum:%d,destFinal:%.2f,dest:%.2f\n",taskId,i,maxNum,destFinal[1],dest[0]);
__bang_add(destFinal, destFinal, dest, maxNum);
//__bang_printf("new,taskId:%d,iteration:%d,maxNum:%d,destFinal:%.2f,dest:%.2f\n",taskId,i,maxNum,destFinal[0],dest[0]);
//__bang_write_zero(dest, maxNum);//初始化dest全部元素为0
}
if(remainNram){
__bang_write_zero(dest, maxNum);//初始化dest全部元素为0
__bang_write_zero(src1, maxNum);//初始化src1全部元素为0
__memcpy(src1, source1, remainNram * sizeof(float), GDRAM2NRAM);
__bang_reduce_sum(dest, src1, maxNum);//即便src1只有一部分非0,也要使用全部长度maxNum,不能使用remainNram
//__bang_printf("taskId:%d,step:%d,remainNram:%d, indStart:%d, maxNum:%d,dest:%.2f\n",taskId, step, remainNram, indStart,maxNum, dest[0]);
__bang_add(destFinal, destFinal, dest, maxNum);
}
float sum = 0.0f;
for(int i = 0; i < maxNum; i++){
sum += destFinal[i];
}
dest[0] = sum;
__memcpy(dst + taskId, dest, sizeof(float), NRAM2GDRAM);
}
int main(void)
{
int num = 102;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {
4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(taskNum * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = 1e-1;
}
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, taskNum * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
Kernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, taskNum * sizeof(float), cnrtMemcpyDevToHost));
float sum_s = 0;
for(int i = 0; i < taskNum; i++){
printf("dst[%d]=%.2f\n",i,host_dst[i]);
sum_s += host_dst[i];
}
if (fabsf(sum_s - float(num * 1e-1)) > EPS) {
printf("%f expected, but %f got!\n", float(num * 1e-1), sum_s);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}
sum规约V2
上面的这种做法:每个taskId处理step个数据,为了防止step超出NARM的限制,不得不使用for循环,循环体内部每次都要处理maxNum个数据的规约结果,不断累加。循环体结束以后,得到了一个长度为maxNum的向量destFinal,这个向量destFinal只有在索引为0,32,64,…等位置取值非0,其余位置取值都是0,最终遍历destFinal求和才得到了该taskId处理的整个step长度数据的规约结果,非常消耗时间。
这里我们考虑另一种做法,每个taskId得到自己需要处理的那step个元素以后,我们以32为一个单元将这部分数据切分,一共得到repeat=step/32个单元,如果step%32=remainWarp不等于0,那么多余的这部分数据特殊处理。我们也利用一个for循环,尝试累加这些单元的数值和,等循环结束单独考虑多余的数据,类似处理,最终得到一个长度为32的向量dest,这个向量dest保存的就是taskId对应的那step个元素的数值和。最后我们使用__bang_reduce_sum函数对这个长度为32的向量规约,把结果规约到destFinal[0]即可,之后把结果拷贝出来。经过测试,这种做法效率更高,但是很容易出现大数吃小数的现象(上面这种做法也有这种现象)。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
#define NRAM_MAX_SIZE 102400
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[warpSize];//每次搬运maxNum数据到NRAM
__nram__ float dest[warpSize];
__nram__ float destFinal[warpSize];
__mlu_entry__ void Kernel(float* dst, float* source1, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
source1 = source1 + indStart;//设定起始偏移量
int repeat = step/warpSize;//针对taskId处理的这部分数据切分,每一份数据长度切分为128字节,即32个float
int remainWarp = step%warpSize;//针对这部分数据先内部做add,把结果集中在32个float上
__bang_write_zero(destFinal, warpSize);//初始化destFinal全部元素为0
__bang_write_zero(dest, warpSize);//初始化dest全部元素为0
for(int i = 0; i < repeat; i++){
//__bang_printf("xiao:%d\n",i);
__memcpy(src1, source1, warpSize * sizeof(float), GDRAM2NRAM);//每次迁移32个float数据到NRAM
__bang_add(dest, dest, src1, warpSize);//dest存储add结果
source1 = source1 + warpSize;
}
if(remainWarp){
//如果step无法整除warpSize,多余数据特殊处理
__bang_write_zero(src1, warpSize);//初始化src1全部元素为0
__memcpy(src1, source1, remainWarp * sizeof(float), GDRAM2NRAM);
__bang_add(dest, dest, src1, warpSize);
}
//上面运算结束以后,dest这个长度为32的向量就保存了taskId处理的这部分step数据的add结果
__bang_reduce_sum(destFinal, dest, warpSize);//针对dest规约即可把结果保存到destFinal[0]
__memcpy(dst + taskId, destFinal, sizeof(float), NRAM2GDRAM);
}
int main(void)
{
int num = 1020010;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {
4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(taskNum * sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = 1e-1;
}
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, taskNum * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
Kernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, taskNum * sizeof(float), cnrtMemcpyDevToHost));
float sum_s = 0;
for(int i = 0; i < taskNum; i++){
printf("dst[%d]=%.6f\n",i,host_dst[i]);
sum_s += host_dst[i];
}
if (fabsf(sum_s - float(num * 1e-1)) > EPS) {
printf("%f expected, but %f got!\n", float(num * 1e-1), sum_s);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}
sum规约V3
上面的两种做法有一个共同点:kernel运算结束以后获得的结果是长度为taskDim的向量dst,其中dst向量对应索引存储的是不同taskId处理那部分的结果,拷贝回CPU以后还需要在CPU端额外做一个for循环来获取最终结果。针对这个问题,我们打算增加一个kernel来处理,思路如下:
第一个kernel我们定义为unionKernel表示这是一个union类型的kernel,taskDim至少是4,将向量规约以后得到一个长度为taskDim的向量middle。
第二个kernel我们定义为blockKernel表示这是一个block类型的kernel,并且限制dim={1,1,1},将middle规约成长度为1的向量dst。在这个kernel中,仍然需要将middle这个向量转移到NRAM上,由于__bang_reduce_sum对向量长度有限制——要求elem_count×sizeof(type)%128=0,针对我们这个例子即要求向量长度是32的倍数。为此我们仍然在NRAM上开辟128字节(即长度为32的float类型)数组,定义repeat=taskDim/32,和上面类似,将middle分成以32元素为单元的子向量,借助于for循环将middle各部分信息加载到一个长度为32的向量,最后使用__bang_reduce_sum规约成一个数即可。完整代码参考如下:
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
#define NRAM_MAX_SIZE 102400
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[warpSize];//每次搬运maxNum数据到NRAM
__nram__ float dest[warpSize];
__nram__ float destFinal[warpSize];
__mlu_entry__ void unionKernel(float* middle, float* source1, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
source1 = source1 + indStart;//设定起始偏移量
int repeat = step/warpSize;//针对taskId处理的这部分数据切分,每一份数据长度切分为128字节,即32个float
int remainWarp = step%warpSize;//针对这部分数据先内部做add,把结果集中在32个float上
__bang_write_zero(destFinal, warpSize);//初始化destFinal全部元素为0
__bang_write_zero(dest, warpSize);//初始化dest全部元素为0
for(int i = 0; i < repeat; i++){
//__bang_printf("xiao:%d\n",i);
__memcpy(src1, source1, warpSize * sizeof(float), GDRAM2NRAM);//每次迁移32个float数据到NRAM
__bang_add(dest, dest, src1, warpSize);//dest存储add结果
source1 = source1 + warpSize;
}
if(remainWarp){
//如果step无法整除warpSize,多余数据特殊处理
__bang_write_zero(src1, warpSize);//初始化src1全部元素为0
__memcpy(src1, source1, remainWarp * sizeof(float), GDRAM2NRAM);
__bang_add(dest, dest, src1, warpSize);
}
//上面运算结束以后,dest这个长度为32的向量就保存了taskId处理的这部分step数据的add结果
__bang_reduce_sum(destFinal, dest, warpSize);//针对dest规约即可把结果保存到destFinal[0]
__bang_printf("taskId:%d,sum:%.2f\n",taskId, destFinal[0]);
__memcpy(middle + taskId, destFinal, sizeof(float), NRAM2GDRAM);
}
__mlu_entry__ void blockKernel(float* dst, float* middle, int taskNum) {
//int repeat = count/warpSize;//count 至少等于上一个taskNum, count%warpSize=0
int remain = taskNum%warpSize;
int repeat = (taskNum - remain)/warpSize;
__nram__ float srcMid[warpSize];
__bang_write_zero(destFinal, warpSize);//初始化destFinal全部元素为0
//__bang_printf("sum:%.6f\n",destFinal[0]);
for(int i = 0; i < repeat; i++){
__memcpy(srcMid, middle + i * warpSize, warpSize * sizeof(float), GDRAM2NRAM);//每次迁移32个float数据到NRAM
__bang_add(destFinal, destFinal, srcMid, warpSize);//destFinal存储add结果
}
if(remain){
__bang_write_zero(srcMid, warpSize);//初始化destFinal全部元素为0
__memcpy(srcMid, middle + repeat * warpSize, remain * sizeof(float), GDRAM2NRAM);
__bang_add(destFinal, destFinal, srcMid, warpSize);//destFinal存储add结果
}
__bang_reduce_sum(destFinal, destFinal, warpSize);//针对destFinal规约即可把结果保存到destFinal[0]
__bang_printf("taskId:%d,sum:%.6f\n",taskId, destFinal[0]);
__memcpy(dst, destFinal, sizeof(float), NRAM2GDRAM);//这个kernel只能使用Block类型,1个任务
}
int main(void)
{
//int num = 1020010;
int num = 102;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {
4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = 1e-1;
}
float* mlu_middle;
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_middle, taskNum * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
unionKernel<<<dim, ktype, queue>>>(mlu_middle, mlu_src1, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
cnrtDim3_t dimBlock = {
1, 1, 1};
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
blockKernel<<<dimBlock, CNRT_FUNC_TYPE_BLOCK, queue>>>(mlu_dst, mlu_middle, taskNum);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//----------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, sizeof(float), cnrtMemcpyDevToHost));
float sum_s = host_dst[0];
if (fabsf(sum_s - float(num * 1e-1)) > EPS) {
printf("%f expected, but %f got!\n", float(num * 1e-1), sum_s);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_middle);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}
sum规约V4-树状求和
上面几个版本的代码有一个共同点:根据taskDim和给定向量长度num计算出不同taskId需要处理的数据个数为step,即taskId处理的是source[indStart:indStart+step]这部分数据,然后将这部分数据进行内部求和压缩得到长度更小的向量。比如说V1压缩以后得到的是长度为maxNum的向量,V2和V3得到的是长度为warpSize的向量,这个压缩过程使用for循环处理,比如说V2和V3每隔warpSize不断选取source[indStart:indStart+step]元素累加最后得到长度为warpSize的向量,该向量保存的是source[indStart:indStart+step]数值和。但是当step很大,warpSize比较小的时候,这个for循环首先非常消耗时间,其次会出现大数吃小数的现象,为了提高性能和正确率,这里我们尝试使用树状求和来加速。思路如下:
对于taskId处理的数据source[indStart:indStart+step],首先使用for循环内部相加压缩成长度为maxNum的向量dest,然后使用树状求和进一步把dest压缩成长度为warpSize的向量(直接把数据集中到dest[0:32]即可),压缩成功以后dest前warpSize个元素保存的就是source[indStart:indStart+step]的数值和,最后针对dest[0:32]规约得到数值结果。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float dest[maxNum];
__nram__ float destFinal[warpSize];
__mlu_entry__ void unionKernel(float* middle, float* source1, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source1 = source1 + indStart;//设定起始偏移量
__bang_write_zero(dest, maxNum);//初始化dest全部元素为0
for(int i = 0; i < repeat; i++){
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_add(dest, dest, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量dest中
}
if(remainNram){
__bang_write_zero(src1, maxNum);//初始化src1全部元素为0
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_add(dest, dest, src1, maxNum);
}//结束以后长度为maxNum的向量dest保存了source1[indSart:indStart+step]这部分数据的数值和
//下面开始针对dest做规约
__bang_write_zero(destFinal, maxNum);//初始化destFinal全部元素为0
int segNum = maxNum / warpSize;//将dest分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){
//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(dest + i * warpSize, dest + i * warpSize, dest + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destFinal, dest, warpSize);
printf("taskId:%d,step:%d,remainNram:%d,expect:%.6f,but get sum:%.6f\n",taskId, step,remainNram,step*0.1, destFinal[0]);
__memcpy(middle + taskId, destFinal, sizeof(float), NRAM2GDRAM);
}
//----------------------
__mlu_entry__ void blockKernel(float* dst, float* middle, int taskNum) {
//int repeat = count/warpSize;//count 至少等于上一个taskNum, count%warpSize=0
int remain = taskNum%warpSize;
int repeat = (taskNum - remain)/warpSize;
__nram__ float srcMid[warpSize];
__bang_write_zero(destFinal, warpSize);//初始化destFinal全部元素为0
//__bang_printf("sum:%.6f\n",destFinal[0]);
for(int i = 0; i < repeat; i++){
__memcpy(srcMid, middle + i * warpSize, warpSize * sizeof(float), GDRAM2NRAM);//每次迁移32个float数据到NRAM
__bang_add(destFinal, destFinal, srcMid, warpSize);//destFinal存储add结果
}
if(remain){
__bang_write_zero(srcMid, warpSize);//初始化destFinal全部元素为0
__memcpy(srcMid, middle + repeat * warpSize, remain * sizeof(float), GDRAM2NRAM);
__bang_add(destFinal, destFinal, srcMid, warpSize);//destFinal存储add结果
}
__bang_reduce_sum(destFinal, destFinal, warpSize);//针对destFinal规约即可把结果保存到destFinal[0]
__bang_printf("taskId:%d,sum:%.6f\n",taskId, destFinal[0]);
__memcpy(dst, destFinal, sizeof(float), NRAM2GDRAM);//这个kernel只能使用Block类型,1个任务
}
int main(void)
{
int num = 102001010;
//int num = 102;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {
4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = 1e-1;
}
float* mlu_middle;
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_middle, taskNum * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
unionKernel<<<dim, ktype, queue>>>(mlu_middle, mlu_src1, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
cnrtDim3_t dimBlock = {
1, 1, 1};
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
blockKernel<<<dimBlock, CNRT_FUNC_TYPE_BLOCK, queue>>>(mlu_dst, mlu_middle, taskNum);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//----------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, sizeof(float), cnrtMemcpyDevToHost));
float sum_s = host_dst[0];
if (fabsf(sum_s - float(num * 1e-1)) > EPS) {
printf("%f expected, but %f got!\n", float(num * 1e-1), sum_s);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_middle);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}
sum规约V5-atomic_add
上面这几个版本的代码都编写了两个kernel来计算sum,第一个kernel使用union任务类型把向量规约成一个长度为taskDim的中间向量middle,第二个kernel使用block任务类型,一个任务把中间向量规约成一个常数。为了简化代码,我们借助于__bang_atomic_add代码使用一个kernel来完成规约。
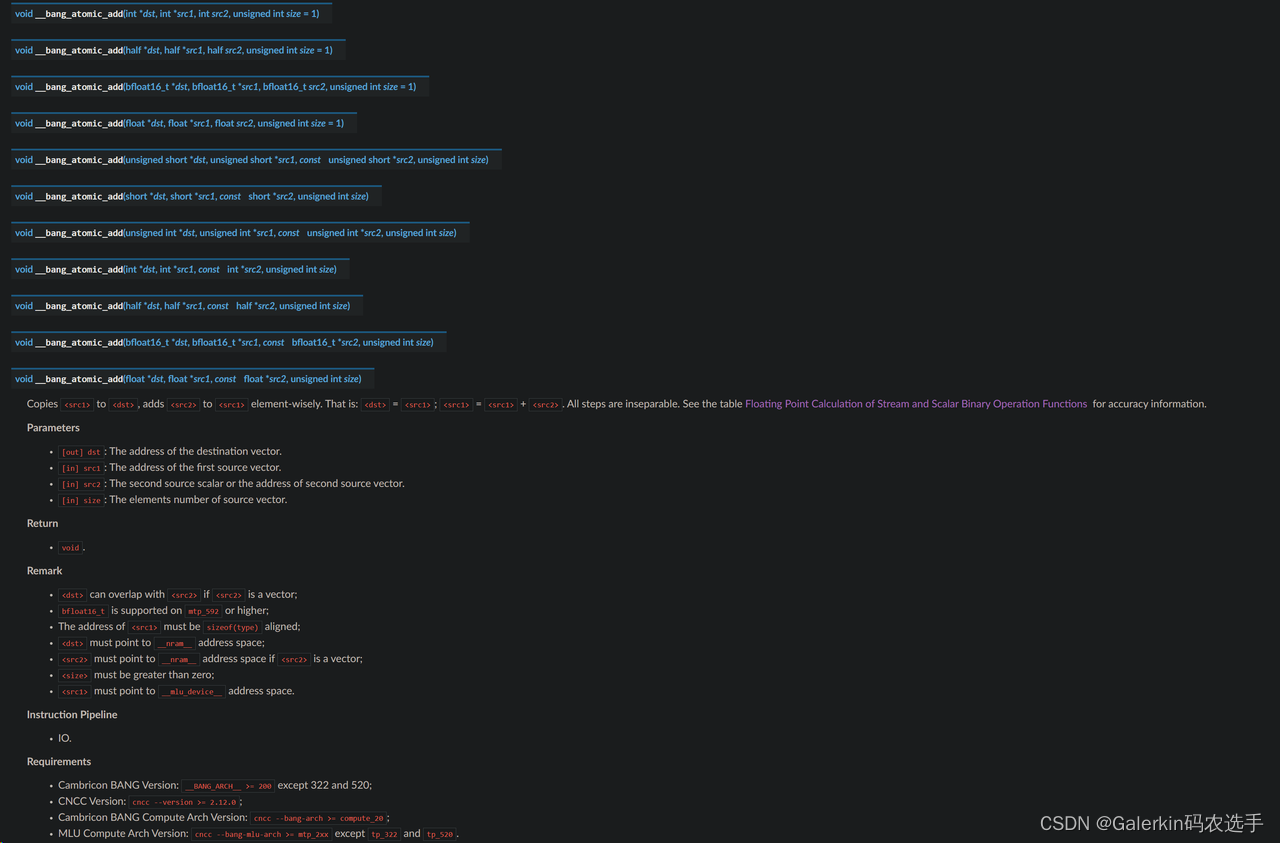
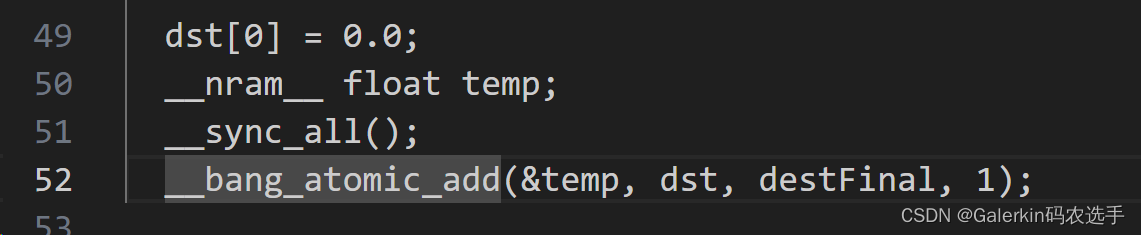
其中特别注意的是dst和src2都是nram上的数组,而src1是mlu_device上的全局数组,核心代码参考下面这一段,其中dst是长度为1的全局数组,destFinal是nram上的数组,并且destFinal[0]存储的是不同taskId的规约结果,temp是临时变量,在正式使用atomic_add之前一定要先做同步,保证前面不同taskId的destFinal[0]都计算完成。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 256;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float dest[maxNum];
__nram__ float destFinal[warpSize];
__mlu_entry__ void unionKernel(float* dst, float* source1, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source1 = source1 + indStart;//设定起始偏移量
__bang_write_zero(dest, maxNum);//初始化dest全部元素为0
for(int i = 0; i < repeat; i++){
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_add(dest, dest, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量dest中
}
if(remainNram){
__bang_write_zero(src1, maxNum);//初始化src1全部元素为0
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_add(dest, dest, src1, maxNum);
}//结束以后长度为maxNum的向量dest保存了source1[indSart:indStart+step]这部分数据的数值和
//下面开始针对dest做规约
__bang_write_zero(destFinal, maxNum);//初始化destFinal全部元素为0
int segNum = maxNum / warpSize;//将dest分成segNum段,每段向量长度为warpSize,分段进行树状求和,segNum要求是2的幂次
for(int strip = segNum/2; strip > 0; strip = strip / 2){
//segNum要求是2的幂次即maxNum必须选取2的幂次
for(int i = 0; i < strip ; i++){
__bang_add(dest + i * warpSize, dest + i * warpSize, dest + (i + strip) * warpSize, warpSize);
}
}
__bang_reduce_sum(destFinal, dest, warpSize);
printf("taskId:%d,step:%d,remainNram:%d,expect:%.6f,but get sum:%.6f\n",taskId, step,remainNram,step*0.1, destFinal[0]);
dst[0] = 0.0;
__nram__ float temp;
__sync_all();
__bang_atomic_add(&temp, dst, destFinal, 1);
}
int main(void)
{
int num = 102001010;
//int num = 102;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {
4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
host_src1[i] = 1e-1;
}
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
unionKernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src1, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//----------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, sizeof(float), cnrtMemcpyDevToHost));
float sum_s = host_dst[0];
if (fabsf(sum_s - float(num * 1e-1)) > EPS) {
printf("%f expected, but %f got!\n", float(num * 1e-1), sum_s);
}
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}
max规约
有了上面实现sum规约的经验,我们可以轻而易举实现max规约,这里调用的函数是__bang_argmax(dst,src,N),其中dst和src长度必须相等,但是dst[0]存储的是src的全局最大值max(src),而dst[1]存储的是最大值对应的索引argmax(src)。
#include <bang.h>
#include <bang_device_functions.h>
#define EPS 1e-7
const int NRAM_MAX_SIZE = 1024 * 128;//后续树状求和必须保证NRAM_MAX_SIZE为2的幂次
const int maxNum = NRAM_MAX_SIZE/sizeof(float); //NRAM上最多存储maxNum个float元素
const int warpSize = 32;//__bang_reduce_sum每次从src取128字节数据相加,对应32个float元素,并且0-31的结果保存在索引0,32-63的结果保存在索引1
__nram__ float src1[maxNum];//每次搬运maxNum数据到NRAM
__nram__ float destMax[1];
__mlu_entry__ void unionKernel(float* middle, float* source1, int num) {
int remain = num%taskDim;//如果不能整除,则让前部分taskId多处理一个元素
int stepEasy = (num - remain)/taskDim;
int stepHard = stepEasy + 1;
int step = (taskId < remain ? stepHard : stepEasy);//前部分tsakId多处理一个元素
int indStart = (taskId < remain ? taskId * stepHard : remain * stepHard + (taskId - remain) * stepEasy);
int remainNram = step%maxNum;
int repeat = step/maxNum;//如果一个task处理元素个数超出NRAM最大内存,则需要for循环
//maxNum尽量取大一些,免得repeat过大导致求和过程累加过于严重,使得大数吃小数
source1 = source1 + indStart;//设定起始偏移量
destMax[0] = -INFINITY;
for(int i = 0; i < repeat; i++){
__memcpy(src1, source1 + i * maxNum, maxNum * sizeof(float), GDRAM2NRAM);
__bang_argmax(src1, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量destMax中
if(destMax[0] < src1[0]){
destMax[0] = src1[0];
}
}
if(remainNram){
__bang_write_value(src1, maxNum, -INFINITY);//初始化src1全部元素为负无穷
__memcpy(src1, source1 + repeat * maxNum, remainNram * sizeof(float), GDRAM2NRAM);
__bang_argmax(src1, src1, maxNum);//针对taskId处理的这step数据,借助于for循环把信息集中到长度为maxNum的向量destMax中
if(destMax[0] < src1[0]){
destMax[0] = src1[0];
}
}//结束以后向量destMax保存了source1[indSart:indStart+step]这部分数据的全局最大值
__memcpy(middle + taskId, destMax, sizeof(float), NRAM2GDRAM);
}
//----------------------
__mlu_entry__ void blockKernel(float* dst, float* middle, int taskNum) {
int remain = taskNum%warpSize;
int repeat = (taskNum - remain)/warpSize;
__nram__ float srcMid[warpSize];
destMax[0] = -INFINITY;
for(int i = 0; i < repeat; i++){
__memcpy(srcMid, middle + i * warpSize, warpSize * sizeof(float), GDRAM2NRAM);//每次迁移32个float数据到NRAM
__bang_argmax(srcMid, srcMid, warpSize);
if(destMax[0] < srcMid[0]){
destMax[0] = srcMid[0];
}
}
if(remain){
__bang_write_value(srcMid, warpSize, -INFINITY);//初始化srcMid全部元素为负无穷
__memcpy(srcMid, middle + repeat * warpSize, remain * sizeof(float), GDRAM2NRAM);
__bang_argmax(srcMid, srcMid, warpSize);
if(destMax[0] < srcMid[0]){
destMax[0] = srcMid[0];
}
}
__memcpy(dst, destMax, sizeof(float), NRAM2GDRAM);//这个kernel只能使用Block类型,1个任务
}
int main(void)
{
//int num = 102001010;
int num = 102;
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {
4, 1, 1};
int taskNum = dim.x * dim.y * dim.z;
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_UNION1;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
float* host_dst = (float*)malloc(sizeof(float));
float* host_src1 = (float*)malloc(num * sizeof(float));
for (int i = 0; i < num; i++) {
if(i % 10 == 0){
host_src1[i] = i;
}
else{
host_src1[i] = 0;
}
}
float* mlu_middle;
float* mlu_dst;
float* mlu_src1;
CNRT_CHECK(cnrtMalloc((void**)&mlu_middle, taskNum * sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_dst, sizeof(float)));
CNRT_CHECK(cnrtMalloc((void**)&mlu_src1, num * sizeof(float)));
CNRT_CHECK(cnrtMemcpy(mlu_src1, host_src1, num * sizeof(float), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
unionKernel<<<dim, ktype, queue>>>(mlu_middle, mlu_src1, num);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//---------------------------
cnrtDim3_t dimBlock = {
1, 1, 1};
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
blockKernel<<<dimBlock, CNRT_FUNC_TYPE_BLOCK, queue>>>(mlu_dst, mlu_middle, taskNum);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
//----------------------------
CNRT_CHECK(cnrtMemcpy(host_dst, mlu_dst, sizeof(float), cnrtMemcpyDevToHost));
float sum_s = host_dst[0];
printf("num:%d, but %f got!\n", num, sum_s);
float timeTotal;
CNRT_CHECK(cnrtNotifierDuration(start, end, &timeTotal));
printf("Total Time: %.3f ms\n", timeTotal / 1000.0);
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_middle);
cnrtFree(mlu_src1);
free(host_dst);
free(host_src1);
return 0;
}