持久化
Redis虽然是个内存数据库,但是Redis支持RDB和AOF两种持久化机制,将数据写往磁盘,可以有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复。
RDB
RDB持久化是把当前进程数据生成快照保存到硬盘的过程。所谓内存快照,就是指内存中的数据在某一个时刻的状态记录。这就类似于照片,当你给朋友拍照时,一张照片就能把朋友一瞬间的形象完全记下来。RDB 就是Redis DataBase 的缩写。
给哪些内存数据做快照?
Redis 的数据都在内存中,为了提供所有数据的可靠性保证,它执行的是全量快照,也就是说,把内存中的所有数据都记录到磁盘中。但是,RDB 文件就越大,往磁盘上写数据的时间开销就越大。
RDB文件的生成是否会阻塞主线程
Redis 提供了两个手动命令来生成 RDB 文件,分别是 save 和 bgsave。
save:在主线程中执行,会导致阻塞;对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是Redis RDB 文件生成的默认配置。
命令实战演示


![]()
除了执行命令手动触发之外,Redis内部还存在自动触发RDB 的持久化机制,例如以下场景:
1)使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。

2)如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点。
3)执行debug reload命令重新加载Redis 时,也会自动触发save操作。

4)默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则自动执行bgsave。

关闭RDB持久化,在课程讲述的Redis版本(6.2.4)上,是将配置文件中的save配置改为 save “”

bgsave执的行流程
为了快照而暂停写操作,肯定是不能接受的。所以这个时候,Redis 就会借助操作系统提供的写时复制技术(Copy-On-Write, COW),在执行快照的同时,正常处理写操作。
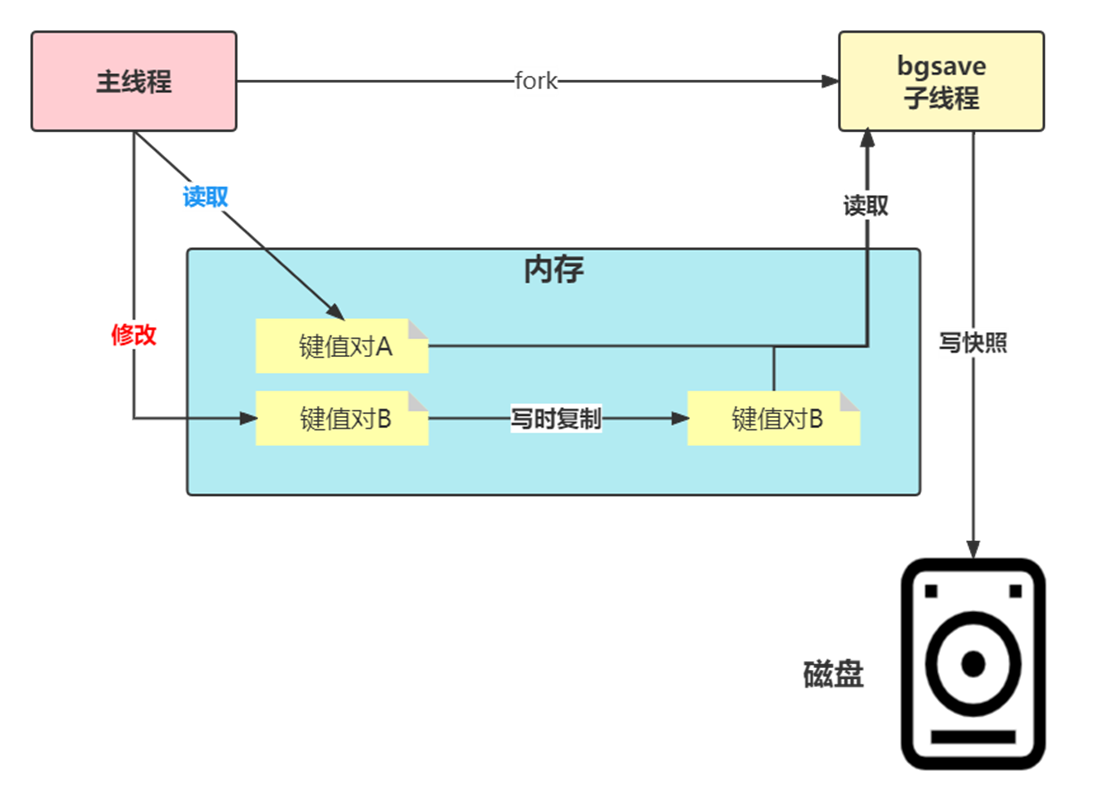
bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。
如果主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和bgsave 子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 B),那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
这既保证了快照的完整性,也允许主线程同时对数据进行修改,避免了对正常业务的影响。
RDB文件
RDB文件保存在dir配置指定的目录下,文件名通过dbfilename配置指定。

可以通过执行config set dir {newDir}和config set dbfilename (newFileName}运行期动态执行,当下次运行时RDB文件会保存到新目录。

Redis默认采用LZF算法对生成的RDB文件做压缩处理,压缩后的文件远远小于内存大小,默认开启,可以通过参数config set rdbcompression { yes |no}动态修改。虽然压缩RDB会消耗CPU,但可大幅降低文件的体积,方便保存到硬盘或通过网维示络发送给从节点,因此线上建议开启。如果 Redis加载损坏的RDB文件时拒绝启动,并打印如下日志:
Short read or OOM loading DB. Unrecoverable error,aborting now.
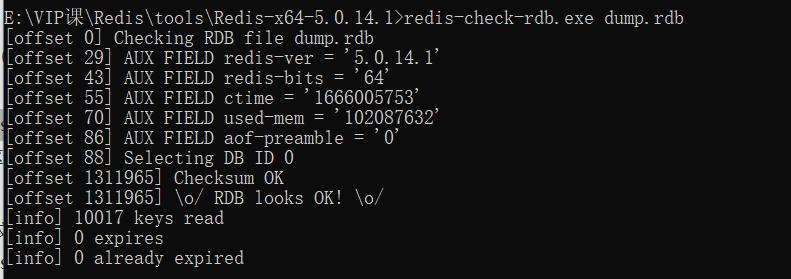
这时可以使用Redis提供的redis-check-rdb工具(老版本是redis-check-dump)检测RDB文件并获取对应的错误报告。
RDB的优缺点
RDB的优点
RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据快照。非常适用于备份,全量复制等场景。
比如每隔几小时执行bgsave备份,并把 RDB文件拷贝到远程机器或者文件系统中(如hdfs),,用于灾难恢复。
Redis加载RDB恢复数据远远快于AOF的方式。
RDB的缺点
RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。
Redis中RDB导致的数据丢失问题
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决。
如下图所示,我们先在 T0 时刻做了一次快照(下一次快照是T4时刻),然后在T1时刻,数据块 5 和 8 被修改了。如果在T2时刻,机器宕机了,那么,只能按照 T0 时刻的快照进行恢复。此时,数据块 5 和 8 的修改值因为没有快照记录,就无法恢复了。

所以这里可以看出,如果想丢失较少的数据,那么T4-T0就要尽可能的小,但是如果频繁地执行全量快照,也会带来两方面的开销:
1、频繁将全量数据写入磁盘,会给磁盘带来很大压力,多个快照竞争有限的磁盘带宽,前一个快照还没有做完,后一个又开始做了,容易造成恶性循环。
2、另一方面,bgsave 子进程需要通过 fork 操作从主线程创建出来。虽然子进程在创建后不会再阻塞主线程,但是,fork 这个创建过程本身会阻塞主线程,而且主线程的内存越大,阻塞时间越长。如果频繁fork出bgsave 子进程,这就会频繁阻塞主线程了。
所以基于这种情况,我们就需要AOF的持久化机制。
AOF
AOF(append only file)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。理解掌握好AOF持久化机制对我们兼顾数据安全性和性能非常有帮助。
使用AOF
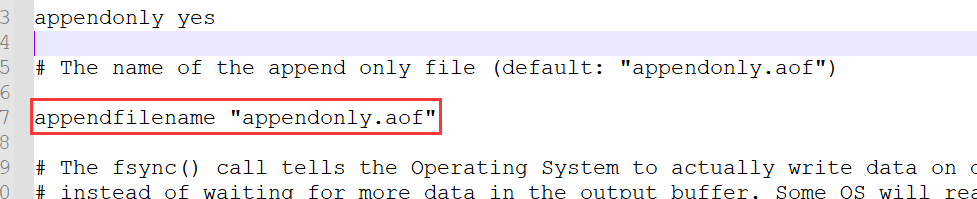
开启AOF功能需要设置配置:appendonly yes,默认不开启。

AOF文件名通过appendfilename配置设置,默认文件名是appendonly.aof。保存路径同RDB持久化方式一致,通过dir配置指定。
AOF的工作流程
AOF的工作流程主要是4个部分: